







针对渲染管线一中三个步骤详细说明:
一. 应用阶段(Application Stage)
这是一个由CPU主要负责的阶段,且完全由开发人员掌控。
在这个阶段,CPU将决定递给GPU什么样的数据(譬如渲染目标场景中的灯光、场景的模型、摄像机的位置),
有时候还会对这些数据进行处理(譬如只递给GPU可以被摄像机看见的元素,其他不可见的元素被 剔除(culling)出去),
并且告诉GPU这些数据的渲染状态(譬如纹理、材质、着色器等)。
1.1 准备渲染数据:
1.2 合批:
把能合并的都合并起来,尽量减少Draw Call
GPUInstance,GPU硬件算法。使用与大量需要重复绘制的模型,比如草地。但是instance是有上限的,并且只能减少Draw Call,对于增加的面数来说是无解的。
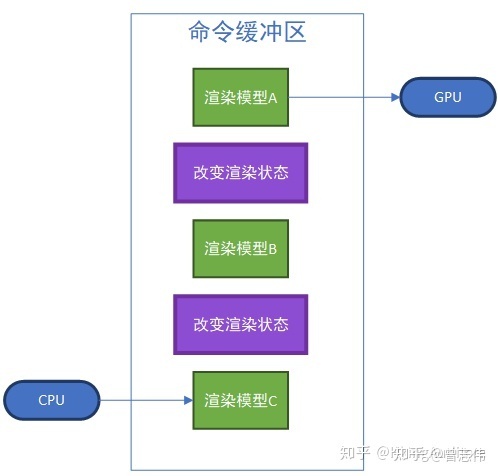
1.3 调用Draw Call
CPU向GPU发送的指令也是像流水线一样的——CPU往命令缓冲区中一个个放入命令,GPU则依次取出执行。在实际的渲染中,GPU的渲染速度往往超过了CPU提交命令的速度,这导致渲染中大部分时间都消耗在了CPU提交Draw Call上。有一种解决这种问题的方法是使用 批处理(Batching),即把要渲染的模型合并在一起提交给GPU。
打个比方,工厂想要把100根钢筋中间截断,如果发货方采用的方法是一根一根钢筋送给工厂,那速度肯定是相当慢的;大部分情况都是发货方把这100根钢筋打包送给工厂,这样明显加快了效率。
二. 几何阶段(Geometry Processing)
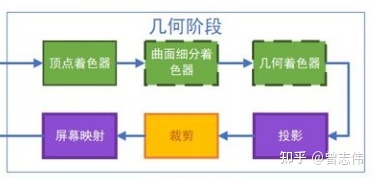
这一个由GPU主导的阶段,从这个阶段开始,我们正式进入了流水线。
而这个阶段又可以进一步细分为若干个流水线阶段,可以类比理解为工厂流水线上进行的一道道工序。
2.1 顶点着色器(Vertex Shaders)【可编程】
顶点着色器中,我们无法创建或销毁任何一个顶点,也无法得到当前处理的这个顶点与其他顶点的关系。
因为每次处理顶点都是独立的,不需要额外考虑其他,所以进行这一步速度会相当快。
- 计算顶点位置
- 计算每个顶点包含的其他性质,如法线,纹理坐标、色彩、光照等
- 坐标转换:把顶点坐标从模型空间变换到齐次裁剪空间,开发者可以编写程序在这个阶段修改顶点的坐标,诸如流动、摇曳等与顶点位置相关的动画操作都可以实现。
- 值得一提的是,这里仅仅是“信息处理”,还不是真正的着色,可以理解为“为接下来的着色计算提供一些信息”。
2.2 曲面细分着色器(Tessellation Stage)
在这一阶段,程序员可以进行曲面细分操作,看起来就像在原有的图元内加入了更多的顶点。
对于一些有大量曲面的模型,进行曲面细分可以让曲面更加圆润;
如果为这些细分的顶点再准备一些位置信息,那么这些细分的顶点将有助于我们展现一个细节更加丰富的模型。这也是 贴图置换(Displacement Mapping)的基本思路。

2.3 几何着色器(Geometry Shader)

