






摘要:研究了一种主动、自然的室内环境中未知物体的检测问题。提出了一种同时利用颜色和深度信息的视觉显著性方案,以唤起机器系统在三维场景中显著位置检测未知物体的兴趣。在突出位置的三维点被选择为种子点,用三维形状生成对象假设。我们在马尔可夫随机场(MRF)上对三维场景的体素进行多类标记,结合对象假设和三维形状的线索。MRF的结果进一步细化合并标记的对象,它们之间的空间连接和颜色直方图之间有很高的相关性。定量和定性两基准RGB-D数据评估说明所提出的方法的优点。在移动机械手上进行目标检测和操作实验,验证了该方法在机器人应用中的有效性和实用性。
关键词:未知目标检测;显著性检测;RGB-D对象分割
1 介绍
当处于一个陌生的视觉环境时,人类变得如此自然地快速聚焦、分割和识别物体,以便帮助了解他们的情况,促进机动性和与物体的交互。然而,这仍然是智能机器系统的一个持续的挑战。许多研究团体一直致力于目标检测的核心问题,以分割出不仅学习对象[1,2],但还未知的对象[ 3–7 ]从各种干扰的环境中。与已知对象不同,先前未知对象的检测更具挑战性,因为它不能依赖已存在的对象模型。检测未知对象的能力变得更加重要,特别是在机器人应用程序中,它需要对环境中的新对象起作用。这项工作的重点是分割以前未知的对象的问题。因此,我们将不使用任何先验知识的对象被检测到。我们开始捕捉RGB和深度图像对,如图1a、b所示,从Kinect深度摄像头。由于吸收或分散Kinect IR的区域被填充为零像素值,因此通过用周围25像素的统计模式替换零值像素来平滑深度图像[ 8 ]。同时,现场的点云重建和voxelized。我们首先提出了一种新的基于颜色的显著性检测方法来检测RGB图像中的显著位置,并利用深度显著性方法在深度图像中找到具有较高中心环绕深度对比度的显著位置。两种突出位置(如图1a中的红色加成)都投射到三维场景中,作为对象假设的候选种子点。然后,我们使用三维形状(例如,对象的大小)建模有效的对象假设,并在一个多层次的3D场景标记的计算框架中执行对象推断。通过合并空间连通的标记对象和颜色直方图之间的高相关性,进一步改进了标记结果。图1C显示了示例场景的最终标记结果,其中不同的检测对象分别被着色。图1D显示了相应的包围盒。
本文的贡献有三个方面:(一)提出了一种基于视觉显著性检测方法的新的颜色,这是加强深度显著的方法找到足够的显著位置,类似于人的眼睛注视;(ii)我们采用三维形状有效地生成对象的假设选择的要点,强调了一个场景中心在多类三维场景标签的计算框架RGB-D对象分割视图;和(iii)我们展示了定量和定性的评价结果对目标检测的基准数据集和两RGB-D实验验证了该方法的有效性对对象的操作任务使用移动机械手。
2实际工作
本文的工作属于主动分割或注意驱动的分割研究的范围,这是首次由Aloimonos等人提出的。[ 9 ]。它的灵感来自于人眼视觉观察和理解一个场景/图像通过一系列固定后分割。米斯拉等人的作品。[ 5 ]已经展示了如何分割一个固定对象,而不是一次分割整个场景,这是一个更容易和更好的定义问题。他们利用边界所有权的概念,找到感兴趣的对象内的固定点,然后提取周围的点的最佳闭合轮廓。闭合轮廓最终作为检测对象的边界。可以看出,主动分割一般分为两个阶段:(1)检测固定点;(二)从固定点分割目标种子。
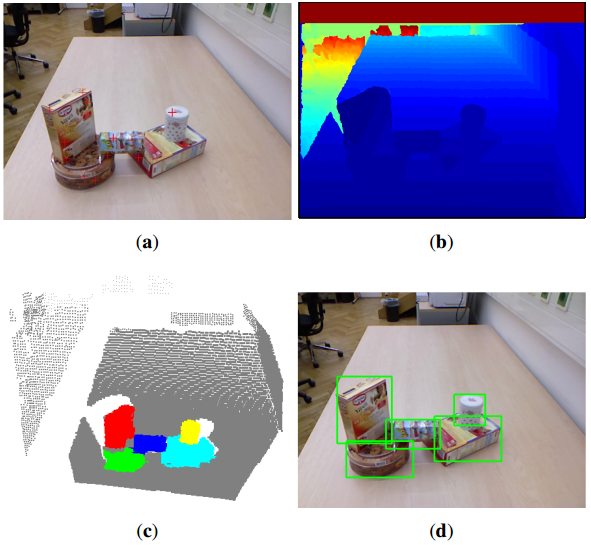
图1。给定一个RGB图像(一)随着每个像素的深度信息,(b)利用RGB-D摄像头拍摄的,我们发现可能的位置(由红色加表示)在生物启发的方式,以前看不到的物体,生成和模型对象的假设,段RGB-D对象在多类标签的框架,最后提炼检测对象。输入场景的目标检测结果被显示为一个彩色点云(c),其中背景是灰色的,而被检测的对象则有其他颜色。(d)用边界框显示被检测对象。
为了检测固定点的问题的解决方案中,最常用的方法是选择固定的显著图的关注点,这可能是由不同的视觉显著性检测方法产生的。视觉显著性检测涉及到认知心理学、神经生物学和计算机视觉等多个学科。许多著名的自底向上的视觉注意模型被提出[10,11]。而自下而上的关注是由基本物理特性的一个场景,如强度、颜色、方向等和低层次的确定,其他阶段,称为自顶向下的注意,这是由任务、情绪、预期等的影响,也有人建议。一些研究[ 14 ] 12–也建议有在显著性检测方案:本地和全球方案。局部方案研究图像区域与其局部环境之间的差异,而全局方案的目的是寻找与之相对应的显著区域。
