







YOLOv10没想到出来的如此之快,作为一名YOLO的爱好者,以YOLOv5和YOLOv8的经验,打算出一套从数据集装备->环境配置->训练->验证->目标追踪全系列教程。请大家多多点赞和收藏!!!
系列文章:
YOLOv10最详细全面讲解1- 目标检测-准备自己的数据集(YOLOv5,YOLOv8均适用)
本人基于YOLOv10最详细全面讲解1- 目标检测-准备自己的数据集(YOLOv5,YOLOv8均适用)继续往下进行,主要包括环境搭建、训练自己的数据集。
1.环境搭建
1.1官方下载源码
官网地址:YOLOv10 gitbub官网源码
利用魔法进入GitHub官网之后点击下载源码压缩包(这里针对小白使用download,当然也可以使用git clone命令)
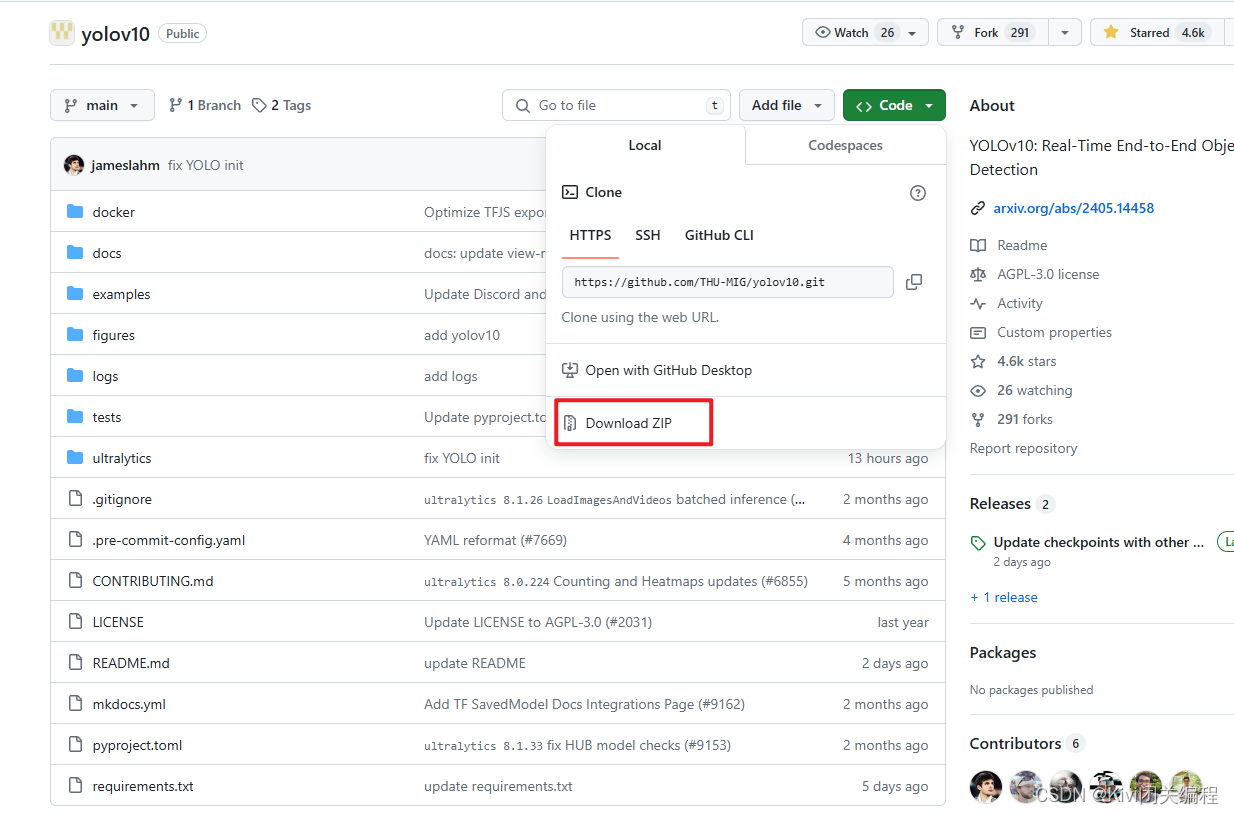
