







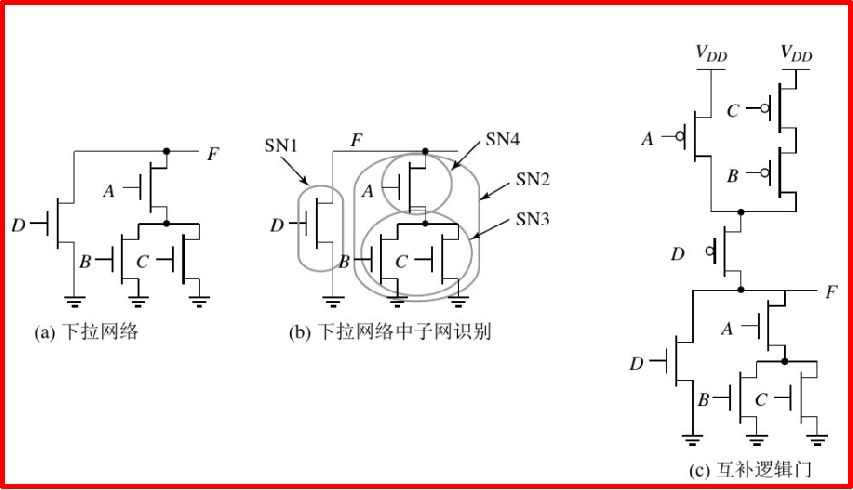
静态电路:每一个时刻,门的输出通过一条低阻通路连到VDD或是GND。
PDN由NMOS器件构成,而PUN由PMOS管构成,这一选择的主要理由是NMOS管产生“强0”而PMOS器件产生“强1”。

NMOS管的并联代表“或”(A+B)操作。PMOS网络的规则:如果两个输入都低,串联的两个PMOS都导通,这代表一个NOR( A ‾ ⋅ B ‾ = A + B ‾ \overline{A}\cdot\overline{B}=\overline{A+B} A⋅B=A+B )操作, 而PMOS 管并联实现NAND( A ‾ + B ‾ = A ⋅ B ‾ \overline{A}+\overline{B}=\overline{A\cdot B} A+B=A⋅B )操作。
设计题: 利用互补 C M O S 逻辑合成一个 C M O S 复合门 , 其功能为 F = D + A ⋅ ( B + C ) ‾ 利用互补CMOS逻辑合成一个CMOS复合门,其功能为F=\overline{D+A\cdot(B+C)} 利用互补CMOS逻辑合成一个CMOS复合门,其功能为F=D+A⋅(B+C)
噪声容限(静态特性)的分析比反相器要复杂,因为这些参数取决于加在这个门上的数据输入模式
增加串联的器件会使电路变慢。

设计题:

补CMOS门的传播延时随扇入数迅速 增加。事实上,一个门的无负载本征延时在最坏情况下是扇入数的二次函数(平方关系,因为扇入增加,电阻和电容同时增加)
大扇入时的设计技术(design techniques for large Fan-in)
1.加大晶体管的尺寸
2.逐级加大晶体管尺寸
3.重新安排输入:把关键路径上的晶体管靠近门的输出端可以提高速度。
4.重组逻辑结构
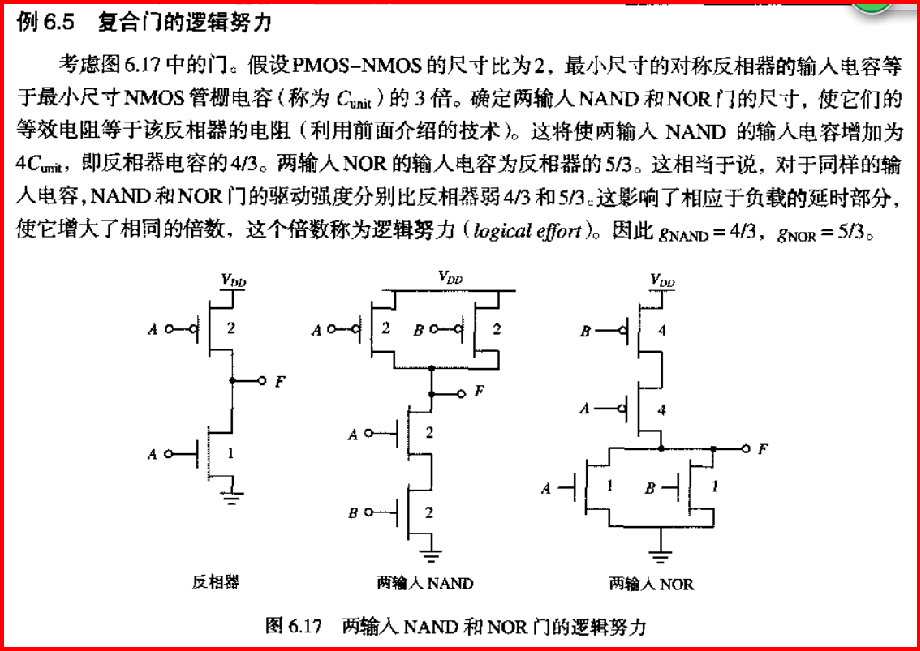
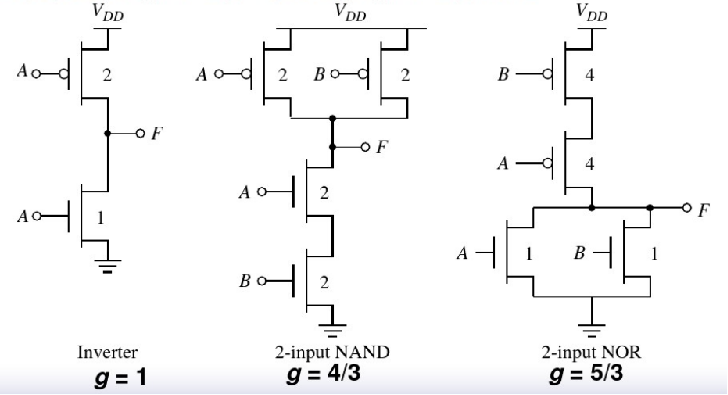
逻辑努力g表示一个门与一个反相器提供相同的输出电流时它所表现出的输入电容是反相器多少倍。
逻辑努力(logical effort)表示一个门与一个反相器ᨀ 供相同的输出电流时它所表现出的 ( ) 是反相器的多少倍。
我们称这两者的积h=f∙g称为门努力(gate effort)。
以下均为公式为重点:
我们用对反相器所釆用的类似步骤来决定这条路径的最小延时。求N-1个偏导数并令它们为零,可以发现每一级应当具有相同的门努力:
f 1 g 1 = f 2 g 2 = … = f N g N f_{1}g_{1}=f_{2}g_{2}=\ldots=f_{N}g_{N} f1g1=f2g2=…=fNgN
沿电路中一条路径的总逻辑努力可以通过把这条路径上所有门的逻辑努力相乘求得,由此得到了路径逻辑努力{path logical effort) G:
G = ∏ 1 N g i G=\prod_1^Ng_i G=∏1Ngi
路径的有效扇出F,它建立了路径中最后一级负载电容与第一 级输入电容之间的关系:
F = C L C g 1 F=\frac{C_{L}}{C_{g1}} F=Cg1CL
为了把F和各个门的等效扇出联系起来,必须引入另一个系数来考虑电路内部的逻辑扇出。当一 个节点的输出上有扇出时,总驱动电流中的一部分沿我们正在分析的路径流动,而有些则离开这条路径。我们把给定路径上一个逻辑门的分支努力(bracing effort} b定义为:
b = C o n − p a t h + C o f f − p a t h C o n − p a t h b=\frac{C_{\mathrm{on-path}}+C_{\mathrm{off-path}}}{C_{\mathrm{on-path}}} b=Con−pathCon−path+Coff−path
路径分支努力(port branching effort)定义为该路径上每一级分支努力的积,即:
B = ∏ 1 N b i B=\prod_1^Nb_i B=∏1Nbi
总努力门
H = ∏ i N h i = ∏ i N g i f i = G F B H=\prod_{i}^{N}h_{i}=\prod_{i}^{N}g_{i}f_{i}=GFB H=∏iNhi=∏iNgifi=GFB
