






文章:An Overview on Visual SLAM: From Tradition to Semantic
作者:Weifeng Chen,Guangtao Shang,Aihong Ji,Chengjun Zhou,Xiyang Wang,Chonghui Xu Zhenxiong Li and Kai Hu
编辑:点云PCL
来源:Remote Sens. 2022, 14, 3010. https://doi.org/10.3390/rs14133010
欢迎各位加入知识星球,获取PDF论文,欢迎转发朋友圈。文章仅做学术分享,如有侵权联系删文。未经博主同意请勿擅自转载。
公众号致力于点云处理,SLAM,三维视觉,高精地图等领域相关内容的干货分享,欢迎各位加入,有兴趣的可联系dianyunpcl@163.com。未经作者允许请勿转载,欢迎各位同学积极分享和交流。
摘要
视觉SLAM(VSLAM)由于低成本传感器、易于融合其他传感器和更丰富的环境信息的优势而快速发展,传统的基于视觉的SLAM研究取得了许多成就,但在挑战性环境下可能无法实现期望的结果,深度学习推动了计算机视觉的发展,深度学习与SLAM的结合越来越受到关注。作为高级环境信息,语义信息可以使机器人更好地理解周围环境,本文介绍了VSLAM技术的发展,重点介绍了传统VSLAM和基于深度学习的语义VSLAM两个方面,对于传统的VSLAM,本文详细总结了间接法和直接法的优缺点,并给出了一些经典的VSLAM开源算法。此外重点介绍了基于深度学习的语义VSLAM的发展,从典型的神经网络CNN和RNN开始,详细总结了神经网络在VSLAM系统中的改进。之后重点介绍了目标检测和语义分割对于VSLAM语义信息引入的帮助,本文认为未来智能时代的发展离不开语义技术的帮助,将深度学习引入VSLAM系统以提供语义信息可以帮助机器人更好地感知周围环境,并为人们提供更高级别的帮助。
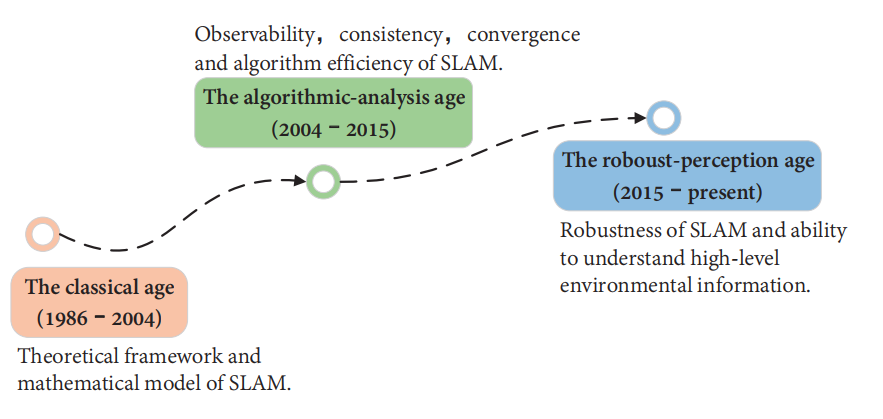
图1. SLAM发展历程概述。SLAM的发展经历了三个主要阶段:理论框架、算法分析和高级别鲁棒感知。时间点并不严格限定,而是代表了SLAM在某个阶段的发展和人们感兴趣的热点问题。
主要贡献
本文全面补充和更新了基于视觉的SLAM技术的发展,此外本文将基于视觉的SLAM的发展分为两个阶段:传统的VSLAM和基于深度学习的语义VSLAM。因此,读者可以更好地理解VSLAM的研究热点,并把握VSLAM的发展方向,我们认为在传统阶段,SLAM问题主要解决算法框架问题。在语义时代,SLAM着重于与深度学习相结合实现先进的情境感知和系统鲁棒性。我们的回顾对现有技术做出了以下贡献:
更全面地回顾了基于视觉的SLAM的发展,并回顾了基于环境语义信息的同时定位和地图构建领域的最新研究进展。
从卷积神经网络(CNN)和循环神经网络(RNN)开始,详细描述了深度学习在VSLAM中的应用,据我们所知,这是首次从神经网络的角度介绍VSLAM。
详细描述了语义信息和VSLAM的结合,并指出了VSLAM在语义时代的发展方向,主要介绍和总结了在系统定位和地图构建方面语义信息和传统视觉SLAM结合的杰出研究成果,并对传统视觉SLAM和语义SLAM进行了深入比较,最后提出了语义SLAM未来的研究方向。
本文的章节目录如图2所示,更加详细的文章可加入知识星球获取pdf文档细读。
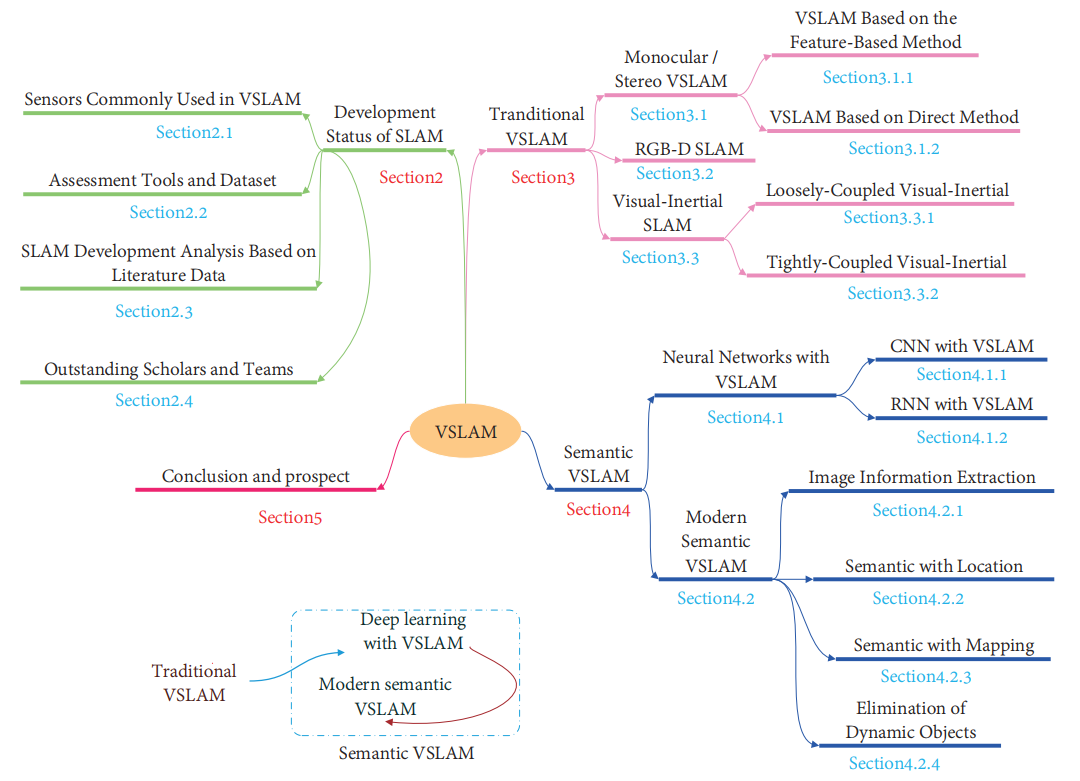
图2. 本文的结构图,本文重点介绍语义VSLAM的第二章,我们认为神经网络的引入是语义VSLAM的开始,从深度神经网络开始,描述其与VSLAM的结合,然后从基于深度学习的目标检测和语义分割的角度详细解释现代语义VSLAM,并进行总结和展望。
主要内容
SLAM的发展现状
VSLAM常用的传感器:在VSLAM中常用的传感器包括单目相机、立体相机和RGB-D相机,单目相机和立体相机原理类似,可用于广泛的室内和室外环境。作为一种特殊形式的相机,RGB-D相机主要通过主动发射红外结构光或计算飞行时间(TOF)直接获取图像深度,它使用方便,但对光线敏感,大多数情况下只能在室内使用[23]。近年来出现的事件相机是一种新型相机传感器,它的输出是像素亮度变化,与传统相机不同。基于事件相机的SLAM算法仍处于初步研究阶段[24]。此外,作为一种基于视觉的经典SLAM系统,视觉惯性融合在许多方面取得了优异的成果。在图3中,我们比较了不同相机的主要特点。

图3 不同相机的比较,事件相机不是一种具体的相机类型,而是一种可以获取“事件信息”的相机,传统相机以恒定频率工作,存在自然缺陷,例如拍摄高速物体时存在滞后、模糊和过度曝光等问题。然而,事件相机采用类似于人眼的神经处理信息的方法,不会出现这些问题。
