







概览
导言
Qwen2.5-Omni 是一个端到端多模态模型,旨在感知文本、图像、音频和视频等多种模态,同时以流式方式生成文本和自然语音响应。
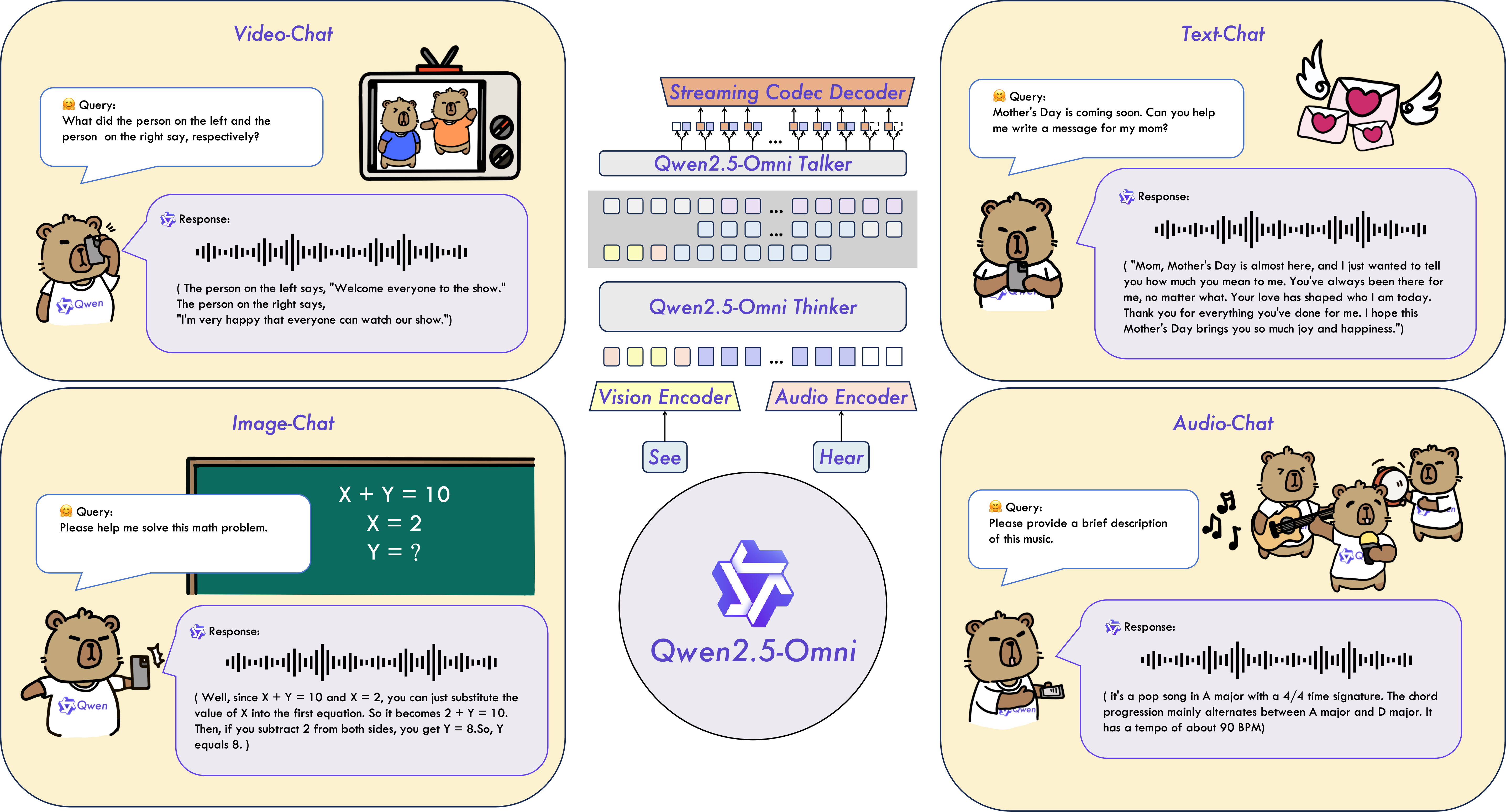
主要功能
-
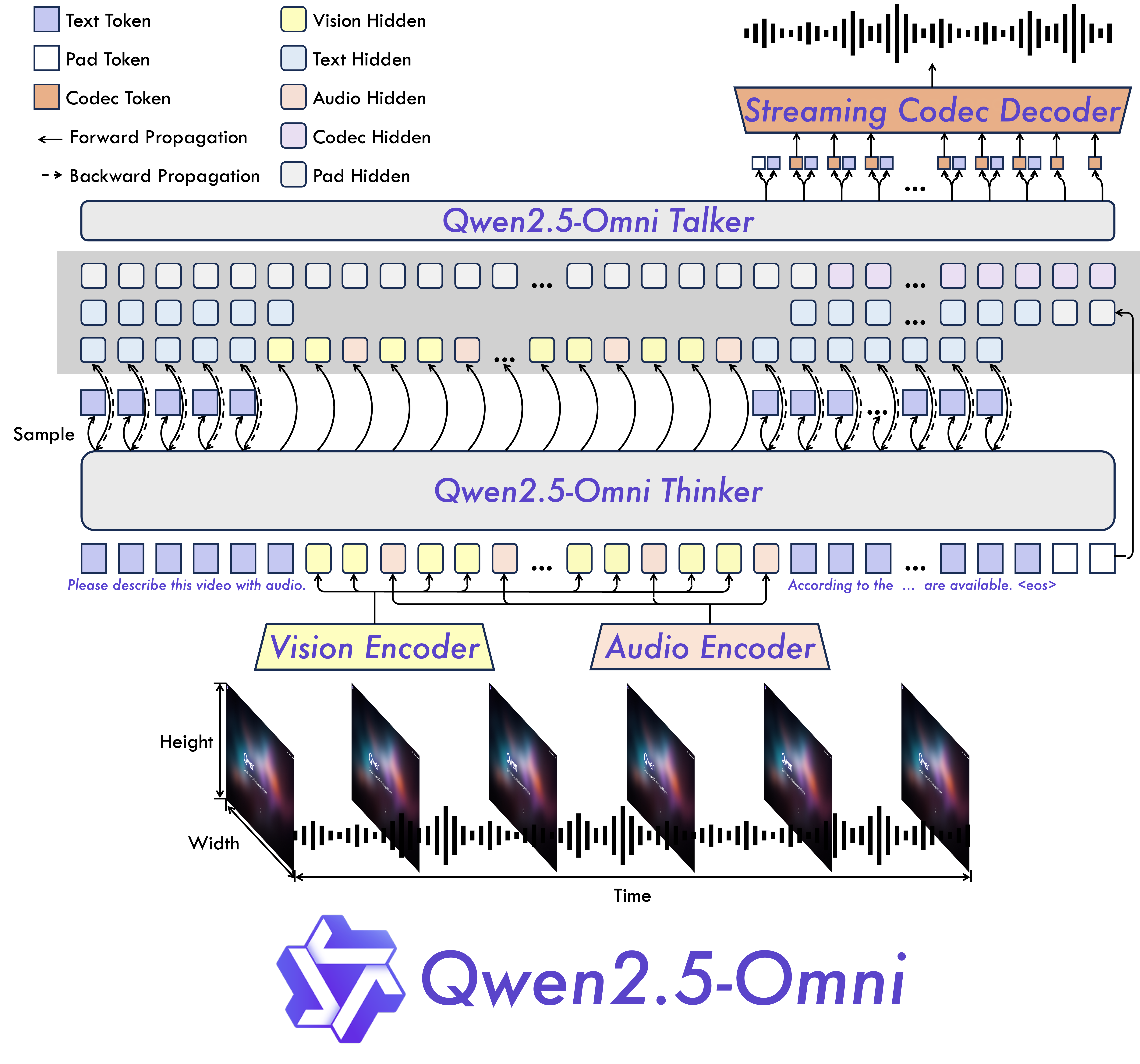
Omni 和新颖的架构:我们提出了 Thinker-Talker 架构,这是一种端到端多模态模型,旨在感知包括文本、图像、音频和视频在内的各种模态,同时以流式方式生成文本和自然语音响应。我们提出了一种名为 TMRoPE(Time-aligned Multimodal RoPE)的新颖位置嵌入方法,以同步视频输入和音频的时间戳。
-
实时语音和视频聊天:架构专为完全实时的交互而设计,支持分块输入和即时输出。
-
自然、稳健的语音生成:超越许多现有的流式和非流式替代方案,在语音生成方面表现出卓越的稳健性和自然性。
-
跨模态的卓越性能:与类似尺寸的单模态型号相比,Qwen2.5-Omni 在所有模态下均表现出卓越性能。Qwen2.5-Omni在音频功能方面超越了同尺寸的Qwen2-Audio,并实现了与Qwen2.5-VL-7B相当的性能。
-
优秀的端到端语音指令跟踪:通过 MMLU 和 GSM8K 等基准测试,Qwen2.5-Omni 在端到端语音指令跟踪方面的性能可与其在文本输入方面的性能相媲美。
模型架构
性能
我们对 Qwen2.5-Omni 进行了全面评估,与类似规模的单模态模型和封闭源模型(如 Qwen2.5-VL-7B、Qwen2-Audio 和 Gemini-1.5-pro)相比,Qwen2.5-Omni 在所有模态中都表现出强劲的性能。在需要整合多种模式的任务中,如 OmniBench,Qwen2.5-Omni 实现了最先进的性能。此外,在单模态任务中,它在语音识别(Common Voice)、翻译(CoVoST2)、音频理解(MMAU)、图像推理(MMMU、MMStar)、视频理解(MVBench)和语音生成(Seed-tts-eval 和主观自然度)等领域表现出色。
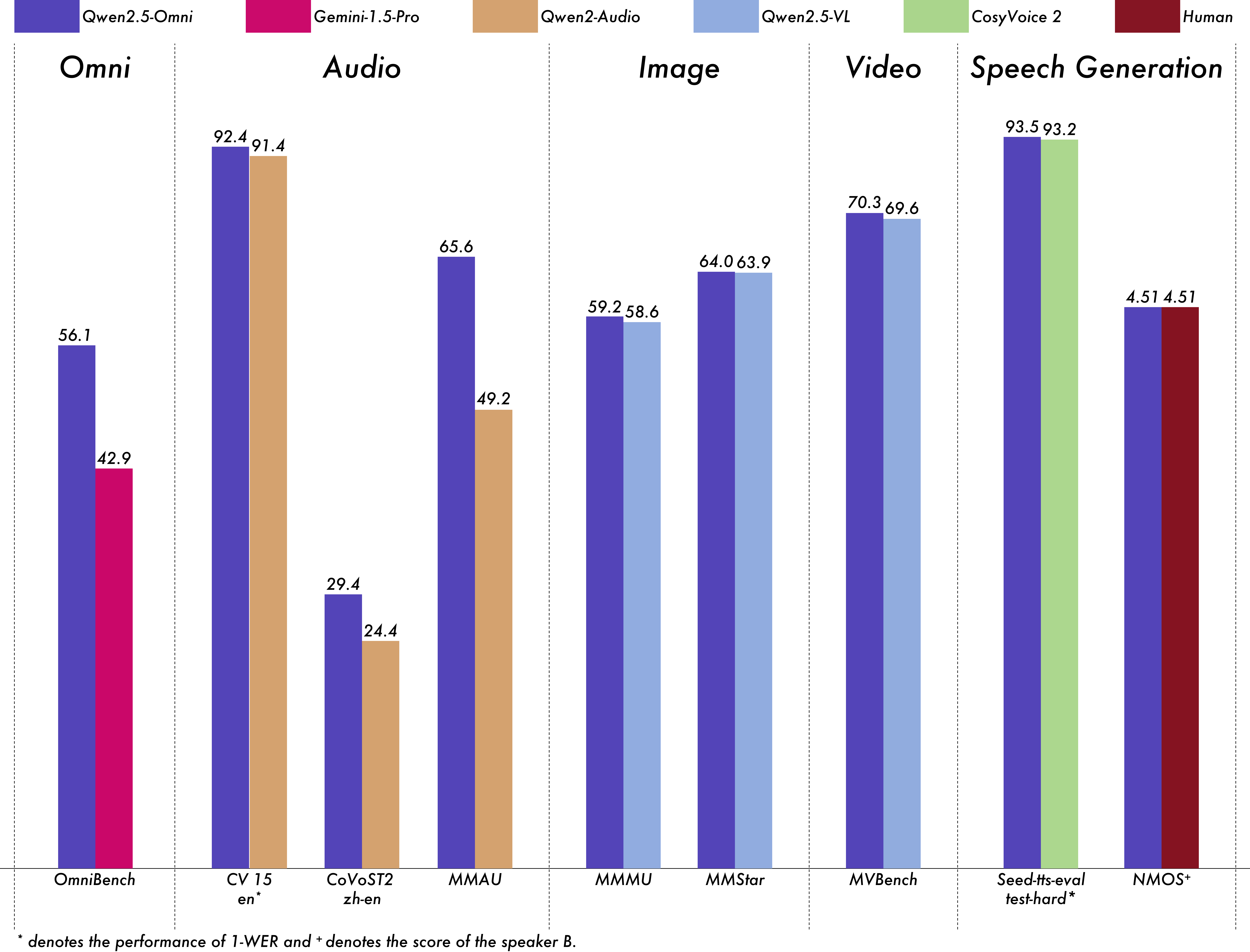
| 数据集 | 模型 | 性能 |
|---|---|---|
| OmniBench Speech | Sound Event | Music | Avg | Gemini-1.5-Pro | 42.67%|42.26%|46.23%|42.91% |
| MIO-Instruct | 36.96%|33.58%|11.32%|33.80% | |
| AnyGPT (7B) | 17.77%|20.75%|13.21%|18.04% | |
| video-SALMONN | 34.11%|31.70%|56.60%|35.64% | |
| UnifiedIO2-xlarge | 39.56%|36.98%|29.25%|38.00% | |
| UnifiedIO2-xxlarge | 34.24%|36.98%|24.53%|33.98% | |
