










一则时序违例分析

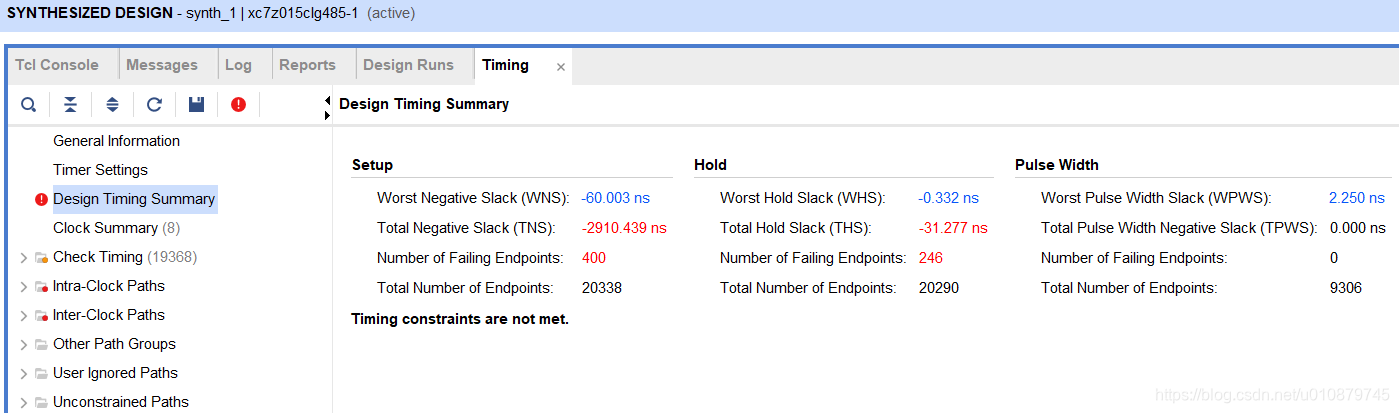
时序出现60ns的违例

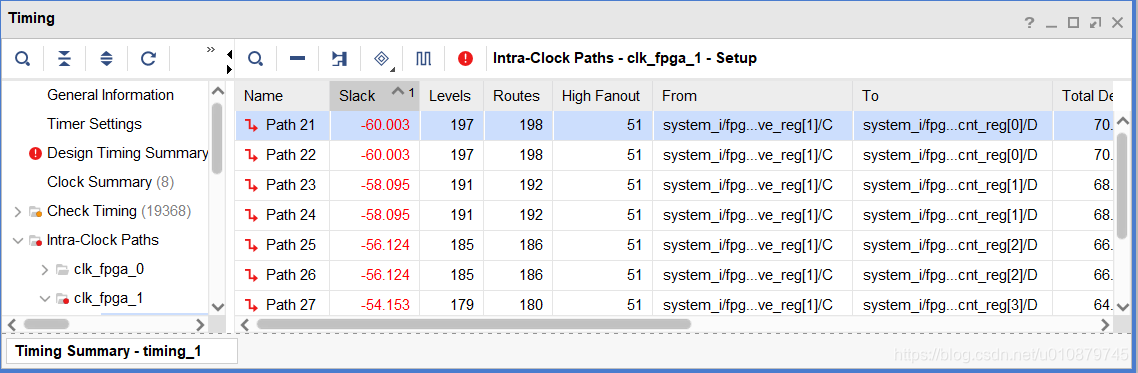
高达197级逻辑级数
这条路径兜了大半个地球。
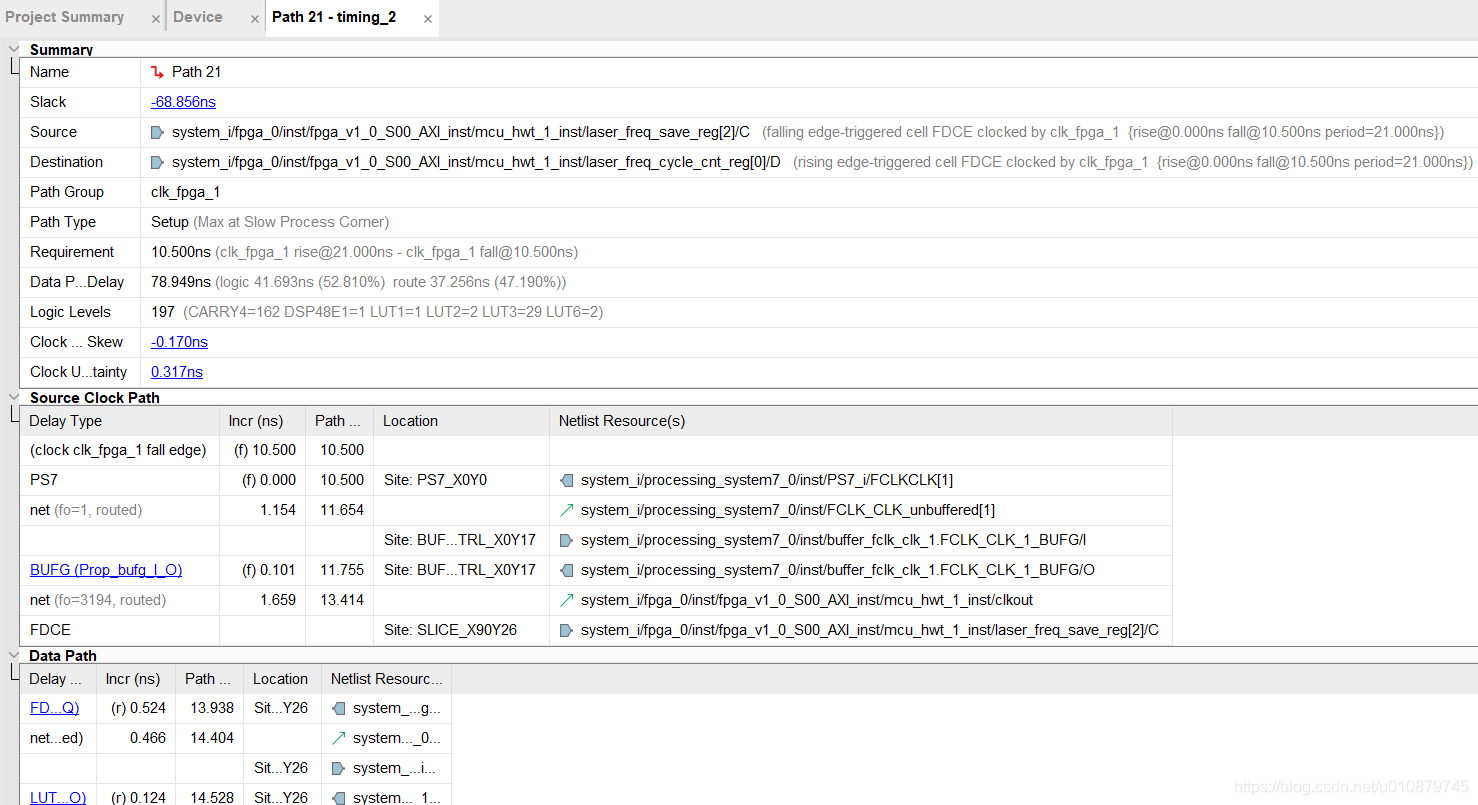
查Path21具体路径信息
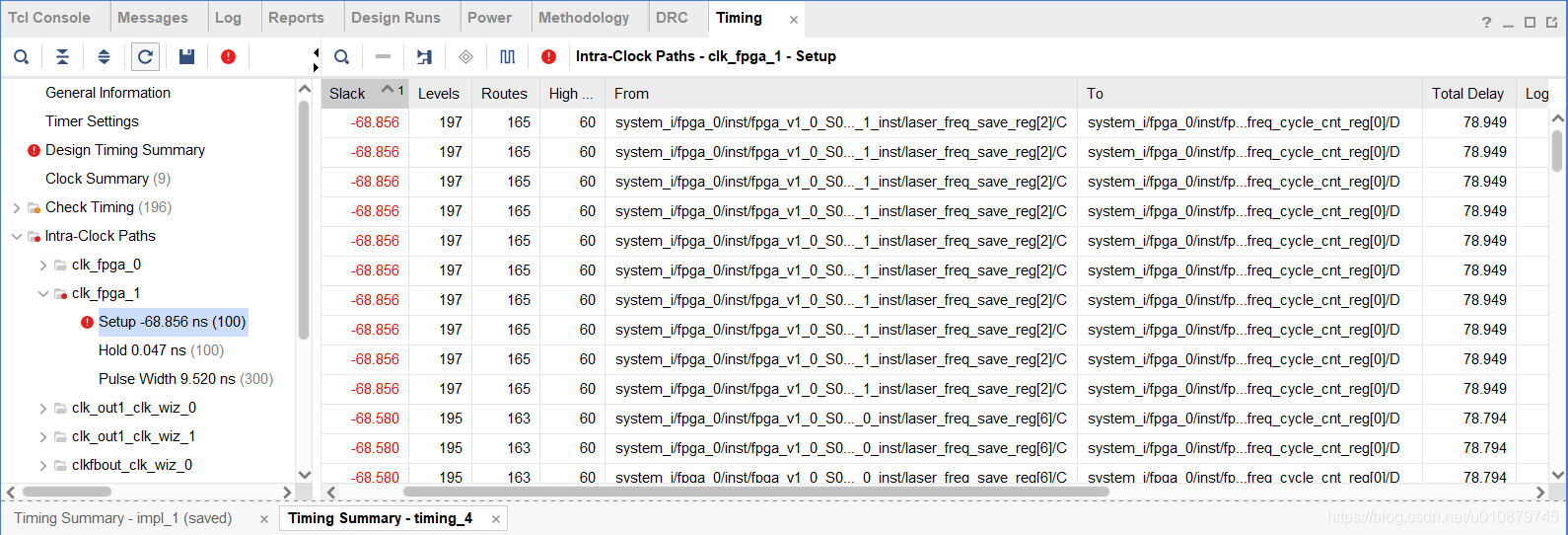
 具体Path21违例信息如下:
具体Path21违例信息如下:
report_timing -max_paths 100 -nworst 100
Slack (VIOLATED) : -60.003ns (required time - arrival time)
Source: system_i/fpga_0/inst/fpga_v1_0_S00_AXI_inst/mcu_hwt_0_inst/laser_freq_save_reg[1]/C
(falling edge-triggered cell FDCE clocked by clk_fpga_1 {rise@0.000ns fall@10.500ns period=21.000ns})
Destination: system_i/fpga_0/inst/fpga_v1_0_S00_AXI_inst/mcu_hwt_0_inst/laser_freq_cycle_cnt_reg[0]/D
(rising edge-triggered cell FDCE clocked by clk_fpga_1 {rise@0.000ns fall@10.500ns period=21.000ns})
Path Group: clk_fpga_1
Path Type: Setup (Max at Slow Process Corner)
Requirement: 10.500ns (clk_fpga_1 rise@21.000ns - clk_fpga_1 fall@10.500ns)
Data Path Delay: 70.085ns (logic 42.146ns (60.135%) route 27.939ns (39.865%))
Logic Levels: 197 (CARRY4=163 DSP48E1=1 LUT1=1 LUT2=1 LUT3=29 LUT6=2)
Clock Path Skew: -0.145ns (DCD - SCD + CPR)
Destination Clock Delay (DCD): 1.224ns = ( 22.224 - 21.000 )
Source Clock Delay (SCD): 1.415ns = ( 11.915 - 10.500 )