在这个阶段,开发者可以控制GPU对顶点进行增删改操作。
几何着色器与顶点着色器都可以对顶点的坐标进行修改,但几何体着色器并行调用硬件困难,并行程度低,效率和顶点着色器有很大的差距;
如果不是要做顶点增、删这些仅仅能用几何着色器实现的效果,那么 还是用顶点着色器来完成吧。
2.4 投影(Projection)
尽管至此GPU已经在三维空间中做了很多工作,但我们最终是要在一个二维的屏幕上查看我们渲染出来的图像——这就需要在GPU把三维空间映射到二维平面上了。
不过值得注意的是,尽管这个过程叫做“投影”,但与数学上的投影还是有很大区别的,这个阶段中,GPU将顶点从摄像机观察空间==>裁剪空间(又被称为齐次裁剪空间),为之后的剔除过程以及投射到二维平面做准备。
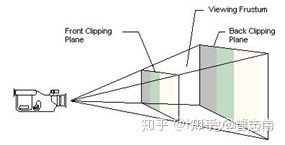
常见的投影方式有:透视投影与正交投影。
2.5 裁剪(不可编程)
裁剪操作的目的就是把摄像机看不到的顶点剔除出去,使他们不被渲染到。判断顶点是否可以免受裁剪也十分简单,只需要满足x,y,z属于[-w,w]
在把不需要的顶点裁剪掉后,GPU需要把顶点映射到屏幕空间,这是一个从三维空间转换到二维空间的操作,更符合大家对“投影”的理解。
对透视裁剪空间来说,GPU需要对裁剪空间中的顶点执行齐次除法(其实就是将齐次坐标系中的w分量除x、y、z分量),得到顶点的归一化的设备坐标(Normalized Device Coordinates, NDC),经过齐次除法后,透视裁剪空间会变成一个x、y、z三个坐标都在[-1,1]区间内的立方体。对于正交裁剪空间就要简单得多,只需要把w分量去掉即可。
此时顶点的x、y坐标就已经很接近于它们在屏幕上所处的位置了,不过还有一个多出来的z分量,不过它也不会被白白丢弃,而是被写入了深度缓冲(z-buffer)中,可以做一些有关于顶点到摄像机距离的计算。
裁剪空间坐标==》归一化设备坐标==》0-1之外的部分裁减掉
2.6 屏幕映射(不可编程)
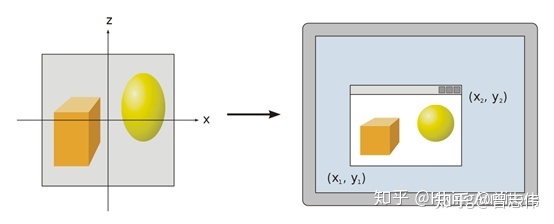
尽管GPU已经得到了顶点的x、y坐标,但他们处于[-1,1]区间中的,GPU还需要进行一定的计算才能把他们映射到我们的1920*1080甚至2560*1440的屏幕。得到的新坐标系称为窗口坐标系,虽然只需要两个坐标把顶点投射到屏幕上,但它仍然是三维的,这个多出来的z值就是在上面算出来的深度。
把三维的几何图元一一映射到二维的屏幕空间上。注意此刻还不是我们肉眼看到的像素
三. 光栅化阶段(Rasterization)
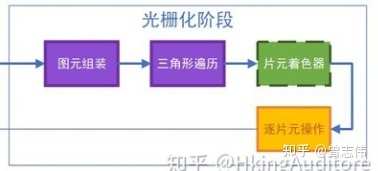
3.1 图元组装(Primitive Assembly)\三角形设置(不可编程)
有些资料把这个过程称为三角形设置(Triangle Setup),不过个人认为叫做Primitive Assembly更为贴切。
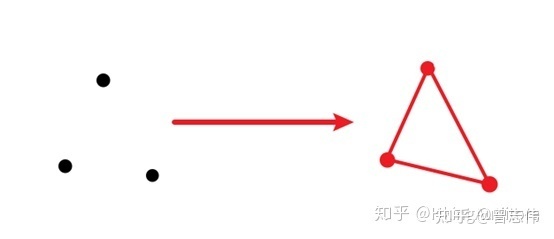
这个过程做的工作就是把顶点数据收集并组装为简单的基本体(线、点或三角形),通俗的说就是把相关的两个顶点“连连看”,有些能构成面,有些只是线,有些甚至没有与之配对的顶点只能当一个“单身狗”。
输出一个三角形的边的数据,给下一个阶段。
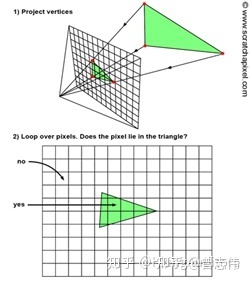
3.2 三角形遍历(Triangle Traversal)(不可编程)
遍历每一个像素,去检查是否被一个三角网格所覆盖,如果覆盖就会生存一个片元。
对于是否覆盖有三种解决方案:
- 常用的有Standard Rasterization(中心点被覆盖即被划入片元)
- Outer-conservative Rasterization(只要被覆盖了,哪怕只有一点也被划入片元)
- Inner-conservative Rasterization(完全被覆盖才会被划入片元)
值得注意的是,片元不是真正意义上的像素,而是包含了很多种状态的集合(譬如屏幕坐标、深度、法线、纹理等),这些状态用于最终计算出每个像素的颜色。