| MiniCPM-o | -|-|-|40.50% | |
| Baichuan-Omni-1.5 | -|-|-|42.90% | |
| Qwen2.5-Omni-7B | 55.25%|60.00%|52.83%|56.13% |
| 数据集 | 模型 | 性能 |
|---|---|---|
| ASR | ||
| Librispeech dev-clean | dev other | test-clean | test-other | SALMONN | -|-|2.1|4.9 |
| SpeechVerse | -|-|2.1|4.4 | |
| Whisper-large-v3 | -|-|1.8|3.6 | |
| Llama-3-8B | -|-|-|3.4 | |
| Llama-3-70B | -|-|-|3.1 | |
| Seed-ASR-Multilingual | -|-|1.6|2.8 | |
| MiniCPM-o | -|-|1.7|- | |
| MinMo | -|-|1.7|3.9 | |
| Qwen-Audio | 1.8|4.0|2.0|4.2 | |
| Qwen2-Audio | 1.3|3.4|1.6|3.6 | |
| Qwen2.5-Omni-7B | 1.6|3.5|1.8|3.4 | |
| Common Voice 15 en | zh | yue | fr | Whisper-large-v3 | 9.3|12.8|10.9|10.8 |
| MinMo | 7.9|6.3|6.4|8.5 | |
| Qwen2-Audio | 8.6|6.9|5.9|9.6 | |
| Qwen2.5-Omni-7B | 7.6|5.2|7.3|7.5 | |
| Fleurs zh | en | Whisper-large-v3 | 7.7|4.1 |
| Seed-ASR-Multilingual | -|3.4 | |
| Megrez-3B-Omni | 10.8|- | |
| MiniCPM-o | 4.4|- | |
| MinMo | 3.0|3.8 | |
| Qwen2-Audio | 7.5|- | |
| Qwen2.5-Omni-7B | 3.0|4.1 | |
| Wenetspeech test-net | test-meeting | Seed-ASR-Chinese | 4.7|5.7 |
| Megrez-3B-Omni | -|16.4 | |
| MiniCPM-o | 6.9|- | |
| MinMo | 6.8|7.4 | |
| Qwen2.5-Omni-7B | 5.9|7.7 | |
| Voxpopuli-V1.0-en | Llama-3-8B | 6.2 |
| Llama-3-70B | 5.7 | |
| Qwen2.5-Omni-7B | 5.8 | |
| S2TT | ||
| CoVoST2 en-de | de-en | en-zh | zh-en | SALMONN | 18.6|-|33.1|- |
