






CVPR2025:DORACAMOM: Joint 3D Detection and Occupancy Prediction with Multi-view 4D Radars and Cameras for Omnidirectional Perception
全向感知中基于4D Radar 和 Camera数据融合的3D目标检测和占据预测
文章目录
摘要
3D物体检测与占据预测是自动驾驶中的关键任务,受到广泛关注。尽管近期基于视觉的方法展现出潜力,但在恶劣条件下仍面临挑战。因此,将摄像头与新一代4D成像雷达结合以实现统一的多任务感知具有重要意义,但该领域的研究仍较为有限。本文提出DORACAMOM,首个通过融合多视角摄像头与4D雷达实现联合3D物体检测与语义占据预测的框架,旨在实现全面的环境感知。具体而言,我们提出一种粗体素查询生成器(Coarse Voxel Queries Generator),将4D雷达的几何先验与图像的语义特征结合以初始化体素查询,为后续基于Transformer的细化模块奠定坚实基础。为利用时序信息,我们设计了双分支时间编码器(Dual-Branch Temporal Encoder),在鸟瞰图(BEV)与体素空间中并行处理多模态时序特征,实现全面的时空表征学习。此外,我们提出跨模态BEV-体素融合模块(Cross-Modal BEV-Voxel Fusion Module),通过注意力机制自适应融合互补特征,同时引入辅助任务以增强特征质量。在OmniHD-Scenes、View-of-Delft(VoD)和TJ4DRadSet数据集上的大量实验表明,DORACAMOM在两项任务中均达到最先进性能,为多模态3D感知树立了新基准。(代码尚未开源)
- 开源后补充Link
关键词
Autonomous driving, camera, 4D radar, deep learning, omnidirectional perception, 3D object detection, 3D occupancy prediction.
一、介绍
自动驾驶技术作为现代交通革命的前沿领域,正引发广泛关注。自动驾驶技术已成为现代交通革命的前沿领域,备受瞩目。自动驾驶系统通常包含环境感知、轨迹预测与规划控制等模块,以实现自动驾驶功能。精确的3D感知是其关键基础,主要聚焦于3D物体检测与语义占据预测两大任务。其中,3D物体检测通过3D边界框定位场景中的前景目标,并预测类别、速度等属性,属于稀疏场景表征[1];而语义占据则利用细粒度体素表征捕捉场景的几何与语义特征,属于密集场景表征[2]。为实现这些任务,通常采用车载摄像头、激光雷达(LiDAR)及毫米波雷达等传感器采集环境数据作为输入。
在各类传感器中,激光雷达(LiDAR)基于飞行时间(TOF)原理工作,通过发射并接收激光束生成密集点云数据,能够为环境提供高精度几何表征[3–7]。然而,激光雷达易受恶劣天气影响且成本高昂[8]。相比之下,摄像头和雷达更具性价比优势,适合大规模部署应用。摄像头能够获取高分辨率的丰富色彩与纹理信息,但缺乏深度感知能力且易受天气干扰[9]。雷达则通过发射电磁波探测目标距离、多普勒和散射信息,在复杂气象条件下展现出较强的鲁棒性[10]。
