







笔者到底想讲些啥?
在SFM(structure from motion)的计算中BA(Bundle Adjustment)作为最后一步优化具有很重要的作用,在近几年兴起的基于图的SLAM(simultaneous localization and mapping)算法里面使用了图优化替代了原来的滤波器,这里所谓的图优化其实也是指BA。其实很多经典的文献对于BA都有深深浅浅的介绍,如果想对BA的全过程做一个全面的更深层次的了解,推荐阅读 Bundle Adjustment —A Modern Synthesis,但是BA的内容确实太多太杂了,刚对其了解的时候往往会陷入其局部的计算中不能自拔,因此笔者准备对其进行一个比较全局一点的介绍,希望读者可以比较轻松的一览BA的全过程而不是陷入其局部的繁琐的计算中,同时也会尽量对其需要的数学工具介绍全面,如有错误和遗漏还望指正。
如果读者对以下内容有基本了解那可就太棒棒了!
- 射影相机几何模型
- 对极几何
- 凸优化
- 矩阵理论
这才是真的开始
Bundle Adjustment(之后在不引起歧义的情况下用BA代替,你问为什么?笔者懒啊-。-),大概似乎也许好像有近百年的历史了吧(没错,可以称为state-of-art的视觉SLAM在几年前才用上将近上百岁的算法),中文译为光束法平差,大概大家看到更多的翻译可能为束调整、捆集调整或者捆绑调整等等。这么多翻译笔者最喜欢的还是光束法平差,一看就比其它的更专业逼格更高嘛,其它的翻译都太直译了。当然最重要的是光束法平差完美的表达了BA的来源、原理和计算过程,而其他的只是强调了将很多数据放在一起进行优化计算这个事。不信?那我们来分析一下嘛。
所谓bundle,来源于bundle of light,其本意就是指的光束,这些光束指的是三维空间中的点投影到像平面上的光束,而重投影误差(后面会讲这到底是个什么鬼)正是利用这些光束来构建的,因此称为光束法强调光束也正是描述其优化模型是如何建立的。剩下的就是平差,那什么是平差呢?借用一下百度词条 测量平差 中的解释吧。
由于测量仪器的精度不完善和人为因素及外界条件的影响,测量误差总是不可避免的。为了提高成果的质量,处理好这些测量中存在的误差问题,观测值的个数往往要多于确定未知量所必须观测的个数,也就是要进行多余观测。有了多余观测,势必在观测结果之间产生矛盾,测量平差的目的就在于消除这些矛盾而求得观测量的最可靠结果并评定测量成果的精度。测量平差采用的原理就是“最小二乘法”。
平差也就正好表述了为什么需要BA以及BA这个优化过程到底是怎么进行的。
BA模型到底是怎么来的?
感觉前面废话说了一大堆,解释了半天BA的中文翻译,那么BA到底是干嘛的呢?经过前面的铺垫,用一句话来描述BA那就是,BA的本质是一个优化模型,其目的是最小化重投影误差
本质是一个优化模型应该很容易理解,那么什么是重投影误差呢?投影自然是个几何的问题,既然是几何问题那这个时候来个图自然就是最棒棒了!
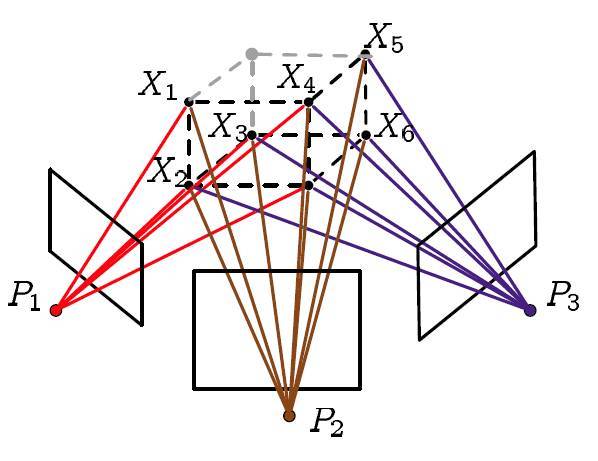
看!这些五颜六色的线就是我们讲的光束啦!那现在就该说下什么叫重投影误差了,重投影也就是指的第二次投影,那到底是怎么投影的呢?我们来整理一下吧:
- 其实第一次投影指的就是相机在拍照的时候三维空间点投影到图像上
- 然后我们利用这些图像对一些特征点进行三角定位(triangulation,很多地方翻译为三角化或者三角剖分等等,当然笔者最喜欢的还是三角定位,显然是利用几何信息构建三角形来确定三维空间点的位置嘛,相关内容请参考对极几何)
- 最后利用我们计算得到的三维点的坐标(注意不是真实的)和我们计算得到的相机矩阵(当然也不是真实的)进行第二次投影,也就是重投影
现在我们知道什么是重投影了,那重投影误差到底是什么样的误差呢?这个误差是指的真实三维空间点在图像平面上的投影(也就是图像上的像素点)和重投影(其实是用我们的计算值得到的虚拟的像素点)的差值,因为种种原因计算得到的值和实际情况不会完全相符,也就是这个差值不可能恰好为0,此时也就需要将这些差值的和最小化获取最优的相机参数及三维空间点的坐标。
进入数学模式!