Clock Pessimism Removal (CPR): 0.047ns
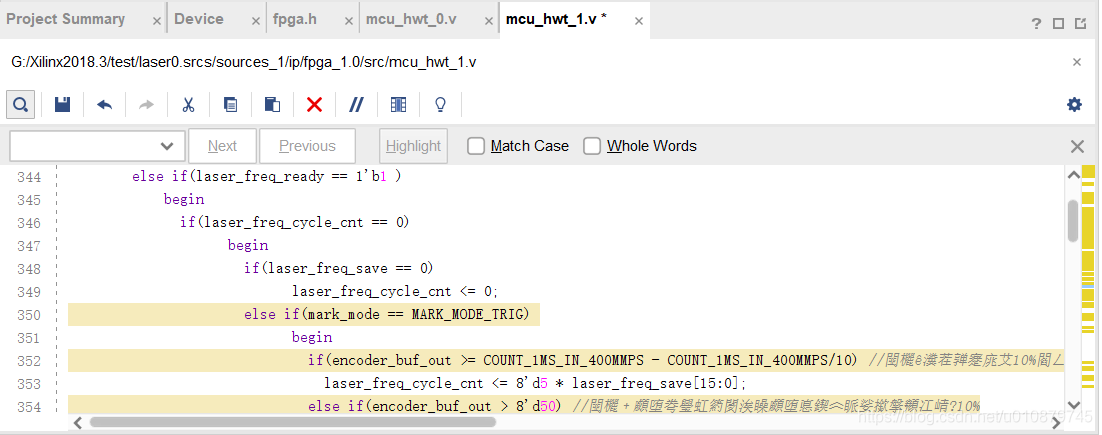
再看前100个都是laser_freq_save_reg到freq_cycle_cnt_reg的路径时延
查找到laser_freq_save_reg到freq_cycle_cnt_reg有关系的语句
begin
if(encoder_buf_out_wire >= 8'd180)
laser_freq_cycle_cnt <= (8'd5 * laser_freq_save[15:0]*COUNT_1MS_IN_400MMPS)/200;
// laser_freq_cycle_cnt <= laser_freq_cycle_cnt_5;
else if(encoder_buf_out_wire > 8'd50) //10%
laser_freq_cycle_cnt <= (8'd5 * laser_freq_save[15:0]*COUNT_1MS_IN_400MMPS)*9/(10*encoder_buf_out);
// laser_freq_cycle_cnt <= 900*laser_freq_save[15:0]/encoder_buf_out; //encoder_buf_out 12bit width, value from 50 to 180 2 ^10=256*4 value 5 - 20
// laser_freq_cycle_cnt <= laser_freq_cycle_cnt_10;
else if(encoder_buf_out_wire > 8'd25) //1/4 20*freq
laser_freq_cycle_cnt <= (8'd5 * laser_freq_save[15:0]*COUNT_1MS_IN_400MMPS)/50;
// laser_freq_cycle_cnt <= laser_freq_cycle_cnt_20;
else //1/5 20*freq
laser_freq_cycle_cnt <= (8'd5 * laser_freq_save[15:0]*COUNT_1MS_IN_400MMPS)/40;
// laser_freq_cycle_cnt <= laser_freq_cycle_cnt_25;
end
源程序神操作,对fpga_1用IP核
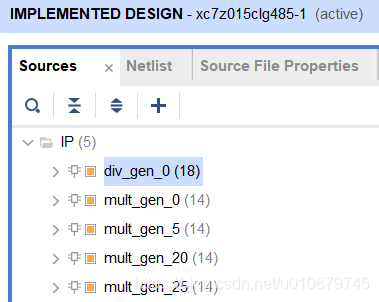
立马见效
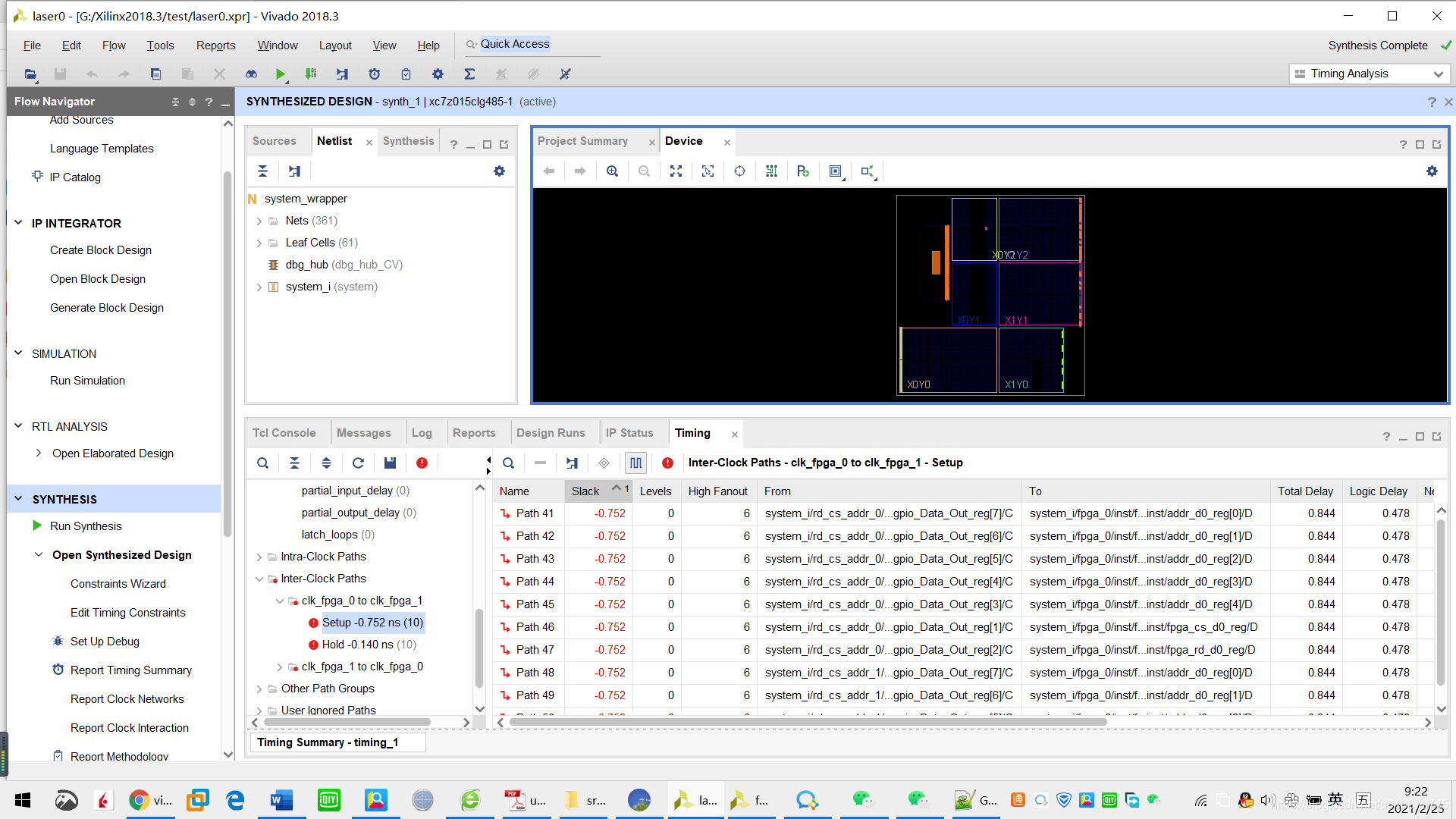
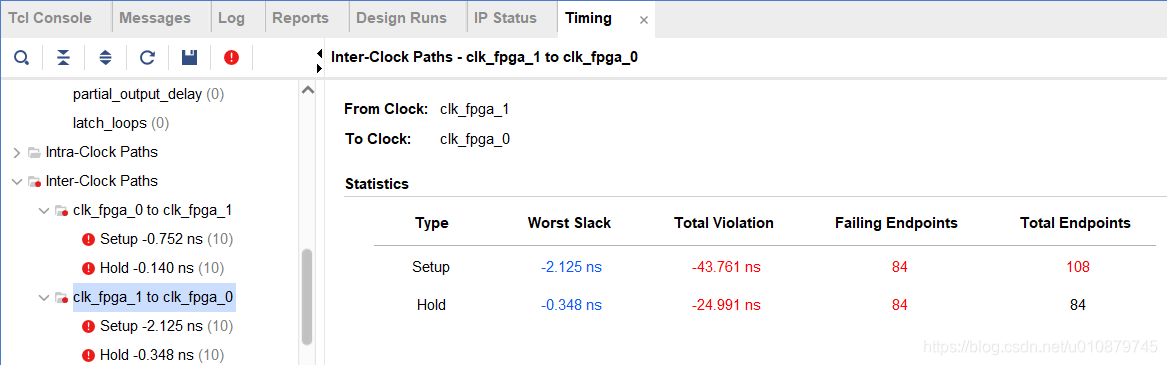
对fpga_0注释掉乘除语句,看到时间明显不同,再次确认重大违例是乘除所引起的。
