







SAFMN(空间自适应特征调制网络)在图像超分辨率领域展现出诸多显著优点。它通过创新的空间自适应特征调制(SAFM)机制,能够有效学习特征依赖关系,增强多尺度特征表示。同时,其引入的卷积通道混合器(CCM),在紧凑结构下可同时编码局部上下文信息与混合通道,进一步优化了特征处理。基于此,本文将 SAFMN应用于 YOLOv8 的 neck 部分的上采样,旨在解决图像上采样时特征模糊的问题,同时增强 neck 部分的多尺度特征,进一步提升模型整体性能。下面是结果图,左边是没有改进的,右边是改进好的
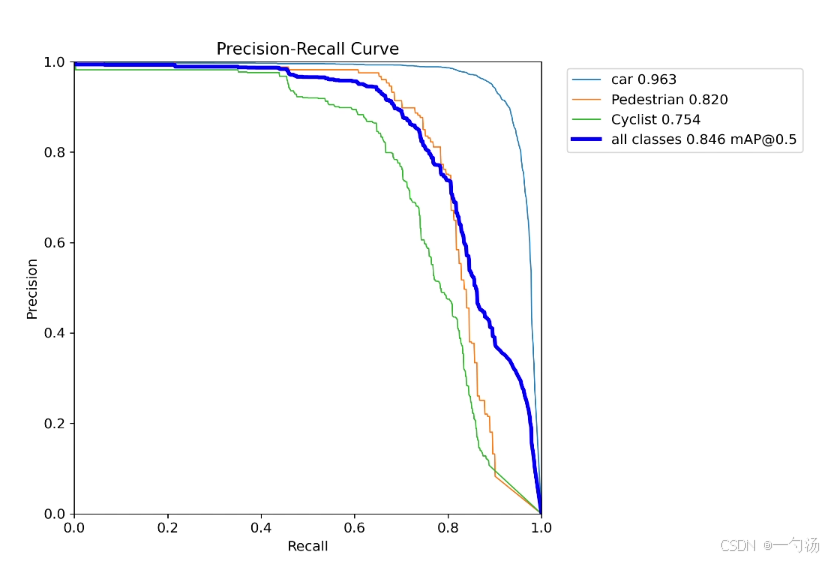
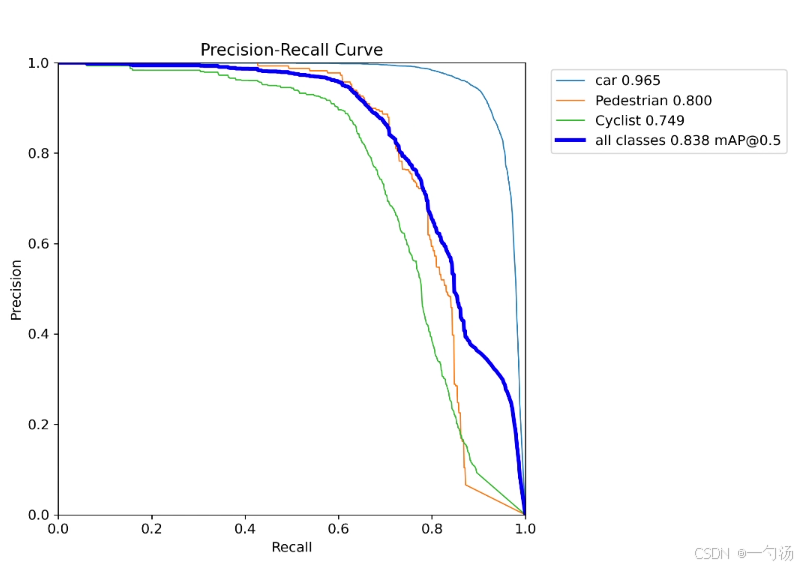
1. 空间自适应特征调制网络SAFMN介绍
SAFMN(Spatial Adaptive Feature Modulation Network)即空间自适应特征调制网络,是一种用于图像超分辨率(SR)的网络架构,其主要模块包括:
- 浅层卷积层:首先将输入的低分辨率(LR)图像通过一个 3×3 卷积层转换到特征空间,生成浅层特征。这一步骤是对输入图像进行初步的特征提取,为后续的处理做准备。
- 特征混合模块(FMM)堆叠:由多个 FMM 模块堆叠而成,用于从浅层特征生成更精细的深层特征,以用于高分辨率(HR)图像重建。
- 空间自适应特征调制(SAFM)层:
- 多尺度特征生成:先将归一化后的输入特征拆分成四组,第一组通过 3×3 深度卷积处理,其余部分通过池化操作进行不同尺度的采样,从而获取不同尺度的特征信息。例如,在生成多尺度特征时,使用了如深度卷积和自适应最大池化等操作来构建特征金字塔,从不同层次捕捉图像特征。
- 特征聚合与调制:将这些不同尺度的特征在通道维度上拼接后,通过 1×1 卷积进行聚合,再经过 GELU 激活函数归一化得到注意力图,最后通过逐元素乘法自适应地调制输入特征。这一系列操作使得模型能够动态地调整不同位置的特征权重,有效利用非局部特征交互,提升模型对图像特征的表达能力。
- 卷积通道混合器(CCM):基于 FMBConv 设计,包含 3×3 卷积和 1×1 卷积。3×3 卷积用于编码空间局部上下文并加倍输入特征的通道数以进行通道混合,1×1 卷积再将通道数还原到原始输入维度,中间应用 GELU 函数进行非线性映射。CCM 的作用是在 SAFM 优先利用非局部特征的基础上,补充局部上下文信息,进一步优化特征表示。
- 残差连接:在 FMM 中还采用了额外的残差学习,将输入特征与经过 SAFM 和 CCM 处理后的特征相加,有助于稳定训练过程并学习高频细节,以实现高质量的图像重建。
- 空间自适应特征调制(SAFM)层:
- 上采样层:在重建阶段,引入全局残差连接来学习高频细节,并使用一个轻量级的上采样层(包含 3×3 卷积和像素混洗层)将特征恢复为 HR 目标图像。这一步骤能够将经过前面模块处理后的特征映射回原始图像的分辨率,从而得到超分辨率后的图像。
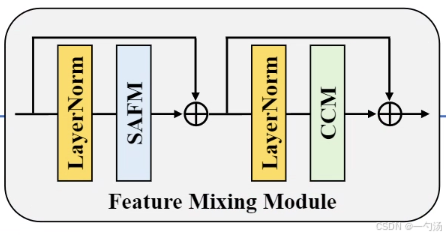
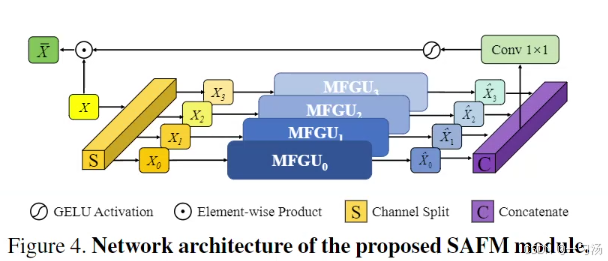
2. 接下来,我们将详细介绍如何将SAFMN集成到 YOLOv8 模型中。
这是我的GitHub代码:tgf123/YOLOv8_improve (github.com)
这是改进讲解:YOLOv8模型改进 第二十二讲 添加空间自适应特征调制网络SAFMN 增强neck部分上采样分辨率_哔哩哔哩_bilibili
2.1 如何添加
1. 首先,在我上传的代码中yolov8_improve中找到SAFMN.py代码部分,它包含两个部分一个是SAFMN.py的核心代码,一个是yolov8模型的配置文件。

