









骁龙神经处理引擎SDK参考指南(14)
6.2 SNPE1 到 SNPE2 迁移指南
有 2 个主要变化推动了 SNPE2 的主要版本更新:
- 语言接口
- SNPE2 引入了 C API。
- 此 API 将是未来与 SNPE 交互的唯一方式。
- C API 减少/消除了 C++ 可能存在的潜在兼容性问题(例如,由于 C++ 模板)。
- 为了简化过渡,C++ API 将继续得到支持,直到 2023 年初/中期,届时它将停用。
- 有关详细信息,请参考“代码示例”和 C API 部分的“C 教程”部分。
- DLC 内容变更
- 正在更新 DLC 文件的内容。
- 这些变化意味着 DLC 在 SNPE1 和 SNPE2 之间不兼容。
- 必须为 SNPE2 生成所有 DLC
- HTP 离线缓存记录在 SNPE2 中向后兼容 - 使用旧 SNPE2 版本生成的缓存将在更高版本的 SNPE2 中工作。
- SNPE2 中的离线缓存在 SoC 之间是兼容的:
- 对于同一个 DSP Arch,如果“用 VTCM 准备”小于或等于“目标 SoC VTCM”,则为一个 SoC 准备的缓存可以在另一个 SoC 上运行。例如,为具有2MB VTCM的sm7450准备的缓存与具有8MB VTCM的sm8450兼容,但是为具有4MB VTCM的sm8450准备的缓存将不兼容只有2MB VTCM的sm7450。
- 为较新的 DSP Arch 生成的缓存无法在具有较低 DSP Arch 的 SoC 上运行。为 sm8550 (v73) 生成的缓存将与 sm8450 (v69) 不兼容,而为 sm8450 (v69) 生成的缓存将与 sm8550 (v73) 兼容。
- DLC 现在可以表示 SNPE1 不支持的其他数据类型——基数数据类型(int8、int32、uint32)、fp16
- 这些是 SNPE1 中支持的 fp32 和量化 8 位类型的补充
- 任何用户缓冲区都需要与 DLC 中包含的数据类型相匹配。
- snpe-dlc-info 可用于识别正确的类型
- 此外,层的名称和输入/输出张量的名称可能与 SNPE1 中的名称不同。
- snpe-dlc-info 可用于识别和查看转换器生成的名称。
- 输入(通常称为“数据”层类型)和“常量”层类型现在被折叠到消耗操作中,而不被视为独立的“层”。因此,它们将不再出现在 snpe-diagview 和 snpe-dlc-info 工具生成的输出中。
- 如果客户端代码使用 SNPEBuilder.setOutputTensors() 之类的 API 来请求特定的输出张量,则可能需要修改此代码。
- 具体的重大层变化
- 从 Caffe 转换而来的模型中 SSD 检测器层的表示已更改。
- 在 SNPE1 中,该层发出单个输出张量,每次检测包含 7 个值:1 个批次索引、1 个类 ID、1 个置信度分数、4 个框坐标。
- 在 SNPE2 中,op 现在发出 4 个包含相同信息的独立输出。
- 从 Caffe 转换而来的模型中 SSD 检测器层的表示已更改。
- ArgMax 现在始终输出 uint32,因此如果基于 SNPE1 的模型使用 int8 输出,由于数据量较大,可能会对性能产生一些影响。
- 以前,如果最大值小于或等于 255,SNPE1 将使用 int8。
SDK 行为/内容更改:
-
未签名的 PD/Skels
- SNPE2 默认使用 Unsigned PD。
- SNPE2 提供未签名的 skel 文件。
- 为了使用已签名的 PD,skel 必须由客户签名,并且必须在运行时显式请求已签名的 PD。
-
运行时更改:
- 具有 V66 CDSP 的 SOC 的 DSP 运行时不支持运行浮动 DLC。DLC 必须量化才能与这些 SOC 的 DSP 运行时一起使用
- 对于GPU运行时,一些初始化时间记录不同,所以init时间会显得更长。这只是测量和捕获初始化方式的不同。
-
整数输入/输出张量
- SNPE1 不支持整数(基数)张量类型。索引或整数数据被处理为浮点张量或使用 Q8 输入使用特殊的硬连线量化编码 [offset=0, scale=1.0]。
- SNPE2 直接支持整数类型。转换器/量化器将整数输入表示为 UIntN 张量,其中 N 可以是 8、16 或 32。
- SNPE 无法将 Q8 输入张量转换为 UInt8 输入张量,因此必须修改此类网络的任何现有代码以使用新 API 来创建 UInt8 UserBuffer 输入。
- SNPE 可以将浮点输入张量转换为 UInt8 输入张量,但此代码路径比提供正确类型要慢。
-
工具/旗帜变化:
- snpe-dlc-quantize 功能已重构为两个独立的工具:
- 仍然提供一个 shell 脚本,它支持以前的命令行界面,并在适当时调用新工具。
- snpe-dlc-quant:用于从浮点 DLC 生成量化 DLC,具有各种量化选项。
- snpe-dlc-graph-prepare:用于在 HTP SOC 的量化 DLC 上执行离线图形准备。
- 这样可以灵活地根据需要从量化的 DLC 快速重新准备图形,而无需同时进行量化和离线准备,这通常需要更多时间。
- 标志变化:
- “bc”(偏差校正)算法已弃用,并且没有任何效果。
- “enable_hta”选项已弃用且无效。
- 不再支持 AIP 的离线准备,所有准备都在运行时完成。
- snpe 网络运行:
- 添加了一个新标志“–userbuffer_auto”,以根据模型的输入和输出张量数据类型自动检测和创建正确的用户缓冲区类型。
SDK 内容变更:
- 添加了一个新标志“–userbuffer_auto”,以根据模型的输入和输出张量数据类型自动检测和创建正确的用户缓冲区类型。
- snpe-dlc-quantize 功能已重构为两个独立的工具:
-
Caffe2 转换器支持在 SNPE2 中退役,转换器未交付。
-