加入级联乘除法器时,注意输入输出需要分别设为不同的类型,输入为wire, 输出为register
reg low_tvalid;
reg high_tvalid;
wire out_tvalid;
wire [23:0] div1_temp;
wire [23:0] div2_temp;
div_gen_900 div_gen_900_1 (
.aclk(clkout), // input wire aclk
.s_axis_divisor_tvalid(low_tvalid), // input wire s_axis_divisor_tvalid
.s_axis_divisor_tdata(encoder_buf_out), // input wire [7 : 0] s_axis_divisor_tdata
.s_axis_dividend_tvalid(high_tvalid), // input wire s_axis_dividend_tvalid
.s_axis_dividend_tdata(900), // input wire [15 : 0] s_axis_dividend_tdata
.m_axis_dout_tvalid(out_tvalid), // output wire m_axis_dout_tvalid
.m_axis_dout_tdata(div1_temp) // output wire [23 : 0] m_axis_dout_tdata
);
mult_gen_16_8 mult_gen_16_8_1 (
.CLK(clkout), // input wire CLK
.A(laser_freq_save[15:0]), // input wire [15 : 0] A
.B(div2_temp), // input wire [7 : 0] B
.P(laser_freq_cycle_cnt_10) // output wire [23 : 0] P
);
assign div2_temp = div1_temp;
此例中采用乘除IP核 ,解决了重大的时序违例。
常用查看时序命令:
report_design_analysis -max_paths 50 -setup
report_timing -max_paths 50 -setup -input_pins -name worstSetupPaths
report_timing -max_paths 100 -slack_less_than 0 -name worse_100_setup
• High logic delay percentage (Logic Delay)
○ Are there many levels of logic? (Logic Levels)
○ Are there any constraints or attributes that prevent logic optimization? (Don’t Touch, Mark