| SpeechLLaMA | -|27.1|-|12.3 | |
| BLSP | 14.1|-|-|- | |
| MiniCPM-o | -|-|48.2|27.2 | |
| MinMo | -|39.9|46.7|26.0 | |
| Qwen-Audio | 25.1|33.9|41.5|15.7 | |
| Qwen2-Audio | 29.9|35.2|45.2|24.4 | |
| Qwen2.5-Omni-7B | 30.2|37.7|41.4|29.4 | |
| SER | ||
| Meld | WavLM-large | 0.542 |
| MiniCPM-o | 0.524 | |
| Qwen-Audio | 0.557 | |
| Qwen2-Audio | 0.553 | |
| Qwen2.5-Omni-7B | 0.570 | |
| VSC | ||
| VocalSound | CLAP | 0.495 |
| Pengi | 0.604 | |
| Qwen-Audio | 0.929 | |
| Qwen2-Audio | 0.939 | |
| Qwen2.5-Omni-7B | 0.939 | |
| Music | ||
| GiantSteps Tempo | Llark-7B | 0.86 |
| Qwen2.5-Omni-7B | 0.88 | |
| MusicCaps | LP-MusicCaps | 0.291|0.149|0.089|0.061|0.129|0.130 |
| Qwen2.5-Omni-7B | 0.328|0.162|0.090|0.055|0.127|0.225 | |
| Audio Reasoning | ||
| MMAU Sound | Music | Speech | Avg | Gemini-Pro-V1.5 | 56.75|49.40|58.55|54.90 |
| Qwen2-Audio | 54.95|50.98|42.04|49.20 | |
| Qwen2.5-Omni-7B | 67.87|69.16|59.76|65.60 | |
| Voice Chatting | ||
| VoiceBench AlpacaEval | CommonEval | SD-QA | MMSU | Ultravox-v0.4.1-LLaMA-3.1-8B | 4.55|3.90|53.35|47.17 |
| MERaLiON | 4.50|3.77|55.06|34.95 | |
| Megrez-3B-Omni | 3.50|2.95|25.95|27.03 | |
| Lyra-Base | 3.85|3.50|38.25|49.74 | |
| MiniCPM-o | 4.42|4.15|50.72|54.78 | |
| Baichuan-Omni-1.5 | 4.50|4.05|43.40|57.25 | |
| Qwen2-Audio | 3.74|3.43|35.71|35.72 | |