评估工具和数据集 :SLAM 问题已经存在了几十年,在过去的几十年中,许多优秀的算法出现了,它们各自从不同的角度为 SLAM 技术的快速发展做出了贡献,一般来说可以从多个角度评估 SLAM 算法,例如时间消耗、复杂度和准确性。然而,最重要的是我们最关注的是其准确性,ATE(绝对轨迹误差)和RPE(相对姿态误差)是用于评估 SLAM 准确性的两个最重要的指标。相对姿态误差用于计算同一时间戳中姿态变化的差异,适用于估计系统漂移,绝对轨迹误差直接计算相机姿态的实际值和 SLAM 系统估计值之间的差异。
ATE:绝对轨迹误差是估计姿态和真实姿态之间的直接差异,可以直接反映算法的精度和全局轨迹一致性。
RPE:相对姿态误差主要描述由固定时间差D分隔的两帧的准确性(与真实姿态相比),相当于直接测量的里程计误差。
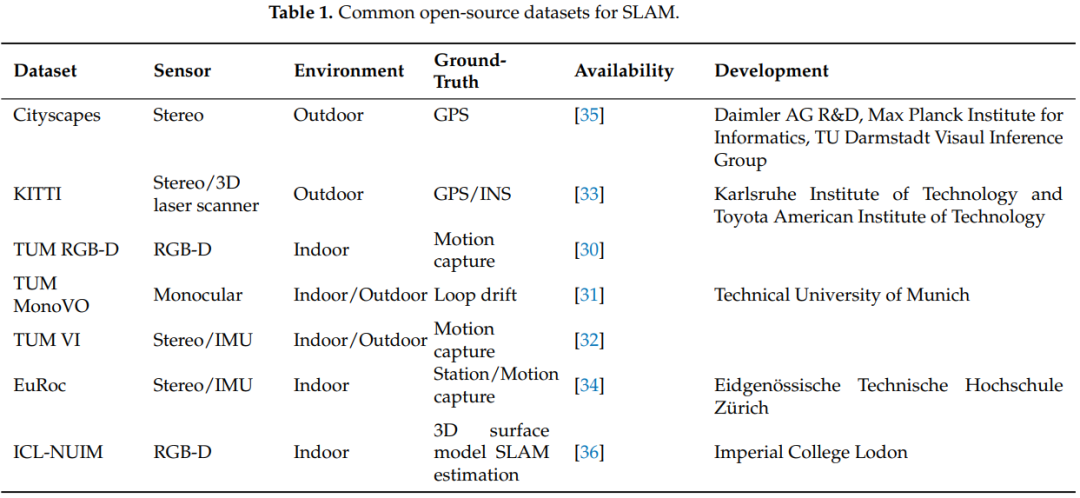
EVO [25]是SLAM系统的Python版本的评估工具,可以与各种数据集一起使用,除了ATE和RPE之外,还可以获取数据,并绘制测试算法和真实轨迹的比较图,是一个非常方便的评估工具包。 此外,我们还需要使用数据集来测试算法的特定可视化效果。用于测试SLAM性能各方面的常用数据集如表1所示。TUM数据集主要包括多视角数据集、3D物体识别和分割、场景识别、3D模型匹配、VSALM和其他各个方向的数据。根据应用方向,可以分为TUM RGB-D [30]、TUM MonoVO [31]和TUM VI [32]。
基于文献数据的 SLAM 发展分析 :自 SLAM 出现以来,它已被广泛应用于机器人领域。如图 4 所示,本文选择了过去二十年中与移动机器人相关的大约1000篇热门文章,并制作了这个关键词热度图。圆圈越大,关键词出现的频率就越高,圆圈的层次从内到外显示了过去到现在的时间,颜色越红,吸引力越大。连接线表示不同关键词之间有联系(数据来自 Web of Science Core Collection)。
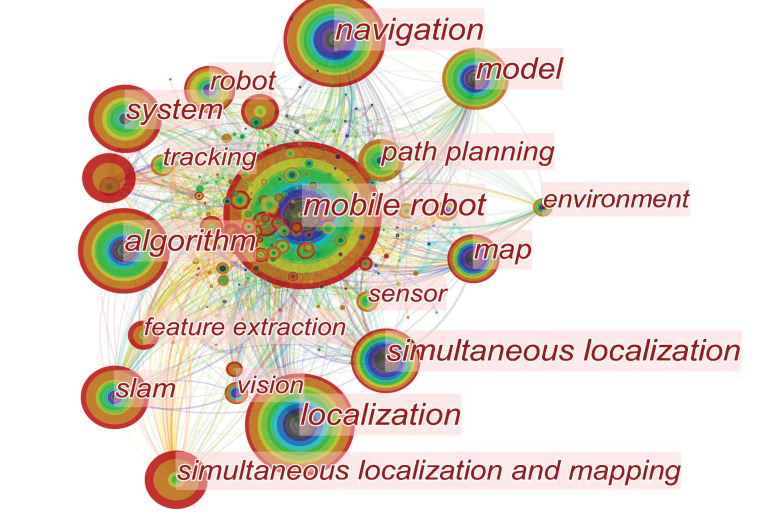
图4. 移动机器人领域的热词
如图 5 所示,与视觉 SLAM 和语义 SLAM 相关的论文被引次数正在迅速增加,特别是在2017年左右,视觉 SLAM 和语义 SLAM 的引用量飙升,在传统的 VSLAM 研究方面已经取得了许多进展,为了使机器人能够从更高层次感知周围环境,语义 VSLAM 研究受到广泛关注。
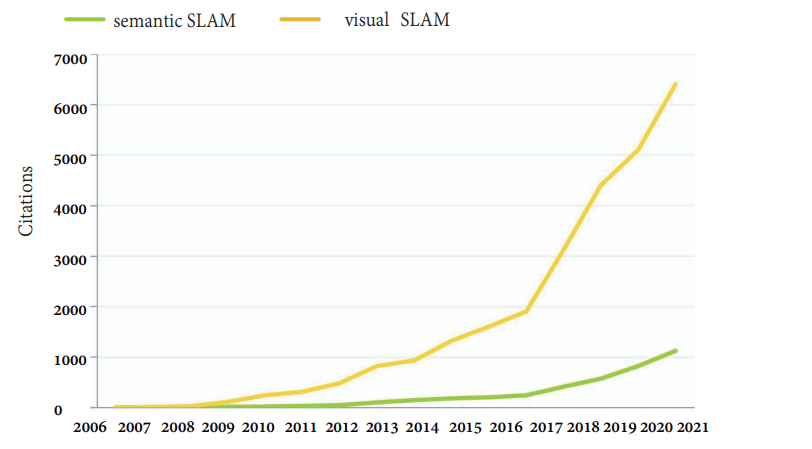
图5. 近年来Web of Science上有关视觉SLAM和语义SLAM的文章引用次数(截止至2021年12月)
此外,如图 6 所示,本文从 Web of Science Core Collection 中选择了约 5000 篇文章,从已发表的关于 SLAM 的期刊标题来看,SLAM 是机器人领域的一个热门话题。
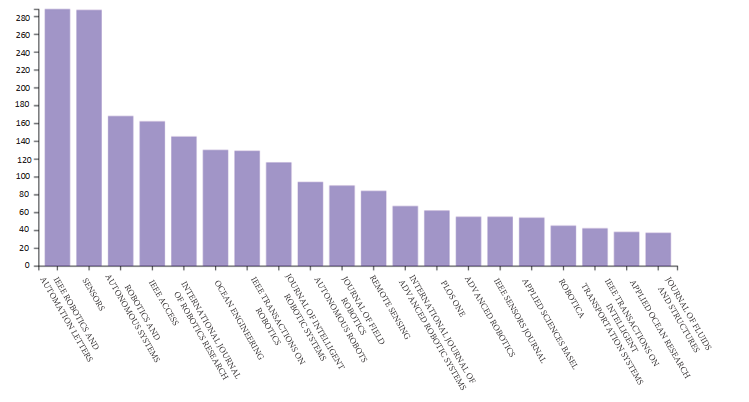
图6. Web of Science上关于SLAM的出版物标题
杰出学者和团队 :此外,许多学者和团队对 SLAM 研究做出了不可磨灭的贡献,如图 7 所示,我们分析了大约 4000 篇 2000 年至 2022 年的文章(数据来自 Web of Science 网站),字体越大表示作者受到的关注度越高,反之亦然。

图7 在视觉SLAM领域的杰出学者
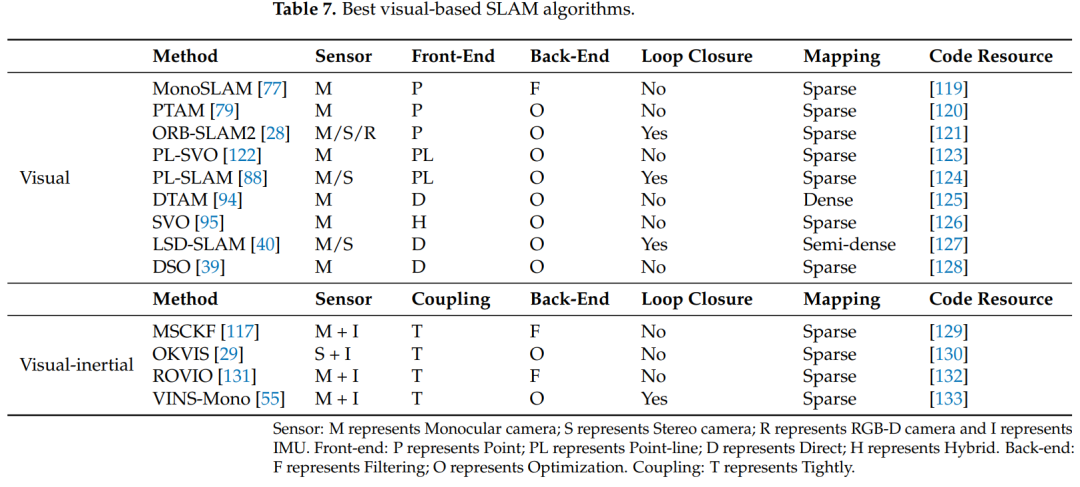
他们所属的国家见图8,德国慕尼黑工业大学的计算机视觉组是该领域的领导者,该团队发表了各种经典的视觉 SLAM 解决方案,如 DSO [39] 和 LSD-SLAM [40],从各个方面提高了视觉 SLAM 的性能,瑞士苏黎世大学的机器人与感知组也通过开发 SVO 和 VO/VIO 轨迹评估工具为 SLAM 技术的快速发展做出了贡献,此外,苏黎世联邦理工学院的计算机视觉Ensemble实验室在这个领域也做出了许多努力。此外,他们在大规模室外地图的视觉语义定位领域取得了很多突破性进展,西班牙萨拉戈萨大学机器人、感知和实时组 SLAM 实验室是 SLAM 发展的最大贡献者之一,实验室推出的 ORB-SLAM 系列是视觉 SLAM 领域的一个里程碑方案,对 SLAM 研究产生了深远的影响。此外,许多学者和团队的努力促进了视觉语义 SLAM 的快速发展,并为未来解决各种问题打下了基础。
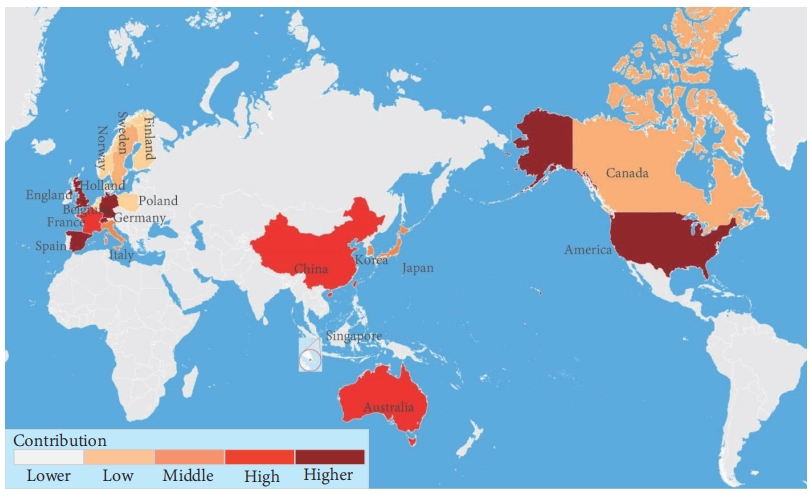
图8. 不同国家在SLAM领域的贡献(颜色从浅到深表示贡献从低到高)
表 2 展示了一些优秀团队的作品和它们的团队网站供您参考,您可以通过其名称后引用的数字查看团队的网站。
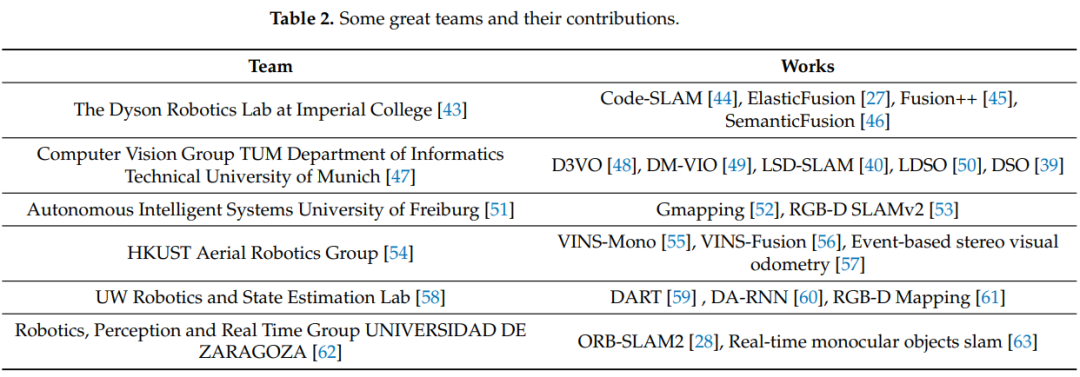