由此时起,分析过程可以沿与反相器链相同的路线进行。使路径延时最小的门努力为
h
=
H
N
h=\sqrt[N]{H}
h=NH
而通过该路径的最小延时为: D = t p 0 ( ∑ j = 1 N p j + N ( H N ) γ ) \begin{aligned}\text{而通过该路径的最小延时为:}\\&D=t_{p0}\biggl(\sum_{j=1}^{N}p_{j}+\frac{N(\sqrt[N]{H})}{\gamma}\biggr)\end{aligned} 而通过该路径的最小延时为:D=tp0(j=1∑Npj+γN(NH))
如果包括分支努力,我们得知第二个门的输入电容是这个值的(f1/b1)倍,即:
g 2 s 2 C r e f = ( f 1 b 1 ) g 1 s 1 C r e f g_{2}s_{2}C_{ref}=\biggl(\frac{f_{1}}{b_{1}}\biggr)g_{1}s_{1}C_{ref} g2s2Cref=(b1f1)g1s1Cref
对于该链中的第i个门,可以得到:
s i = ( g 1 s 1 g i ) ∏ j = 1 i − 1 ( f j b j ) s_{i}=\left(\frac{g_{1}s_{1}}{g_{i}}\right)\prod_{j=1}^{i-1}\left(\frac{f_{j}}{b_{j}}\right) si=(gig1s1)∏j=1i−1(bjfj)
公式小结:
门努力: h i = g i f i h_i=g_if_i hi=gifi
路径的电气努力: F = C o u t / C i n F=C_{out}/C_{in} F=Cout/Cin
路径的逻辑努力: G = g 1 g 2 … g N G=g_1g_2\ldots g_N G=g1g2…gN
路径的分支努力 : B = b 1 b 2 … b N :B=b_1b_2\ldots b_N :B=b1b2…bN
路径的努力 : H = G F B :H=GFB :H=GFB
路径延时 D = Σ d i = Σ p i + Σ h i D=\Sigma d_i=\Sigma p_i+\Sigma h_i D=Σdi=Σpi+Σhi
使路径延时最小的门努力为:
h
N
=
H
h^N=H
hN=H
h
=
H
N
h=\sqrt[N]{H}
h=NH
每一级的门努力:
g
1
f
1
=
g
2
f
2
=
…
=
g
N
f
N
g_1f_1=g_2f_2=\ldots=g_Nf_N
g1f1=g2f2=…=gNfN
每一级的有效扇出: f i = h / g i f_i=h/g_i fi=h/gi
最小路径延时
D ^ = ∑ ( g i f i + p i ) = N H 1 / N + P \hat{D}=\sum\bigl(g_if_i+p_i\bigr)=NH^{1/N}+P D^=∑(gifi+pi)=NH1/N+P