| Qwen2.5-Omni-7B | 4.49|3.93|55.71|61.32 | |
| VoiceBench OpenBookQA | IFEval | AdvBench | Avg | Ultravox-v0.4.1-LLaMA-3.1-8B | 65.27|66.88|98.46|71.45 |
| MERaLiON | 27.23|62.93|94.81|62.91 | |
| Megrez-3B-Omni | 28.35|25.71|87.69|46.25 | |
| Lyra-Base | 72.75|36.28|59.62|57.66 | |
| MiniCPM-o | 78.02|49.25|97.69|71.69 | |
| Baichuan-Omni-1.5 | 74.51|54.54|97.31|71.14 | |
| Qwen2-Audio | 49.45|26.33|96.73|55.35 | |
| Qwen2.5-Omni-7B | 81.10|52.87|99.42|74.12 | |
| 数据集 | Qwen2.5-Omni-7B | Other Best | Qwen2.5-VL-7B | GPT-4o-mini |
|---|---|---|---|---|
| MMMUval | 59.2 | 53.9 | 58.6 | 60.0 |
| MMMU-Prooverall | 36.6 | - | 38.3 | 37.6 |
| MathVistatestmini | 67.9 | 71.9 | 68.2 | 52.5 |
| MathVisionfull | 25.0 | 23.1 | 25.1 | - |
| MMBench-V1.1-ENtest | 81.8 | 80.5 | 82.6 | 76.0 |
| MMVetturbo | 66.8 | 67.5 | 67.1 | 66.9 |
| MMStar | 64.0 | 64.0 | 63.9 | 54.8 |
| MMEsum | 2340 | 2372 | 2347 | 2003 |
| MuirBench | 59.2 | - | 59.2 | - |
| CRPErelation | 76.5 | - | 76.4 | - |
| RealWorldQAavg | 70.3 | 71.9 | 68.5 | - |
| MME-RealWorlden | 61.6 | - | 57.4 | - |
| MM-MT-Bench | 6.0 | - | 6.3 | - |
| AI2D | 83.2 | 85.8 | 83.9 | - |
| TextVQAval | 84.4 | 83.2 | 84.9 | - |
| DocVQAtest | 95.2 | 93.5 | 95.7 | - |
| ChartQAtest Avg | 85.3 | 84.9 | 87.3 | - |
| OCRBench_V2en | 57.8 | - | 56.3 | - |
| 数据集 | Qwen2.5-Omni-7B | Qwen2.5-VL-7B | Grounding DINO | Gemini 1.5 Pro |