一些学者在语义VSLAM研究方面做出了杰出的贡献,例如,Niko Sünderhauf [41]及其团队在机器人场景理解和语义VSLAM方面取得了许多进展,该团队致力于使机器人理解它所看到的是最迷人的目标之一,为此,他们通过将目标检测与同时定位和建图(SLAM)技术相结合,开发了语义建图和语义SLAM的新方法。该团队[42]的研究人员是澳大利亚机器人视觉中心的一部分,总部位于澳大利亚昆士兰科技大学布里斯班分校,他们致力于开发新的SLAM(同时定位和建图)方法,通过将几何和语义信息相结合,创建具有语义含义的地图,我们相信,这种语义丰富的地图将有助于机器人理解我们复杂的世界,并最终增加机器人在家庭和工业部署场景中可以拥有的交互范围和复杂性。
传统VSLAM
Cadena等人[15]提出了一个经典的视觉SLAM框架,主要由两部分组成:前端和后端,如图9所示,前端提供实时的相机姿态估计,而后端提供地图更新和优化。具体来说,成熟的视觉SLAM系统包括传感器数据采集、前端视觉里程计、后端优化、回环检测和地图构建模块[64]。
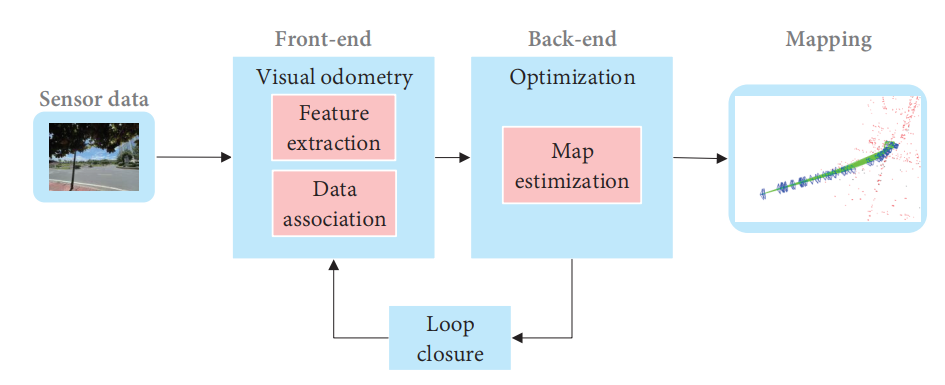
图9. 典型的视觉SLAM系统框架
单目/立体 VSLAM
这里详细介绍基于单目或双目摄像头的 VSLAM 算法,对于 VSLAM 系统,作为 SLAM 前端的视觉里程表是不可或缺的一部分[65]。文献[20]指出,根据前端视觉里程计收集的不同图像信息,VSLAM 可以分为直接法和间接法,间接法需要从收集的图像中选择一定数量的代表性点,称为关键点,并在随后的图像中检测和匹配它们以获得相机姿态,它不仅保存了图像的关键信息,而且减少了计算量,因此被广泛使用。直接法使用图像的所有信息而无需预处理,并直接在像素强度上进行操作,对于纹理稀疏的环境具有更高的鲁棒性[66],间接法和直接法都得到了广泛关注并得到了不同程度的发展。
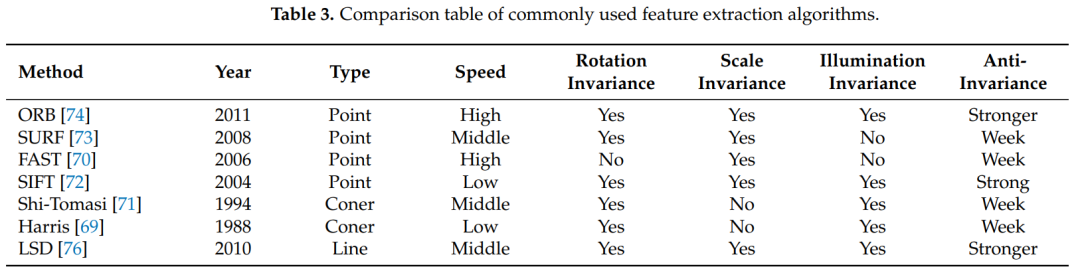
基于特征的VSLAM方法:间接式VSLAM的核心是检测、提取和匹配几何特征(点、线或平面)、估计相机位姿和构建环境地图,同时保留重要信息,可以有效降低计算量,因此被广泛使用[67],由于其简单性和实用性,基于点特征的VSLAM方法长期以来一直被视为间接VSLAM的主流方法[68]。早期的特征提取大多采用角点提取方法,例如Harris [69]、FAST [70]、GFTT [71]等。在表3中,我们列出了常见的传统特征提取算法,并比较它们的主要性能,以帮助读者更全面地了解。
Davidson等人于2007年提出了MonoSLAM算法。该算法被认为是第一个能够实现实时无漂移运动结构恢复的单目VSLAM算法。前端使用shi-Tomasi角点追踪稀疏特征点进行特征点匹配,而后端使用扩展卡尔曼滤波器(EKF)进行优化,可以在线实时建立稀疏的环境地图。这个算法在SLAM研究中具有里程碑意义,但是EKF方法导致存储和状态数量之间的平方增长,因此不适用于大规模场景。在同一年,PTAM的出现改善了MonoSLAM在广泛环境中无法长时间稳定工作的问题。PTAM作为第一个使用后端非线性优化的SLAM算法,解决了基于滤波器方法数据增长快的问题,此外,它首次将跟踪和建图分为两个不同的线程,前端使用FAST角点检测提取并使用图像特征估计相机运动,而后端负责非线性优化和建图,它不仅保证了相机姿态计算的实时性,还保证了整个SLAM系统的准确性,然而,由于没有回路检测模块,在长时间运行期间会积累误差。在2015年,MUR-Artal等人提出了ORB-SLAM [80],该算法被认为是PTAM的优秀继承者,在PTAM的基础上增加了回路闭合检测模块,有效地减少了累积误差,作为一种实时单目视觉SLAM系统,它使用ORB特征匹配来完成整个过程,如图10所示,创新性地使用跟踪、局部地图和回路闭合检测三个线程。此外,回路闭合检测线程使用单词袋模型DBoW [81]来进行回路闭合,基于BoW模型的回路闭合方法可以通过检测图像相似性快速检测回路闭合,并在处理速度和地图构建的准确性方面取得良好的结果,在后来的几年中,该团队推出了ORB-SLAM2 [28]和ORB-SLAM3 [82],由于其实时CPU性能和稳健性,ORB-SLAM系列是最广泛使用的视觉SLAM解决方案之一,但是,ORB-SLAM系列严重依赖于环境特征,因此在没有纹理特征的环境中很难获得足够的特征点。
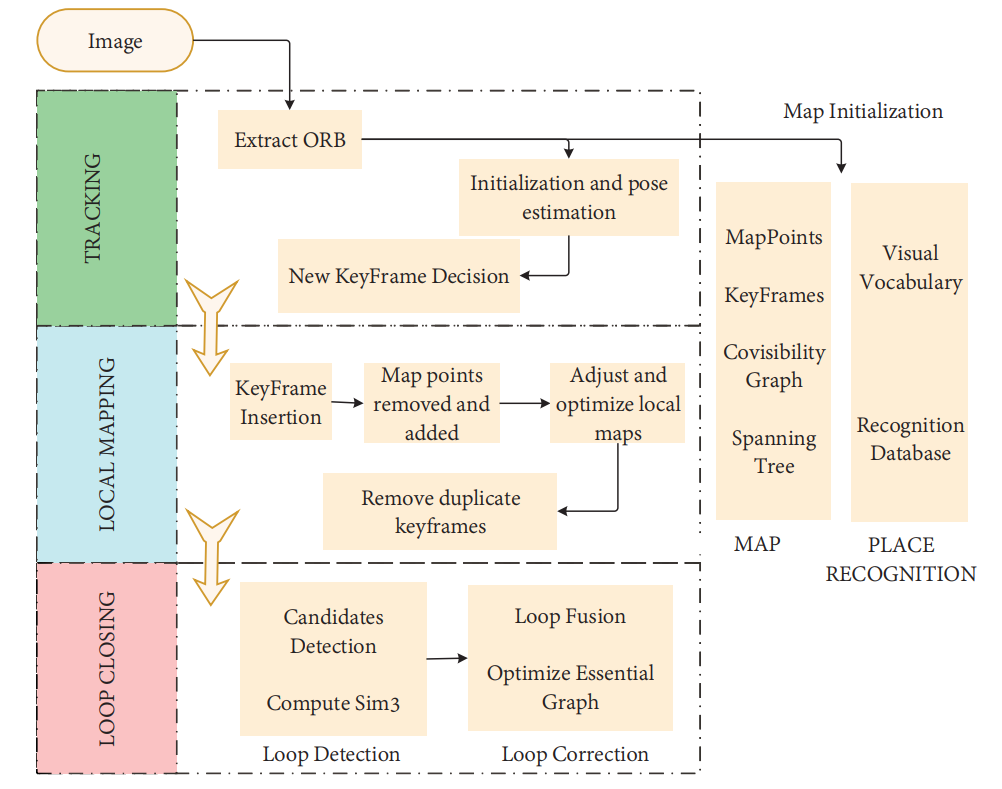
图10 ORB-SLAM流程图