Debug)
○ Does the path include a cell with high logic delay such as RAMB or DSP?
○ Is the path requirement too tight for the current path topology? (Requirement)
• High net delay percentage (Net Delay)
○ Are there any high fanout nets in the path? (High Fanout, Cumulative Fanout)
○ Are the cells assigned to several Pblocks that can be placed far apart? (PBlocks)
○ Are the cells placed far apart? (Bounding Box Size, Clock Region Distance)
○ For SSI devices, are there nets crossing SLR boundaries? (SLR Crossings)
○ Are one or several net delay values a lot higher than expected while the placement seems
correct? See the section on Congestion.
• Missing pipeline register in a RAMB or DSP cell (when present in the path)
○ Check the path to see if pipeline register is enabled for RAMBs or DSP cells
• High skew (<-0.5 ns for setup and >0.5 ns for hold) (Clock Skew)
○ Is it a clock domain crossing path? (Start Point Clock, End Point Clock)
○ Are the clocks synchronous or asynchronous? (Clock Relationship)
○ Is the path crossing I/O columns? (IO Crossings)
Slow Corner Model: 最高温度,最低电压下的模型
Fast Corner Model: 最低温度,最高电压下的模型
优化时序的方法
1. 插入寄存器
最基本的策略:在组合逻辑中插入寄存器(Add Register Layers),通过引入时延与增大电路面积来提升电路速度。流水线设计就是将组合逻辑系统地分割,并在各个部分(分级)之间插入寄存器,并暂存中间数据的方法。
用下面的语句避免优化掉
(dont_touch = “true”) reg vga_valid1;
(122条消息) FPGA中的流水线设计(Pipeline Design)_yc16032399的博客-CSDN博客_fpga流水线设计 https://blog.csdn.net/yc16032399/article/details/100833296
一个 8bit 流水线加法器的小例子
module add8(
a,
b,
c);
input [7:0] a;
input [7:0] b;
output [8:0] c;
assign c[8:0] = {1'd0, a} + {1'd0, b};
endmodule
采用两级流水线:第一级低 4bit,第二级高 4bit,所以第一个输出需要 2 个时钟周期有效,后面的数据都是 1 个周期之后有效。
module adder8_2(
clk,
cin,
cina,
cinb,
sum,
cout);
input clk;
input cin;
input [7:0] cina;
input [7:0] cinb;
output [7:0] sum;
output cout;
reg cout;
reg cout1; //插入的寄存器
reg [3 :0 ] sum1 ; //插入的寄存器
reg [7 :0 ] sum;
reg [3:0] cina_reg;
reg [3:0] cinb_reg;//插入的寄存器
always @(posedge clk) //第一级流水
begin
{cout1 , sum1} <= cina[3:0] + cinb [3:0] + cin ;
end
always @(posedge clk)
begin
cina_reg <= cina[7:4];
cinb_reg <= cinb[7:4];
end
always @(posedge clk) //第二级流水
begin
{cout ,sum[7:0]} <= {{1'b0,cina_reg[3:0]} + {1'b0,cinb_reg[3:0]} + cout1 ,sum1[3:0]} ;
end
endmodule
2. GUI界面【Max Fanout】或用语句限制fanout
Fanout,即扇出,指模块直接调用的下级模块的个数,如果这个数值过大的话,在FPGA直接表现为net delay较大,不利于时序收敛。
这个选项,能够使XST自动实现寄存器复制。在综合时,通过这个选项为所有寄存器都加上扇出的限制,一旦寄存器的扇出大于设置的值,XST会自动进行寄存器复制。
max_fanout属性
