







前两天,和大家分享了阿里最新开源的推理模型:
比肩满血DS,阿里新王 QwQ-32B 本地部署,Ollma/vLLM 实测对比
有朋友反馈:模型还是太大了。。。
其实,很多情况下,我们只需解决一些特定场景的问题,完全没必要搞这么大的模型。
指令微调了解下?
最近,DeepSeek算命大师很火,今日分享,以算命为例,用 Unsloth 来微调一个垂直领域的推理模型。
1. Unsloth 简介
关于大模型指令微调,笔者之前有过分享:
【大模型指令微调实战】小说创作,一键直达天池挑战赛Top50
当时微调用的 peft 框架。
不得不感叹,这个领域技术更新太快,最新出的 Unsloth 极大加速了模型微调的速度,同时降低显存占用。
开源四个月,GitHub 已斩获 34k star。
老规矩,简短介绍下 Unsloth 亮点:
- 所有内核均基于 OpenAI 的 Triton 重写,大幅提升模型训练速度,降低显存占用。
- 实现中不存在近似计算,模型训练的精度损失为零。
- 支持绝大多数主流的 NVIDIA GPU 设备,CUDA 计算能力 7.0+。
- 支持 4bit 和 16bit QLoRA / LoRA 微调(基于 bitsandbytes)
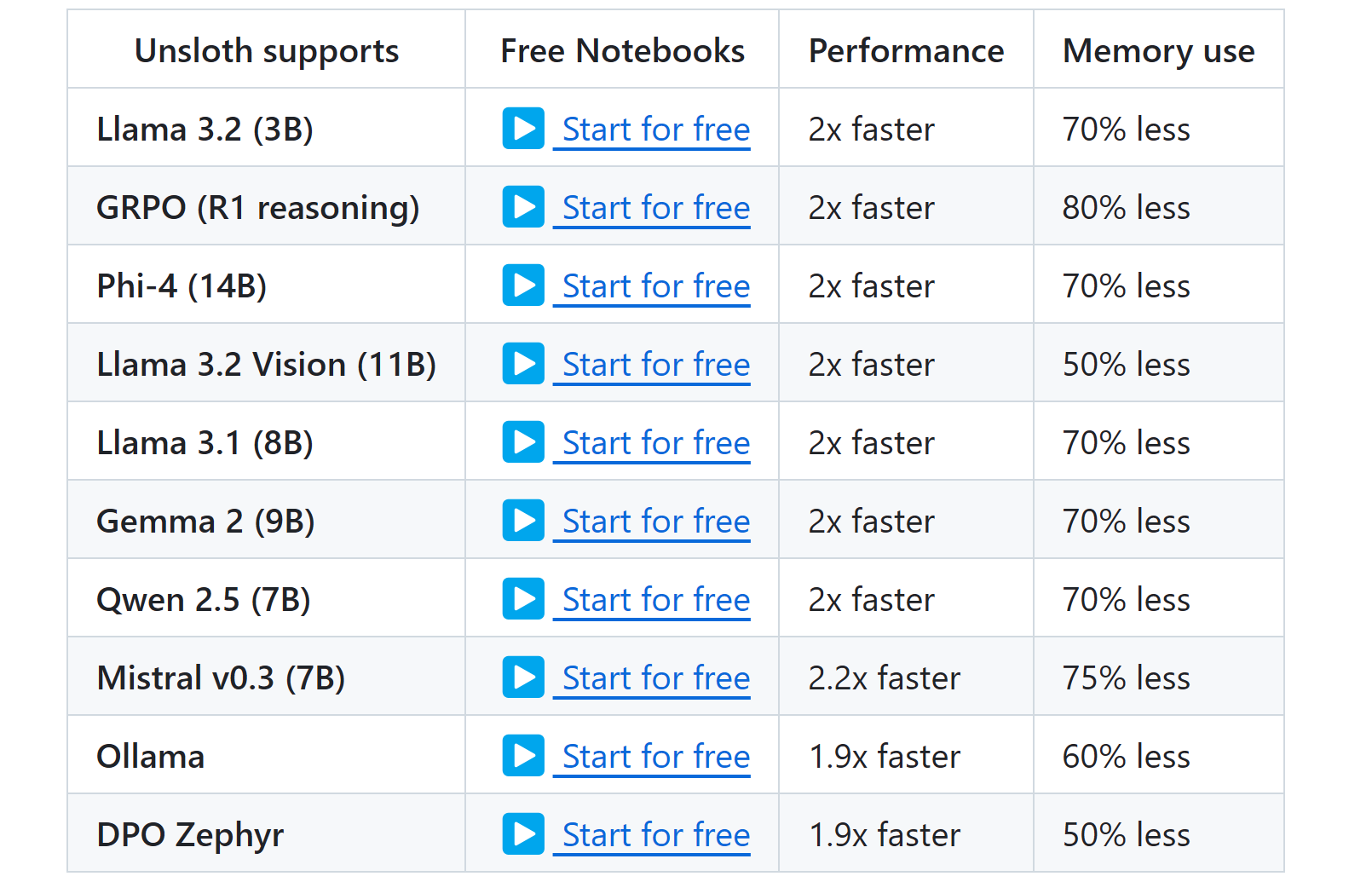
来看看惊人的加速比和显存节省:
2. Unsloth 微调教程
2.1 Unsloth 安装
pip 一键安装:
pip install unsloth
2.2 模型准备
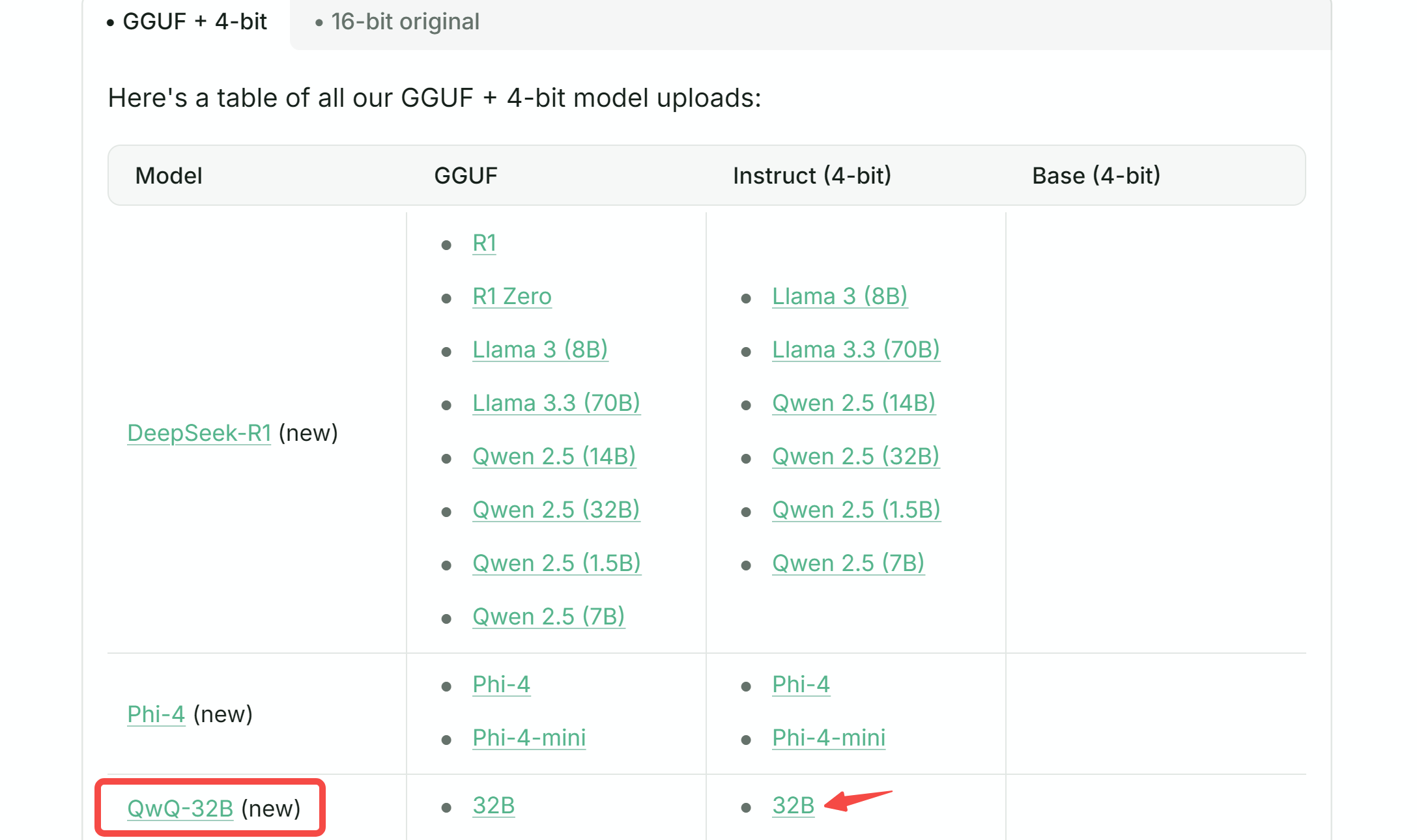
这里查看所有支持的模型列表:
https://docs.unsloth.ai/get-started/all-our-models