snpe-dlc-reorder 工具已被删除,因为它不再相关(它仅用于 HTA 离线准备)
6.3 转换和执行具有动态权重的模型
介绍
本教程将展示采用公开可用的 SESR-XL 超分辨率模型并对其进行修改所需的步骤,以便在执行期间可以动态地将不同的权重集与模型一起使用。本教程将使用 Onnx 版本的 SESR-XL 作为示例。下面的代码片段将特定于此模型,需要进行修改以适应其他用例。
有关本教程中使用的 SNPE 转换器和 snpe-net-run 工具的更多信息,请参阅:工具和snpe-net-run。
本教程假设在安装时已遵循一般安装说明。
教程的各个部分如下:
- 设置
- 修改框架模型
- 转换模型
- 执行模型
6.3.1 设置
SESR 在https://github.com/ARM-software/sesr上公开提供 。对于本教程,tensorflow 模型将首先转换为 Onnx 模型。克隆 SESR 存储库并设置 python 环境:
apt-get install python3-venv
python3 -m venv pyenv
source pyenv/bin/activate
python -m pip install -U pip
pip install tensorflow
pip install tensorflow_datasets==4.1
pip install tf2onnx
pip install packaging
pip install pandas
source ${SNPE_SDK_ROOT}/x86_64-linux-clang/SecondParty/QNN/src/qnn-backends/SDK/Assets/check-python-dependency.sh
git clone https://github.com/ARM-software/sesr
cd sesr/
git apply ${SNPE_SDK_ROOT}/examples/Models/SESR/sesr.patch
export PYTHONPATH=$PWD:$PYTHONPATH
cd ..
注意:为了更好地演示,原始张量流模型被更改为使用 Relu 激活并包括卷积的偏差。
可以执行以下脚本来生成本教程中使用的 x2 超分辨率 SESR-XL 的配置并将其转换为 onnx 模型:
import tensorflow as tf
from models import sesr, model_utils
import utils
import tf2onnx
FLAGS = tf.compat.v1.flags.FLAGS
FLAGS.__delattr__('int_features')
tf.compat.v1.flags.DEFINE_string('model_name', 'SESR', 'Name of the model')
tf.compat.v1.flags.DEFINE_bool('quant_W', False, 'Quantize weights')
tf.compat.v1.flags.DEFINE_bool('quant_A', False, 'Quantize activations')
tf.compat.v1.flags.DEFINE_bool('gen_tflite', True, 'Generate TFLITE')
tf.compat.v1.flags.DEFINE_integer('tflite_height', 256, 'Height of LR image in TFLITE')
tf.compat.v1.flags.DEFINE_integer('tflite_width', 256, 'Width of LR image in TFLITE')
tf.compat.v1.flags.DEFINE_integer('int_features', 32, 'Number of intermediate features within SESR (parameter f in paper)')
model = sesr.SESR(
m=11,
feature_size=64,
LinearBlock_fn=model_utils.LinearBlock_c,
quant_W=FLAGS.quant_W,
quant_A=FLAGS.quant_A,
gen_tflite=FLAGS.gen_tflite,
mode='infer')
model.compile()
input_image = tf.random.uniform([1, FLAGS.tflite_height, FLAGS.tflite_width, 1])
temp = model(input_image)
tf2onnx.convert.from_keras(model, output_path="original_model.onnx")
6.3.2 修改框架模型
原始模型具有 1x256x256x1 的单个输入和 1x512x512x1 的单个输出。框架模型将通过从图表中删除静态权重和偏差并用图表的额外输入替换它们来修改。SESR-XL 有 26 组权重和偏差。修改后的图形总共有 27 个输入。
用于修改 Onnx 框架模型的 Python 脚本,如下所述:
import onnx
from onnx import helper, numpy_helper
from onnx import AttributeProto, TensorProto, GraphProto
onnx_model = onnx.load('original_model.onnx')
nodes = onnx_model.graph.node
inputs = onnx_model.graph.input
weights = onnx_model.graph.initializer
for i,node in enumerate(nodes):