四维成像雷达作为传统雷达的升级技术,不仅在原有基础上增加了高程信息维度,还能够提供相比传统"2+1维"雷达更高分辨率的点云数据。最新研究表明,该技术在多种下游任务中展现出显著的应用潜力[11,12]。然而相较于激光雷达,其生成的点云仍存在稀疏性和噪声干扰的问题。因此,通过跨模态融合技术有效弥补这些缺陷显得尤为必要,这突显了将摄像头与四维成像雷达信息进行深度融合的重要性。
近年来,随着四维雷达数据集的问世,四维雷达与摄像头融合技术在环境感知领域展现出重要潜力。当前主流融合技术多采用鸟瞰图(BEV)架构,将原始传感器输入转化为BEV特征进行整合。这种视角不仅能缓解前景物体的遮挡问题,还能保持尺度一致性。此类方法的核心在于通过先进的视角变换算法,将缺乏深度信息的图像数据转换至鸟瞰空间。对于占据预测任务,由于需要细粒度体素表征和语义信息,现有研究主要集中在以视觉为核心或视觉与激光雷达融合的方案。传统雷达因缺乏高度信息,难以支持三维占据预测,而四维雷达凭借高程信息和高分辨率点云为此提供了新可能,但相关研究仍处于起步阶段。此外,将三维目标检测与占据预测作为统一多任务框架下的两项关键感知任务进行整合,可优化计算资源利用率与效率,具有显著应用价值。
为此,我们提出Doracamom这一统一框架,首次实现多视角摄像头与四维成像雷达点云的融合,协同处理三维目标检测与语义占据预测两项任务。本文的主要贡献如下:
• 提出Doracamom框架,这是首个融合摄像头与四维成像雷达的联合三维目标检测与占据预测统一框架,实现全面环境感知与理解。
• 设计了三个核心模块以提升模型性能:
- 粗粒度体素查询生成器(CVQG)通过融合4D Radar 几何线索与Camera 图像语义信息,建立高质量初始化的体素查询以实现有效特征优化;
- 双分支时序编码器(DTE)在鸟瞰图与体素空间并行开展时序建模,捕获场景的全面时空表征;
- 跨模态BEV-体素融合模块(CMF)通过注意力机制自适应融合互补特征,并引入辅助二元占据预测与BEV分割任务指导特征学习过程,获得更具判别性的表征。
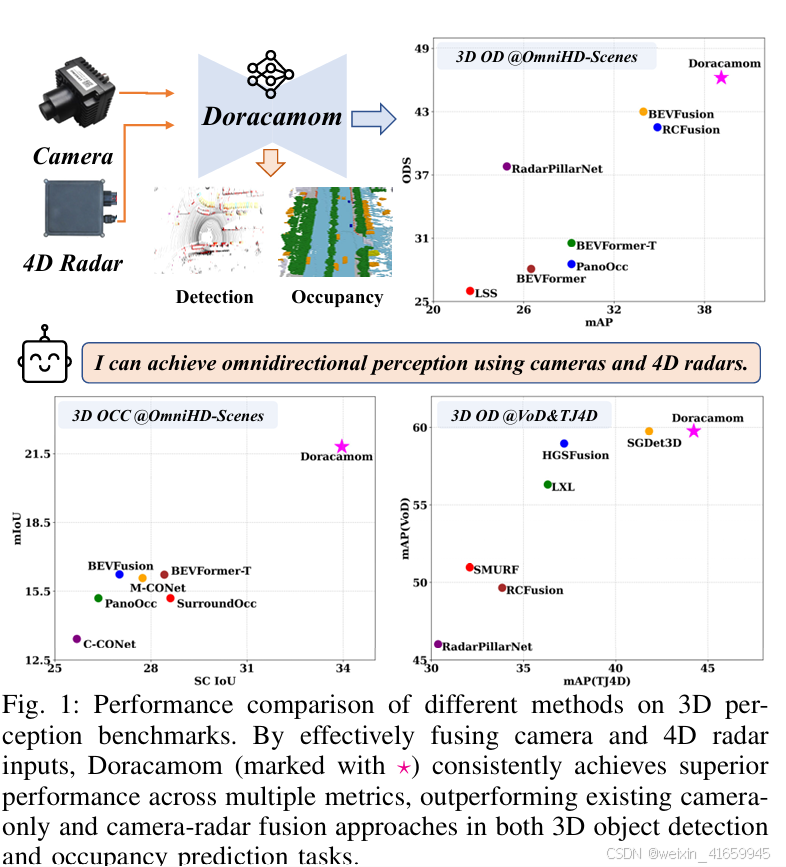
• 大量实验表明,Doracamom在OmniHD-Scenes[13]、VoD[14]、TJ4DRadSet[15]等多个四维成像雷达数据集上(如图1所示),均取得业界领先性能,为四维成像雷达与摄像头融合的三维目标检测及占据预测任务树立了新基准。
二、相关工作
1.基于Camera的3D感知
近年来,三维感知研究主要聚焦于基于视觉的方案。早期研究虽能直接从单张图像回归三维属性[16],但此类单目方法易受遮挡与视角变化的干扰。这促使研究者们转而关注基于鸟瞰图(BEV)表征的多视图方法,通过将二维特征转换至三维空间实现更鲁棒的感知[17–21]。