|---|---|---|---|---|
| Refcocoval | 90.5 | 90.0 | 90.6 | 73.2 |
| RefcocotextA | 93.5 | 92.5 | 93.2 | 72.9 |
| RefcocotextB | 86.6 | 85.4 | 88.2 | 74.6 |
| Refcoco+val | 85.4 | 84.2 | 88.2 | 62.5 |
| Refcoco+textA | 91.0 | 89.1 | 89.0 | 63.9 |
| Refcoco+textB | 79.3 | 76.9 | 75.9 | 65.0 |
| Refcocog+val | 87.4 | 87.2 | 86.1 | 75.2 |
| Refcocog+test | 87.9 | 87.2 | 87.0 | 76.2 |
| ODinW | 42.4 | 37.3 | 55.0 | 36.7 |
| PointGrounding | 66.5 | 67.3 | - | - |
| 数据集 | Qwen2.5-Omni-7B | Other Best | Qwen2.5-VL-7B | GPT-4o-mini |
|---|---|---|---|---|
| Video-MMEw/o sub | 64.3 | 63.9 | 65.1 | 64.8 |
| Video-MMEw sub | 72.4 | 67.9 | 71.6 | - |
| MVBench | 70.3 | 67.2 | 69.6 | - |
| EgoSchematest | 68.6 | 63.2 | 65.0 | - |
| 数据集 | 模型 | 性能 |
|---|---|---|
| Content Consistency | ||
| SEED test-zh | test-en | test-hard | Seed-TTS_ICL | 1.11 | 2.24 | 7.58 |
| Seed-TTS_RL | 1.00 | 1.94 | 6.42 | |
| MaskGCT | 2.27 | 2.62 | 10.27 | |
| E2_TTS | 1.97 | 2.19 | - | |
| F5-TTS | 1.56 | 1.83 | 8.67 | |
| CosyVoice 2 | 1.45 | 2.57 | 6.83 | |
| CosyVoice 2-S | 1.45 | 2.38 | 8.08 | |
| Qwen2.5-Omni-7B_ICL | 1.70 | 2.72 | 7.97 | |
| Qwen2.5-Omni-7B_RL | 1.42 | 2.32 | 6.54 | |
| Speaker Similarity | ||
| SEED test-zh | test-en | test-hard | Seed-TTS_ICL | 0.796 | 0.762 | 0.776 |
| Seed-TTS_RL | 0.801 | 0.766 | 0.782 | |