最新的 QwQ-32B 也已支持,包括量化版和原始模型:
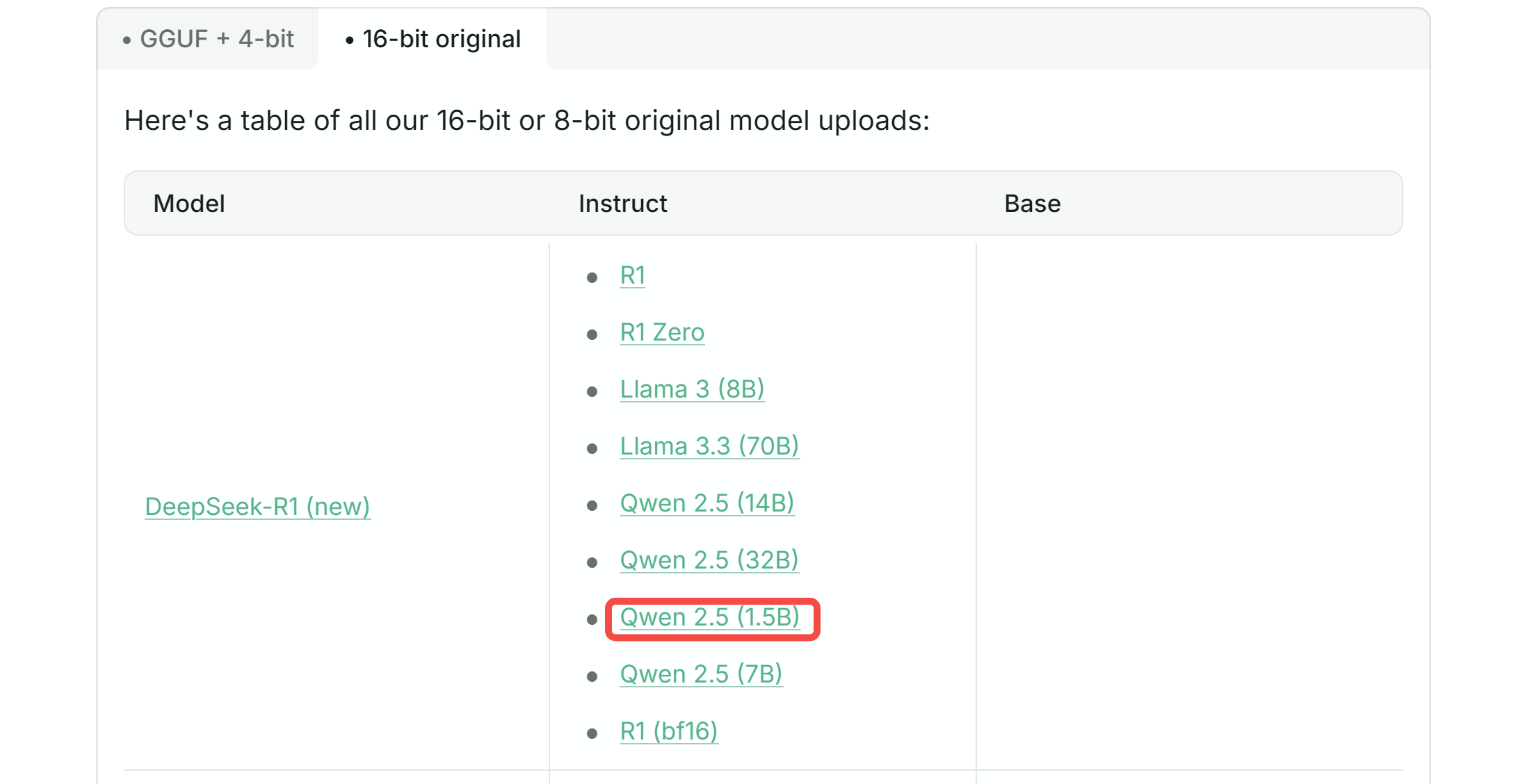
为兼顾到绝大部分同学,本次微调选用 DeepSeek 蒸馏版 Qwen2.5 1.5B:
首先,从 huggingface 下载模型:(国内伙伴可引入镜像)
export HF_ENDPOINT=https://hf-mirror.com # 引入镜像地址
huggingface-cli download --resume-download unsloth/DeepSeek-R1-Distill-Qwen-1.5B --local-dir ./ckpts/qwen-1.5b
2.3 数据集准备
数据是燃料,是模型微调成功的关键。
就像是给孩子补课的教材,这些数据往往需要审核(标注),以便模型有样学样。