为了检测固定点的问题的解决方案中,最常用的方法是选择固定的显著图的关注点,这可能是由不同的视觉显著性检测方法产生的。视觉显著性检测涉及到认知心理学、神经生物学和计算机视觉等多个学科。许多著名的自底向上的视觉注意模型被提出[10,11]。而自下而上的关注是由基本物理特性的一个场景,如强度、颜色、方向等和低层次的确定,其他阶段,称为自顶向下的注意,这是由任务、情绪、预期等的影响,也有人建议。一些研究[ 14 ] 12–也建议有在显著性检测方案:本地和全球方案。局部方案研究图像区域与其局部环境之间的差异,而全局方案的目的是寻找与全球环境不同的显著区域。为深度数据,很少有研究试图探讨场景深度影响的显著性检测[15,16]和显示的深度信息可以对视觉注意的显著影响。通过potapoval等人提出了一个有趣的工作。[ 6 ]研究了局部三维对称性对视觉显著性的影响,结果表明基于三维对称性的显著图比二维显著图更好地捕捉场景的特征。
在本文中,我们的目标是找到一个通用的和非常有效的视觉显著性检测方法,可以检测RGB-D场景突出三维点具有良好的检测性能。因此,我们提出了一种新的基于颜色的显著性检测方法,即强度显著性(SS),它利用局部和全局信息进行检测。一般来说,SS将输入图像作为一个整体系统,其中每个像素被视为一个实体,它可以对其他实体施加影响,这取决于它的强度和邻近实体的邻近程度。实体在全球演化过程中相互作用,直到每个实体保持不变的力量。整个系统的强度分布产生一个全分辨率显著图。因此,SS提供了一种新的简单而有效的方法,将局部和全局的方案结合到显著性检测中,从而补充了最新的显著性检测方法。此外,我们利用深度线索来检测基于各向异性中心环绕差的基于颜色的方法无法发现的更多突出点[ 15 ]。
作为在RGB-D场景虚拟物体分割的问题,马尔可夫随机场(MRF)的技术此前已应用于对它作为一种3D的全球多类分割问题。赖等人。[ 1 ]提出的分割对象在重建的三维场景使用MRF框架连续RGB-D图像。然而,对象假设不是由固定点产生的,而是一些预先学习的二维对象模型。因此,它不能检测以前未知的对象。他们的方法中的一个重要技术是将三维形状应用到MRF中,以实现标签的平滑性,并帮助清除由对象假设引入的虚假信号。约翰逊等人。[ 3 ]建议从种子点创建虚拟对象的颜色模型,并执行多类分割。分割过程是迭代的,而颜色模型是更新的。在这项工作中,我们建议使用三维形状(特别是物体大小)从种子点生成物体假设,并发现这种简单和快速的方法是足够的播种时,从我们的显着性方法检测到的固定点。我们结合对象假设和MRF的三维形状的线索,并利用颜色线索,进一步完善标签的结果。因此,我们的方法利用三维形状和颜色信息,以寻求更多的鲁棒性和准确性的目标检测。
3.未知的RGB-D目标检测
为了解决在RGB-D图像未知目标的检测问题,我们强调一个场景为中心的观点在RGB-D图像视为一个独立的三维场景的一部分。然后,我们将3D场景的一部分表示为一组体素v。每个体素V带标签的yv= 1;···;C,cb; 1;···;C是虚拟对象类和CB是背景类。因此,未知目标检测问题可以看作是三维场景中的多类标记问题。我们的场景中的主要挑战是,对象类的集合以前是未知的,需要通过多对象假设在线生成。同时,由于不具备先验信息,检测方法也需要处理对象假设的不准确性和不确定性。然后,我们使用基于MRF技术的体素类标签的联合分布模型,这已被用于许多标记任务,并可以提供一个统一的计算框架相结合的地方证据与区域之间的依赖关系。三维场景的最优标号最小化了以下能量:
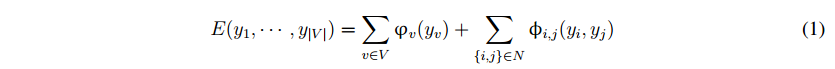
其中n是所有对相邻体素的集合。数据项的V(电视)的措施以及如何分配的标签符合观测到的数据,和成对词φ我;J(彝族;YJ)模型之间的相互作用的相邻体素,如标签平整度。MRF中的数据项通常表示为负对数似然:
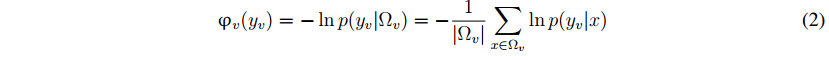
其中X表示一个三维点,ΩV是V和P素的3D点集(yvjx)是X点属于概率类电视。我们将基于显著性检测生成多对象假设(参见第3.2节)(参见第3.1节)。得到一组可能的对象类,并进一步对属于对象类的每个点的概率进行建模。成对术语将在第3.3节讨论,在这里我们还引入了一种直观的方法来改进检测结果。
3.1。视觉显著性图的生成