在代码中可以设置信号属性,将对应信号的max_fanout属性设置成一个合理的值,当实际的设计中该信号的fanout超过了这个值,综合器就会自动对该信号采用优化手段,常用的手段其实就是寄存器复制。属性设置如下代码所示:
(* max_fanout = “3” *)reg signed [15:0] din_d;

3. 并行结构
把串行改成并行。最典型的就是乘法器了。
作为一个16bit的乘法器,最省资源的就是等待16个clock出结果,也可以是设计成面积最大但是出来结果速度最快的,只需要一个周期就可以出来结果。
组合电路设计策略:提升组合逻辑的并行度,缩短门延时。
两种实现乘法器的方法:串行乘法器和流水线乘法器。https://blog.csdn.net/messi_cyc/article/details/79108463
1)串行乘法器
两个N位二进制数x、y的乘积用简单的方法计算就是利用移位操作来实现。
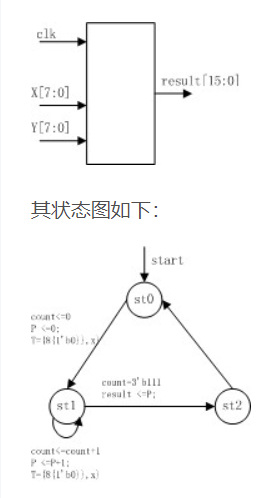
缺点:乘法功能是正确的,但计算一次乘法需要8个周期,因此可以看出串行乘法器速度比较慢、时延大 。
优点:该乘法器所占用的资源是所有类型乘法器中最少的,在低速的信号处理中有广泛的使用。
2)流水线乘法器
一般的快速乘法器通常采用逐位并行的迭代阵列结构,将每个操作数的N位都并行地提交给乘法器。但是一般对于FPGA来讲,进位的速度快于加法的速度,这种阵列结构并不是最优的。所以可以采用多级流水线的形式,将相邻的两个部分乘积结果再加到最终的输出乘积上,即排成一个二叉树形式的结构,这样对于N位乘法器需要log2(N)级来实现,
一个8位乘法器,其原理图如下图所示:
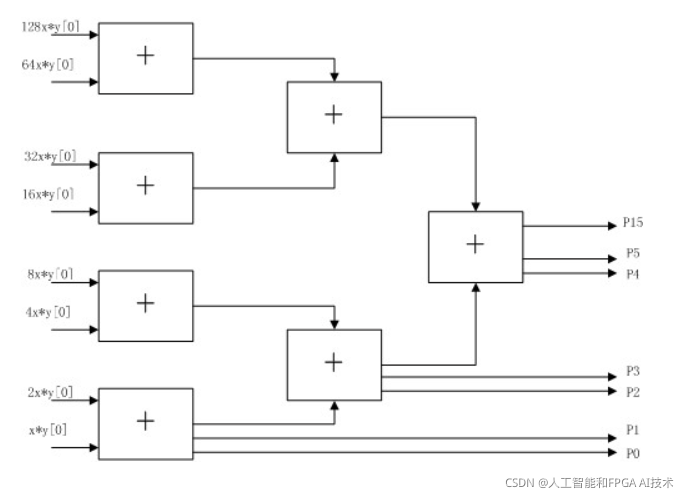
流水线乘法器比串行乘法器的速度快很多很多,但资源消耗也比较多。
4. 逻辑展开(Flatten Logic Structures)
第一是逻辑复制,特别是针对大扇出,通常使用generate或者是在综合器中设定。
逻辑复制是一种通过增加面积来改善时序条件的优化手段,最常使用的场合是调整信号的扇出。如果某个信号需要驱动后级很多单元,此时该信号的扇出非常大,那么为了增加这个信号的驱动能力,一种办法就是插入多级Buffer,虽然这样能增加驱动能力,但是也增加了这个信号的路径延时。为了避免这种情况,此时可以复制生成这个信号的逻辑,用多路同频同相的信号驱动后续电路,使平均到每路的扇出变低,这样不需要插入Buffer就能满足驱动能力增加的要求,从而节约该信号的路径延时。
在大部分逻辑设计中,高扇出信号多为同步信号,即寄存器信号,所以进行逻辑复制时是对寄存器进行复制。由于高扇出信号会增加布局布线的难度,减缓布线速度,因此可以通过寄存器复制解决两个问题:减少扇出,缩短布线延时; 复制后每个寄存器可以驱动芯片的不同区域,有利于布局布线。