3.3 片元着色器(Fragment Shader)(可编程)
这一阶段被一些资料称为像素着色器(Pixel Shader),不过进行到这一步时片元还不是真正意义上的像素。这是十分重要的一步,它将为每个片元计算颜色,这意味着它们很快就能被我们在屏幕上看见了。
这个阶段是完全可编程的;在收到GPU为这个阶段输入了大量的数据后,程序员可以决定这些片元该着上什么样的颜色。


此外,程序员还可以引入更多的信息计算颜色,包括法线贴图、高度图、糙度图等等。虽然片元着色器可以完成很多重要效果,但它仅可以影响单个片元。也就是说,当执行片元着色器时,它不可以将自己的任何结果直接发送给它附近的片元的。
3.4 逐片元操作(Per-Fragment Operations)(可编程)
在DirectX中,这一步又称作输出合并阶段(Output-Merger)。从两个名字中我们大致可以推测出GPU在这个阶段要做的事情:对每个片元进行操作,将它们的颜色以某种形式合并,得到最终在屏幕上像素显示的颜色。主要的工作有两个:对片元进行测试(Test)并进行合并(Merge)。
测试步骤决定了片元最终会不会被显示出来。在OpenGL中,主要的测试有:裁剪测试(Scissor Test)、透明度测试(Alpha Test)、模板测试(Stencil Test)以及深度测试(Depth Test)。这个阶段是高度可配置的。
裁剪测试(Scissor Test)
在裁剪测试中,允许程序员开设一个裁剪框,只有在裁剪框内的片元才会被显示出来,在裁剪框外的片元皆被剔除。

裁剪测试效果
透明度测试(Alpha Test)
在透明度测试中,允许程序员对片元的透明度值进行检测,仅仅允许透明度值达到设置的阈值后才可以会绘制。在OpenGL3.1后这个API被删除了,但你可以在片元着色器中实现类似的效果。