if node.op_type == "Conv":
weight_name = node.input[1]
bias_name = node.input[2]
new_weight_name = weight_name + "_as_input"
new_bias_name = bias_name + "_as_input"
[weights_tensor] = [w for w in weights if w.name == weight_name]
[biases_tensor] = [b for b in weights if b.name == bias_name]
weights_tensor = numpy_helper.to_array(weights_tensor)
biases_tensor = numpy_helper.to_array(biases_tensor)
# create new tensors to be used as graph inputs
weights_as_input = helper.make_tensor_value_info(new_weight_name, TensorProto.FLOAT, weights_tensor.shape)
biases_as_input = helper.make_tensor_value_info(new_bias_name, TensorProto.FLOAT, biases_tensor.shape)
inputs.append(weights_as_input)
inputs.append(biases_as_input)
# create new copy of conv node that uses graph inputs for weights/biases instead
new_conv_node = onnx.helper.make_node(
'Conv',
name=node.name + "_dynamic",
inputs=[node.input[0], new_weight_name, new_bias_name],
outputs=node.output
)
# copy over attribute data to new conv node
for attribute in node.attribute:
if (attribute.type == AttributeProto.INTS):
new_conv_node.attribute.append(helper.make_attribute(attribute.name, attribute.ints))
if (attribute.type == AttributeProto.INT):
new_conv_node.attribute.append(helper.make_attribute(attribute.name, attribute.i))
# replace old conv node in the node list
nodes.remove(node)
nodes.insert(i, new_conv_node)
try:
onnx.checker.check_model(onnx_model)
except onnx.checker.ValidationError as e:
print('The modified model is not valid: %s' % e)
else:
print('The modified model is valid')
onnx.save(onnx_model, 'modified_model.onnx')
原始图拓扑

修改图拓扑
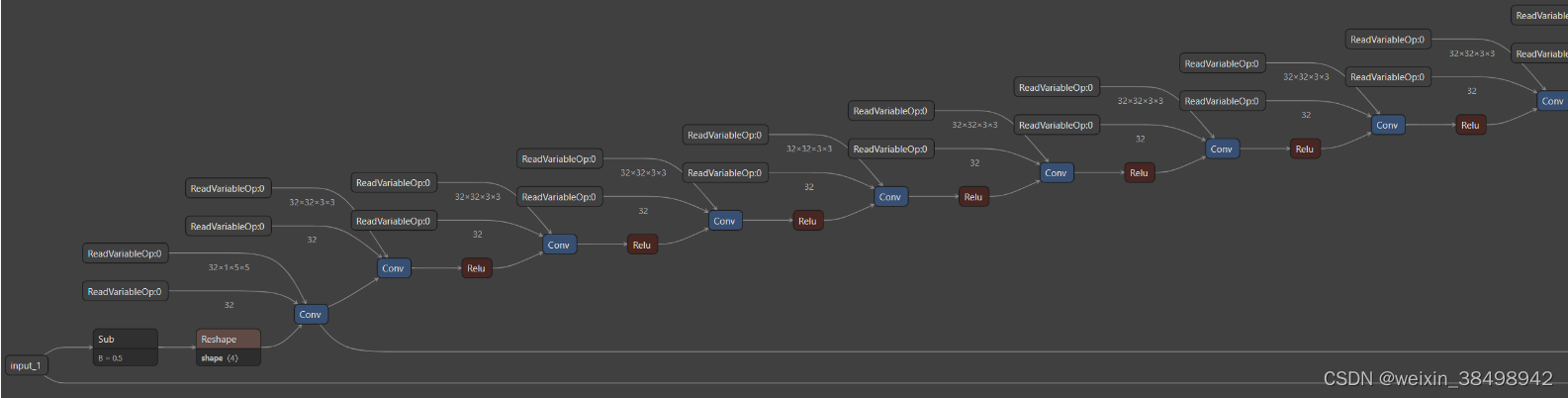
需要从模型中提取权重,以便稍后用作图形的输入:
import onnx
from onnx import helper, numpy_helper
onnx_model = onnx.load('original_model.onnx')
nodes = onnx_model.graph.node
inputs = onnx_model.graph.input
weights = onnx_model.graph.initializer
for i,node in enumerate(nodes):
if node.op_type == "Conv":
weight_name = node.input[1]
bias_name = node.input[2]
new_weight_name = (weight_name + "_as_input").replace("/", "_").replace(":", "_")
new_bias_name = (bias_name + "_as_input").replace("/", "_").replace(":", "_")
[weights_tensor] = [w for w in weights if w.name == weight_name]
[biases_tensor] = [b for b in weights if b.name == bias_name]
weights_tensor = numpy_helper.to_array(weights_tensor)
biases_tensor = numpy_helper.to_array(biases_tensor)
weights_tensor.tofile(new_weight_name + ".raw")
biases_tensor.tofile(new_bias_name + ".raw")














 154
154











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