基于点特征的SLAM系统过于依赖点特征的质量和数量,在弱纹理场景下(例如走廊、窗户、白色墙壁等),很难检测到足够的特征点,从而影响了系统的稳健性和准确性,甚至导致跟踪失败,此外,由于相机的快速移动、照明变化等原因,点特征的匹配数量和质量会严重下降,为了改善基于特征的SLAM算法,应用线特征在SLAM系统中的应用越来越受到关注[83],常用的线特征提取算法是LSD [76]。如图11所示,相比单独使用点特征或线特征,点特征和线特征的组合增加了特征观测和数据关联的数量,此外,与点特征相比,线特征对光照变化不太敏感,这提高了原始系统的定位精度和鲁棒性[76],在2016年,Klein等人[87]采用了点线融合的方法来改善因快速相机移动引起的图像模糊导致的SLAM跟踪失败问题,2017年,Pumarola等人[88]发表了单目PL-SLAM,Gomez-Ojeda等人[89]在同一年发表了双目PL-SLAM。这两种算法都基于ORB-SLAM,使用LSD检测算法来检测线特征,然后将点线特征组合在SLAM的每个环节中,它甚至可以在大多数点特征消失时工作,此外,它提高了SLAM系统的精度、鲁棒性和稳定性,但实时性不佳。

图11. 在弱纹理环境下进行点特征和线特征提取的比较,从左到右分别是ORB点特征提取,LSD线特征提取以及点线组合特征提取。
此外,在某些环境下,存在一些明显的表面特征,引起了一些研究人员的浓厚兴趣,[90]提出了一种结合平面和线条的地图构建方法,通过将表面特征引入实时VSLAM系统,通过组合低级特征来减少误差并提高系统的鲁棒性。表4显示了几何特征的比较。
| 特征类型 | 优点 | 缺点 | 适用场景 |
| 点特征 | 容易提取,计算速度快 | 在弱纹理区域和光照变化较大时容易受到影响 | 室内平滑表面场景,小型室外场景 |
| 线特征 | 与点特征相比,更不受光照变化的影响,可以提高姿态估计的精度和鲁棒性 | 在复杂的场景中,易受到遮挡和复杂背景干扰 | 室内、室外较简单场景 |
| 面特征 | 在平滑表面上具有更好的辨识度,利用面特征进行建图可以提高SLAM系统的鲁棒性 | 在自然环境中,适用的面特征较少 | 仅限于平滑表面的室内环境和人工环境 |
基于直接法的VSLAM :与特征点法不同,直接法直接操作像素强度,并且可以保留有关图像的所有信息,此外,直接法取消了特征提取和匹配的过程,因此计算效率比间接法更高,此外,它对于纹理复杂的环境具有良好的适应性,在缺失特征的环境中仍然可以保持良好的效果[93],直接法类似于光流法,它们都有一个强假设:灰度不变性,其原理如图12所示。

图12 直接法的示意图
2011 年,Newcombe 等人提出了 DTAM 算法[94],被认为是第一个实用的直接法 VSLAM 算法,DTAM 通过将输入图像与重建地图创建的图像进行比较来进行跟踪,该算法对环境进行了精确而详细的重建,然而,它影响了存储和处理数据的计算成本,因此只能在 GPU 上实时运行,LSD-SLAM [40]忽略了无纹理区域以提高操作效率,并可以在 CPU 上实时运行,LSD-SLAM 是另一种主要的间接方法,将无特征提取与半稠密重建相结合,其核心是使用半稠密重建的视觉测距,该算法由三个步骤组成:跟踪,深度估计和地图优化,首先,最小化光度误差以估计传感器姿态,其次,为进行深度估计选择一个关键帧,最后,在地图优化步骤中,使用姿态优化算法将新的关键帧合并到地图中并进行优化。2014 年,Forster 等人提出了半直接式视觉 SLAM 算法 SVO[95],由于该算法不需要为每帧提取特征,因此可以以高帧率运行,使其可以在低成本嵌入式系统中运行[80],SVO 结合了特征点方法和直接法的优点,该算法分为两个主要线程:运动估计和地图制作。运动估计通过特征点匹配进行,但地图制作通过直接法进行,SVO 有良好的结果,但作为纯视觉方法,它只执行短期数据关联,这限制了其准确性[82],2018 年,Engel 等人提出了 DSO,DSO 可以有效地使用任何图像像素,这使其即使在无特征区域也具有鲁棒性。到目前为止,VSLAM在直接和间接方法方面取得了许多成就。表5比较了直接方法和间接方法的优缺点,以帮助读者更好地理解。
| 类型 | 优势 | 缺点 |
直接法 | (1) 特征点本身对光照、运动和旋转不敏感,因此相对稳定。 (2) 相机移动速度较快(相对于直接法),可以成功跟踪,具有更好的鲁棒性。 (3) 研究时间较长,方案比较成熟。 | (1) 提取、描述和匹配关键点需要很长时间。 (2) 特征点丢失的情况无法使用。 (3) 只能构建稀疏地图。 |
| 间接法 | (1) 速度快,可以节省特征点和描述子计算的时间。 (2) 可以用于特征缺失的情况(如白墙),而在这种情况下特征点方法会迅速恶化。 (3) 可以构建半密集甚至密集的地图。 | (1) 由于假设灰度不变,对光照变化敏感。 (2) 需要慢速移动的相机或高采样频率(可以通过图像金字塔改善)。 (3) 对于单个像素或像素块的差分不强,采取数量而非质量的策略。 |
RGB-D SLAM