下载之后解压放入平时存放代码的目录中:

2. 配置conda环境
目前官网只针对了conda环境。关于如何安装conda这里就不赘述,请各位同学自行去找相关博客学习安装。
打开Anaconda Powershell Prompt程序,我这里因为装的是miniconda,所以后面带了个miniconda3,这不重要。

输入命令回车:conda create -n yolov10 python=3.9
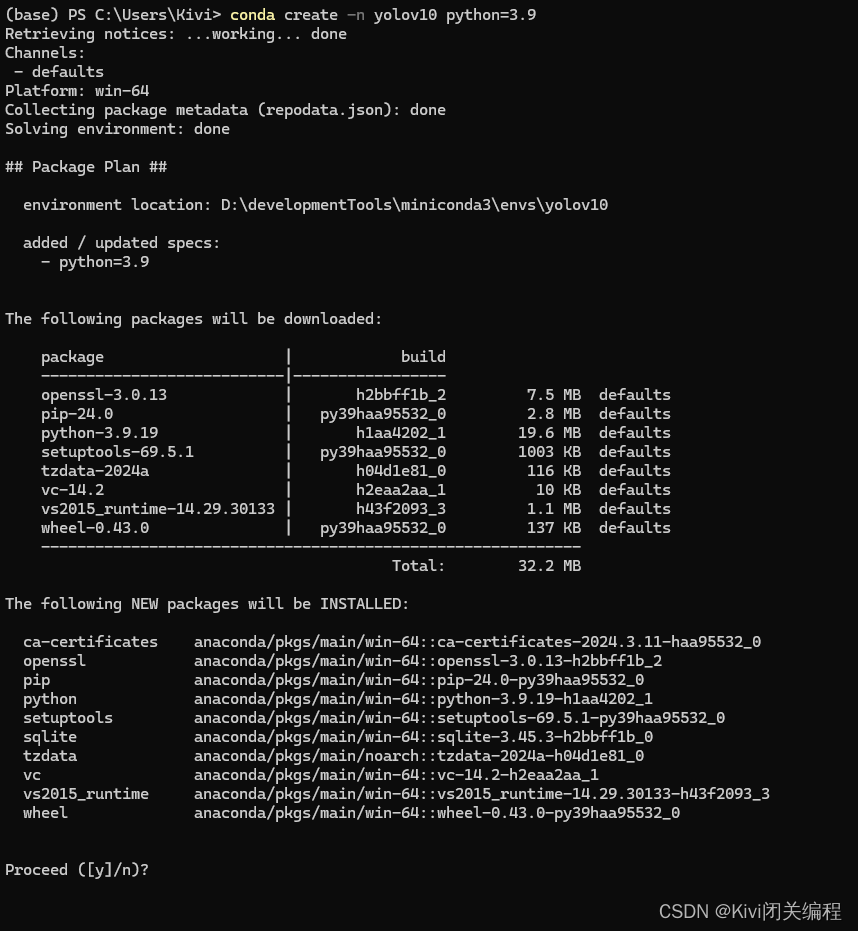
输入y,继续安装,出现如下信息,表示安装成功:

输入conda activate yolov10,切换至刚刚创建的yolov10环境

利用cd命令切换至第一步中下载解压后的源代码所在目录:
cd D:\projects\pycharm\yolov10
请改成你自己的文件夹目录