| MaskGCT | 0.774 | 0.714 | 0.748 | |
| E2_TTS | 0.730 | 0.710 | - | |
| F5-TTS | 0.741 | 0.647 | 0.713 | |
| CosyVoice 2 | 0.748 | 0.652 | 0.724 | |
| CosyVoice 2-S | 0.753 | 0.654 | 0.732 | |
| Qwen2.5-Omni-7B_ICL | 0.752 | 0.632 | 0.747 | |
| Qwen2.5-Omni-7B_RL | 0.754 | 0.641 | 0.752 | |
| 数据集 | Qwen2.5-Omni-7B | Qwen2.5-7B | Qwen2-7B | Llama3.1-8B | Gemma2-9B |
|---|---|---|---|---|---|
| MMLU-Pro | 47.0 | 56.3 | 44.1 | 48.3 | 52.1 |
| MMLU-redux | 71.0 | 75.4 | 67.3 | 67.2 | 72.8 |
| LiveBench0831 | 29.6 | 35.9 | 29.2 | 26.7 | 30.6 |
| GPQA | 30.8 | 36.4 | 34.3 | 32.8 | 32.8 |
| MATH | 71.5 | 75.5 | 52.9 | 51.9 | 44.3 |
| GSM8K | 88.7 | 91.6 | 85.7 | 84.5 | 76.7 |
| HumanEval | 78.7 | 84.8 | 79.9 | 72.6 | 68.9 |
| MBPP | 73.2 | 79.2 | 67.2 | 69.6 | 74.9 |
| MultiPL-E | 65.8 | 70.4 | 59.1 | 50.7 | 53.4 |
| LiveCodeBench2305-2409 | 24.6 | 28.7 | 23.9 | 8.3 | 18.9 |
Quickstart
下面,我们将提供一些简单的示例,说明如何将 Qwen2.5-Omni 与🤗Transformers一起使用。Qwen2.5-Omni 在 Hugging Face Transformers 上的代码处于拉取请求阶段,尚未合并到主分支。因此,您可能需要从源代码构建才能使用该命令:
pip uninstall transformers
pip install git+https://github.com/huggingface/transformers@3a1ead0aabed473eafe527915eea8c197d424356
pip install accelerate
否则可能会遇到以下错误:
KeyError: 'qwen2_5_omni'
我们提供了一个工具包,帮助您更方便地处理各种类型的音频和视频输入,就像使用 API 一样。其中包括 base64、URL 以及交错音频、图像和视频。您可以使用以下命令安装它,并确保您的系统已安装ffmpeg:。