现有方法可分为三大类:第一类基于深度预测,以LSS[18]为代表,通过深度分布估计与体素池化操作将二维特征提升至鸟瞰空间;BEVDepth[20]、BEVDet[19]和BEVDet4D[22]在此基础上引入激光雷达监督与时序融合[23]进行扩展。第二类采用反投影策略,如OFTNet[24]和simpleBEV[25]通过将三维体素投影至二维图像进行特征采样。第三类基于注意力机制,BEVFormer[21]利用BEV查询与可变形注意力[26]实现自适应特征聚合,而DETR3D[27]、PETR[28]及Sparse4D[29]则通过对象查询在不显式构建BEV特征的情况下展现优异性能。
基于视觉的占据预测技术通过将二维特征转换至三维空间,构建鸟瞰图(BEV)特征[30]、三维金字塔(TPV)特征[31]或体素特征[32]实现环境建模。现有方法主要分为投影法、深度法与交叉注意力法[2]。其中,MonoScene[33]采用投影与U-Net网络实现语义补全;FlashOcc[30]与FastOcc[34]沿用LSS[18]框架预测深度分布,并通过通道到高度转换操作[30]提升内存效率;SurroundOcc[32]、PanoOcc[35]及TPVFormer[31]则利用可变形注意力机制[26]进行特征聚合。近期研究包括:AdaptiveOcc[36]通过八叉树结构优化体素表征,LinkOcc[37]引入稀疏查询与近在线训练、对比学习相结合的方式实现时序关联建模。
2.基于传统Radar+Camera 融合的3D感知
传统汽车雷达受限于角分辨率,生成的点云数据稀疏且缺乏高度信息,需结合摄像头进行融合感知[10]。CenterFusion[38]通过二维检测器生成视锥ROI区域,并与雷达点柱体建立关联;特征级融合方法多在BEV层面[39,40]或提案阶段[41,42]开展。CRN[39]利用雷达实现BEV空间转换,并通过多模态可变形注意力实现特征对齐;RCBEV[43]融合点级与ROI级特征,而RCBEVDet[40]采用具备双重表征的RadarBEVNet网络,结合RCS感知的BEV特征,通过跨模态注意力机制融合雷达与图像BEV特征。CRAFT[41]在极坐标系下建立提案与雷达点的关联,CramNet[44]则利用射线约束注意力构建几何对应关系。TransCAR[42]与FUTR3D[45]均基于DETR3D[27]扩展,利用对象查询实现雷达-摄像头特征交互。
除三维目标检测外,近期研究开始探索摄像头与雷达融合在占据预测中的应用。Occfusion[46]采用动态2D/3D融合策略构建多层级特征表征,LiCROcc[47]则通过跨模态蒸馏模块实现语义场景补全。然而,传统雷达数据固有的稀疏性与高度信息缺失问题,仍对三维语义占据任务构成严峻挑战。
3.近期基于4D Radar的感知研究进展
在三维目标检测领域,多项研究通过四维成像雷达独立应用或与其他传感器融合取得了显著成果。RPFA-Net[64]利用自注意力机制进行四维成像雷达特征提取,SMURF[65]通过柱化处理并结合多维高斯混合核密度估计(KDE)生成的密度特征,有效缓解四维成像雷达点云的稀疏性与噪声问题。SCKD[66]采用半监督知识蒸馏策略,从激光雷达与雷达融合的教师网络中迁移知识。InterFusion[67]通过自注意力机制分别学习激光雷达与四维成像雷达模态特征,并在中间层进行信息交互。