然后输入:pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/自动安装所有的依赖库tips:必须先按照上一步切换到下载解压后的源代码所在目录才行
同时会自动根据你是否有GPU自动选择pytorch版本进行按照,这里不需要自己去选择pytorch和cuda按照,非常良心
等待下载库,看个人网速问题,快的话也需要几分钟才行,慢的话可能几个小时
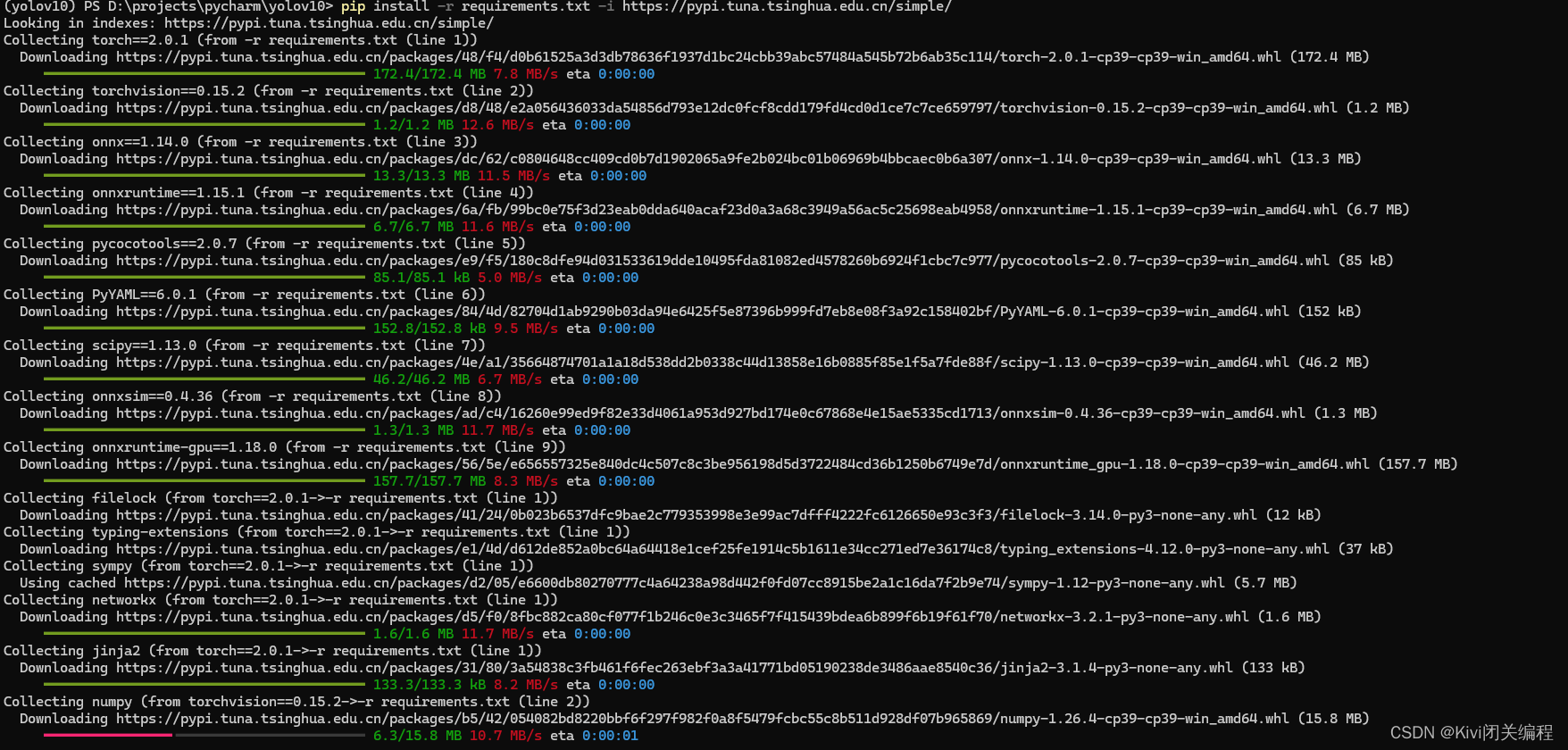
出现如下信息,则表示下载完成
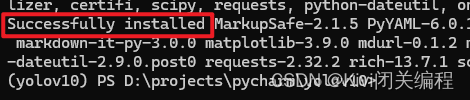
继续输入:pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple/安装配置环境
出现如下信息表示安装成功

至此!yolov10的conda虚拟环境搭建全部成功!!
