







来源:时序人
本文约2000字,建议阅读5分钟本文介绍一篇KDD 2024中的时序表示学习方法文章。本文介绍一篇KDD 2024中的时序表示学习方法文章。研究者提出了 TSDE,一种用于时间序列表示学习(TSRL)的新型自监督学习(SSL)框架。TSDE 是同类中的第一个,它有效地利用了一个扩散过程,该过程基于一种创新的双正交 Transformer 编码器架构,该架构具有交叉机制,并采用了一种独特的IIF掩码策略。研究者在多种时间序列分析任务上进行了全面的实验,表明 TSDE 在处理高缺失率和各种复杂性的多变量时间序列(MTS)数据时显示出显著的结果,从而验证了其在捕捉复杂 MTS 动态方面的有效性。

【论文标题】
Self-Supervised Learning of Time Series Representation via Diffusion Process and Imputation-Interpolation-Forecasting Mask
【论文地址】
https://arxiv.org/abs/2405.05959
【论文源码】
https://github.com/llcresearch/TSDE
论文背景
时间序列表示学习专注于为各种时间序列建模任务生成信息丰富的表示。时间序列表示学习中的传统自监督学习方法主要分为四类:重构性、对抗性、对比性和预测性,每种方法都面临对噪声敏感和复杂数据细微差别敏感的共同挑战。
最近,基于扩散的方法已显示出先进的生成能力。然而,它们主要针对插补和预测等特定应用场景,在利用扩散模型进行通用时间序列表示学习方面存在空白。
本文介绍的这一工作——时间序列扩散嵌入(TSDE)填补了这一空白。TSDE 使用插补-插值-预测(IIF)掩码将时间序列数据分割为观测部分和掩码部分。它应用了一个可训练的嵌入函数,该函数具有带有交叉机制的双重正交 Transformer 编码器,用于处理观测部分。研究者训练了一个以嵌入为条件的反向扩散过程,旨在预测添加到掩码部分的噪声。TSDE 方法的提出,旨在通过创新的自监督学习框架来解决现有方法的局限性,提高时间序列数据表示学习的性能。
模型方法
TSDE 的核心是无监督的扩散过程,它模拟了通过逐步添加噪声将数据转换为接近标准高斯分布的过程。这个过程包括前向和反向两个部分:前向过程中,数据逐渐被噪声化;反向过程中,则尝试通过去噪来恢复原始数据。TSDE 的关键在于利用观测到的数据部分来预测和恢复被掩蔽或缺失的数据部分。
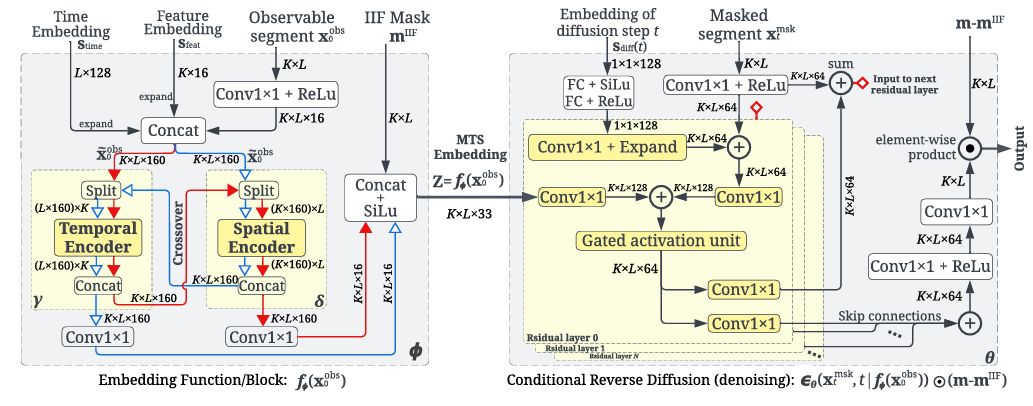 图1:TSDE架构包括一个嵌入函数(左)和一个条件反向扩散块(右)时间和空间编码器实现为一层Transformer
图1:TSDE架构包括一个嵌入函数(左)和一个条件反向扩散块(右)时间和空间编码器实现为一层Transformer
为了实现这一点,TSDE 采用了一种新颖的 IIF 掩码策略,该策略能够模拟数据填充、插值和预测任务。通过这种方式,模型被训练来预测时间序列中缺失或未来的值,从而学习到能够适用于多种下游任务的通用表示。
TSDE 的另一个重要组成部分是嵌入函数,它由双正交变换器编码器和交叉机制组成。这个函数不仅处理输入的观测数据,还整合了时间嵌入、特征嵌入和 IIF 掩码等额外信息。通过这种方式,TSDE 能够生成具有丰富信息的时间序列表示,这些表示可以直接用于异常检测、聚类、分类等任务。
在训练过程中,TSDE 通过最小化预测噪声和实际噪声之间的差异来优化模型参数。这种方法允许模型在没有外部标注的情况下自主学习,从而减少了对大量标注数据的依赖。
一个显著的优势是 TSDE 在推理时的速度。通过简化条件反向扩散过程,TSDE 显著提高了模型的运算效率,使其在实际应用中更具吸引力。
训练好的模型可以在两种场景中使用:
(1)嵌入函数作为一个独立的组件,可以用来生成全面的多变量时间序列表示,适用于各种下游应用,包括异常检测、聚类和分类。
(2)当与训练好条件反向扩散过程结合使用时,模型能够预测多变量时间序列数据中的缺失值(用于填充和插值)以及未来值(用于预测)。
在第二种场景中,与现有的基于扩散的方法相比,可以实现显著的加速。
实验效果
研究者在六个任务(填充、插值、预测、异常检测、分类和聚类)上的对 TSDE 框架进行全面实验评估,此外也对推理效率、消融研究和嵌入可视化进行了额外分析。
在数据填充、插值和预测任务中,TSDE 与现有的最先进方法相比,展现出了显著的性能提升。具体来说,在 PhysioNet 和 PM2.5 数据集上进行的填充任务中,TSDE 在 CRPS、MAE 和 RMSE 等指标上均取得了最佳性能,特别是在处理高比例的缺失数据时。插值任务的结果也表明,TSDE 能够有效处理时间序列中的不规则时间戳间隔。在预测任务中,TSDE 在诸如 Electricity、Solar、Taxi、Traffic 和 Wiki 等多个真实世界数据集上同样展现了优异的性能。
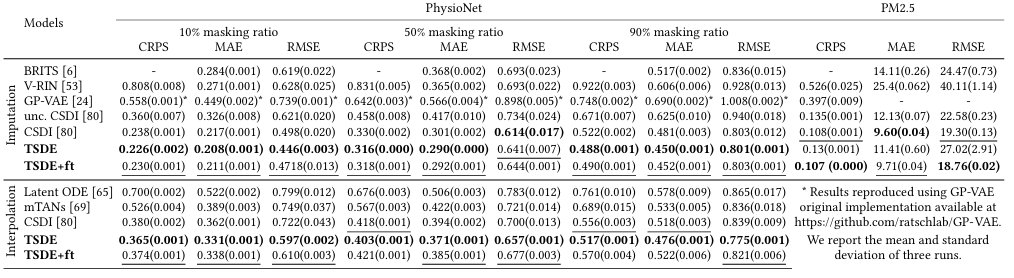
表1:概率性多任务学习(MTS)插补和插值基准测试结果