感觉像写小说一样写了一堆堆的文字,既然BA是个数学问题,不用数学讲讲好像不太行,接下来就看看BA的数学模型是怎么构建的吧。
对BA有点了解的同学可能知道BA是一个图优化模型,那首先肯定要构造一个图模型了(没学过图论也没事,后面还是会回到一般的优化模型)。既然是图模型那自然就有节点和边了,这个图模型的节点由相机和三维空间点构成
构成,如果点
投影到相机
的图像上则将这两个节点连接起来。还是来张图吧。
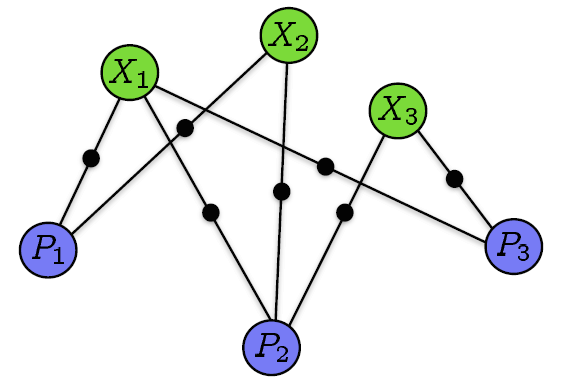
这样就一目了然了。那么我们现在就可以通过这个图来构造优化模型了。
令点在相机
拍摄到的图像归一化坐标系上的坐标为
,其重投影后的图像归一化坐标系下坐标为
,其中
是为了在计算时能不受相机内参影响kk和k'k′是将齐次坐标转换为非齐次坐标的常数项,可以得到该重投影误差为
BA是要将所有重投影误差的和最小化,那么这里自然就要开始求和了。
其中当点X_jXj在相机P_iPi中有投影时,否则为
。
到此我们就得到了BA优化模型的数学形式了。
接下来就应该开始计算了!
既然是优化模型,那自然就应该用各种优化算法来进行计算了。这里先小小的剧透一下,BA现在基本都是利用LM(Levenberg-Marquardt)算法并在此基础上利用BA模型的稀疏性质来进行计算的,LM算法是最速下降法(梯度下降法)和Gauss-Newton的结合体,至于是怎么结合的接下来就来慢慢介绍了。
提前给定
为什么用平方呢??还不是因为不用计算平方根了嘛!
最速下降法
如果你对梯度比较熟悉的话,那你应该知道梯度方向是函数上升最快的方向,而此时我们需要解决的问题是让函数最小化。你应该想到了,那就顺着梯度的负方向去迭代寻找使函数最小的变量值就好了嘛。梯度下降法就是用的这种思想,用数学表达的话大概就是这样
其中为步长。
最速下降法保证了每次迭代函数都是下降的,在初始点离最优点很远的时候刚开始下降的速度非常快,但是最速下降法的迭代方向是折线形的导致了收敛非常非常的慢。
Newton型方法
现在先回顾一下中学数学,给定一个开口向上的一元二次函数,如何知道该函数何处最小?这个应该很容易就可以答上来了,对该函数求导,导数为0处就是函数最小处。
Newton型方法也就是这种思想,首先将函数利用泰勒展开到二次项:
为Hessian矩阵,是二次偏导矩阵。
也就是说Newton型方法将函数局部近似成一个二次函数进行迭代,然后令在
方向上迭代直至收敛,接下来自然就对这个函数求导了:
Newton型方法收敛的时候特别快,尤其是对于二次函数而言一步就可以得到结果。但是该方法有个最大的缺点就是Hessian矩阵计算实在是太复杂了,并且Newton型方法的迭代并不像最速下降法一样保证每次迭代都是下降的。
Gauss-Newton方法
既然Newton型方法计算Hessian矩阵太困难了,那有没有什么方法可以不计算Hessian矩阵呢?在范数符号内将ee一阶泰勒展开,我们可以得到
其中\mathbf{J}J为Jacobi矩阵,函数ee对xx求一次偏导而来,梯度也是对向量函数求一次偏导而来。将标量考虑为的矩阵,将向量考虑为
的矩阵,其实这些求导都是求Jacobi矩阵。此时不需要计算Hessian矩阵。
同样,二次函数导数为0时取极值,则有
由此在
方向上迭代直至
最小。
同时我们可以发现一个等式,会在下面的LM方法中用到
Gauss-Newton方法就避免了求Hessian矩阵,并且在收敛的时候依旧很快。但是依旧无法保证每次迭代的时候函数都是下降的(虽然从上式可以推导出来是下降方向,但是步长可能过长)。
LM方法
LM方法就是在以上方法基础上的改进,通过参数的调整使得优化能在最速下降法和Gauss-Newton法之间自由的切换,在保证下降的同时也能保证快速收敛。
Gauss-Newton最后需要求解的方程为
LM算法在此基础上做了更改,变成了
通过参数\lambdaλ的调节在最速下降法和Gauss-Newton法之间切换。做个不很数学的直观分析吧,当\lambdaλ很小时,显然和Gauss-Newton法是一样的;当\lambdaλ很大时,就变成了这样:
然后再看看前面的最速下降法?
