






2.2 统一仿射量化
在本节中,我们定义了本文中将使用的量化方案。这个方案被称为统一量化,它是最常用的量化方案,因为它允许有效地实现定点算术。
均匀仿射量化,也称为非对称量化,由三个量化参数定义:比例因子s、零点z和位宽b。比例因子和零点用于将浮点值映射到整数网格,其大小取决于位宽。比例因子通常表示为浮点数,并指定量化器的步长。零点是一个整数,确保实际零被量化而没有误差。这对于确保常见操作(如零填充或ReLU)不引入量化误差非常重要。
一旦定义了这三个量化参数,我们就可以进行量化操作。从实值向量x开始,我们首先将其映射到无符号整数网格{0, . . . ,
2
b
−
1
{2}^{b − 1}
2b−1 }:

其中⌊⌉是最近舍入运算符,clamp定义为:

为了近似实值输入x,我们执行一个反量化步骤:

结合上述两个步骤,我们可以提供量化函数q(·)的一般定义:

通过反量化步骤,我们还可以定义量化网格的限制范围(qmin, qmax),其中qmin = −sz,qmax = s( 2 b {2}^{b } 2b − 1 − z)。任何超出此范围的x值都将被剪裁到其限制范围内,从而产生剪裁误差。如果我们想要减少剪裁误差,可以通过增加比例因子来扩大量化范围。然而,增加比例因子会导致舍入误差增加,因为舍入误差的范围在[- 1 2 \frac{1}{2} 21s, 1 2 \frac{1}{2} 21s]。在第3.1节中,我们将更详细地探讨如何选择量化参数以在剪裁误差和舍入误差之间取得适当的平衡。
2.2.1 对称均匀量化
对称量化是一种简化版本的非对称量化。对称量化器将零点限制为0。这减少了在方程(3)的累加操作中处理零点偏移的计算开销。但是,缺少偏移限制了整数和浮点域之间的映射。因此,选择有符号或无符号的整数网格是重要的。

无符号对称量化非常适用于单尾分布,例如ReLU激活函数(参见图3)。另一方面,对于大致关于零对称的分布,可以选择有符号对称量化。

2.2.2 二的幂量化器
二的幂量化是对称量化的特殊情况,其中缩放因子被限制为二的幂次,s = 2^(-k)。这种选择可以带来硬件效率,因为与s的缩放对应于简单的位移操作。然而,缩放因子的受限表达能力可能会使舍入和截断误差的权衡变得复杂。
2.2.3 量化粒度
到目前为止,我们为每个张量定义了一个单独的量化参数(量化器),一个用于权重,一个用于激活函数,如公式(3)所示。这被称为每张量量化。我们还可以为张量的各个片段定义单独的量化器(例如,权重张量的输出通道),从而增加量化粒度。在神经网络量化中,每张量量化是由于其更简单的硬件实现而最常见的粒度选择:公式(3)中的所有累加器使用相同的缩放因子swsx。然而,我们可以使用更细的粒度来进一步提高性能。例如,对于权重张量,我们可以为每个输出通道指定不同的量化器。这被称为每通道量化,其影响将在2.4.2节中详细讨论。
其他研究超越了每通道量化参数,并对权重或激活函数的组应用单独的量化器。增加组的粒度通常会提高准确性,但会增加一些额外开销。这些开销与处理具有不同缩放因子的值之和的累加器相关。目前,大多数现有的定点加速器不支持此类逻辑,因此我们在本文中不考虑它们。然而,随着这一领域的研究不断发展,未来可以预期会有更多的硬件支持这些方法。
2.3 量化模拟