比如,如果要让模型学会算命,就得准备一些标注好的命理学知识。
开源社区已有这样的数据集:
https://huggingface.co/datasets/Conard/fortune-telling
不妨先下载来试试:
export HF_ENDPOINT=https://hf-mirror.com # 引入镜像地址
huggingface-cli download --repo-type dataset --resume-download Conard/fortune-telling --local-dir data/fortune-telling
注:采用 huggingface-cli 下载数据集时,加上 --repo-type dataset
数据集格式如下:
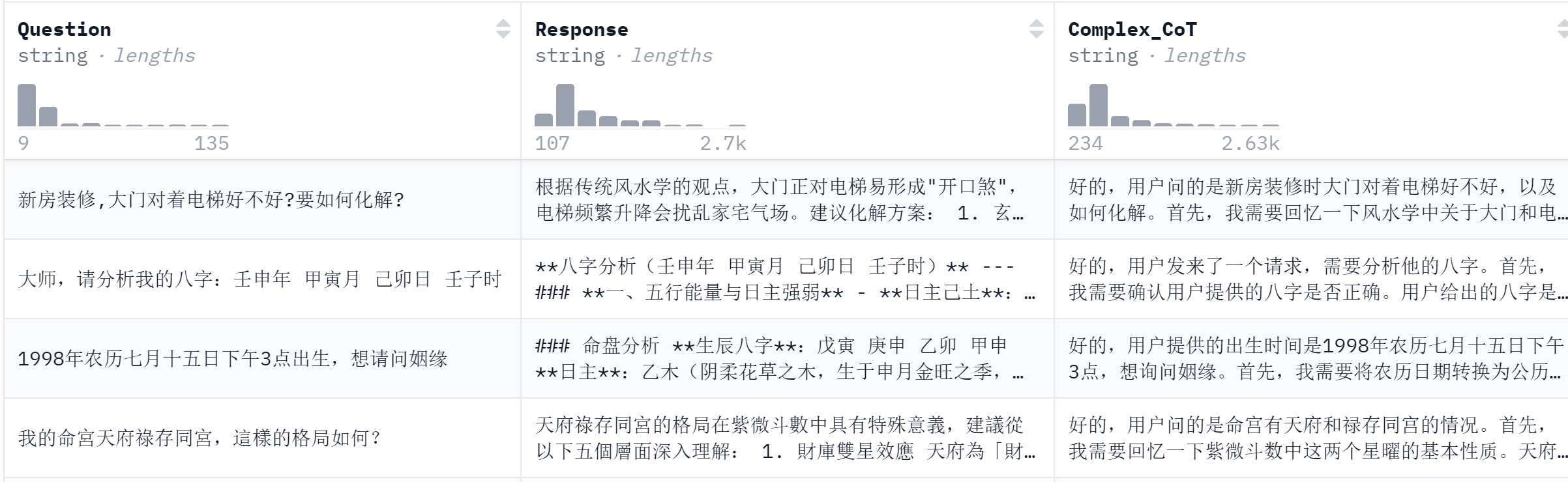
OK,一切准备就绪,下面开始炼丹!