在这项工作中,我们探讨如何快速检测未知物体的可能位置在生物启发的方式。提出了一种新的显著性检测方法,即强度显著性(SS),用于生成显著性地图,用于预测人体固定,从而获得可能的物体位置。其基本思想是,给定的图像被视为一个系统,每个像素可以对其他像素施加影响,这取决于它的强度和邻近像素的距离。在我们的实现中,我们建立在图像边界不突出或无趣的前提下,因此,它们的像素作为高强度的初始实体。一个实体与另一个实体在特征空间中的相似性越大,它们的优势就越相似。实体相互作用,直到每个实体保持不变的强度。整个系统的强度分布产生了全分辨率显著图。
具体来说,我们发现图像的显著性在CIE L*a*b*颜色空间(CIELAB);因此,只有彩色图像的应用。输入RGB图像i以像素p表示,具有特定特征f、i=f(π、FI)g、i=1;···m;m,其中m是像素总数。s(pi)表示pi的强度。位于四个图像边界上的所有像素被选择为初始实体,其强度为1。图像边框的宽度或高度的定义是δ。实体之间的距离定义为多尺度空间距离为8邻域,以及相应的特征空间的出现距离。我们把S=1;···;实验中的4。实体之间的诱导交互手段被定义为:

pi是一个8s的相邻像素的po,η表示增益η(PO)= S(PO)、D(PI;PO)代表在选定的特征空间和maxdist PI和PO的L2之间的距离是在特征空间中的任何两个特征向量之间的最大距离。我们选择分离的CIELAB颜色通道的特征空间。方程(3)表明像素在特征空间中与另一个像素的相似性越大,它们的优势就越相似。由于一个实体将从不同的来源获得各种影响,我们更新PI的强度:
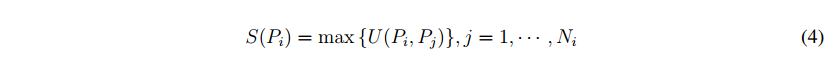
其中ni是影响pi的实体数,其强度被选择为来自不同来源的最大值。基于方程(3)和(4),更新过程可以迭代,直到每个像素保持不变的强度。任何像素PI显著是最后计算为1−S(PI),产生一个全领域的显著图

基于上述框架,我们可以在不同的邻域尺度上生成不同的特征空间中的多个全域显著图。利用L2归一化对这些映射进行汇总和归一化。算法1对算法进行了总结。图2的第三列显示了一些示例结果。我们将在4.1个基准数据集上对该算法进行评估,并在第三节中展示其良好性能。虽然颜色线索在显著性检测中起着重要的作用,但它们不能检测出与背景颜色相似的物体。例如,场景中的订书机不能从周围环境突出显示(见图2)。因此,我们利用一种基于各向异性中心环绕差的深度显著性方法(15)来增强基于颜色的显著性检测方法,以发现更显著的位置。在考虑全球深度结构的同时,根据这些点的深度值来衡量一个点与其周围的环境有多大关系。图2的第四列显示了基于深度的显著图。然后将基于颜色的显著图和基于深度的显著图引入显著性播种过程,在下一个分段中引入。

图2.给定一对RGB图像(a)和深度图像(b),该算法强度显著性(SS)输出基于颜色的显著图(C),而所采用的方法(15)输出基于深度的显著图(d)。这两种显著图相互补充,找出足够显著的位置。
3.2。显著性播种与虚拟对象建模
为了从输出显著图中估计可能的对象位置,最简单的方法是使用一个固定的阈值。然而,当峰值在显著区域之间出现较大方差时,这种方法将变得不利。通过重建操作的开放,然后通过查找区域极大值来检索粗糙对象区域[ 17 ]。具体来说,形态侵蚀是使用20像素的圆盘形结构元素使不良的小峰的同时保持理想的大峰的显著图进行。然后利用原始图像作为掩模对被腐蚀图像进行形态学重建。然后计算区域极大值,选择平坦峰作为粗糙对象区域。这些区域的质心,然后作为虚拟对象的候选种子点。我们进一步删除种子点,这是位于主要的三维支持面垂直于重力矢量。具体来说,我们首先用一个简单而可靠的方法计算重力向量[ 18 ]。该方法试图在尽可能多的点上找到与局部估计的表面法线方向最一致或最正交的方向。然后选取与重力向量一致的法向量作为支撑面点。最终提取出主支撑面,使大多数选定点在世界坐标系中具有几乎相同的高度。图1a显示了示例图像的生成种子点。
假设生成了C种子点;一组虚拟对象类形成为f1;····CG。我们建议使用三维形状来建立物体假设模型:
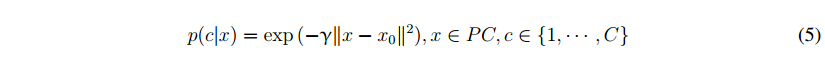
其中x0是相应的种子点的三维点,X代表任意点的点云PC的输入图像和γ管制如何迅速在米增加空间距离的概率降低。γ越大,物体假设的三维尺寸越小。图3显示了当γ=180时来自不同种子点的一些生成的对象假设。在实验中,我们将研究γ如何影响目标检测的准确性。从图3中可以看出,我们的模型只能获得真实对象的一部分的概率图。然而,它表明,不同的标签的真实对象的不同部分可以通过MRF在一定程度上平滑。特别是,它们可以通过直观的精化方法进一步合并,并在下一小节中介绍。为了获得背景概率,我们利用C对象假设的前景概率:
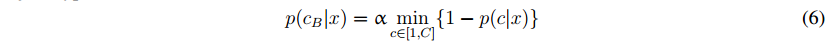
在α经验设置为0:1。此外,位于支配支撑面上的点与一个概率值相关。通过使用方程(5)和(6),可以很容易地计算方程(2)中的数据项。

图3。分别从4个种子点(用红色加号表示)建模虚拟对象的示例,以获得在所有像素上定义的概率图。
3.3。RGB-D对象提取
在MRF中的数据项建模之后,如等式(1)所示,我们希望进一步加强场景标记的上下文约束。例如,在光滑表面上的体素应该分配相同的标号。我们使用赖的模型[ 1 ]来编码邻近体素之间的相互作用:
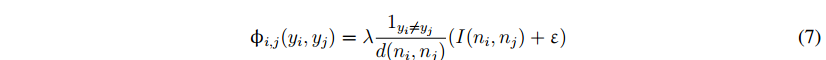
在λ和“平衡参数,1yi6 = YJ评价一当y6=YJ,D(Ni;NJ)测量表面正常Ni和NJ,之间的差异分别,体素I和J是L2距离加上一个小的常数作为表面法线之间的距离度量。i(ni,nj)表示体素i和j之间的表面转换是否是凸的,这是由:
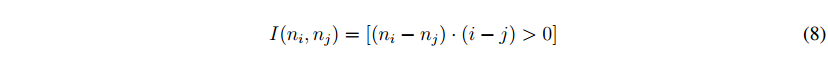
从等式(7)中可以看出,如果它们被赋予不同的类标签,那么这些具有相似的法线和凸面转换的体素将花费很多。这个成对项和数据项一起定义了一个多类成对MRF,如方程(1)所示,其能量可以用图割[ 19 ]快速最小化。
图4显示了表演的MRF优化后的多类标签为例输入RGB-D图像。我们可以看到14个对象从场景中分割出来,即使超过14个虚拟对象被建模。这意味着MRF可以在一定程度上处理对象假设的不精确性和不确定性。然而,对象,如手电筒,碗和谷物盒,不被标记为一个对象,分别。为了解决这个问题,我们建议以直观的方式进一步改进标记结果,使具有一致颜色模型的空间连接点云合并为一个对象。例如,手电筒被标记为两个物体。对应的两点云在空间上有着相似的颜色。我们使用3D颜色直方图对物体外观进行建模。每一个RGB颜色通道被分成20个垃圾桶,总共有8000个垃圾箱,用来代表二次标准化的颜色直方图。我们进一步计算相关系数来测量两种颜色直方图之间的相似性。如果相关系数大于τCE,这是经验设置为0.5,我们认为,两连接的对象应该是一个真正的对象两部分,以及相应的点云应合并和标记的一类。通过执行这些操作,图4B所示的多类标记结果被细化,如图4所示。我们可以看到真实对象的错误分割部分被正确合并,从而使主动检测的对象更符合人类的感知和分割。
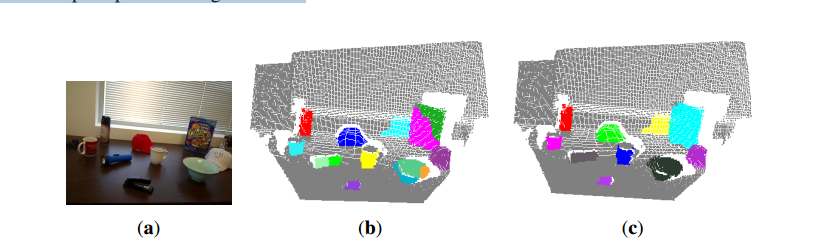
图4。多类标记结果(B)为例,输入RGB-D图像(一)(只有RGB图像所示)执行马尔可夫的随机场后(MRF)优化;(c)进行细化操作后的最终结果。不同的物体是随机着色的。
4。结果与讨论
为了验证未知物体检测方法的性能,尤其是对常见的机器人的操作任务,我们使用了两个公开可用的RGB-D数据集,对象分割的数据集(OSD)[ 7 ]和[ 20 ] RGB-D场景数据集,用Kinect式传感器评估如何成功的方法检测未知物体。这两个数据集都包含了常见的室内场景,每天的物体被随机地放置在台面、桌子、书桌、地面等。在某些场景中,物体被堆叠和遮挡,使得物体检测更加具有挑战性。此外,由于我们的工作重点是对对象的操作,我们的研究对象有一个小的、可理解的大小。因此,我们主要是在评估和实验中对未知的日常物品进行检测。
物体的地面真实性被表示为感兴趣对象周围的包围盒。因此,我们将检测到的物体在三维场景中的点云投影到二维图像中,计算投影像素包围盒与地面真实包围盒之间的重叠。重叠是根据边界盒的交集和联合的比率计算的。如果重叠大于0.5,则将对象视为检测到的。计算精度,召回率和F1测量分数来证明我们的方法的性能。由于提出的显著性检测方法在整个目标检测过程中起着重要的作用,我们首先进行人体固定预测实验,对多个基准数据集上的显著性检测方法进行定量和定性评价。其次,我们报告两基准RGB-D数据对象的检测精度。最后,将该方法应用于真实机器人场景中未知目标的检测。被检测的对象然后被移动机械手操纵时,它被要求执行的行动,如清理地面。cy Detection
4.1。显著性评价