2.训练自己的数据集
请先基于本人前置博客YOLOv10最详细全面讲解1- 目标检测-准备自己的数据集(YOLOv5,YOLOv8均适用)进行!!!!!
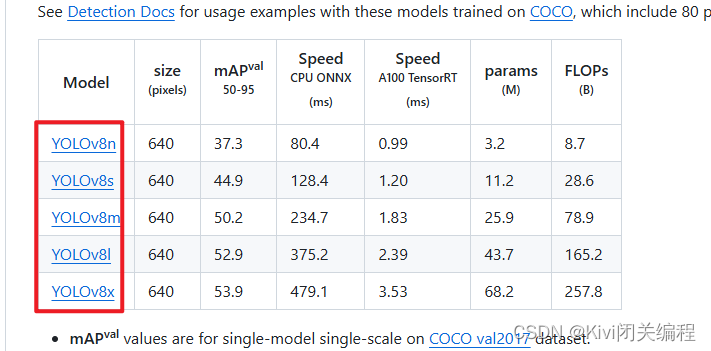
2.1训练之前需要先去YOLOv8官网下载yolov8的预训练权重文件,不然可能训练不了
利用魔法进入yolov8官网
建议将所有yolov8的权重文件都下载下来,以免后续你训练yolov10过程中出现问题。当然也可以根据自己情况单独下载,例如:如果你只用yolov10n那么你只需要下载yolov8n的权重文件,如果你只用yolov10l那么你只需要下载yolov8l的权重文件
将下载的yolov8的预训练权重文件放入yolov10的文件夹中,如图:
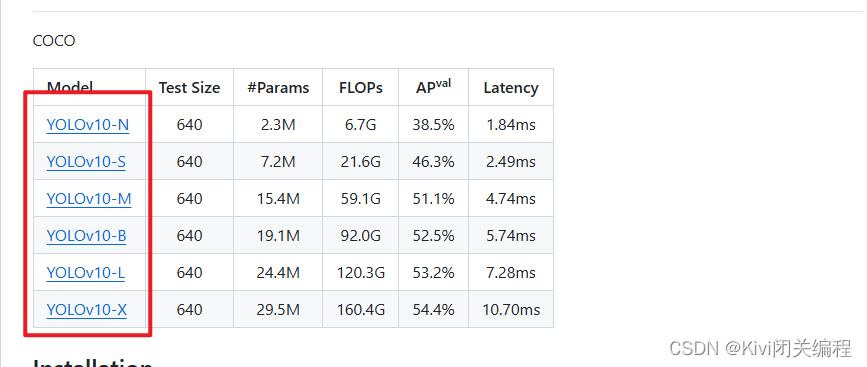
下载YOLOv10的预训练权重
进入YOLOv10官网下载预训练权重,这里以YOLOv10-N为例
下载之后放入yolov10代码中新建的weights目录:
利用命令行命令训练:
yolo detect train data=D:\\ModelsDatas\\YOLO_datasets\\data.yaml model=yolov10n.pt epochs=5 batch=4 imgsz=640 device=cpu
上述各个参数解释如下,请根据自己的情况修改。
- yolo detect train:表示进行目标检测的训练,这几个词不需要改
- data=coco.yaml:指定你自己的数据集yaml文件,这里需要改成我上篇文章中指出的data.yaml文件。