2.4 模型微调
模型微调,只需按照以下 8 步走~
step 1:引入依赖
from unsloth import FastLanguageModel, is_bfloat16_supported
from transformers import TrainingArguments
from trl import SFTTrainer
from datasets import load_dataset
step 2:加载模型
max_seq_length = 8192 # 模型处理文本的最大长度
# 加载模型
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "ckpts/qwen-1.5b",
max_seq_length = max_seq_length,
dtype=None, # 自动检测合适的类型
load_in_4bit = True,
# device_map="balanced" # 多卡训练时均衡分布模型权重,默认为sequential
)
step 3:加载数据集
# 定义训练数据格式化字符串模板
train_prompt_style="""请遵循指令回答用户问题。
在回答之前,请仔细思考问题,并创建一个逻辑连贯的思考过程,以确保回答准确无误。
### 指令:
你是一位精通八字算命、紫微斗数、风水、易经卦象、塔罗牌占卜、星象、面相手相和运势预测等方面的算命大师。
请回答以下算命问题。
### 问题:
{}
### 回答:
<think>{}</think>
{}
"""
# 加载数据集
dataset = load_dataset("data/fortune-telling", split="train")
def formatting_data(examples):
questions = examples["Question"]
cots = examples["Complex_CoT"]
responses = examples["Response"]
texts = []
for q, c, r in zip(questions, cots, responses):
text = train_prompt_style.format(q, c, r) + tokenizer.eos_token
texts.append(text)