我们进行人类固定预测实验来评估所提出的显著性检测方法。三眼运动数据集,麻省理工学院[ ],多伦多[ 22 ]和23号航班,都是公开可用的,用作基准数据集。第一个数据集,麻省理工学院(21),由贾德等人介绍,包含1003个景观和肖像图像。由布鲁斯等人介绍的第二个数据集多伦多[ 22 ],包含120幅室内和室外场景图像。Kootstra [ 23 ]数据集包含100张图片,包括动物、花卉、汽车和其他自然景观。为了定量评价一致性特别显著图和一组眼跟踪的图像固定之间,我们用三个指标:曲线下面积(AUC)ROC,归一化的扫描路径的显著性(NSS)和相关系数(CC)。对于AUC度量,我们使用了一种新型的实施,AUC borji [ 24 ]。这些公制代码可在网站上[ 25 ]查阅。我们所提出的方法比SS与八个国家的最先进的显著性检测方法,包括itti2 [ 26 ],sigsal [ 27 ],GBVS [ 26 ],太阳[ 28 ],目标[ 22 ],LP [ 21 ]、[ 12 ]和BMS系统[ 14 ]。为了简单起见,比较的方法被命名为这里没有额外的意义。
评估指标对模糊非常敏感。通过对图像中高斯模糊标准差(STD)进行参数化,对因子进行了明确分析,以更好地理解每种方法的比较性能。我们设置高斯模糊性病从0 - 0.16的图像宽度。最佳的AUC borji,NSS和CC的分数各法配合相应的高斯模糊性病在三个基准数据集在表1–3报道。对于每一个度量,在所有三个基准数据集上,当每个方法的平均得分比较时,所提出的方法SS达到了最高的性能。方法,BMS也GBVS竞争这些比较方法之间。图5显示了SS和其他八个最先进的方法产生的样本显著图。样本输入图像是从三个基准数据集中随机选择的。从这个图中,我们可以看到许多比较的方法倾向于边界,而不是突出对象的内部区域。相比之下,我们的方法SS可以更好地执行,不仅检测的显着边界,但也内部区域。这样的优点有助于在以后的过程中检测未知对象。
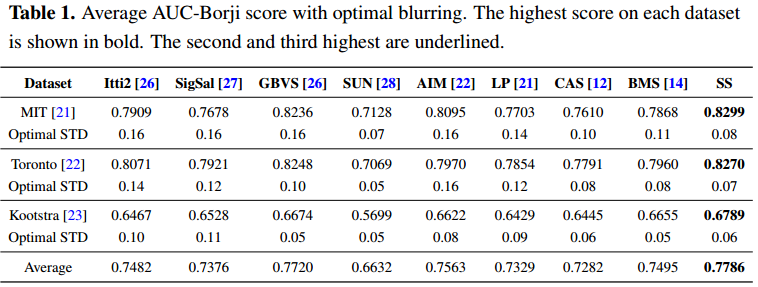
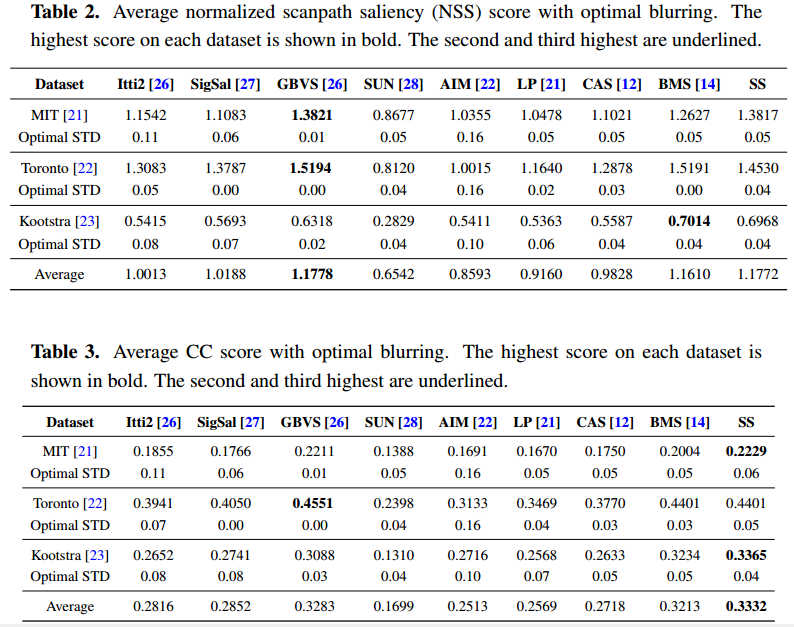

图5。三种基准眼动数据中九种方法的显著图比较。前两列样本图像和固定热地图从麻省理工、多伦多和Kootstra的数据(每个数据集显示了三的样本图像)。固定的热图通过在原始眼睛固定地图上应用高斯模糊来计算。其余的列显示从最先进的方法和我们的方法,SS显著图。
4.2。未知目标检测的评价
在OSD数据[ 7 ],有111的RGB-D图像上对象表。这个数据集是非常具有挑战性的,因为不同类型的日常对象是随机定位,堆叠和闭塞。我们为每一对RGB和深度图像检测未知对象,并在整个数据集上报告对象检测的精度、召回率和F1度量分数。检测结果如图6所示。图6A显示了对象假设模型中参数γ在不同设置下的三种检测精度的变化。结果表明,参数γ对该数据集的检测精度影响不大。我们的方法可以实现高的检测精度超过90%,其优点是,提出的显著性检测和播种方法可以产生更多的种子点突出的物体在前景比非明显的对象在后台。检测的召回率相对较低,但仍达到80%左右。这是因为这个数据集中的大多数图像包含了堆叠和闭塞的对象。被遮挡物体的不同部分总是分割成不同的对象,而具有相似外观的堆叠对象被分割为一个对象。图6b显示相应的分数时,使用相对最优的参数γ= 180,并达到最高的F1得分。图7显示了我们的方法的一些定性的结果,以及Richtsfeld等人提出的方法。[ 7 ]。结果表明,所提出的显著性引导检测方法可以去除许多不相关的背景,产生的物体数量比7中的方法小得多。虽然[ 7 ]中的方法是利用机器学习对整幅图像中的物体表面斑块进行聚类,但存在过分割问题。例如,图7的第一个场景中只有四个感兴趣的对象,但是[ 7 ]中的方法输出几乎26个对象。下面将比较这些方法的特点。
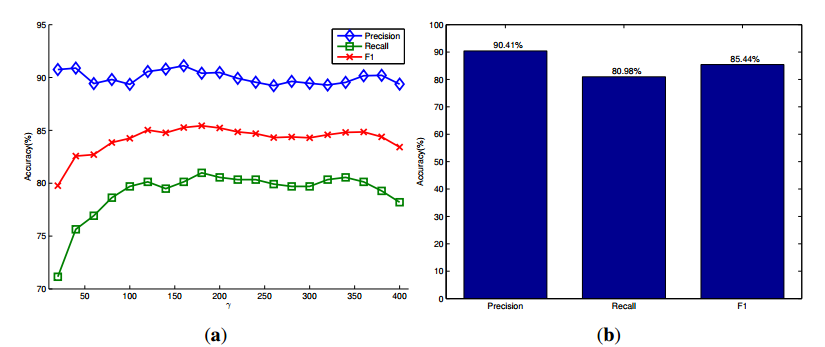
图6。OSD数据集的定量评价。(a)对象假设模型的精确度、召回率和F1测量分数与参数γ分别;(b)使用γ=180时相应的分数。
在RGB-D场景数据集[ 20 ],有六种类型的对象(如弓、帽、麦片盒、咖啡杯、手电筒和苏打水),在不同的场景设置中出现,如在一个厨房,一个会议室,在一张桌子,桌子上。这些设置导致数据集中总共有八个场景。每个场景包含一个序列的RGB-D图像从不同的观点。仅针对这六类对象的对象检测的成功率报告,因为其他类别的对象的地面真相是不可用的。检测结果如图8所示。图8显示检测精度的变化(召回精度)在不同参数设置下γ每个场景。在RGB-D现场数据集的大多数情况下,最优或次优的γ实现高召回对象的检测精度是80左右。这意味着,我们可以生成一个稍微大一点的对象假设,以减少过度分割的可能性。然而,它将不可避免地牺牲探测精度。