







一、应用程序代码示例
改进算法
此示例演示如何简化算法以优化其性能。给定一个图像,对其应用一个简单的8x8框模糊过滤器。
优化前的原始内核:
__kernel void ImageBoxFilter(__read_only image2d_t source,
__write_only image2d_t dest,sampler_t sampler)
{
… // variable declaration
for( int i = 0; i < 8; i++ )
{
for( int j = 0; j < 8; j++ )
{
coor = inCoord + (int2) (i - 4, j - 4 );
// !! read_imagef is called 64 times per work item
sum += read_imagef( source, sampler, coor);
}
}
// Compute the average
float4 avgColor = sum / 64.0f;
… // write out result
}
为了减少纹理访问,上面的内核被分成两个过程。第一个过程计算每个工作项的2x2平均值,并将结果保存到中间图像。第二遍使用中间图像进行最终计算。
修改内核:
// First pass: 2x2 pixel average
__kernel void ImageBoxFilter(__read_only image2d_t source,
__write_only image2d_t dest, sampler_t sampler)
{
… // variable declaration
// Sample an 2x2 region and average the results
for( int i = 0; i < 2; i++ )
{
for( int j = 0; j < 2; j++ )
{
coor = inCoord - (int2)(i, j);
// 4 read_imagef per work item
sum += read_imagef( source, sampler, inCoord - (int2)(i, j) );
}
}
// equivalent of divided by 4, in case compiler does not optimize
float4 avgColor = sum * 0.25f;
… // write out result
}
// Second Pass: final average
__kernel void ImageBoxFilter16NSampling( __read_only image2d_t source,
__write_only image2d_t dest,sampler_t sampler)
{
… // variable declaration
int2 offset = outCoord - (int2)(3,3);
// Sampling 16 of the 2x2 neighbors
for( int i = 0; i < 4; i++ )
{
for( int j = 0; j < 4; j++ )
{
coord = mad24((int2)(i,j), (int2)2, offset);
// 16 read_imagef per work item
sum += read_imagef( source, sampler, coord );
}
}
// equivalent of divided by 16, in case compiler does not optimize
float4 avgColor = sum * 0.0625;
… // write out result
}
改进后的算法对每个工作项访问图像缓冲区20(4+16)次,明显小于原来的64个read_imagef访问。
二、矢量化加载/存储
此示例演示如何在adreno gpus中执行矢量化加载/存储,以更好地利用带宽。
优化前的原始内核:
__kernel void MatrixMatrixAddSimple( const int matrixRows,const int matrixCols,
__global float* matrixA,__global float* matrixB,
__global float* MatrixSum)
{
int i = get_global_id(0);
int j = get_global_id(1);
// Only retrieve 4 bytes from matrixA and matrixB.
// Then save 4 bytes to MatrixSum.
MatrixSum[imatrixCols+j] =
matrixA[imatrixCols+j] + matrixB[imatrixCols+j];
}
修改内核:
__kernel void MatrixMatrixAddOptimized2( const int rows,const int cols,
__global float matrixA,__global float* matrixB,
__global float* MatrixSum)
{
int i = get_global_id(0);
int j = get_global_id(1);
// Utilize built-in function to calculate index offset
int offset = mul24(j, cols);
int index = mad24(i, 4, offset);
// Vectorize to utilization of memory bandwidth for performance gain.
// Now it retieves 16 bytes from matrixA and matrixB.
// Then save 16 bytes to MatrixSum
float4 tmpA = (((__global float4)&matrixA[index])); // Alternatively
vload and vstore can be used in here
float4 tmpB = (((__global float4)&matrixB[index]));
(((__global float4)&MatrixSum[index])) = (tmpA+tmpB);
// Since ALU is scalar based, no impact on ALU operation.
}
新内核正在使用float4执行矢量化的加载/存储。由于这种矢量化,新内核中的全局工作大小应该是原始内核的四分之一。
三、 Epsilon滤波器
Epsilon滤波器在图像处理中广泛应用于蚊子噪声的抑制,蚊子噪声是图像边缘等高频区域的一种损伤。该滤波器本质上是一个具有空间变化支持的非线性点态低通滤波器,只对具有一定阈值的像素进行滤波。
在该实现中,Epsilon滤波器仅应用于YUV图像的强度(Y)分量,因为噪声主要在其中可见。此外,假设Y分量是连续存储的(NV12格式),它与UV分量分离。有两个基本步骤,如下图所示:
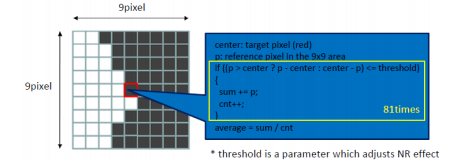 (Epsilon滤波算法)
(Epsilon滤波算法)
本篇文章主要介绍了基于Adreno的OpenCL优化案例研究,大家有兴趣的话可以相互探讨学习。















 1494
1494











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