# It's highly recommended to use `[decord]` feature for faster video loading.
pip install qwen-omni-utils[decord]
如果您使用的不是 Linux,您可能无法从 PyPI 安装 decord。在这种情况下,您可以使用 pip install qwen-omniutils,这会退回到使用 torchvision 进行视频处理。不过,您仍然可以 install decord from source 在加载视频时使用 decord。
🤗 Transformers 使用
这里我们展示了一个代码片段,告诉您如何使用聊天模型和 transformers 和 qwen_omni_utils:
import soundfile as sf
from transformers import Qwen2_5OmniModel, Qwen2_5OmniProcessor
from qwen_omni_utils import process_mm_info
# default: Load the model on the available device(s)
model = Qwen2_5OmniModel.from_pretrained("Qwen/Qwen2.5-Omni-7B", torch_dtype="auto", device_map="auto")
# We recommend enabling flash_attention_2 for better acceleration and memory saving.
# model = Qwen2_5OmniModel.from_pretrained(
# "Qwen/Qwen2.5-Omni-7B",
# torch_dtype="auto",
# device_map="auto",
# attn_implementation="flash_attention_2",
# )
processor = Qwen2_5OmniProcessor.from_pretrained("Qwen/Qwen2.5-Omni-7B")
conversation = [
{
"role": "system",
"content": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech.",
},
{
"role": "user",
"content": [
{"type": "video", "video": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/draw.mp4"},
],
},
]
# Preparation for inference
text = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False)
audios, images, videos = process_mm_info(conversation, use_audio_in_video=True)
inputs = processor(text=text, audios=audios, images=images, videos=videos, return_tensors="pt", padding=True)
inputs = inputs.to(model.device).to(model.dtype)
# Inference: Generation of the output text and audio
text_ids, audio = model.generate(**inputs, use_audio_in_video=True)
text = processor.batch_decode(text_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(text)
sf.write(
"output.wav",
audio.reshape(-1).detach().cpu().numpy(),
samplerate=24000,
)
| Precision | 15(s) Video | 30(s) Video | 60(s) Video |
|---|---|---|---|
| FP32 | 93.56 GB | Not Recommend | Not Recommend |
| BF16 | 31.11 GB | 41.85 GB | 60.19 GB |
注意:上表给出了使用 Transformers 和 BF16是用 attn_implementation="flash_attention_2";但是,在实际应用中,实际内存使用量通常至少是原来的 1.2 倍。有关详细信息,请参阅链接资源 此处。
视频 URL 的兼容性主要取决于第三方库的版本。详情如下表所示。通过 FORCE_QWENVL_VIDEO_READER=torchvision 或 FORCE_QWENVL_VIDEO_READER=decord 如果您不想使用默认设置。
| Backend | HTTP | HTTPS |
|---|---|---|
| torchvision >= 0.19.0 | ✅ | ✅ |
| torchvision < 0.19.0 | ❌ | ❌ |
| decord | ✅ | ❌ |
当return_audio=False设置时,模型可以批处理由文本、图像、音频和视频等不同类型的混合样本组成的输入。下面是一个示例。
# Sample messages for batch inference
# Conversation with video only
conversation1 = [
{
"role": "system",
"content": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech.",
},
{
"role": "user",
"content": [
{"type": "video", "video": "/path/to/video.mp4"},
]
}
]
# Conversation with audio only
conversation2 = [
{
"role": "system",
"content": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech.",
},
{
"role": "user",
"content": [
{"type": "audio", "audio": "/path/to/audio.wav"},
]
}
]
# Conversation with pure text
conversation3 = [
{
"role": "system",
"content": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech.",
},
{
"role": "user",
"content": "who are you?"