经验证明,在考虑精度和查全率的情况下,处理不可预知的场景,通过将γ值设为180可以实现未知目标检测的良好性能。此外,我们还发现参数γ与生成对象假设种子点的方法有关。生成种子点的其他方法可能与本文所述的最优γ值不同。图8b显示一些成功地检测对象相比,在每个场景中物体的总数时,采用最优参数。可以看出,在八的情况下table_small_2,达到检测精度高达98:52 %。这主要是因为这个场景只包含了几乎有不同外观的四个前景对象,而且背景很简单。然而,第五种情况meeting_small_1更有挑战性。每个图像中的对象数总是大于10。它们常常被其他物体或图像边界遮挡。特别是,许多突出的对象在事实中没有被标记为前景对象。因此,检测成功率相对较低。总的来说,在整个数据集上的检测率是令人满意的,并验证了该方法的良好性能。如表4所示,我们的结果与[ 5 ]中报告的检测率是有竞争力的,尽管在我们的评估中,数据集中每个场景的大量图像用于检测。一些定性结果也如图9所示。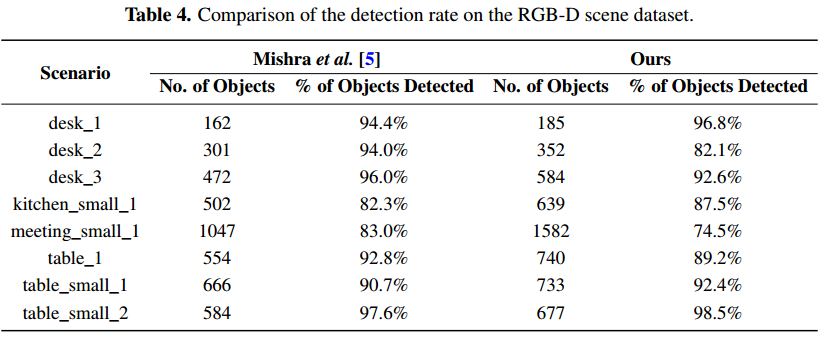
表5报告的运行时间,我们目前的单线程C++实现该方法的一个典型的640×480室内场景RGB-D图像。它运行在2.4GHz的双核64位Linux的笔记本电脑的内存16 GB。在主动分割的第一阶段,使用颜色和深度线索检测固定点需要0.23秒左右。绝大多数的计算都花在分割阶段,其中计算三维点法线和MRF优化是耗时的。对象假设生成、标记对象的细化和检测对象的呈现都需要很短的时间。总的来说,它需要大约3的利用当今的计算机硬件RGB-D框架的过程

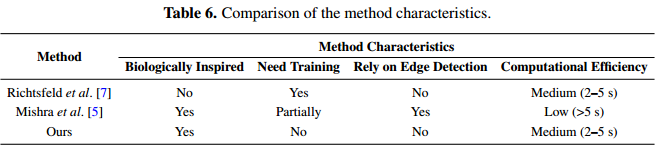
表6比较了这些方法的一些特点。与其他两种具有生物启发性的方法不同,7中的方法不遵循主动分割的方法,其目的是利用机器学习对整个图像中的物体表面斑块进行聚类。因此,分割性能将取决于训练集,它将产生更多的对象提案。[ 5 ]中的方法高度依赖于[ 29 ]中的边缘检测器,这是非常耗时的。它还需要训练来学习确定该方法中深度边界的一些参数。一般来说,所提出的方法被证明是更通用的和有效的。

图7。Visual examples of unknown object detection on the OSD的数据集。the shows the first column with the detected场景图像输入overlapped种子点(红色加工对象hypotheses)。第二和第三列显示盒和the bounding着色点云的对象detected学院,分别。the last column shows the detection using the method提出的结果〔7〕。
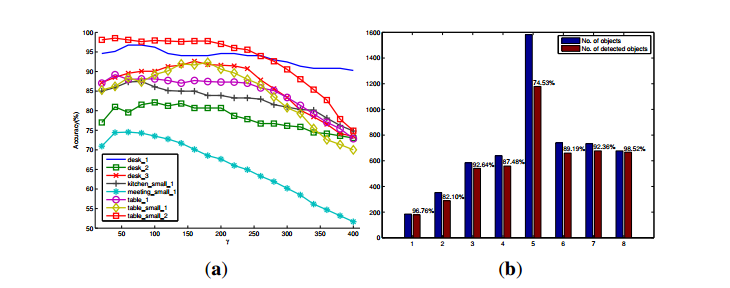
图8。八种情况对RGB-D场景数据的定量评价。(a) The
成功的检测百分比与参数γ在对象假设模型的八个场景中分别;(b)使用最佳参数在每个场景中的对象数量以及被检测对象的数量。

图9。Visual examples of unknown object detection on the RGB三维场景的数据集。
表6。of the method的特点比较。
4.3。未知对象检测和操作
我们还测试了我们的目标检测方法操作任务使用配备Kinect摄像头移动机械手系统,如图10A所示。该移动机械手由一个七自由度机械手和一个非完整移动基地。我们实现了我们的目标检测算法在基于核心库的机器人平台的感知模块nestk [ 30 ]中。所开发的图形用户界面的观察对象检测过程图10b所示。目前,它让我们实现大约三秒的时间过程中的一个典型的室内场景版。在实验中,移动机械手使用感知模块检测未知物体,并计算被检测物体的属性(如物体大小、抓取位置等)。当机器人被命令执行一个任务,如通过对话接口清理地面时,机器人就开始通过自然语言处理模块、接地模块和动作模块来处理人类的发声,这是我们在以前的工作中开发的[ 31 ]。然后,该任务被转换为一系列的机器人动作(即,移动到,开放的手爪,闭合夹具等)和移动机械手执行的轨迹。
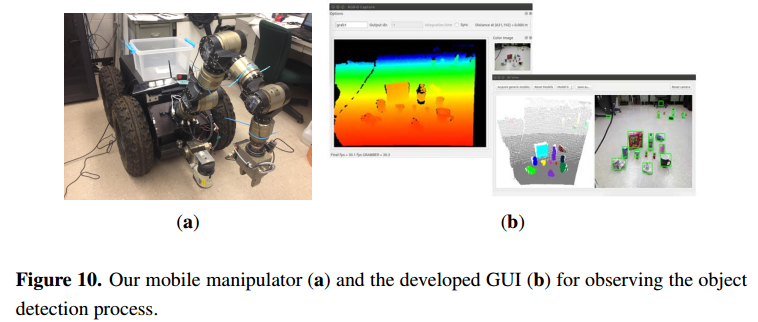