第二个是消除代码中的优先级。这里需要多说一句:现在的工具很智能,就算你写成if else 有优先级的结构,有时候也能综合出并行结构。如果并行也符合你的设计要求,为了安全起见,最好还是写成case这种并行结构比较好。
【Case Implementation Style】中有三个选项:【Full】、【Parallel】与【Full-Parallel】。其中,【Full】针对上述的第一点,向XST说明有些状态是不可能出现的,让XST不要考虑太多;【Parallel】让XST将case语句综合为并行的电路结构;【Full-Parallel】则是两者的结合。
5. 寄存器平衡 (Register Balancing)。
寄存器平衡就是在你的关键路径中移动你的寄存器。第一就是你手动移动 —— 改代码。第二就是设定综合器让它自己移动 —— 不到万不得已不这么干,因为这么多导致代码移植性变差。整体设计策略:移动寄存器位置,平衡各组合逻辑路径的门延时。
6. 路径重组
对于某一级信号中到来相对较晚的信号,将其置于这一周期的后端进行计算,改善电路的时序性能。对关键路径上的组合和时序逻辑进行重新组合分配。
7. 全局资源
BUFG
通常BUFG是用于全局时钟的资源,可以解决信号因为高扇出产生的问题。但是其一般用于时钟或者复位之类扇出超级大的信号,此类信号涉及的逻辑遍布整个芯片,而BUFG可以从全局的角度优化布线。而且一块FPGA芯片中BUFG资源也有限,在7k325tffg900上也仅有32个,如果用于普通信号的高扇出优化也不大现实。因此,在时钟上使用BUFG是必须的,但是如果设计中遇到某些复位信号因高扇出产生的时序问题时,可以在此信号上使用BUFG来优化。
set_property CLOCK_BUFFER_TYPE BUFG [get_nets netName]
在遇到信号高扇出时,对于普通信号可采用寄存器复制或者设置max_fanout属性优化;而对于复位和时钟等全局信号,可加入BUFG优化。
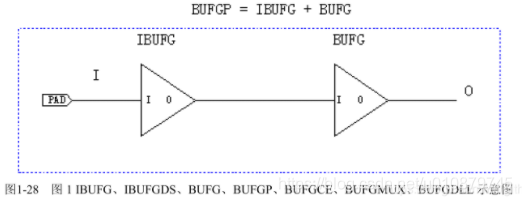
IBUFG即输入全局缓冲,是与专用全局时钟输入管脚相连接的首级全局缓冲。所有从全局时钟管脚输入的信号必须经过IBUF元,否则在布局布线时会报错。
IBUFGP U1(.I(clk_in), .O(clk_out));
BUFG是全局缓冲
(dont_touch= “true”)
BUFG BUFG_inst ( //clock buff .O(trig_buf), .I(trig));
复位用于全局资源
module resetn_bufg(input aresetn_input, output aresetn_output );
(dont_touch= “true”)
BUFG BUFG_inst ( //clock buff .O(aresetn_output), .I(aresetn_input) );