RGB-D相机是近年来推出的一种视觉传感器。它可以同时收集环境的彩色图像和深度图像,并通过主动发射红外结构光或计算飞行时间(TOF)直接获取深度图,主要是通过三维重建方面的发展来方便地获得空间中的三维信息。KinectFusion [98]是基于RGB-D相机的首个实时3D重建系统。它使用由深度创建的点云通过ICP(迭代最近点)来估计相机姿态。然后,基于相机姿态拼接多帧点云集合,并通过TSDF(截断有符号距离函数)模型来表示重建结果。使用GPU加速可以实时构建3D模型。然而,该系统未经过闭环优化。此外,在长期运行中会出现明显的误差,并且RGB-D相机的RGB信息尚未得到充分利用。相比之下,ElasticFusion [27]充分利用了RGB-D相机的颜色和深度信息。它通过RGB的颜色一致性来估计相机姿态,并通过ICP来估计相机姿态。然后通过不断优化和重构地图来提高相机姿态的估计精度。最后,使用surfels模型来表示地图,但只能在小型室内场景中重建。与上述算法相比,RGB-D SLAMv2 [53]是一个非常优秀和全面的系统。它包括图像特征检测、优化、闭环等模块,适合初学者进行二次开发。
尽管RGB-D相机使用更加便利,但RGB-D相机对光线非常敏感。此外,存在许多窄小、嘈杂和有限的视野等问题,因此大多数情况下仅在室内使用。此外,现有算法必须使用GPU来实现。因此,主流传统的VSLAM系统仍然不将RGB-D相机作为主要传感器使用。然而,在室内三维重建中,RGB-D相机被广泛使用。此外,由于能够建立密集的环境地图,语义VSLAM方向中,RGB-D相机也被广泛使用。表6展示了基于RGB-D相机的经典SLAM算法。

纯视觉SLAM算法已经取得了很多成就,但是仅使用相机作为单一传感器仍然难以解决由快速相机运动和光照不良引起的图像模糊等问题。IMU被认为是相机最补充的传感器之一,它可以在短时间内以高频率获得精确的估计,并降低动态物体对相机的影响。此外,相机数据可以有效地纠正IMU的累积漂移。同时,由于相机和IMU的小型化和成本降低,视觉惯性融合也取得了快速发展,并成为许多研究者青睐的传感器融合方法。目前,视觉惯性融合可以根据是否将图像特征信息添加到状态向量中分为松耦合和紧耦合。松耦合意味着IMU和相机分别估计它们的运动,然后融合它们的位姿估计。紧耦合则是将IMU的状态和相机的状态组合在一起,共同构建运动和观测方程,然后进行状态估计。
语义VSLAM
语义SLAM指的是可以获取未知环境的几何信息和机器人的运动信息,还可以检测和识别场景中的目标,它可以获取它们的功能属性和与周围对象的关系等语义信息,甚至可以理解整个环境的内容[134],传统的VSLAM以点云等形式表示环境,对我们来说是一堆无意义的点,为了从几何和内容层面感知世界并为人类提供更好的服务,机器人需要进一步抽象这些点的特征并理解它们[135]。随着深度学习的发展,研究人员逐渐意识到其对SLAM问题的可能帮助[136],语义信息可以帮助SLAM更高层次地理解地图。此外,它减少了SLAM系统对特征点的依赖性并提高了系统的鲁棒性[137]。
现代语义VSLAM系统离不开深度学习的帮助,通过学习获得的特征属性和关联关系可以用于不同的任务[138],作为机器学习的重要分支,深度学习在图像识别[139]、语义理解[140]、图像匹配[141]、3D重建[142]等任务中取得了显著的成果,深度学习在计算机视觉中的应用可以大大缓解传统方法遇到的问题[143],传统的VSLAM系统在许多方面取得了值得称赞的结果,但仍有许多具有挑战性的问题需要解决[144],文献[145]详细总结了基于深度学习的VSLAM,并指出了传统VSLAM存在的问题,这些研究[146-149]建议使用深度学习替换传统SLAM的一些模块,例如回环检测和位姿估计,以改进传统方法。
具有 VSLAM 的神经网络:图13展示了CNN和RNN的典型框架,CNN可以从图像中捕捉空间特征,帮助我们准确地识别物体及其与图像中其他物体的关系[150],RNN的特点是它可以处理图像或数字数据,由于网络本身的记忆能力,它可以学习具有上下文相关性的数据类型[151],此外,其他类型的神经网络,如DNN(深度神经网络)也有一些试验性工作,但仍处于初级阶段,本文指出,CNN具有提取带有某种模型的事物特征,然后根据特征进行分类、识别、预测或决策的优点。它可以对VSLAM的不同模块有所帮助。此外,本文认为RNN在帮助建立相邻帧之间的一致性方面具有巨大优势,此外,高层次特征具有更好的区分性,这可以帮助机器人更好地完成数据关联。
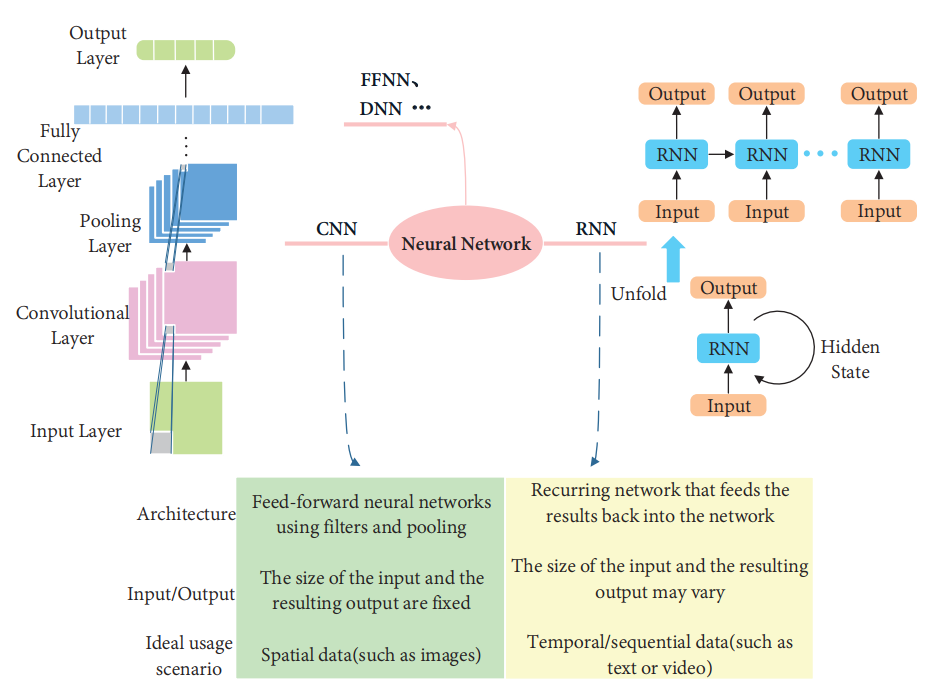
图13. CNN和RNN的结构块图。CNN适用于从分层或空间数据中提取未标记的特征。RNN适用于时间序列数据和其他类型的顺序数据。
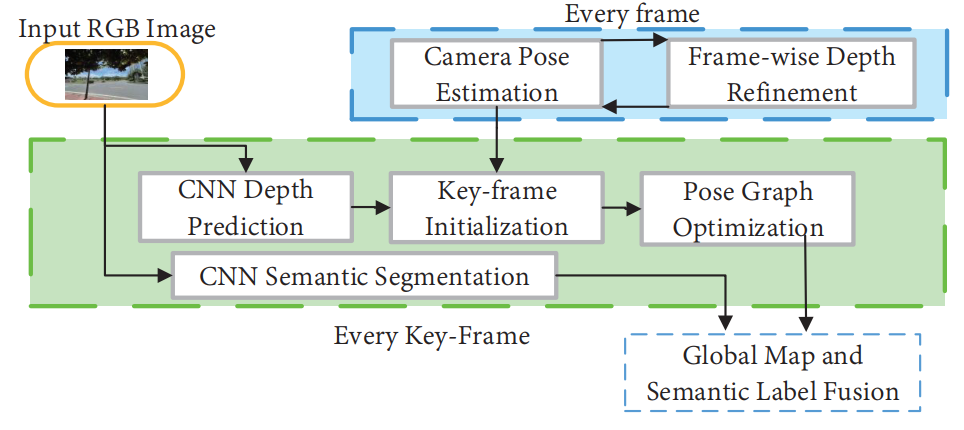
图14 CNN-SLAM框架图
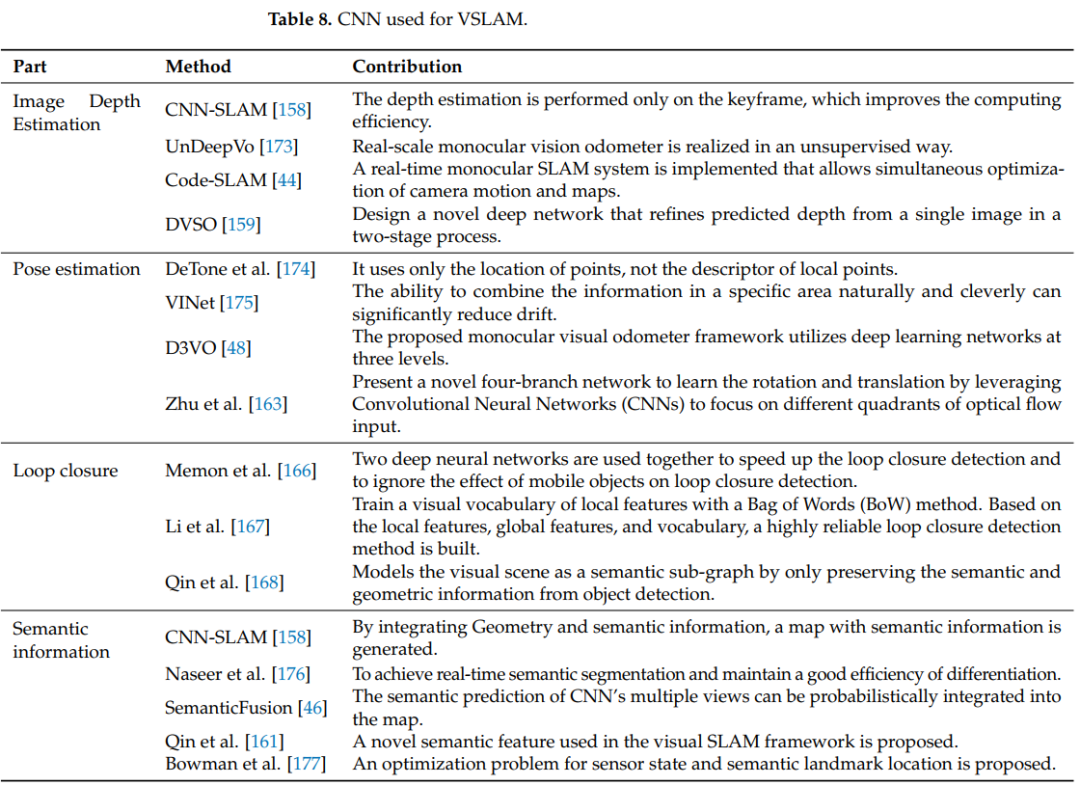