RCFusion[68]利用RadarPillarNet对四维成像雷达点云进行层级化特征提取,并借助交互式注意力机制实现摄像头与四维成像雷达BEV特征的高效融合。UniBEVFusion[69]提出雷达深度LSS(RDL)模块改进深度估计能力,并通过统一特征融合(UFF)模块整合多模态特征。LXL[70]提出"雷达占据辅助的深度采样"策略,将预测深度与三维雷达占据栅格结合以辅助图像视角变换。**SGDet3D[71]**设计几何与语义双分支融合架构,结合目标导向注意力机制实现雷达-摄像头特征交互,HGSFusion[72]则提出混合点生成与双同步融合框架。近期,**DPFT[73]**通过在三维空间进行查询采样实现四维成像雷达张量与摄像头特征的融合,取得优越性能。
在占据预测任务中,RadarOcc[74]利用四维成像雷达张量实现了二值占据预测,但仅能区分前景与背景,无法提供更精细的语义信息。考虑到处理原始雷达张量需消耗大量计算资源,此类方法难以满足实时应用需求。另一方面,雷达点云作为高级驾驶辅助系统(ADAS)与自动驾驶系统中广泛采用的数据形式,基于实用化四维成像雷达点云的三维语义占据预测研究仍处于探索阶段。
三、方法
1.整体框架
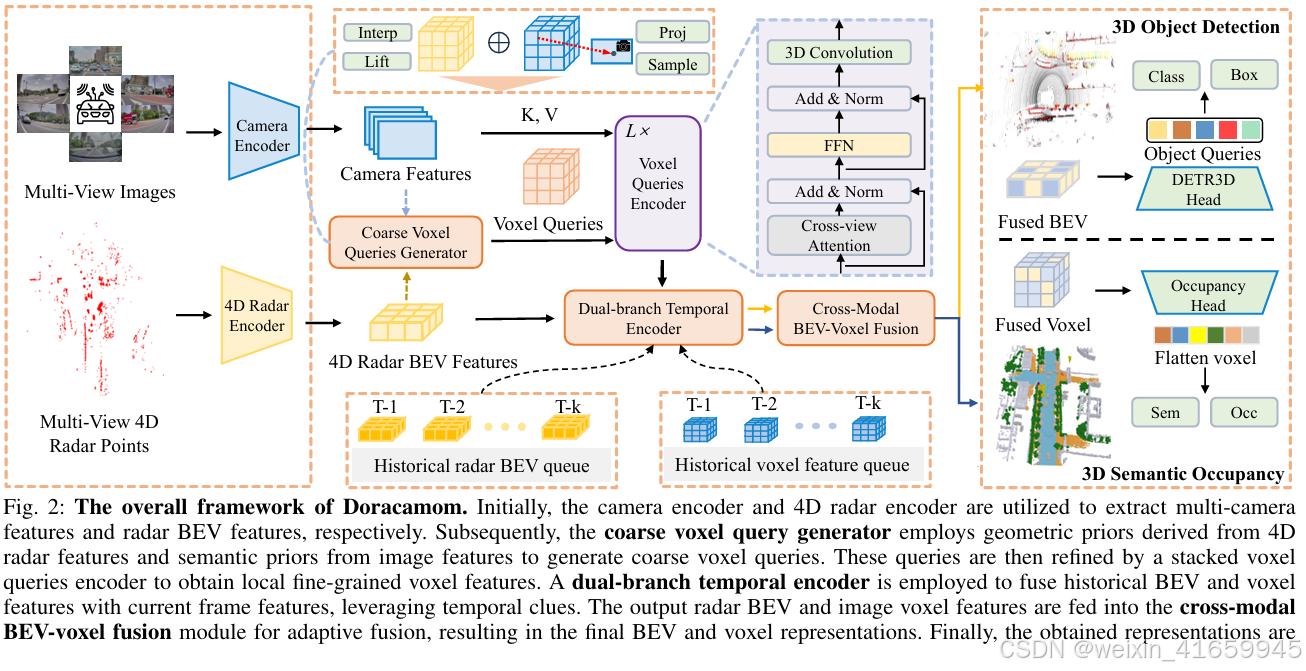
我们提出DORACAMOM这一统一多任务框架,通过融合多视角图像与4D Radar点云实现联合三维目标检测与占据预测。如图2所示,其整体架构包含以下核心组件:
首先,多视角图像与四维成像雷达点云分别输入摄像头编码器与四维成像雷达编码器,提取图像二维特征与雷达鸟瞰图(BEV)特征。随后,粗粒度体素查询生成器(CVQG)融合图像与雷达特征,生成具有几何-语义感知的粗粒度体素查询。体素查询编码器通过堆叠的Transformer模块与交叉视角注意力机制迭代优化细粒度体素特征。双分支时序编码器(DTE)利用时序线索分别增强BEV与体素特征表征。跨模态BEV-体素融合模块(CMF)自适应整合双模态特征,最终输出的BEV与体素特征将输入多任务预测头完成目标检测与占据预测。
2.Camera & 4D Radar 编码器
在特征提取阶段,我们采用了解耦的架构,以分别从两种输入模态中独立提取高维特征。相机编码器处理多视图图像,这些图像表示为 I ∈ RNC×3×HI×WI,其中 NC是相机的数量,HI 和 WI是图像的高度和宽度,3 对应于 RGB 通道。特征提取是通过共享的 ResNet-50 [75] 主干网络和特征金字塔网络(FPN)[76] 作为颈部结构来完成的,该结构获取多尺度特征,并将其简化为单一尺度的表示 FI =
{Fi I}NC i=1, 其中 Fi I ∈ RC× HC× WC,是第 i个视图的特征,C 表示特征维度,而 HC 和WC 是特征图的空间维度。