为了测试神经网络在量化设备上的运行情况,我们通常会在用于训练神经网络的通用硬件上模拟量化行为。这被称为量化模拟。我们旨在使用浮点硬件来近似固定点运算。与在实际量化硬件上运行实验或使用量化内核相比,这样的模拟要容易得多。它们允许用户有效地测试各种量化选项,并且可以实现量化感知训练的GPU加速,如第4节所述。在本节中,我们首先解释这个模拟过程的基本原理,然后讨论帮助减少模拟和实际设备性能差异的技术。
之前,我们看到了如何在专用的固定点硬件中计算矩阵-向量乘法。在图4a中,我们将这个过程推广到卷积层,但我们还包括了一个激活函数,使其更加逼真。在设备上的推理过程中,硬件的所有输入(偏置、权重和输入激活)都以固定点格式表示。然而,当我们使用常见的深度学习框架和通用硬件进行量化模拟时,这些量是浮点数。这就是为什么我们在计算图中引入量化器块来引入量化效果的原因。
图4b展示了相同的卷积层在深度学习框架中的建模方式。在权重和卷积之间添加了量化器块,以模拟权重量化,在激活函数之后添加量化器块,以模拟激活量化。偏置通常不进行量化,因为它以更高的精度存储。在第2.3.2节中,我们将详细讨论在非线性之后放置量化器的适当时机。量化器块实现了方程(7)的量化函数,每个量化器由一组量化参数(比例因子、零点、位宽)定义。量化器的输入和输出都是浮点格式,但输出位于量化网格上。
2.3.1 批归一化折叠
批归一化是现代卷积网络的标准组件。批归一化在缩放和添加偏移之前对线性层的输出进行归一化(参见方程9)。对于设备上的推理,这些操作被折叠到前一个或后一个线性层中,这一步骤称为批归一化折叠。这将批归一化操作完全从网络中移除,因为计算被吸收到相邻的线性层中。除了减少额外缩放和偏移的计算开销外,这还防止了额外的数据移动和层输出的量化。更正式地说,在推理过程中,批归一化被定义为输出x的仿射映射:

在训练过程中,µ和σ是通过对批次统计进行指数移动平均计算得到的均值和方差,而γ和β是每个通道学习的仿射超参数。如果在线性层之后立即应用批归一化,我们可以重写这些术语,使批归一化操作与线性层本身融合。假设权重矩阵W ∈ R^n×m,我们对每个输出yk(其中k = {1, . . . , n})应用批归一化。
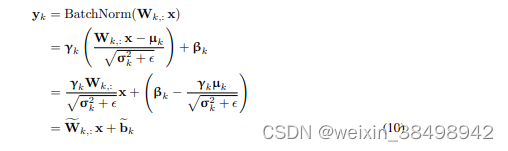

2.3.2 融合激活函数
在我们在第2.1节介绍的朴素量化加速器中,我们看到激活的重新量化发生在矩阵乘法或卷积输出值计算之后。然而,在实践中,我们经常在线性操作之后直接使用非线性函数。将线性层的激活写入内存,然后再加载到计算核心中应用非线性函数是一种浪费。因此,许多硬件解决方案都配备了一个硬件单元,在重新量化步骤之前应用非线性函数。如果是这种情况,我们只需要模拟在非线性函数之后发生的重新量化。例如,ReLU非线性函数可以很容易地通过重新量化块来建模,只需将该激活量化的最小可表示值设置为0。
其他更复杂的激活函数,如sigmoid或Swish,需要更专门的支持。如果没有这种支持,我们需要在图中的非线性函数之前和之后添加量化步骤。这可能对量化模型的准确性产生重大影响。尽管像Swish函数这样的新型激活函数在浮点数中提供了准确性改进,但在量化后可能会消失,或者在固定点硬件上部署可能不太高效。
2.3.3 其他层和量化
神经网络中使用了许多其他类型的层。如何对这些层进行建模很大程度上取决于具体的硬件实现。有时,模拟量化与目标性能之间的不匹配是因为层没有正确量化。在这里,我们提供一些关于如何模拟量化几种常用层的指导:
最大池化 不需要激活量化,因为输入和输出值在同一量化网格上。
平均池化 整数的平均值不一定是整数。因此,平均池化后需要进行量化步骤。然而,由于量化范围没有显著变化,我们使用相同的量化器用于输入和输出。
逐元素相加 尽管这个操作很简单,但很难准确模拟。在相加过程中,两个输入的量化范围必须完全匹配。如果这些范围不匹配,则需要特别小心以使相加正常工作。对于这个问题,没有一个单一的解决方案,但可以通过添加重新量化步骤来粗略地模拟添加的噪声。另一种方法是通过将输入的量化网格绑定来优化网络。这将避免重新量化步骤,但可能需要微调。
连接 通常,被连接的两个分支不共享相同的量化参数。这意味着它们的量化网格可能不重叠,需要进行重新量化步骤。与逐元素相加类似,可以优化网络,使被连接的分支共享量化参数。















 2595
2595











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