return {"text": texts}
dataset = dataset.map(formatting_data, batched=True)
可以打印一行数据,输出看看:
Generating train split: 207 examples [00:00, 1319.25 examples/s]
Dataset size: 200 ['Question', 'Response', 'Complex_CoT']
step 5:定义 LoRA
# 添加 LoRA 权重
model = FastLanguageModel.get_peft_model(
model,
r = 16, # Rank of the LoRA matrix
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj",], # Layers to apply LoRA to
lora_alpha = 16, # LoRA alpha value
lora_dropout = 0, # Supports any, but = 0 is optimized,防止过拟合,0 表示不drop任何参数
bias = "none", # Supports any, but = "none" is optimized
use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context
random_state = 3407,
use_rslora = False, # We support rank stabilized LoRA
loftq_config = None, # And LoftQ
)
step 6:定义 trainer
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
packing = False, # Can make training 5x faster for short sequences.
args = TrainingArguments(
per_device_train_batch_size = 2, # 每个GPU上的batch size
gradient_accumulation_steps = 4, # 梯度累积步数
warmup_steps = 10,
# max_steps = 200, # 最大训练步数
num_train_epochs=3, # 训练轮数 和 max_steps 二选一
learning_rate = 2e-4, # 学习率,默认值是 2.0e-5
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 2,
output_dir = "outputs",
optim = "adamw_8bit",
seed = 3407,
),
)
step 7:开始训练
train_stats = trainer.train()
Unsloth 会根据加载的模型和设备情况自动选择 GPU 数量。
如果默认 device_map="sequential",只有当单卡显存不够时,才占用其他卡。
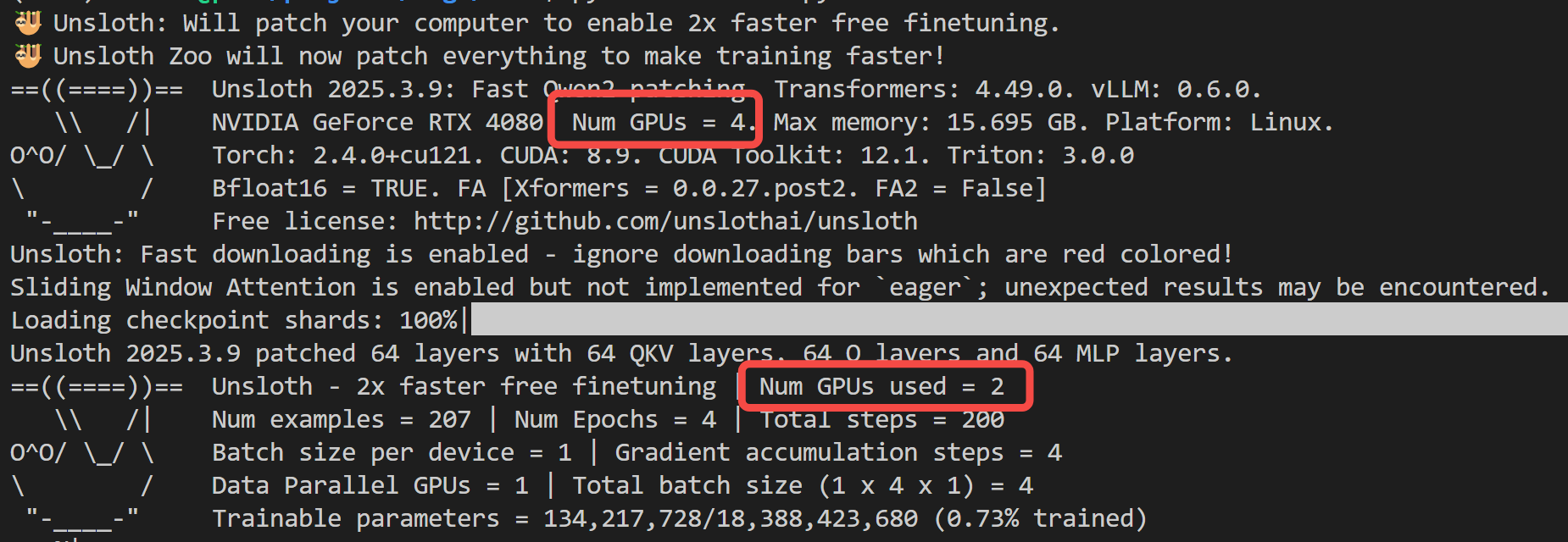
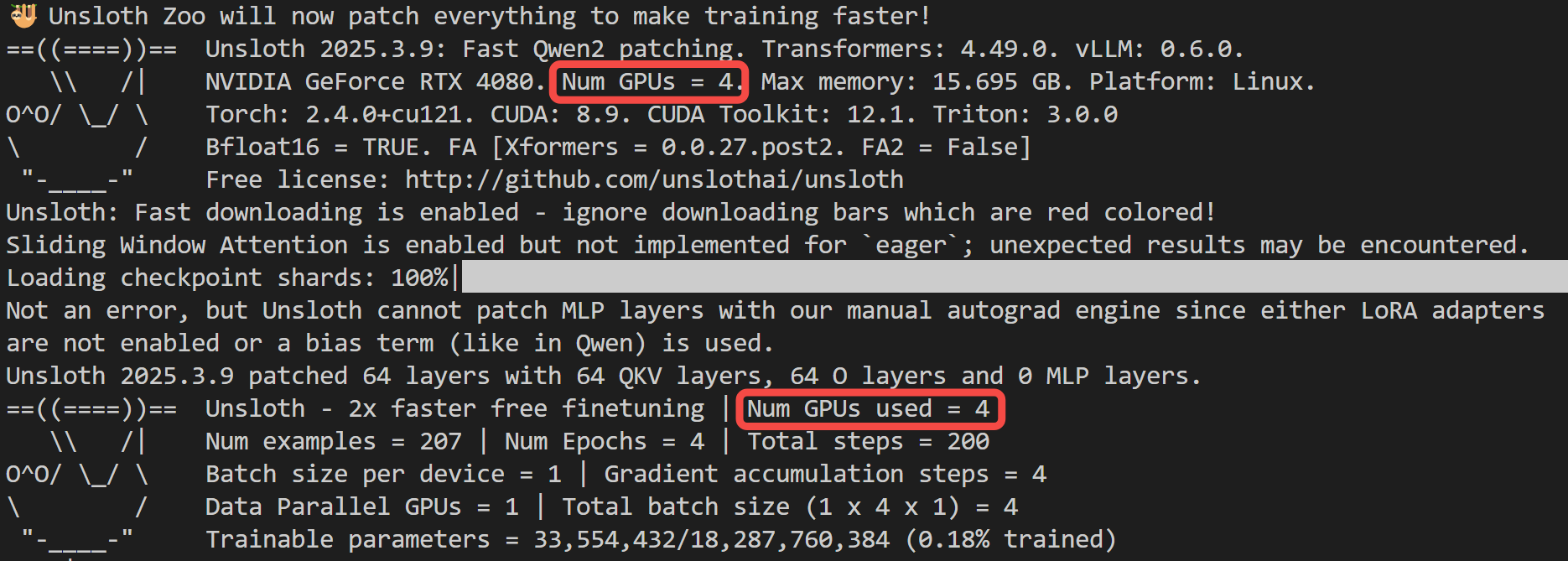
如果设定 device_map="balanced",会占用所有卡,并均衡分布模型权重:
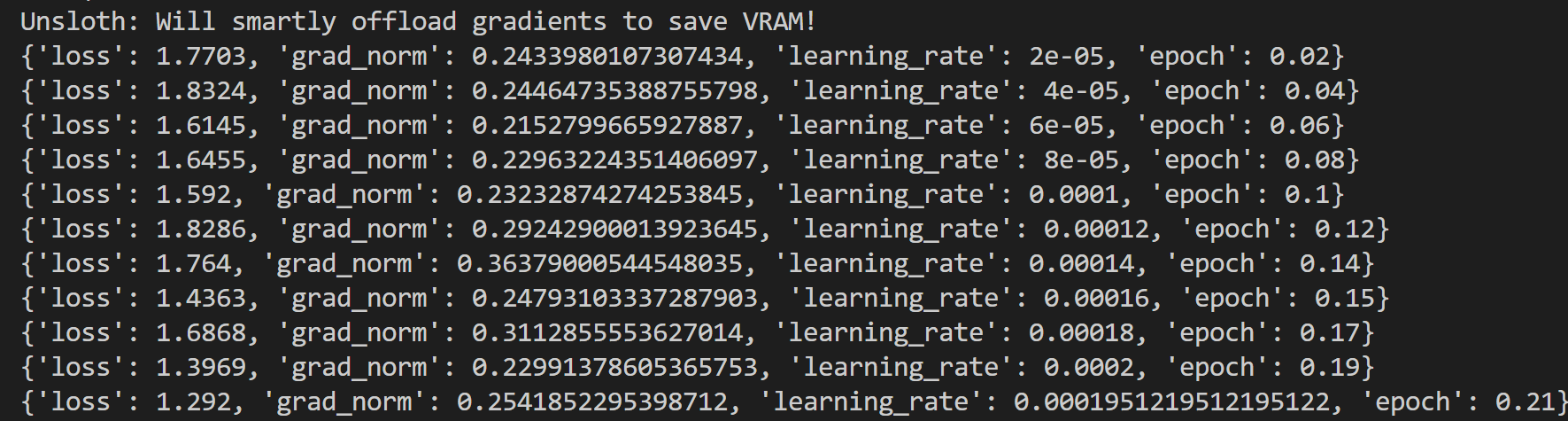
看到损失下降,说明成功开始训练:
step 8:模型保存
最后,别忘了保存训练好的模型权重:
model.save_pretrained("ckpts/lora_model")
tokenizer.save_pretrained("ckpts/lora_model")
注:这里只会保存 LoRA 权重,在adapter_config.json会指定原始模型位置:
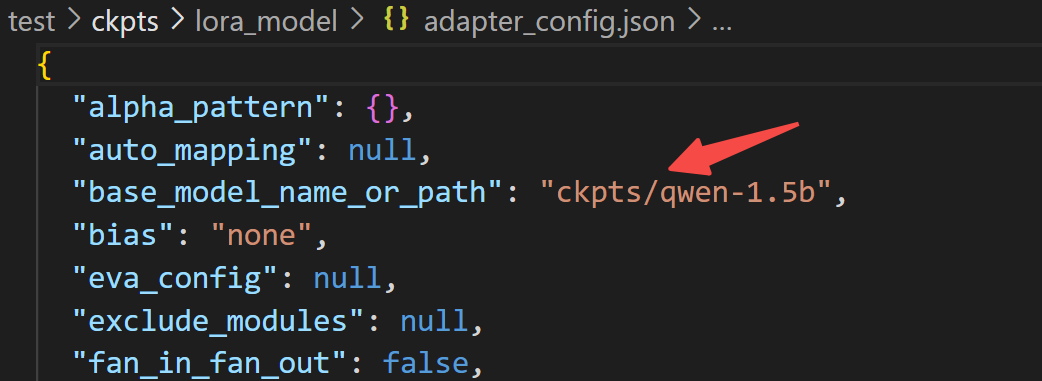
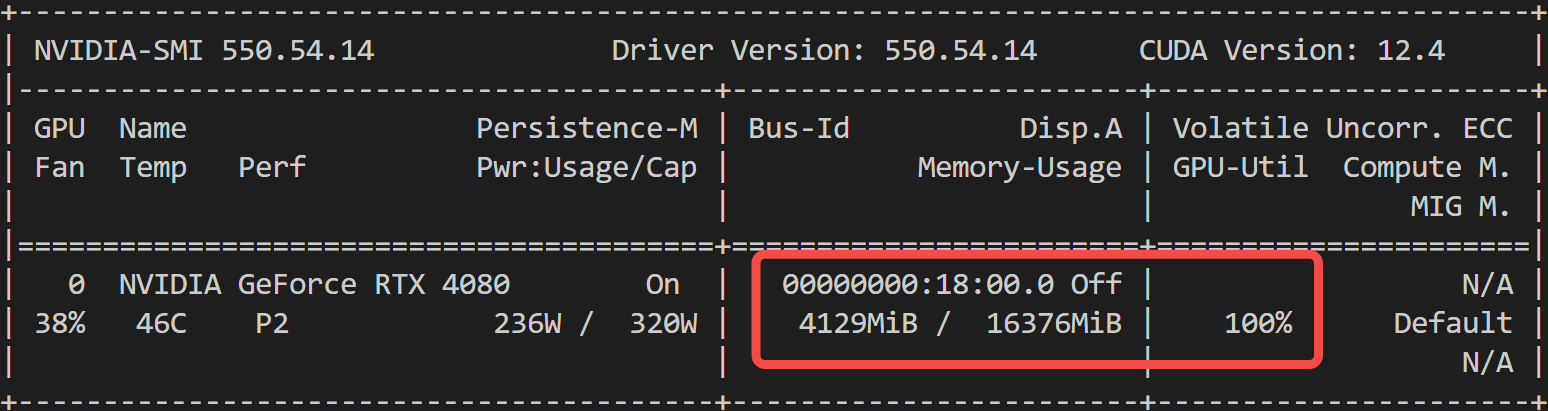
至此,我们成功走完了模型微调之旅,需要完整代码的小伙伴,文末自取!
对于 qwen2.5 1.5B而言,4G 显存即可开启微调:
2.5 模型测试
模型测试代码如下:
# 加载模型
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "ckpts/lora_model",
max_seq_length = max_seq_length,
load_in_4bit = True,
)
FastLanguageModel.for_inference(model)