2. 然后我们在ultralytics文件夹下面创建一个新的文件夹,名字叫做change_models, 然后再这个文件夹下面创建SAFM.py文件,然后将SAFM的核心代码放入其中

3. 在 task.py文件中导入mdfm
from ultralytics.change_models.mdfm import SAFMNPP

4. 然后将 SAFMNPP添加到下面当中

5. 最后将配置文件复制到下面文件夹下

6. 运行代码跑通
from ultralytics.models import NAS, RTDETR, SAM, YOLO, FastSAM, YOLOWorld
if __name__=="__main__":
# # 使用自己的YOLOv8.yamy文件搭建模型并加载预训练权重训练模型
# model = YOLO(r"D:\model\yolov8\ultralytics\cfg\models\v8\yolov8_LDConv.yaml")\
# .load(r'D:\model\yolov8\yolov8n.pt') # build from YAML and transfer weights
#
# results = model.train(data=r'D:\model\yolov8\ultralytics\cfg\datasets\VOC_my.yaml',
# epochs=300,
# imgsz=640,
# batch=16,
# # cache = False,
# # single_cls = False, # 是否是单类别检测
# # workers = 0,
# # resume=r'D:/model/yolov8/runs/detect/train/weights/last.pt',
# # amp = True
# )
# 使用YOLOv8.yamy文件搭建的模型训练
model = YOLO(r"D:\model\yolov8\ultralytics\cfg\models\v8\yolov8_SAFM.yaml") # build a new model from YAML
model.train(data=r'D:\model\yolov8\ultralytics\cfg\datasets\VOC_my.yaml',
epochs=300, imgsz=640, batch=64
# , close_mosaic=10
)
# # 加载已训练好的模型权重搭建模型训练
# model = YOLO(r'D:\bilibili\model\ultralytics-main\tests\yolov8n.pt') # load a pretrained model (recommended for training)
# results = model.train(data=r'D:\bilibili\model\ultralytics-main\ultralytics\cfg\datasets\VOC_my.yaml',
# epochs=100, imgsz=640, batch=4)


















 2838
2838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









