







卷积神经网络硬件加速——INT8数据精度加速
上一专题已介绍了一种通用的卷积神经网络硬件加速方法——Supertile,本文将介绍一种特殊的硬件加速方案,一种INT8数据精度下的双倍算力提升方案。
目前大部分卷积神经网络模型的数据类型都是32-bits单精度浮点型,或者16-bits,但对于实际应用而言,99%和99.5%的网络准确率是没有区别的。所以,对于某些场景下,网络的数据精度使用INT8的数据类型就能较好的胜任工作。
INT8数据硬件加速原理
Xilinx DSP48E2系列的硬核乘法器最大支持27-bits * 18-bits位宽的乘法,而对于INT8数据的卷积运算而言,其只需要使用8-bits * 8-bits的数据位宽,这过多的浪费了DSP资源。
于是乎,我们可以考虑是否可以利用1个DSP资源,同时计算多个INT8数据的卷积。幸运的是,DSP的结构恰好满足我们的要求,可以通过将两个乘数拼接在一个数据中进行计算,完成计算后再将两个结果分离,具体的并行原理见下图:
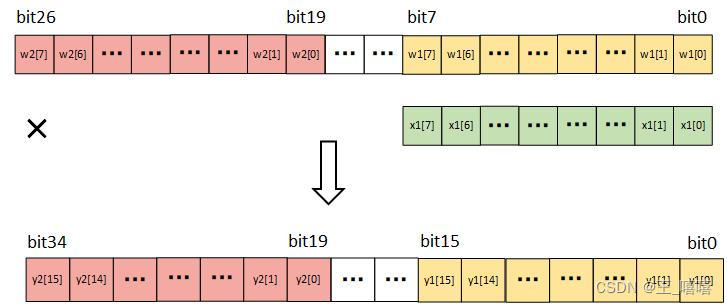
DSP的两个预加法器端口A、D最小位宽是27-bits,而两个8-bits数相乘最大位宽为16-bits,所以第二个权重放在高于16-bits的位置就可以避免低位乘法溢出带来的数据紊乱,具体DSP结构图在Supertile专题中有展示:FPGA在卷积神经网络中的双倍算力应用——Supertile技术分析。
为保证后续DSP级联完成累加功能,高位乘积和低位乘积间还需空余部分数据位保证累加不会发生加法溢出导致的错误。所以将权重w1放在低八位,权重w2放置高八位,中间留出11-bits的空档。
通过如此拼接数据,可以在一个DSP的低8-bits和高8-bits中分别完成两个通道的卷积操作。如果使用的是Xilinx DSP48E2型号的DSP,结果中两个数据会存放在[15:0]和[34:19],中间存在3-bits的空挡,将DSP前后级联正好满足16次的累加操作的空间需求,如果再结合Supertile加速方法,最多可以在一个系统时钟周期内完成4次INT8数据精度的卷积运算。
最后本文给出一个不同加速方案的性能对比:
| 方案 / 性能 | 原始FP32卷积 | Supertile-FP32卷积 | Supertile-INT8卷积 |
|---|---|---|---|
| 1X | 2X | 4X |
其中性能表示一个时钟周期内方案能完成的卷积个数,由于本文仅关注加速效率,所以将不对量化后的网络精度等进行比对。
搜索关注我的微信公众号【IC墨鱼仔】,获取我的更多IC干货分享!














 61
61











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









