






文章目录
简述
illumina二代测序分为4步:
1. sample prep 样本准备
2. cluster generation 簇生成
3. sequencing 测序
4. data analysis 数据分析
1. sample prep 样本准备
样本准备,即文库构建。用超声波分割DNA片段(灰色),两端用酶先补平。在3'端加上A碱基,再用酶把两端特定接头(adapter,彩色部分)加上去。
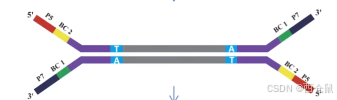
1.1 adapter成分

接头adapter:
- 橙色:测序结合位点
- 紫色:寡聚核苷酸引物的互补序列
2. cluster generation 簇生成
用于扩增DNA片段。更多的DNA片段可以增强信号,避免测量时,由于返回信号过于相似导致的错误。
2.1 flow cell流动池


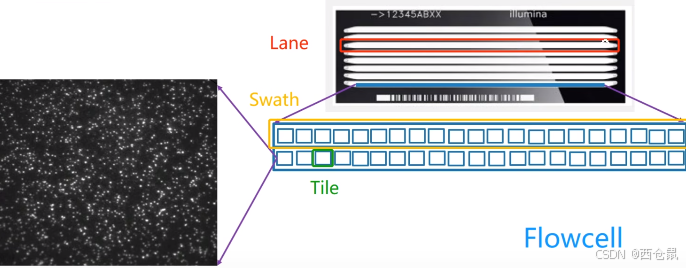
由大到小分别为: Lane>Swath>Tile
一个大甬道Lane分割为n个平行的小甬道Swath,每个小甬道上由一个个小格子Tile。
每个大甬道的两端分别有一个小孔,即液流孔,分别用于引导溶液的进入和排出(单向)。
2.2 扩增流程

lane(大甬道)内表面如图,预置了两种不同寡居核苷酸引物,每个小球代表一个碱基。
每种引物通过共价键连接至flowcell表面,并且这两种引物分别与拼接在DNA片段上的核苷酸序列互补。
一般每次6-8位
重点
- 为什么用共价键?
共价键保证连接的强度,避免在液体流动过程中被溶液冲走
- 为什么要互补?
互补意味着,在扩增过程中,可以用将DNA片段可逆的固定在板子上。用碱性溶液可以轻松解开配对。
2.3 桥式PCR扩增详细流程
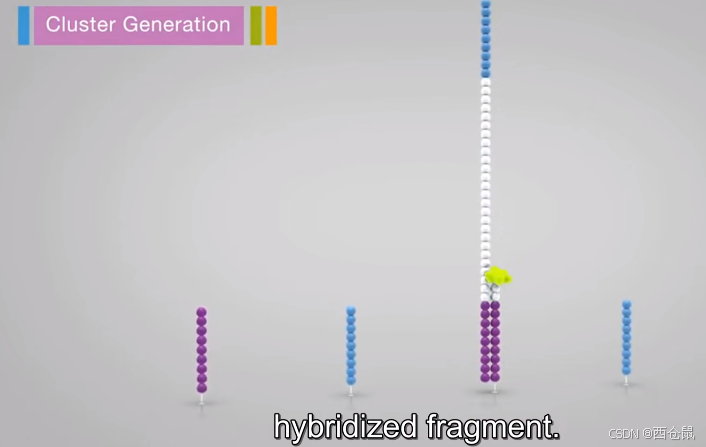
-
在引物匹配的板子上,加入处理过的DNA片段,即DNA文库(内含少量DNA片段)。
-
加入dntp和DNA聚合酶(紫),复制DNA,形成互补链(图中紫色处为杂交匹配)
-
加入NaOH,洗去未固定链,生成固定(共价键,磷酸二酯)在flowcell上的单链

-
加入中性溶液,链的另一端(蓝)就会和板子上的另一种引物匹配,折叠为桥形。

-
加入匹配蓝色引物的dntp和DNA聚合酶,由蓝–>紫方向复制DNA(区别于2)。此时紫->蓝方向为互补序列,蓝->紫方向恰好为原序列。
-
加入NaOH,解开双链。与初始状态相比,已经扩增了2^1倍。
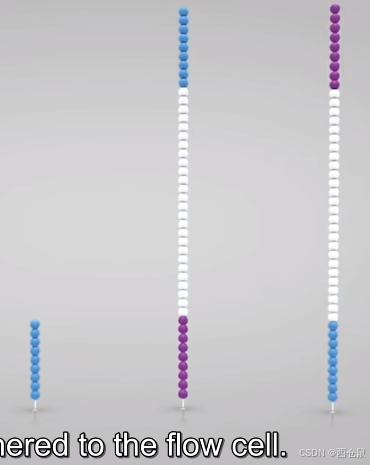
-
加入中性溶液,此时链尾会和板子上匹配的引物杂交,形成新的桥。

