







所需先验知识(没有先验知识可能会有大碍,了解的话会对D*的理解有帮助):A*算法/ Dijkstra算法
何为D*算法
Dijkstra算法是无启发的寻找图中两节点的最短连接路径的算法,A*算法则是在Dijkstra算法的基础上加入了启发函数h(x),以引导Dijkstra算法搜索过程中的搜索方向,让无必要搜索尽可能的少,从而提升找到最优解速度。这两者都可应用于机器人的离线路径规划问题,即已知环境地图,已知起点终点,要求寻找一条路径使机器人能从起点运动到终点。

但是上述两个算法在实际应用中会出现问题:机器人所拥有的地图不一定是最新的地图,或者说,机器人拥有的地图上明明是可以行走的地方,但是实际运行时却可能不能走,因为有可能出现有人突然在地上放了个东西,或者桌子被挪动了,或者单纯的有一个行人在机人运行时路过或挡在机器人的面前。

碰到这样的问题,比如机器人沿着预定路径走到A点时,发现在预先规划的路径上,下一个应该走的点被障碍物挡住了,这种情况时,最简单的想法就是让机器人停下来,然后重新更新这个障碍物信息,并重新运行一次Dijkstra算法 / A*算法,这样就能重新找到一条路。
但是这样子做会带来一个问题:重复计算。假如如下图所示新的障碍物仅仅只是挡住了一点点,机器人完全可以小绕一下绕开这个障碍物,然后后面的路径仍然按照之前规划的走。可是重复运行Dijkstra算法 / A*算法时却把后面完全一样的路径重新又计算了一遍
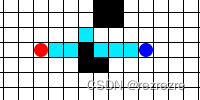
D*算法的存在就是为了解决这个重复计算的问题,在最开始求出目标路径后,把搜索过程的所有信息保存下来,等后面碰到了先验未知的障碍物时就可以利用一开始保存下来的信息快速的规划出新的路径。
顺便一提因为D*算法有上述的特性,所以D*算法可以使用在“无先验地图信息/先验地图信息不多的环境中的导航”的问题,因为只需要在最开始假装整个地图没有任何障碍,起点到终点的路径就是一条直线,然后再在在线运行时不断使用D*算法重新规划即可。
下面将开始讲述D*算法的流程。为此先提及一下算法应用的语境:
机器人已知一个地图map,在某个起点S,要前往终点E。但是机器人走着走着,突然在中途发现了地图上没有标注的障碍物(比如走着走着突然用激光雷达发现前面1米处有一些没有标注在地图上的障碍物),而这些障碍物有的挡住了机器人原本规划好的路,有的没挡住。
为了简化,我们认为机器人在栅格地图上运动,每次运动一个格子(8邻接),并且机器人为一个点,体积仅占据一个格子大小。
D*算法流程
先说明一下需要用到的类,开始运行前需要对地图中每个节点创建一个state类对象,以便在搜索中使用。
# 伪代码
class state:
# 存储了每个地图格子所需的信息,下面会说到这个类用在哪。以下为类成员变量
x # 横坐标
y # 纵坐标
t = "new" # 记录了当前点是否被搜索过(可为“new”,"open", "close",分别代表这个格子没被搜索过,这个格子在open表里,这个格子在close表里。关于什么是open表什么是close表,建议去看A*算法,能很快理解)。初始化为new
parent = None # 父指针,指向上一个state,沿着某个点的父指针一路搜索就能找到从这个点到目标点end的最短路径
h # 当前代价值(D*算法核心)
k # 历史最小代价值(D*算法核心,意义是所有更新过的h之中最小的h值)
d*算法主代码:
function Dstar(map, start, end):
# map:m*n的地图,记录了障碍物。map[i][j]是一个state类对象
# start:起点,state类对象
# end: 终点,state类对象
open_list = [ ] # 新建一个open list用于引导搜索
insert_to_openlist(end,0, open_list) # 将终点放入open_list中
# 第一次搜索,基于离线先验地图找到从起点到终点的最短路径,注意从终点往起点找
loop until (start.t == “close”):process_state() # D*算法核心函数之一
end loop
# 让机器人一步一步沿着路径走,有可能在走的过程中会发现新障碍物
temp_p = start
while (p != end) do
if ( unknown obstacle found) then # 发现新障碍物, 执行重规划
for new_obstacle in new_obstacles: # 对每个新障碍物调用modify_cost函数
modify_cost( new_obstacle ) #(D*算法核心函数之一)
end for
do
k_min = process_state()
while not ( k_min >= temp_p.h or open_list.isempty() )continue
end if
temp_p = temp_p.parent
end while
上述伪代码中核心函数为2个:modify_cost 和 process_state。我翻阅了csdn几个关于process_state的解释,发现都有挺大的错误,会让整个算法在某些情况下陷入死循环(比如D*规划算法及python实现_mhrobot的博客-CSDN博客)。而且就连原论文的伪代码都有点问题(可能原论文(Optimal and Effificient Path Planning for Partially-Known Environments,
function modify_cost( new_obstacle ):
set_cost(any point to new_obstacle ) = 10000000000 # 让“从任何点到障碍点的代价”和“从障碍点到任何点的代价” 均设置为无穷大,程序中使用超级大的数代替(考虑8邻接)
if new_obstacle.t == "close" then
insert(new_obstacle, new_obstacle.h ) # 放到open表中,insert也是d*算法中的重要函数之一
end if
下面是 Process_state函数的伪代码,注意标红那条
function process_state( ):
x = get_min_k_state(oepn_list) # 拿出openlist中获取k值最小那个state,这点目的跟A*是一样的,都是利用k值引导搜索顺序,但注意这个k值相当于A*算法中的f值(f=g+h, g为实际代价函数值,h为估计代价启发函数值),而且在D*中,不使用h这个启发函数值, 仅使用实际代价值引导搜索,所以其实硬要说,D*更像dijkstra,都是使用实际代价引导搜索而不用启发函数缩减搜索范围,D*这点对于后面发现新障碍物进行重新规划来说是必要的。