CNN已经在替换传统VSLAM算法的某些模块方面取得了良好的效果,例如深度估计和环路闭合检测。但其稳定性仍不如传统的VSLAM算法 [172]。相比之下,CNN系统的语义信息提取效果更好,通过使用CNN提取环境的高层次特征的语义信息来优化传统VSLAM过程,使传统VSLAM获得更好的结果。将神经网络用于提取语义信息并将其与VSLAM相结合将是一个极具兴趣的领域,在语义信息的帮助下,数据关联从传统的像素级升级到对象级别,感知几何环境信息被赋予语义标签,以获得高级别的语义地图,它可以帮助机器人理解自主环境和人机交互。表8显示了CNN网络在VSLAM中的一些主要应用链接。其中一些涉及许多方面,这里仅列出主要贡献。
RNN与VSLAM :RNN(循环神经网络)的研究始于20世纪80年代和90年代,并在21世纪初发展成为经典深度学习算法之一,长短时记忆网络(LSTM)是最常见的循环神经网络之一[178]。LSTM是RNN的一种变体,它可以记住可控的大量先前的训练数据或更好地遗忘它[179]。
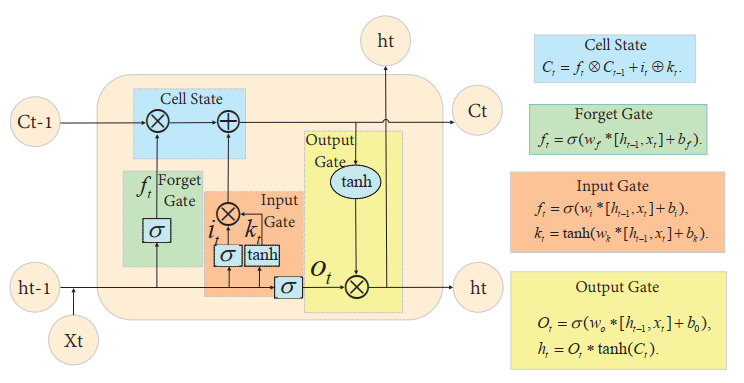
图15 LSTAM基础框架
如图15所示,给出了LSTM的结构以及其不同模块的状态方程。带有特殊隐式单元的LSTM可以长时间保留输入。LSTM继承了RNN模型的大多数特征,并解决了由于逐渐减少的梯度反传过程引起的梯度消失问题。作为RNN的另一种变体,门控循环单元(GRU)更易于训练,可以提高训练效率[180]。由于其记忆和参数共享的特性,RNN在学习序列的非线性特征方面具有一定的优势。引入卷积神经网络CNN构建的RNN可以处理涉及序列输入的计算机视觉问题[181]。

表10展示了一些将神经网络与VSLAM相结合的优秀算法。
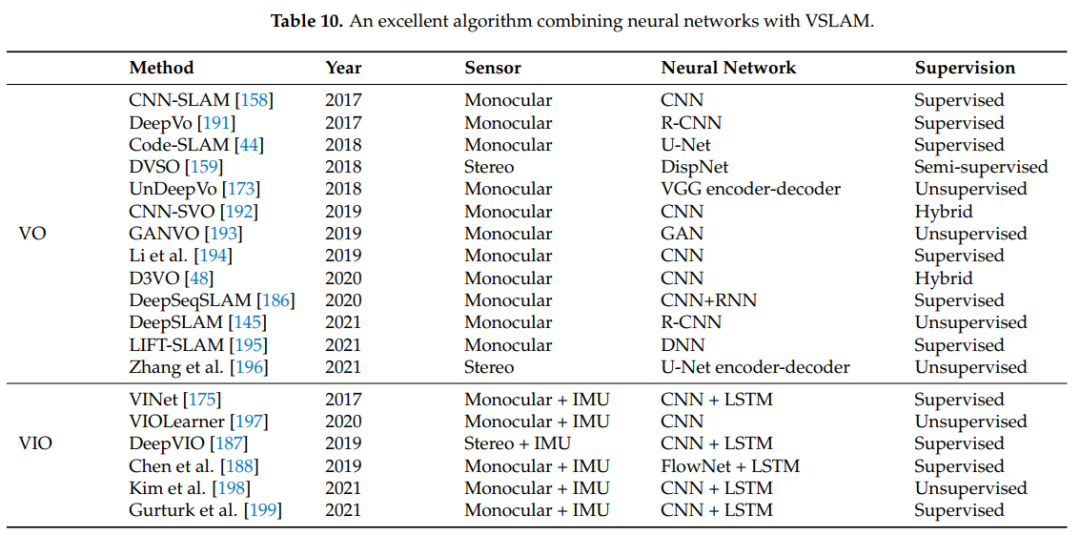
现代语义VSLAM
深度学习在姿态估计、深度估计和环路闭合检测方面取得了许多成果。然而,在VSLAM中,深度学习目前无法撼动传统方法的主导地位,然而,将深度学习应用于语义VSLAM研究中,可以获得更有价值的发现,从而快速推动语义VSLAM的发展。引用文献[60,158,168]使用CNN或RNN提取环境中的语义信息,以改进传统VSLAM中不同模块的性能。语义信息用于姿态估计和环回检测。它显著改善了传统方法的性能,并证明了语义信息对VSLAM系统的有效性。本文认为这为现代语义VSLAM的发展提供了技术支持,是现代语义VSLAM的开始。使用深度学习方法,如目标检测和语义分割,创建语义地图是语义SLAM发展的一个重要代表时期。引用文献[135,200]指出,根据不同的目标检测方法,语义SLAM可以分为两种类型。一种是使用传统方法检测目标。实时单目物体SLAM是最常见的一种,使用大量的二进制字和对象模型数据库提供实时检测。但由于“汽车”等语义类别有许多类型的3D对象实体,因此非常有限。SLAM的另一种方法是使用深度学习方法进行对象识别,例如[46]中提出的方法。
近年来,计算机性能的不断提升促进了视觉领域中实例分割的快速发展。实例分割不仅在像素级别上进行分类(语义分割),还有不同物体的位置信息(目标检测),甚至可以检测相同的物体。在2017年,何凯明等人提出了Mask R-CNN [220]。这一算法是实例分割的开创性工作。如图19所示,其主要思想是在Faster R-CNN的基础上添加一个用于语义分割的分支。
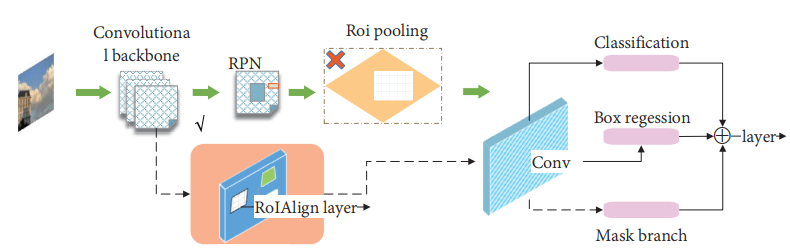
图19 MASK-RCNN框架图
尽管基于神经网络的目标检测和分割技术已经非常成熟,但实时处理仍需要强大的计算能力。VSLAM对实时操作有很高的要求,因此如何高效地从环境中分离所需物体及其语义信息将是一项长期而艰巨的任务。作为语义VSLAM的基础,在进行语义分割处理后,我们将关注语义信息对VSLAM不同方面的影响。我们将阐述定位、建图和动态物体移除三个方面。目标检测和语义分割都是从图像中提取语义信息的手段。表11展示了一些算法的贡献。目标检测比语义分割更快,但语义分割的精度更高,实例分割集成了目标检测和语义分割,在精度上表现出色,但不能保证运行速度。

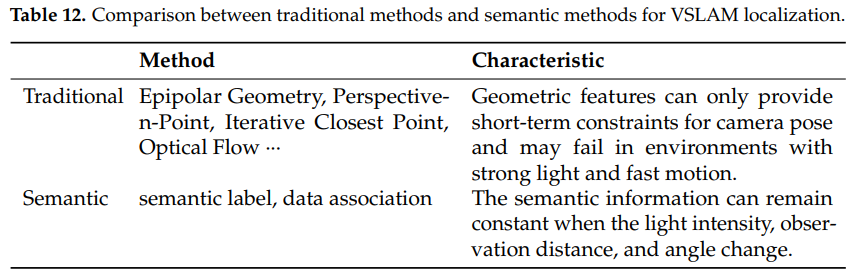
具有位置语义信息:定位精度是SLAM系统中最基本的评估标准之一,也是移动机器人执行许多任务的前提条件[225]。引入环境语义信息可以有效地提高视觉SLAM定位中的尺度不确定性和累积漂移,从而在不同程度上提高定位精度[226]。在大多数情况下,传统VSLAM仍然在定位精度方面表现良好。然而,语义帮助VSLAM系统提高定位精度也值得研究。表12比较了传统方法和语义方法在VSLAM定位方面的差异。
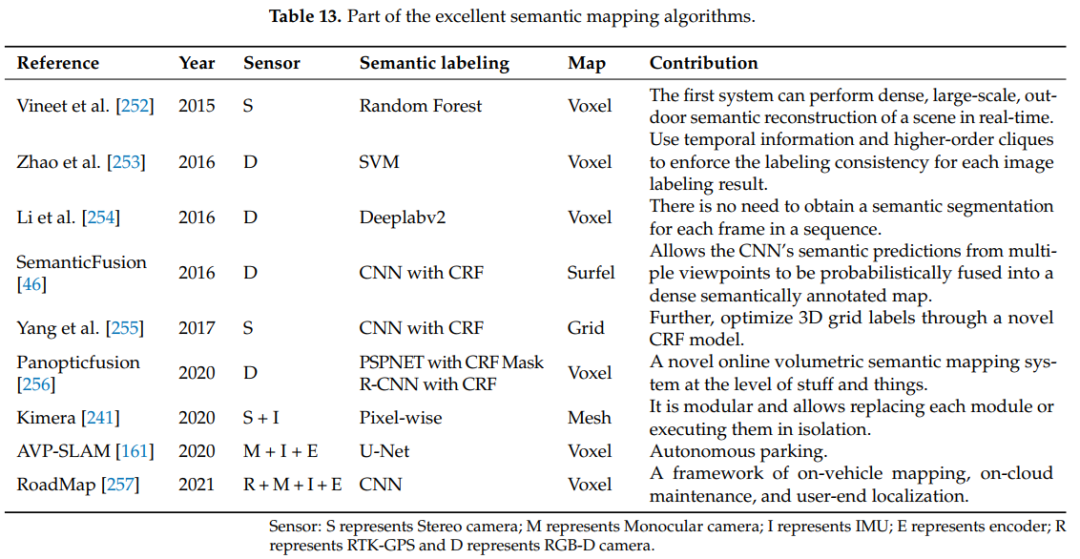