使用的纹理

透明度测试效果
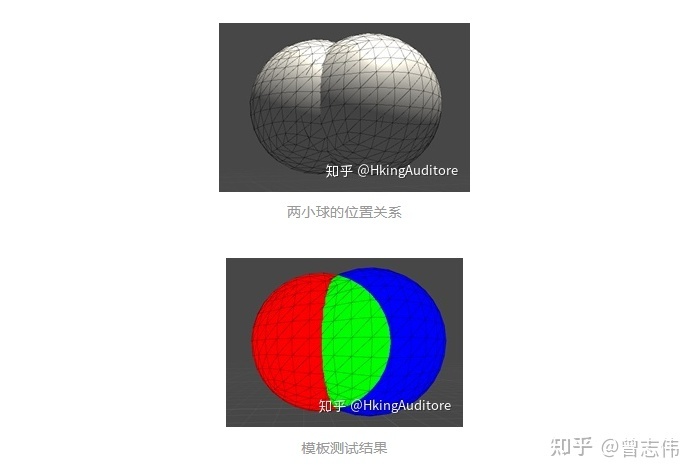
模板测试(Stencil Test)
模板测试是一个相对复杂的测试。在模板测试中,GPU将读取片元的模板值与模板缓冲区的模板值进行比较,如何比较可以由程序员决定,如果比较不通过,这个片元将被舍弃。
譬如图中两个有重叠区域的小球;令左侧小球模板值为3,右侧小球在非重合处模板值为2,重合处模板值为3。现进行模板测试,令左侧小球始终被绘制为红色,令右侧小球满足:模板值与缓冲区相等的绘制为绿色,否则绘制为蓝色。于是我们发现,右侧小球重合处的片元通过了模板测试,被成功绘制为绿色。
深度测试(Depth Test)
深度测试是一个十分重要的测试。在深度测试中,GPU将读取片元的深度值(就是我们前面留下来的坐标z分量)与缓冲区的深度值进行比较,比较方式同样是可以配置的。用通俗的说法解释,深度测试允许程序员设置如何渲染物体之间的遮挡关系。
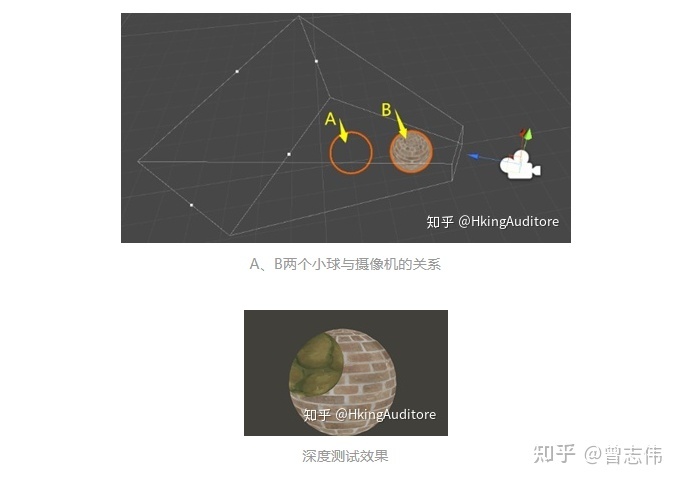
如图,对于摄像机,尽管A小球在B小球的后方,但通过修改深度测试,我们让GPU把A没有被遮挡的部分隐藏了,反而让A被遮挡的部分显示出来的。
大量的被遮挡片元直到深度测试阶段才会被剔除,而在此之前它们同样地被计算,这占用了GPU大量的资源。因此有种优化技术是将深度测试提前(Early-Z)。但这带来了与透明度测试的冲突,例如某个片元甲虽然遮挡了另一个片元乙,但甲却是透明的,GPU应当渲染的是片元乙,这就产生了矛盾,这就是透明度测试会导致性能下降的原因。
合并阶段(merge)
如果一个片元通过了上面所有的测试,那它终于可以来到合并环节了。合并有两种主要的方式,一种是直接进行颜色的替换,另一种是根据不透明度进行混合(Blend),而混合操作同样是可配置的,程序员可以设定是把这两种颜色进行相加、相减还是相乘等等,有点像在PS里的操作。

在A小球与B小球的遮挡部分进行柔和相加操作
在经过上面的层层测试后,片元颜色就会被送到颜色缓冲区。GPU会使用双重缓冲(Double Buffering)的策略,即屏幕上显示前置缓冲(Front Buffer),而渲染好的颜色先被送入后置缓冲(Back Buffer),再替换前置缓冲,以此避免在屏幕上显示正在光栅化的图元。
总结:
1. 应用阶段:这是一个CPU主导阶段,主要做的就是CPU准备数据,把相机看不见的元素剔除,把相机能看到的元素的数据(纹理、材质、着色器等)合批,调用DrawCall,把渲染命令放在命令缓冲区
2. 几何阶段:这是一个GPU主导阶段,主要做的就是GPU从命令缓冲区拿命令,然后开始顶点着色器处理,这个就是shader的顶点着色器,做的就是把顶点坐标从模型坐标转到屏幕坐标。
3. 光栅化阶段:这个阶段,我的理解就是,把顶点着色器传入的数据,组装成一个个的三角形,然后遍历三角形覆盖的网格,生成片元,然后把这些片元传入片元着色器,片元着色器就可以对纹理进行采样,然后和顶点的颜色进行计算、混合,得到最后想输出的每个像素的颜色值。
















 1305
1305











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