这里还存在一个问题,当\lambdaλ取某个值的时候可能会导致不可逆,所以这里变成了
其实LM算法的具体形式就笔者看到的就有很多种,但是本质都是通过参数\lambdaλ在最速下降法和Gauss-Newton法之间切换。这里选用的是维基百科上的形式。
LM算法就由此保证了每次迭代都是下降的,并且可以快速收敛。
还没完呢!别忘了还要解方程
LM算法主体就是一个方程的求解,也是其计算量最大的部分。当其近似于最速下降法的时候没有什么好讨论的,但是当其近似于Gauss-Newton法的时候,这个最小二乘解的问题就该好好讨论一下了。以下的讨论就利用Gauss-Newton的形式来求解。
稠密矩阵的最小二乘解
对于形如的超定参数方程而言,有很多求解方式,伪逆、QR分解、SVD等等,这里不展开谈,想具体了解的可以去查阅矩阵理论相关资料。这些方式都有一个共同的特点,我们都是将AA看作一般的稠密矩阵,主要得到的解自然非常鲁棒,都是计算量却是和维数的三次方成正比
。面对BA这种超大规模的优化似乎有点不太实用。
稀疏矩阵的Cholesky分解
稠密矩阵计算起来那么复杂,如果是稀疏矩阵的话利用其稀疏的性质可以大幅减少计算量,对于稀疏矩阵的Cholesky分解就是这样。其分解形式为一个上三角矩阵的转置乘上自身:
为什么说我们的矩阵是稀疏的
用一个非常简单的例子来解释吧,考虑有两个相机矩阵和
、两个空间点
和
,其中
只在
中有投影,
在两个相机(或视角)中都有投影。令优化函数为
,此时Jacobi矩阵为
考虑相机位置(图像数量)和空间点都非常多的情况,不难想象Jacobi矩阵不光是一个稀疏矩阵而且还可以写成形如的分块矩阵。接下来就该利用这些性质正式进入计算了!
开始计算吧!
现在再回到Gauss-Newton最后的超定参数方程吧。既然Jacobi矩阵可以分块那我们就先分块,分块可以有效降低需要计算的矩阵的维度并以此减少计算量。
由此我们可以先求出,然后代回求出
。其中
被称为舒尔补(Schur complement)。分块降维之后的计算就可以利用稀疏的Cholesky分解进行计算了。
注意事项!
以上就基本将BA的整个过程进行了介绍,当然这只是最基础的思路,接下来一些遗漏点进行补充。
李群及李代数
不知道有没有人注意到,在优化迭代的过程中,我们求的值为,然后利用
来更新
的值。这里就应该出现一个问题了,对于空间点的坐标和平移向量这么处理自然没有什么问题,但是对于旋转矩阵呢?难道用
来更新RR的值吗?好像不太对吧。
对于旋转矩阵RR而言是不存在加法的,按理讲应该用来更新
的值,但是优化算法的迭代过程又不能是乘法,这就出现了矛盾。
这里旋转矩阵及相关运算属于李群,此时将旋转矩阵变换到其对应的李代数上进行计算,然后再变回李群。打个不是那么恰当的比方,在计算卷积的时候常常通过傅里叶变换计算乘积然后再反变换回来就是要求的卷积了,这个也是转换到李代数上计算然后再变回李群。具体的推导可以参看李群及李代数相关内容。
协方差矩阵
在我们的推导中是求解方程
但常常加入信息矩阵(协方差矩阵的逆),令求解方程变为
其中\mathbf{\Sigma_x}Σx为协方差矩阵,令其为分块对角阵表示所有观测向量都不相关。
参考文献
- Triggs B, McLauchlan P F, Hartley R I, et al. Bundle adjustment—a modern synthesis[C]//International workshop on vision algorithms. Springer Berlin Heidelberg, 1999: 298-372.
- Hartley R, Zisserman A. Multiple view geometry in computer vision[M]. Cambridge university press, 2003.
- Barfoot T D. STATE ESTIMATION FOR ROBOTICS[J]. 2017.















 1144
1144











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