-
多次重复5-7,直至flowcell上全部引物都有桥连接。
-
加入NaOH,全部变为单链。
10.加入特定酶,切除紫色引物特定酶,使之不再能发挥匹配作用。 扩增完成。
3. sequencing 测序
从远板端–>近板端看,此时flowcell上已经拥有大量的,与原链同序的DNA片段。
3.1 边合成边测序详细流程
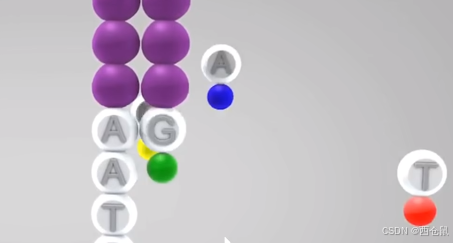
测序原理是不断按位添加碱基,每添加一次,就检测一次荧光强度,最终实现按位读取出全部序列。
-
中性溶液加入测序引物(紫),用于结合远板端

-
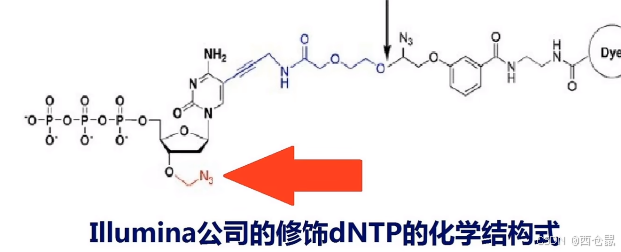
加入带有不同颜色荧光标记的碱基,聚合酶等,用于每次只增加一个碱基。(**核心技术:荧光修饰可逆合成终止。**每请参考下图结构式,箭头处增新修饰了一个叠氮基团,可以实现按位结合)。
-
激光扫描一次,得到一位荧光信号。
-
解析荧光信号,推理荧光信号互补的字母。
-
添加化学试剂,特异性切除叠氮基团和荧光标记,并洗去。此时flowcell上状态为不发光,可结合。

-
重复2-5,直至全部完成。这是一个大规模并行的过程,一次可数以千万计的簇
。在图中每个光点就是一个簇,即为一个小格子(Tile)。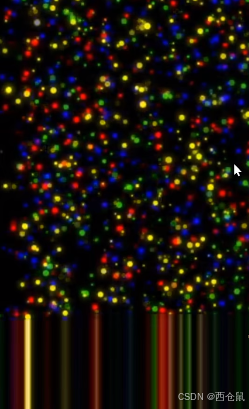
-
在每一次走完上述流程后,要进行index的读取。先将该次读段产物用碱洗掉再加入index1的测序引物,一般位于蓝色引物的前几位。(index=barcode:接头设计之初内置了一个特定标记,作为该DNA片段的编号)

3.2 双端测序详细流程
上一小节“边合成边测序,每次有效位数为6-8位。该方法PCR扩增时用桥式,而在按位测序时,链尾是自由的,非桥式。
而illumina的另一个核心技术是,在扩增及检测时都使用桥式,有效长度增加了一倍。每次检测在正反两端分别检测一次,大大提升了效率。
链首链尾分别用不同的index1,index2加以区分。
- 在完整进行边合成边测序(上一小节)后,洗去原链,保留反向链
- 加入蓝引物,重复边合成边测序,得到互补序列。(由蓝->紫)
- 数据分析,看是否反向互补
4. data analysis数据分析
上述过程大量并行,以引物唯一序列index作为唯一标记,已经生成了数百万甚至数千万个序列。
4.1 片段拼接流程
- 在这些序列中,一定存在index1和index2(这是随机的两个index)所引领的序列完全互补,用计算机进行匹配。
- 在完全互补后,找出部分互补序列。在两序列大部分互补,只有少部分反向延申时,认为他们出自统一DNA片段。,将他们拼接起来。

- 引入参考基因组,进行目标DNA的突变识别等工作。

















 5621
5621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