- model=weights/yolov10n.pt: 指定下载的yolov10预训练权重文件,我这里指定了上述所说。
- epochs=5:设置训练轮次,可以先设置一个5轮或者10轮,测试看看,顺利进行再设置大一点进行下一步训练。
- batch=4:设置训练集加载批次,主要是提高训练速度,具体得看你的显卡或者内存容量。如果显存大,则可以设置大一些。或许训练再详细讲解如何设置
- imgsz=640:设置图片长度,为640像素,这里建议不修改,也可以设置成1280或者其他,会影响训练速度和精度。
- device=0:指定训练设备,如果没有gpu,则令device=cpu,如果有一个gpu,则令device=0,有两个则device=0,1以此类推进行设置。
自行修改上述参数,输入命令进行训练:成功运行:
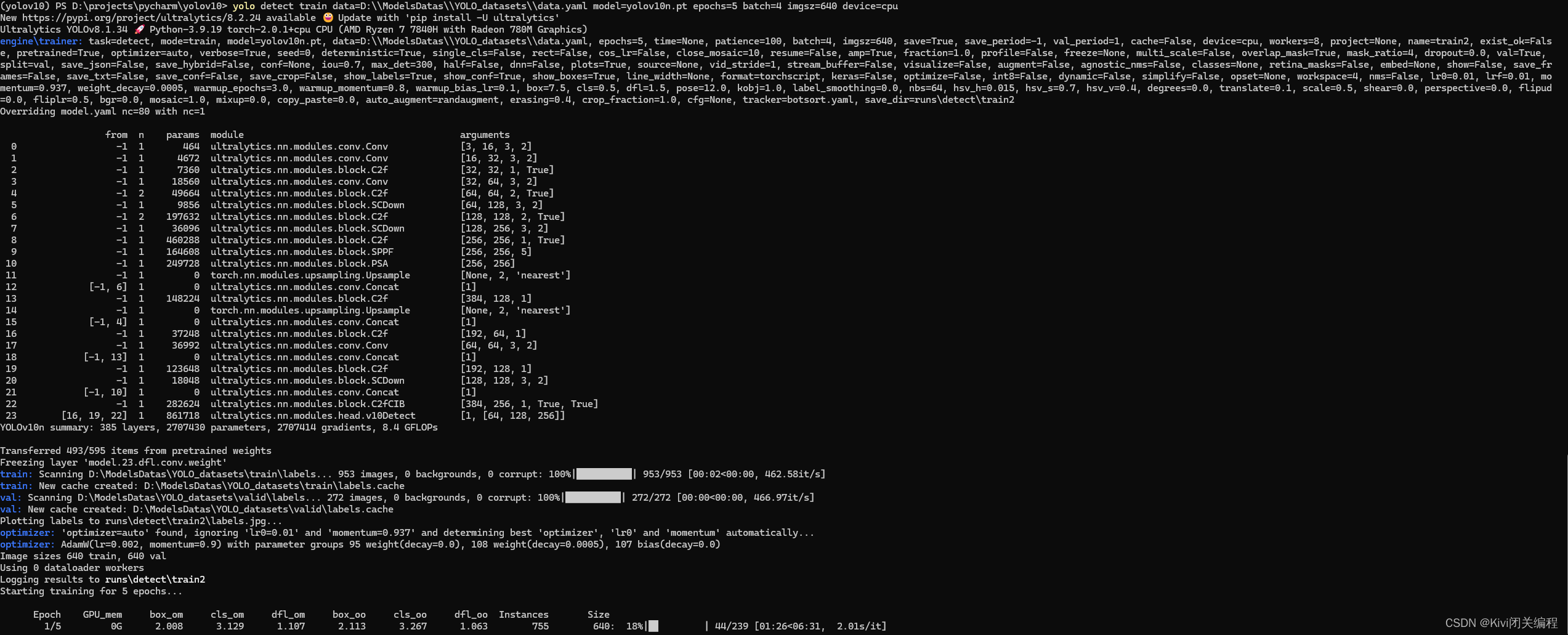
成功运行之后就可以设置epoch=200或者500等进行真正的训练了。
使用代码训练
from ultralytics import YOLOv10
model = YOLOv10('yolov10n.pt')
model.train(data='data.yaml', epochs=20, batch=64, imgsz=640,device=[1,2,3,4])
参数意思和上述命令行中的参数一样
当然部分小伙伴可能没有我上述过程这么顺利。如果出现各种报错,大家请在评论区提出,我会针对大家问题一一解答。我将知无不尽,为大家解惑帮助!!还请各位小伙伴多多点赞收藏,支持新人博主,你们的认可是我最大的动力!


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