语义与建图 :VSLAM和深度学习的另一个关键交汇点是SLAM的语义地图构建,大多数语义VSLAM系统都是基于这个想法的[230]。为了让机器人像人一样理解环境并从一个地方执行不同的任务,需要一种不同于几何地图所能提供的技能[231]。机器人应该具备人类中心化的环境理解能力。它需要区分房间和走廊,或者在未来区分厨房和客厅的不同功能[232]。因此,涉及人类概念的语义属性(例如房间类型、对象及其空间布局)被认为是未来机器人的必要属性[233]。近年来,随着深度学习的快速发展,逐渐出现了包含语义信息的语义地图[234]。语义SLAM系统中的语义地图使机器人能够获取环境的特征点等几何信息。此外,它还可以识别环境中的对象,并获取位置、属性和类别等语义信息。与传统VSLAM构建的地图相比,机器人可以具备感知能力。这对于机器人处理复杂环境和完成人机交互非常重要[235]。语义地图构建是SLAM研究的热点之一[236]。2005年,Galindo等人[237]提出了语义地图的概念。如图21所示,它由两个平行层表示:空间表示和语义表示。它为机器人提供了类似于人对环境的推理能力(例如,卧室是一个包含床的房间)。之后,Vasudevan等人[238]进一步加强了人们对语义地图的理解。
目前,大多数语义地图构建方法需要同时处理实例分割和语义分割,导致系统实时性能较差[250]。表13列出了一些语义地图构建工作。此外,当处理动态物体时,大多数算法通过消除动态物体来实现系统的鲁棒性,这会使系统失去很多有用的信息。因此,面向动态场景的SLAM是需要解决的紧迫问题[251]。
去除动态物体 :传统的VSLAM算法假定环境中的物体是静态或低运动的,这影响了VSLAM系统在实际场景中的适用性[258]。当环境中存在动态物体(如人、车辆和宠物)时,它们会给系统带来错误的观测数据,降低系统的精度和鲁棒性[259]。传统方法通过RANSAC算法来解决一些异常值对系统的影响。然而,如果动态物体占据大部分图像区域或移动物体移动速度较快,仍然无法获得可靠的观测数据[260]。如图23所示,由于动态物体的存在,相机无法准确捕捉数据。因此,如何解决动态物体对SLAM系统的影响已成为许多研究人员的目标。
目前,解决动态物体对SLAM系统带来的干扰问题的解决方案是一致的。即在视觉里程计之前,使用目标检测和图像分割算法来过滤图像中的动态区域。然后使用静态环境点来计算相机附近的位置并构建包含语义信息的地图[261]。图24显示了一个典型的结构。虽然无法完全解决动态物体的影响,但系统的鲁棒性得到了极大的改善。
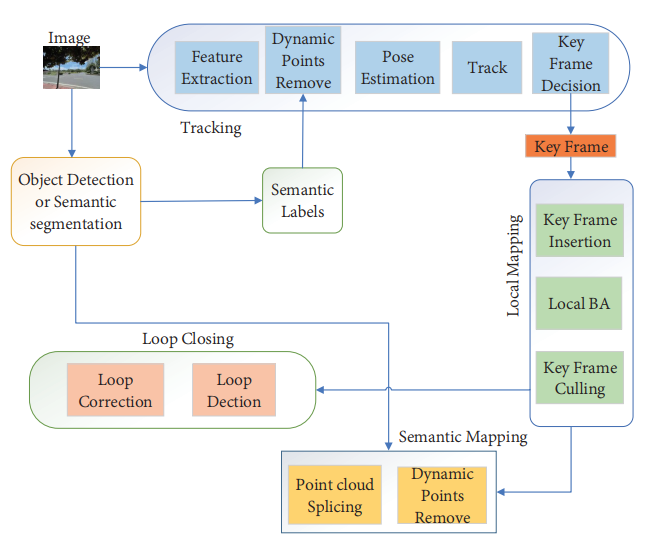
图24. 典型的动态物体去除框架
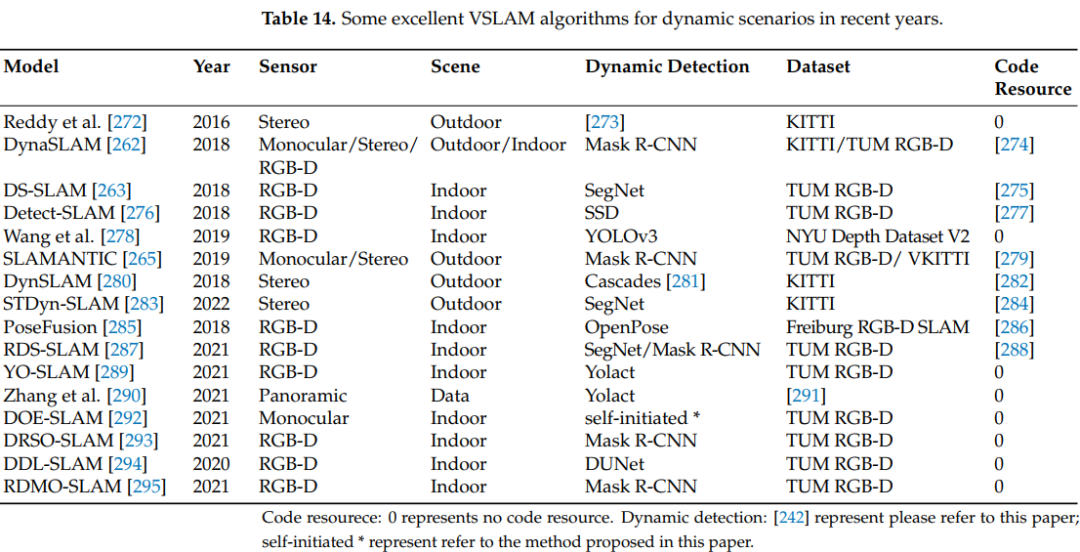
当前,由于计算资源的高消耗,语义信息可以更好地帮助系统解决动态物体带来的干扰。然而,现有方案通常不足以实时地广泛推广到实际机器人,并且应用场景受到极大限制。此外,语义信息可能无法在相机帧率内得到,或者可能不总是提供准确的数据。将图像区域分配给错误的语义类别可能会不必要地将其从姿态估计中排除,在稀疏纹理环境中可能至关重要。目前解决这个问题的方案集中在使用光流等方法来检测场景中正在移动的物体。尽管现有算法在数据集中取得了良好的结果,但在实际工程中尚未实现非常可靠的结果。表14展示了近年来使用深度神经网络改进动态环境的VSLAM算法。
总结
同时定位与地图构建是机器人学领域的一个重要研究问题,研究者们一直致力于开发新的方法来最大化它们的鲁棒性和可靠性,基于视觉的SLAM技术经历了多年的发展,涌现出了许多优秀的算法,成功地应用于机器人和无人机等各个领域。深度学习的快速发展推动了计算机领域的创新,两者的结合成为一个活跃的研究领域,因此,对VSLAM的研究越来越受到关注。此外,随着智能时代的到来,对移动机器人的自主性提出了更高的要求。为了实现机器人的先进环境感知,语义VSLAM被提出并快速发展,传统的VSLAM只在构建环境地图时恢复环境的几何特征,不能满足机器人导航、人机交互、自主探索等应用需求。然而,早期的语义地图构建方法一般采用模型库匹配方法,需要事先构建一个对象模型库,具有很大的限制性,不利于推广应用。随着计算机性能的提高和深度学习技术的快速发展,VSLAM技术与深度学习技术相结合,填补了传统VSLAM系统的不足之处。近年来,作为最有前途和有利的计算机视觉处理方法,深度学习技术受到了SLAM研究者的广泛关注,在语义SLAM系统中,环境语义信息可以直接通过深度学习技术从预先训练的图像集和实时感知的图像集中学习,它还可以用于更好地利用大数据集,给系统带来更强的泛化能力,在构建语义地图时,语义SLAM系统可以使用深度学习方法来检测和分类环境中的对象,并构建一个信息更丰富的地图,具有更好的实用性。