endmodule
8. 独热码编码, 配case语句
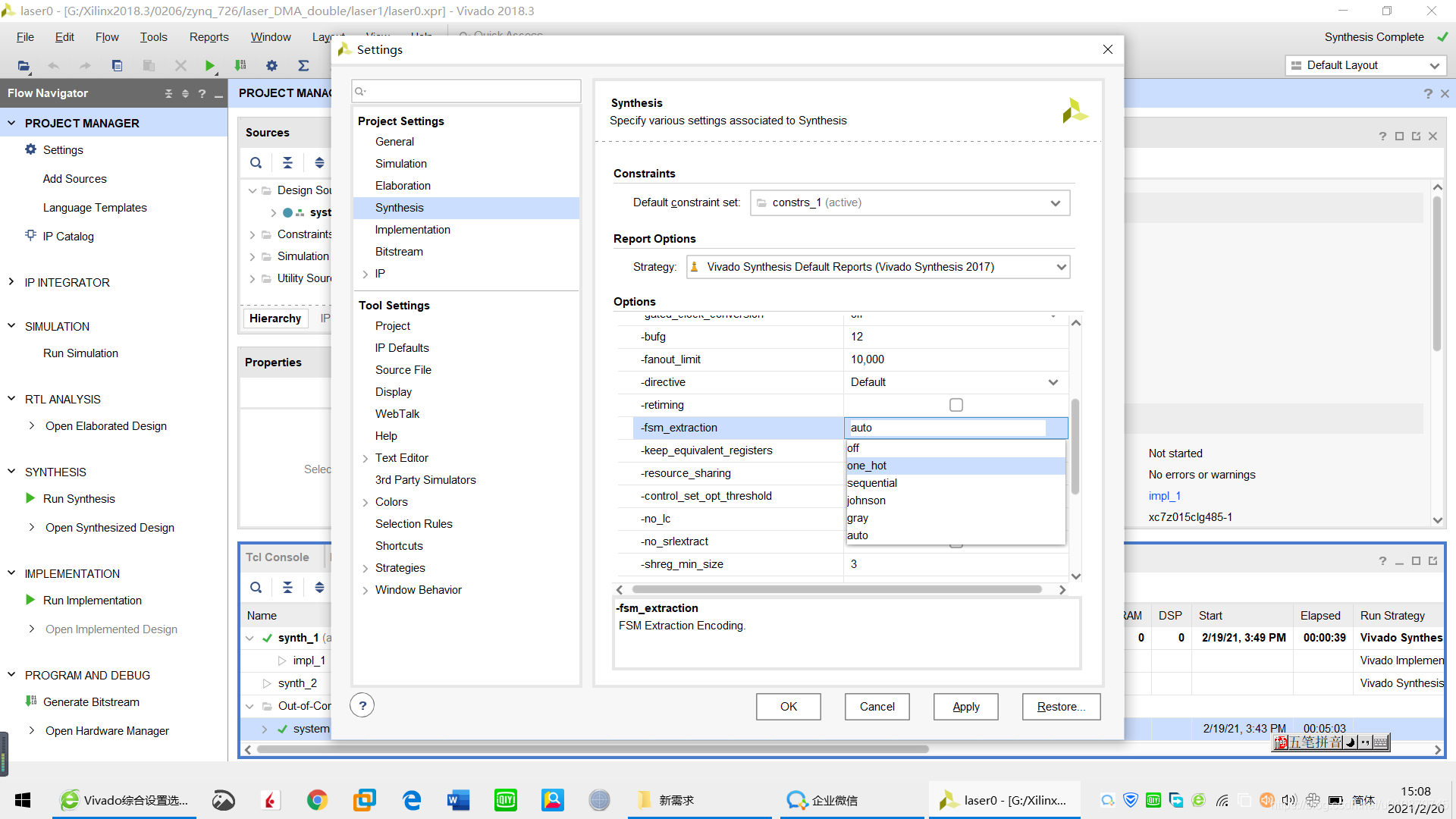
-综合选项-fsm_extraction优先级高于RTL代码中指定的编码方式
-综合属性FSM_ENCODING优先级则高于-fsm_extraction指定的编码方式
(* fsm_encoding = “one_hot” *) reg [7:0] my_state;
-在综合log文件中,搜索encoding或Synth 8-3354可查看状态机对应的编码方式
二进制编码、格雷码编码使用最少的触发器,消耗较多的组合逻辑,而独热码编码反之。独热码编码的最大优势在于状态比较时仅仅需要比较一个位,从而一定程度上简化了译码逻辑。虽然在需要表示同样的状态数时,独热编码占用较多的位,也就是消耗较多的触发器,但这些额外触发器占用的面积可与译码电路省下来的面积相抵消。
9. 用寄存器对模块的输入与输出进行缓存
10. 能不用复位就不用复位;不能的话,采用同步复位。
在FPGA设计中,有许多模块确实不需要复位。 在设计时,认真考虑一下这一点,去掉那些无用的复位信号。
11. 尽量不要使用多层嵌套的条件判断语句, 条件判断电路设计策略:不需要优先级编码的话,采用无优先级的电路。
12. 对于在同一时钟周期内要计算的内容有重复的,资源共享。
13. 大位宽的运算作为判断条件,必须要提前打拍flag,转为1bit信号。
latch
http://blog.sina.com.cn/s/blog_a73f94190102uwot.html
出现latch的情况?
在组合逻辑中,有时候往往不需要生成latch,所以必须知道某些信号会综合为latch,通过实践发现下面两类会出现latch:
1.在if-else和case中没有else和default将会导致产生latch。这个在夏宇闻的verilog中有讲到。
2.即使if-else 和case语句都满足if都有else,caes都有default,此时还是有可能出现latch.
怎么使得代码中消除不需要的latch呢?
由上面发现即使使用了if-else和 case-default这样标准的代码风格,还是会导致latch的产生的。通过测试可以发现要使得组合逻辑中,特别是在三段式状态机中代码不产生latch,必须做到下面几点:
- if-else 和case-default必须配套,也就是出现if 必须出现else与之配套;有case必须在后面写一个default。
- 在所有条件下,对信号都进行赋值
我的时序调试经验
- 选择合适的外时钟频率
- 尽量使用IP核
- 模块尽量小型化

















 2076
2076

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