表2:在电力预测任务上的结果
在异常检测方面,TSDE 利用重建误差作为异常评判标准,其性能在多个基准数据集上超越了其他方法,接近于利用大型预训练语言模型的 GPT4TS。
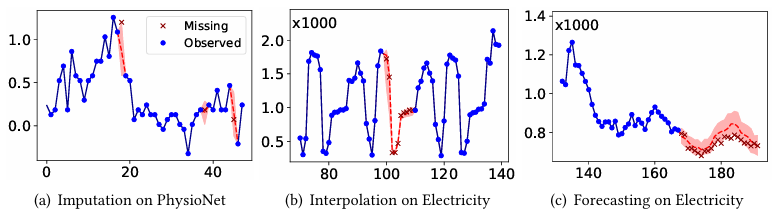
图2:预测值与真实值的比较,包括(a)插补(缺失10%),(b)插值,和(c)预测
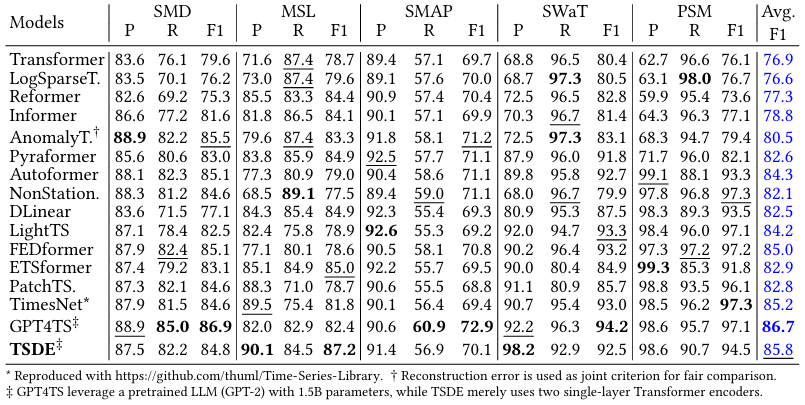
表3:异常检测:基线结果。分数越高表示性能越好;最佳和第二佳结果分别以粗体和下划线表示
分类任务的实验结果显示,TSDE 在 PhysioNet 数据集上进行的二元分类任务中达到了与最先进方法相媲美的 AUROC 分数,这说明 TSDE 学习到的嵌入能够有效地捕捉时间序列数据的动态变化,从而进行有效的分类。

表4:在PhysioNet上的分类性能
聚类任务的实验则证明了 TSDE 生成的嵌入可以直接用于聚类分析,而无需进行数据填充。通过 UMAP 降维和 DBSCAN 聚类,TSDE 能够揭示数据内在的结构,即使在数据存在大量缺失的情况下。
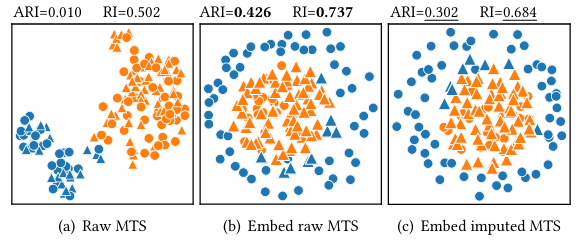
图3:聚类结果
此外,TSDE 还展现出了显著的推理速度优势。由于模型采用了高效的双正交变换器编码器和简化的反向扩散过程,TSDE 在执行填充、插值和预测任务时的速度比现有方法快了十倍。
编辑:王菁
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU

















 2015
2015

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