本文调查了大多数使用特征来定位机器人并绘制周围环境的最先进的视觉SLAM解决方案。根据基于特征的视觉SLAM方法依赖的特征类型对其进行分类;传统的VSLAM和与深度学习相结合的VSLAM,全面调查了每个类别的优缺点,并在适用的情况下,突出了每个解决方案所克服的挑战,这项工作展示了使用视觉作为唯一的外部感知传感器来解决SLAM问题的重要性,这主要是因为相机是理想的传感器,因为它是轻便、被动、低功耗,并能够捕捉有关场景的丰富而独特的信息,然而,使用视觉需要可靠的算法,在可变照明条件下具有良好的性能和一致性,由于人或物体的移动、无特征区域的幻影、白天和晚上的转换或任何其他未预料的情况,因此,仅使用视觉作为传感器的SLAM系统仍然是一个具有挑战性和有前途的研究领域,图像匹配和数据关联仍然是计算机视觉和机器人视觉中开放的研究领域,检测器和描述子的选择直接影响系统跟踪显着特征、识别先前看到的区域、建立一致的环境模型并实时工作的性能,特别是数据相关性需要长期的导航,尽管数据库越来越大且环境不断变化且复杂,接受错误关联将导致整个SLAM系统的严重错误,这意味着位置计算和地图构建将不一致。
此外,我们强调了融合语义信息的VSLAM的发展,将语义信息与VSLAM系统相结合,可以在鲁棒性、精度和高级感知方面取得更好的结果。我们将更多关注语义VLSAM的研究,这将从根本上提高机器人的自主交互能力。结合其他研究,我们对VSLAM未来的发展做出以下展望:
(1)工程应用。经过几十年的发展,VSLAM已经广泛应用于机器人等许多领域,然而,SLAM对环境光照、高速运动、运动干扰等问题非常敏感,因此如何提高系统的鲁棒性,建立长期的大规模地图都是值得挑战的问题,SLAM主要用于嵌入式平台(如智能手机或无人机)和3D重建、场景理解和深度学习等两个主要场景,如何平衡实时性和准确性是一个重要的开放性问题,解决动态、非结构化、复杂、不确定和大规模环境的问题仍需探索。
(2)理论支持。通过深度学习学习的信息特征仍缺乏直观的意义和清晰的理论指导,目前,深度学习主要应用于SLAM的局部子模块,如深度估计和闭环检测,然而,如何将深度学习应用于整个SLAM系统仍是一个巨大的挑战,传统的VSLAM在定位和导航方面仍有优势。尽管一些传统方法的模块通过深度学习得到了改进,但深度学习的范围通常不广泛,它可能在某些数据集上取得良好的结果,但在另一个场景中可能不稳定。定位和建图过程涉及大量的数学公式,而深度学习在处理数学问题方面存在缺陷,同时使用深度学习进行相关训练的数据更少,这种方法更为传统。因此,SLAM框架目前没有显著优势,主要算法仍然是SLAM技术,未来,SLAM将逐渐吸收深度学习方法,并使用更多的训练数据集来提高定位和建图的准确性和鲁棒性。
(3) 高级别环境信息感知和人机交互。随着深度学习的进一步发展,语义 VSLAM 的研究和应用将有巨大的发展空间,在未来智能化的时代,人们对智能自主移动机器人的需求将会迅速增长,如何利用语义 VSLAM 技术更好地提高机器人的自主能力将是一项长期而艰巨的任务,虽然近年来已经取得了一些优秀的成果,但与经典的 VSLAM 算法相比,语义 VSLAM 仍处于发展阶段,目前,语义 SLAM 的开源解决方案并不多,语义 SLAM 的应用仍处于初级阶段,主要是因为精确语义地图的构建需要大量的计算资源,这严重影响了 SLAM 的实时性能,随着未来硬件水平的不断提高,SLAM 系统的实时性能问题可能会得到极大改善。
(4) 建立完善的评估体系。语义 VSLAM 技术近年来得到了快速发展,然而,与传统 VSLAM 相比,目前尚无完美的评估标准,在 SLAM 系统研究中,通常使用 ATE 或 RPE 来评估系统性能,然而,这两个评估标准都是基于 SLAM 系统的位姿估计结果,而没有普遍认可的可靠评估标准来评估地图构建效果,对于语义 SLAM 系统,如何评估语义信息获取的准确性以及如何评估语义地图构建的效果是应该考虑到语义 SLAM 系统评估标准的问题,此外,仅通过主观指标进行评估不是长期解决方案,未来,如何建立系统的评估指标成为一个热门话题。
更多详细内容后台发送“知识星球”加入知识星球查看更多。
智驾全栈与3D视觉学习星球:主要针对智能驾驶全栈相关技术,3D/2D视觉技术学习分享的知识星球,将持续进行干货技术分享,知识点总结,代码解惑,最新paper分享,解疑答惑等等。星球邀请各个领域有持续分享能力的大佬加入我们,对入门者进行技术指导,对提问者知无不答。同时,星球将联合各知名企业发布自动驾驶,机器视觉等相关招聘信息和内推机会,创造一个在学习和就业上能够相互分享,互帮互助的技术人才聚集群。
以上内容如有错误请留言评论,欢迎指正交流。如有侵权,请联系删除
扫描二维码
关注我们
让我们一起分享一起学习吧!期待有想法,乐于分享的小伙伴加入知识星球注入爱分享的新鲜活力。分享的主题包含但不限于三维视觉,点云,高精地图,自动驾驶,以及机器人等相关的领域。
分享与合作方式:微信“920177957”(备注:姓名+学校/公司+研究方向) 联系邮箱:dianyunpcl@163.com。
点一下“在看”你会更好看耶



















 3759
3759

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