}
]
# Conversation with mixed media
conversation4 = [
{
"role": "system",
"content": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech.",
},
{
"role": "user",
"content": [
{"type": "image", "image": "/path/to/image.jpg"},
{"type": "video", "video": "/path/to/video.mp4"},
{"type": "audio", "audio": "/path/to/audio.wav"},
{"type": "text", "text": "What are the elements can you see and hear in these medias?"},
],
}
]
# Combine messages for batch processing
conversations = [conversation1, conversation2, conversation3, conversation4]
# Preparation for batch inference
text = processor.apply_chat_template(conversations, add_generation_prompt=True, tokenize=False)
audios, images, videos = process_mm_info(conversations, use_audio_in_video=True)
inputs = processor(text=text, audios=audios, images=images, videos=videos, return_tensors="pt", padding=True)
inputs = inputs.to(model.device).to(model.dtype)
# Batch Inference
text_ids = model.generate(**inputs, use_audio_in_video=True, return_audio=False)
text = processor.batch_decode(text_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(text)
使用提示
提示音频输出
如果用户需要音频输出,系统提示必须设置为 “您是阿里巴巴集团’奇文’团队开发的虚拟人’奇文’,能够感知听觉和视觉输入,并能生成文字和语音”,否则音频输出可能无法正常工作。
{
"role": "system",
"content": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech.",
}
在视频中使用音频
在多模态交互过程中,用户提供的视频往往会伴有音频(如对视频内容的提问,或视频中某些事件产生的声音)。这些信息有利于模型提供更好的交互体验。因此,我们提供了以下选项,供用户决定是否在视频中使用音频。
# first place, in data preprocessing
audios, images, videos = process_mm_info(conversations, use_audio_in_video=True)
# second place, in model inference
text_ids, audio = model.generate(**inputs, use_audio_in_video=True)
值得注意的是,在多轮对话中,use_audio_in_video这两处的参数必须设置为相同,否则会出现意外结果。
是否使用音频输出
模型支持文本和音频输出,如果用户不需要音频输出,可以设置 enable_audio_output 输出、他们可以设置 enable_audio_output=Falsefrom_pretrained函数中。该选项将保存约 ~2GB GPU 内存,但 return_audio选项的Generate函数将只允许设置为False。
model = Qwen2_5OmniModel.from_pretrained(
"Qwen/Qwen2.5-Omni-7B",
torch_dtype="auto",
device_map="auto",
enable_audio_output=False,
)
为了获得灵活的体验、我们建议用户将 enable_audio_output 设置为True 通过 from_pretrained函数初始化模型时、然后决定在调用 generate 函数时是否返回音频。当 return_audio设置为False、模型将只返回文本输出,以便更快地获得文本响应。
model = Qwen2_5OmniModel.from_pretrained(
"Qwen/Qwen2.5-Omni-7B",
torch_dtype="auto",
device_map="auto",
enable_audio_output=True,
)
...
text_ids = model.generate(**inputs, return_audio=False)
更改输出音频的语音类型
Qwen2.5-Omni支持更改输出音频的声音。"Qwen/Qwen2.5-Omni-7B"检查点支持以下两种语音类型:
| 声音类型 | 性别 | 说明 |
|---|---|---|
| Chelsie | Female | A honeyed, velvety voice that carries a gentle warmth and luminous clarity. |
| Ethan | Male | A bright, upbeat voice with infectious energy and a warm, approachable vibe. |
用户可以使用“generate”函数的“spk”参数来指定语音类型。默认情况下,如果未指定“spk”,默认语音类型为“Chelsie”。
text_ids, audio = model.generate(**inputs, spk="Chelsie")
text_ids, audio = model.generate(**inputs, spk="Ethan")
Flash-Attention 2 加快生成速度
首先,确保安装最新版本的Flash Attention 2:
pip install -U flash-attn --no-build-isolation
此外,您应该拥有与FlashAttention 2兼容的硬件。在[flash attention repository](https://github.com/Dao-AILab/flash-attention)的官方文档中阅读更多有关它的信息。FlashAttention-2只能在torch.float16或torch.bfloat16中加载模型时使用。
要使用FlashAttention-2加载和运行模型,请在加载模型时添加attn_implementation="flash_attention_2":
from transformers import Qwen2_5OmniModel
model = Qwen2_5OmniModel.from_pretrained(
"Qwen/Qwen2.5-Omni-7B",
device_map="auto",
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)

















 163
163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