question = '1995年七月初十生,今年是2025年,了解未来五年的运势'
inputs = tokenizer([prompt_style.format(question)], return_tensors='pt', max_length=max_seq_length).to("cuda")
outputs = model.generate(inputs['input_ids'], attention_mask=inputs['attention_mask'], max_length=max_seq_length, use_cache=True)
answer = tokenizer.batch_decode(outputs, skip_special_tokens=True)[0]
print(answer)
注:如果单卡放不下模型权重,会报错,因为模型权重切分了,但 inputs 并没有切分,因此可考虑采用
vLLM 推理。
2.6 vLLM 推理
不了解 vLLM 推理 的小伙伴,可翻看上篇:比肩满血DS,阿里新王 QwQ-32B 本地部署,Ollma/vLLM 实测对比
首先,我们要将微调后的模型保存为 GGUF 格式:
model.save_pretrained_gguf("ckpts/merged", tokenizer, quantization_method="q4_k_m")
Unsloth 会自动下载编译 llama.cpp 进行格式转换:

过程中先转成 BF16,然后再进行 4bit 量化,权重大小分别为 3G 和 1G:

转换成功后,一键开启 vLLM 推理:
vllm serve ckpts/merged/unsloth.Q4_K_M.gguf --api-key 123 --port 3002
写在最后
本文分享了开源大模型微调工具 Unsloth,并通过一个简单例子,带大家走完了微调全流程。
如果对你有帮助,欢迎点赞收藏备用。
本文微调+测试完整代码已上传云盘,需要的朋友,公众号后台回复微调自取!
为方便大家交流,新建了一个 AI 交流群,公众号后台「联系我」,拉你进群。

















 827
827

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