图11显示了一个典型的实验场景。一些日常使用的物品被随机地放置在我们实验室的地面上。机器人被命令自动找到,捡起这些物体,并把它们放到机器人基座顶部的盒子里。一开始,机器人检测其视野内的对象,如图11左图所示,并开始拿起对象在其操作范围。一轮操作后,现场显示,绿色块和蓝色抹布未回收,如图11b所示。这是因为绿色块叠放另一块没有被发现之前,和蓝色的抹布是达到机械手。因此,机器人再次检测当前场景中的对象,以确保在导航到下一个位置之前没有对象。在检测和拾取绿色块后,机器人移动到清洁抹布,然后捡起来。机器人重复检测物体的过程,接近物体,再次检测物体并拾取它们。图12显示了机器人自动执行这些过程时的一些典型场景快照。

图12。当我们的机器人执行清理地面任务时的场景快照。在检测到未知物体后,机器人将其手爪移动到最近的物体(A),抓住物体(B),然后把它放进盒子里。当物体到达机械手时,机器人移动其基座以便于抓取(c)。在回收当前点的所有物体后,机器人继续寻找物体并移动到下一个地点(d)。
5 结论
提出了一种利用显著性检测和三维多类标记技术的未知目标检测方法。该方法利用检测到的显著三维点生成物体假设,并在三维场景的体素上对MRF进行多类标记。此外,检测对象是对三维场景的一部分进行的,因为只使用一个RGB-D图像每一次检测,但我们相信,现场为中心的范式可以从多个视图可以用来重建一个完整的场景分割多个对象。我们已经验证了所提出的视觉显著性检测方法三眼动数据集和两个基准数据集对象检测结果显示深度。我们还应用所提出的方法,我们的移动机械手来执行任务,如清理地面。未知对象的检测是机器人领域一个非常有前途的研究领域,特别是由于在新环境中处理新对象的需求日益增长。未来的方向可以探索语义属性,如部分,形状和材料,以帮助描述对象假设从突出点播种。通过使用语义属性描述对象,可以很好地细化对象假设,并提供有关被检测对象的更多信息。此外,提供有关被检测物体的充分信息也有利于参考接地,在此基础上,人类可以通过自然语言与机器人交互以实现共同目标。
致谢
这项工作得到了江苏省自然科学基金的部分支持。
(第bk20130451),江苏省大学科学研究项目(编号13kjb520025)和远程测量与控制江苏省重点实验室开放基金(批准号:ycck201402和ycck201502)。
作者的贡献
贾通宝开发的算法,对算法和写文章。云一佳参加了算法的开发和写作。于成进行机器人实验。宁席监督工作和修改论文。
利益冲突
作者声明没有利益冲突。
References
1. Lai, K.; Bo, L.; Ren, X.; Fox, D. Detection-based object labeling in 3D scenes. In Proceedings
of the IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA,
14–18 May 2012.
2. Collet, A.; Martinez, M.; Srinivasa, S.S. The MOPED framework: Object recognition and pose
estimation for manipulation. Int. J. Robot. Res. 2011, 30, 1284–1306.
3. Johnson-Roberson, M.; Bohg, J.; Bjorkman, M.; Kragic, D. Attention-based active 3D point cloud
segmentation. In Proceedings of the IEEE International Conference on Intelligent Robots and
Systems, Taipei, Taiwan, 18–22 October 2010.
4. Bjorkman, M.; Kragic, D. Active 3D scene segmentation and detection of unknown objects.
In Proceedings of the IEEE International Conference on Robotics and Automation, Anchorage,
AK, USA, 3–7 May 2010.
5. Mishra, A.K.; Srivastav, A.; Aloimonos, Y. Segmenting “Simple” Objects Using RGB-D.
In Proceedings of the IEEE International Conference on Robotics and Automation, Saint Paul,
MN, USA, 14–18 May 2012.