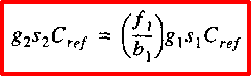
降低翻转活动性的设计技术(开关活动性降低)
1.逻辑重组:结果表明对于随机输入,链形实现比树形实现总体上具有较低的开关活动性。
2.输入排序:推迟输入具有较高翻转率的信号是有利的。
3.分时复用资源
4.均衡信号路径减少毛剌
电路中产生毛剌主要是由于在电路中路径长度失配引起 的。如果一个门的所有输入信号同时改变,那么就不会发生毛刺。反之,如果各输入信号在不同的时刻变化,那么就有可能形成动态故障。信号时序上的这一失配一般都是由于相对于电路的原始输入信号路径的长度不同而引起的。
建立一个能够完全消除静态电流和提供从电源轨线至轨线电压摆幅的有比逻辑方式是可能的。
PDN1必须足够强使out以低于VDD-|Vtp|
稳定有效的传输管设计
1.电平恢复器
电平恢复器 对器件切换速度的影响:增加恢复器器件就增加了内部节点X上的电容,从而减慢了这个门的速度。此外门的上升时间也受到负面影响。电平恢复晶体管Mr在被关断之前要阻止节点X处的电压下降。反之,电平恢复器将减少下降时间,因为PMOS管一旦导通, 就会加速上拉作用。
2.确定电平恢复器的尺寸
3.多种阈值晶体管
4.传输门逻辑
解决由n个传输门构成的链长延时问题最常用的办法是每隔m个传输门开关切断串联链并插入一个缓冲器。
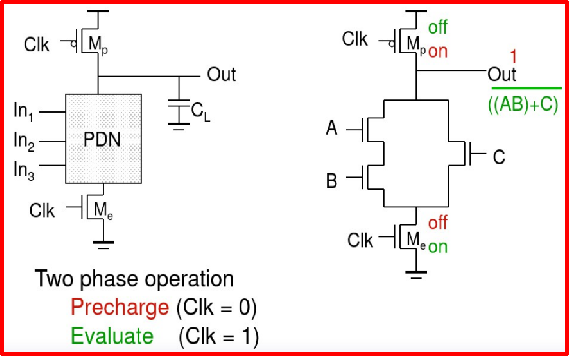
逻辑功能由NMOS下拉网络实现,构成PDN的过程与静态CMOS完全一样。
晶体管的数目(对于复杂门)明显少于静态情况:为N + 2而不是2N。
是无比的逻辑门。PMOS预充电器件的尺寸对于实现门的正确功能并不重要。预充电器件的尺寸可以较大以改善低至高的翻转时间(当然,这是以由高至低的翻转时间为代价的)。 然而这里还有一个权衡功耗的问题,因为较大的预充电器件会直接增加时钟的功耗。
动态逻辑门只有动态功耗。理想情况下在Vdd和GND之间从不存在任何静态电流路径。但是它的总功耗还是可以明显高于静态逻辑门。
动态逻辑门具有较快的开关速度,主要有两个原因。第一个(明显的)原因是由于减少了 每个门晶体管的数目,并且每个扇入对前级只表现为一个负载晶体管,因而降低了负载电容,这相当于降低了逻辑努力。例如,一个两输入动态NOR门的逻辑努力是2/3,大大小于相应静态CMOS门的5/3。第二个原因是动态门没有短路电流,并且由下拉器件提供的 所有电流都用来对负载电容放电。
利用对偶的方法可以实现P型动态逻辑。
动态逻辑的主要优点是提高了速度和减少了实现面积。
预充期间,下拉网络中的逻辑值不能用!
动态CMOS设计—设计中信号完整性问题—电荷泄漏
1.电荷泄漏
2.电荷分享
3.电容耦合
4.时钟馈通
动态CMOS串级问题的岀现是由于每一个门的输出(并且也是下一个门的输入)被预充电至1。这在求值周期开始时可能造成无意的放电。(同时求值,求值前管子是导通的)
静态互补CMOS把对偶的上拉和下拉网络组合在一起,在任何时候只有其中之一是导通的。
CMOS门的性能与扇入密切相关。解决扇入问题的技术包括决定晶体管的尺寸、输入的重新排序以及划分。速度也与扇岀存在线性关系。对于大的扇出需要使用额外的缓冲器。
有比逻辑由一个有源下拉网络连到一个负载器件上构成,这大大减少了门的复杂性,其代价是静态功耗和不对称的响应。仔细地确定晶体管的尺寸对于保证足够的噪声容 限是必要的。在这类电路中最常用的方法是采用伪NMOS技术和差分DCVSL,后者要求互补信号。
传输管逻辑把一个逻辑门实现为一个简单的开关网络,这使某些逻辑功能的实现非常简单。应当避免开关的长串联,因为延时与链中元件的数目成平方关系增长。仅含NMOS的 传输管逻辑虽然结构更为简单,但也许会引起静态功耗并减少噪声容限。这一问题可以通过增加电平恢复晶体管的办法来解决。
动态逻辑的工作原理是基于电荷存储在电容节点上以及该节点根据输入进行有条件的放电,这要求分两个阶段工作,即一个预充电阶段之后是一个求值阶段。动态逻辑用噪声容限来换取性能。它对于像漏电、电荷重分配以及时钟馈通等寄生效应的影响很敏感。使动态门串级可能会引起问题,因此应当小心处置。
一个逻辑网络的功耗很大程度与这个网络的开关活动性有关。这一活动性与输入的统计特性、网络的拓扑结构以及逻辑类型有关。像虚假尖峰信号(毛刺)和短路电流等造成的功耗可以通过仔细的电路设计及晶体管尺寸的选择来最小化。
低电压操作要求按比例降低阈值电压。漏电控制是低电压操作的关键。
该节点根据输入进行有条件的放电,这要求分两个阶段工作,即一个预充电阶段之后是一个求值阶段。动态逻辑用噪声容限来换取性能。它对于像漏电、电荷重分配以及时钟馈通等寄生效应的影响很敏感。使动态门串级可能会引起问题,因此应当小心处置。



















 1607
1607

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











