







 warmup与余弦退火学习率策略通过逐步提升然后按余弦函数衰减学习率,帮助模型避免初期过拟合,加速收敛,并保持稳定性。在PyTorch中,可以通过GradualWarmupScheduler实现此策略,结合tensorboard可直观观察学习率变化。该策略在训练初期从较小学习率开始,逐渐增加到最大值,随后以余弦曲线方式降低,确保模型优化过程平稳。
warmup与余弦退火学习率策略通过逐步提升然后按余弦函数衰减学习率,帮助模型避免初期过拟合,加速收敛,并保持稳定性。在PyTorch中,可以通过GradualWarmupScheduler实现此策略,结合tensorboard可直观观察学习率变化。该策略在训练初期从较小学习率开始,逐渐增加到最大值,随后以余弦曲线方式降低,确保模型优化过程平稳。
warmup与余弦退火学习率的主要思路是学习率先从很小的数值线性增加到预设学习率,然后按照余弦函数值进行衰减。为什么要这么做的呢?主要有如下原因:
1. 在模型的训练之初weights是随机初始化的,可以理解模型对数据的“理解程度”为0,也就是说没有任何先验知识,在第一个epoche中,每个batch的数据对模型来说都是新的,模型会根据输入的数据进行快速调参,此时如果采用较大的学习率的话,有很大的可能使模型对于数据“过拟合”,后续需要更多的轮次才能“拉回来”;
2. 当模型训练一段时间之后(如:10epoch或10000steps),模型对数据具有一定的先验知识,此时使用较大的学习率模型就不容易学“偏”,可以使用较大的学习率加速模型收敛;
3. 当模型使用较大的学习率训练一段时间之后,模型的分布相对比较稳定,此时不宜从数据中再学到新特点,如果仍使用较大的学习率会破坏模型的稳定性,而使用小学习率更容易获取局部最优值。
学习率的变化趋势类似下图所示,学习率先从很小的数值线性增加到一个最大的学习率,然后按照余弦函数值进行衰减:
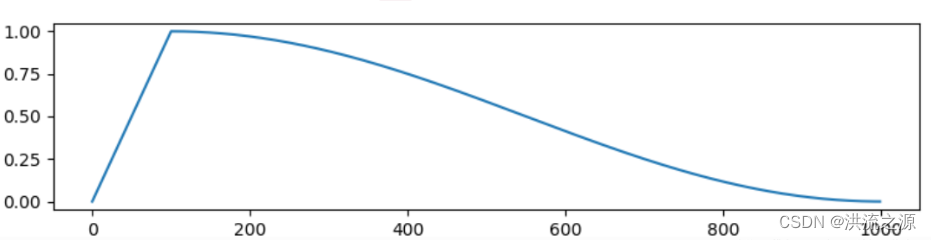
在pytorch中实现warmup与余弦退火学习率的伪代码如下:
from warmup_scheduler import GradualWarmupScheduler
MAX_EPOCH=100
INIT_LR = 0.01
WARMUP_LR_TIMES = 10
WARMUP_EPOCH = 5
optimizer = optim.SGD(net.parameters(), lr=INIT_LR, momentum=0.9)
cosine_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer=optimizer,
T_max=MAX_EPOCH,
eta_min=0,
last_epoch=-1)
scheduler = GradualWarmupScheduler(optimizer,
multiplier=WARMUP_LR_TIMES,
total_epoch=WARMUP_EPOCH,
after_scheduler=cosine_scheduler)
for epoch in range(1, MAX_EPOCH):
... ...
optimizer.step()
... ...
scheduler.step(epoch)
print(epoch, optim.param_groups[0]['lr'])
... ...API :
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1, verbose=False)
optimizer:学习率调整器作用的优化器,在初始化optimizer时就设定了初始学习率。
T_max:最大迭代次数或最大epoch数量。
eta_min:最小学习率。
last_epoch:最后一个epoch的index,默认值为-1。如果是训练了很多个epoch后中断了,继续训练,这个值就设置为加载模型的epoch,-1表示总是从头开始训练。
verbose:若为true,每次更新时会打印一些信息。
GradualWarmupScheduler(optimizer, multiplier, total_epoch 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2868
2868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