6. Potapova, E.; Varadarajan, K.M.; Richtsfeld, A.; Zillich, M.; Vincze, M. Attention-driven object
detection and segmentation of cluttered table scenes using 2.5D symmetry. In Proceedings
of the IEEE International Conference on Robotics and Automation, Hong Kong, China,
31 May–7 June 2014.
| 7. Richtsfeld, A.; Morwald, T.; Prankl, J.; Zillich, M.; Vincze, M. Segmentation of unknown objects |
| in indoor environments. In Proceedings of the IEEE International Conference on Intelligent Robots |
| and Systems, Vilamoura, Portugal, 7–12 October 2012. |
| 8. Sanford, K. Smoothing Kinect Depth Frames in Real-Time. Available online: http://www.code |
| project.com/Articles/317974/KinectDepthSmoothing (accessed on 24 January 2012). |
| 9. Aloimonos, J.; Weiss, I.; Bandyopadhyay, A. Active Vision. IJCV 1988, 1, 333–356 |
10. Koch, C.; Ullman, S. Shifts in selective visual attention: towards the underlying neural circuitry.Hum. Neurbiol. 1985, 4, 219–227.
11. Itti, L. The iLab Neuromorphic Vision C++ Toolkit: Free tools for the next generation of vision
algorithms.
11. Itti, L. The iLab Neuromorphic Vision C++ Toolkit: Free tools for the next generation of vision
algorithms. Neuromorphic Eng. 2004, 1, 10.
12. Goferman, S.; Zelnik-Manor, L.; Tal, A. Context-aware saliency detection. IEEE PAMI 2012,
34, 1915–1926.
13. Cheng, M.; Mitra, N.J.; Huang, X.; Torr, P.H.S.; Hu, S. Global Contrast based Salient Region
Detection. IEEE TPAMI 2015, 37, 569–582.
14. Zhang, J.; Sclaroff, S. Saliency detection: A boolean map approach. In Proceedings of the IEEE
International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013.
15. Ju, R.; Ge, L.; Geng, W.; Ren, T.; Wu, G. Depth saliency based on anisotropic center-surround
difference. In Proceedings of the IEEE International Conference on Image Processing, Paris,
France, 27–30 October 2014.
16. Desingh, K.; Krishna, K.M.; Rajan, D.; Jawahar, C.V. Depth really matters: Improving visual
salient region detection with depth. In Proceedings of the British Machine Vision Conference,
Bristol, UK, 9–13 September 2013.
17. Bharath, R.; Nicholas, L.; Cheng, X. Scalable scene understanding using saliency-guided object
localization. In Proceedings of the IEEE International Conference on Control and Automation,
Hangzhou, China, 12–14 June 2013.
18. Gupta, S.; Arbelaez, P.; Malik, J. Perceptual organization and recognition of indoor scenes from
RGB-D images. In Proceedings of the IEEE International Conference on Computer Vision and
Pattern Recognition, Portland, OR, USA, 2013.
19. Boykov, Y.; Veksler, O.; Zabih, R. Fast approximate energy minimization via graph cuts.
IEEE TPAMI 2001, 23, 1222–1239.
20. Lai, K.; Bo, L.; Ren, X.; Fox, D. A large-scale hierarchical multi-view RGB-D object dataset.
In Proceedings of the International Conference on Robotics and Automation, Shanghai, China,
9–13 May 2011.
21. Judd, T.; Ehinger, K.; Durand, F.; Torralba, A. Learning to predict where humans look.
In Proceedings of the 12th International Conference on Computer Vision, Kyoto, Japan,
29 September–2 October 2009.
22. Bruce, N.; Tsotsos, J. Saliency, attention, and visual search: An information theoretic approach.
J. Vis. 2009, 9, 5, 1–24.
23. Kootstra, G.; Nederveen, A.; Boer, B. Paying attention to symmetry. In Proceedings of the British
Machine Vision Conference, Leeds, UK, 1–4 September 2008.
24. Borji, A.; Tavakoli, H.; Sihite, D.; Itti, L. Analysis of scores, datasets, and models in visual
saliency prediction. In Proceedings of the 12th International Conference on Computer Vision,
Sydney, Australia, 1–8 December 2013.
25. Bylinskii, Z.; Judd, T.; Durand, F.; Oliva, A.; Torralba, A. MIT Saliency Benchmark. Available
online: http://saliency.mit.edu/ (accessed on 26 August 2015).
26. Harel, J.; Koch, C.; Perona, P. Graph-based visual saliency. NIPS 2007, 19, 545–552.
27. Hou, X.; Harel, J.; Koch, C. Image signature: Highlighting sparse salient regions. PAMI 2012,
34, 194–201.
28. Zhang, L.; Tong, M.; Marks, T.; Shan, H.; Cottrell, G. SUN: A Bayesian framework for saliency
using natural statistics. J. Vis. 2008, 8, 1–20.
29. Martin, D.R.; Fowlkes, C.C.; Malik, J. Learning to Detect Natural Image Boundaries Using Local
Brightness, Color, and Texture Cues. TPAMI 2004, 26, 530–549.
30. Rodriguez, S.; Burrus, N.; Abderrahim, M. 3D object reconstruction with a single RGB-Depth
image. In Proceedings of the International Conference on Computer Vision Theory and
Applications, Barcelona, Spain, 21–24 February 2013.
31. She, L.; Cheng, Y.; Chai, J.Y.; Jia, Y.; Xi, N. Teaching robots new actions through natural language
instructions. In Proceedings of the IEEE International Symposium on Robot and Human Interactive
Communication, Edinburgh, UK, 25–29 August 2014.

















 442
442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