if x == Null then return -1
k_old = get_min_k(oepn_list) # 找到openlist中最小的k值,其实就是上面那个x的k值
open_list.delete(x) # 将x从open list中移除, 放入close表
x.t = "close" # 相当于放入close表,只不过这里不显式地维护一个close表
# 以下为核心代码:
# 第一组判断
if k_old < x.h then # 满足这个条件说明x的h值被修改过,认为x处于raise状态
for each_neighbor Y of X: #考虑8邻接neighbor
if y.h<k_old and x.h> y.h + cost(y,x) then
x.parent = y
x.h = y.h + cost(x,y)
end if
end for
end if
# 第二组判断
if k_old == x.h then
for each_neighbor Y of X: #考虑8邻接neighbor
if y.t== "new" or
(y.parent == x and y.h !=x.h + cost(x,y) ) or
(y.parent != x and y.h >x.h + cost(x,y)) then
y.parent = x
insert(y, x.h + cost(x,y))
end if
end for
else: # 不满足k_old == x.h 那就是k_old < x.h
for each_neighbor Y of X: #考虑8邻接neighbor
if y.t == "new" or
(y.parent == x and y.h !=x.h + cost(x,y) ) then
y.parent = x
insert(y, x.h + cost(x,y))
else:
if (y.parent != x and y.h >x.h + cost(x,y)) then
x.k = x.h # 注意这行!没有这行会出现特定情况死循环。在查阅大量资料后,在wikipedia的d*算法页面中找到解决办法就是这行代码。网上大部分资料,包括d*原始论文里都是没这句的,不知道为啥
insert(x, x.h)
else:
if (y.parent!=x and x.h>y.h+cost(y,x) and y.t= "close" and y.h>k_old then
insert(y,y.h)
end if
end if
end if
end for
end if
return get_min_k(oepn_list)
上面使用到的insert函数:
function insert(state, new_h)
if state.t == "new": # 将未探索过的点加入到open表时,h设置为传进来的 new_h state.k = h_new # 因为未曾被探索过,k又是历史最小的h,所以k就是new_h elif state.t == "open": state.k = min(state.k, h_new) # 保持k为历史最小的h elif state.t == "close": state.k = min(state.k, h_new) # 保持k为历史最小的h state.h = h_new # h意为当前点到终点的代价 state.t = "open" # 插入到open表里所以状态也要维护成open open_list.add(state) # 插入到open表
以上便是完整的d*算法流程。
D*流程详解
现在我们从“d*算法主代码”开始详解d*函数:
第一次搜索
首先可以看到,在最开始我们需要创建一个open list,然后将终点end加入到open list,之后不断调用process_state直到起始点start被加入到close表。open表中的东西要按照k值大小排序,每次调用process_state需要取出k值最小的一个来扩展搜索,注意open list中的东西要按照 k 值大小从小到大排序而不是h值。
第一次搜索时,对应主代码中的:
# 第一次搜索,基于离线先验地图找到从起点到终点的最短路径,注意从终点往起点找
loop until (start.t == “close”):process_state() # D*算法核心函数之一
end loop
这部分。
其实,在首次搜索时,我们可以发现每个点第一次被加入到open表中时都是从new状态加入,即每次调用insert函数时state.t 最开始都是new,所以其h值与k值其实是相等的;在搜索过程中,也即每一步调用process_state时,k_old 也一直等于x.h(k_old相当于x.k),因此每次第一组判断都不会被执行,第二组判断也总是只执行k_old == x.h这部分:
# 第二组判断
if k_old == x.h then
for each_neighbor Y of X: #考虑8邻接neighbor
if y.t== "new" or
(y.parent == x and y.h !=x.h + cost(x,y) ) or
(y.parent != x and y.h >x.h + cost(x,y)) then
y.parent = x
insert(y, x.h + cost(x,y))
end if
end for
else:
........
而这部分中,对x的8邻接点y的判断只会有两种情况,①y.t== "new" ②y.parent != x and y.h >x.h + cost(x,y)。而第三种情况③y.parent == x and y.h !=x.h + cost(x,y) 在这时是不会出现的,因为h的意思是当前点到终点的代价,parent的意思是最短路径上当前点到终点的路径的上一个点,那么只要某个点的parent是x,那么这个点的h一定是x的h值加上从x到这个点的代价。第三种情况出现必定是因为y.h、x.h或者cost(x,y)被非正常流程中人为修改过,这在第一次搜索时是不会出现的,而是在重规划时出现,这点下面一个部分我们再谈。
也就是说,在初次搜索时其实整个process_state代码相当于如下(因为其他部分此时不会被调用&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1174
1174











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