为了解决4D雷达点云的稀疏性问题,并通过消除自车运动效应来获取它们的地面速度,我们实现了一种预处理流程,该流程结合了多帧雷达点云的累积和速度补偿。该算法使用对应的自车速度 Ve ∈ R3× 1处理每个雷达扫描区域s,该速度通过雷达到自车旋转矩阵Rr→e ∈ R3× 3 转换到雷达坐标系中,得到Vrad ∈ R3× 1。为了补偿相对径向速度,速度矢量根据每个点的方位角 ϕ 和仰角 θ分解为径向方向。补偿后的速度分量随后通过旋转矩阵 Rr→e ∈ R3× 3 and Re→e′ ∈ R3× 3转换到当前自车坐标系中。对于每个点的位置,变换是通过使用雷达到自车的变换矩阵 Rr→e ∈ R3× 3 和 tr→e ∈ R3× 1,以及从扫描时间到当前时间的自车姿态变换矩阵Re→e′ ∈ R3× 3 和 te→e′ ∈ R3× 1 来实现的。需要注意的是,由周围动态物体运动引起的点的运动在累积操作中被忽略,因为这种运动很少引入较大的误差。
4D雷达编码器处理输入的点云P ∈ RNR×D,其中 NR 和 D分别表示点的数量和属性维度。我们采用了 RadarPillarNet [68] 来对输入的4D雷达点云进行编码,该方法通过分层特征提取生成伪图像。编码后的特征随后通过 SECOND 和 SECONDFPN [77] 进一步处理,以生成精炼的4D雷达鸟瞰图(BEV)特征 FR ∈ RCR× H× W,其中CR表示特征维度,(H, W) 表示鸟瞰图的分辨率。
3.粗糙体素查询生成器
我们将空间中的3D体素查询表示为Q ∈ RC×HV×WV×ZV,其中 (HV,WV,ZV) 表示体素网格的分辨率。为了降低计算开销,我们将体素网格的鸟瞰图(BEV)平面分辨率设置为 (HV,WV)=(H/2,W/2)。
然而,现有的方法 [32, 35] 通常使用随机初始化来生成体素查询,这种方法可能会增加模型训练过程的复杂性。为了解决这一局限性并提高视图转换的保真度,我们引入了一种新颖的初始化方法,该方法将从4D雷达数据中提取的几何先验与从图像中提取的语义特征相结合。这种结合使得能够生成具有几何和语义先验的粗粒度体素查询,为后续的细化过程奠定了更坚实的基础。受 [25, 34] 的启发,我们设计了一个体素查询初始化流程,如下所述。
在雷达特征处理阶段,我们首先通过双线性插值将雷达鸟瞰图(BEV)特征 FR 转换为与体素网格对齐的特征,得到 F′ R ∈ RCR× HV× WV 。随后,我们使用Conv-BN-ReLU(CBR)进一步优化特征通道。通过在高度维度上对2D BEV特征进行简单的“扩展”(Unsqueeze)操作,我们获得了雷达3D体素特征QR,这可以用数学公式表示为: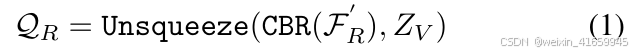
对于图像特征处理,我们采用了一种与文献 [25, 78] 类似的方法。我们首先在自车坐标系内定义了 3D 参考点Pref ∈ RHV× WV× ZV× 3 ,这些参考点的形状基于 3D 体素查询的形状。与此同时,我们将体素特征QI ∈ RC× HV× WV× ZV初始化为0。
接下来,我们计算从自车坐标系到图像像素坐标的变换矩阵 Te→I ∈ R3× 4 。这个变换矩阵是通过相机的内参矩阵 K ∈ R3×4和外参矩阵Te→c ∈ R4× 4计算得到的:

利用Te→I,我们将参考点投影到每个图像平面上,以获得它们在特征图上的对应坐标 ((x, y, z)。有效点的确定基于两个标准:(x, y) 必须位于特征图边界内,且 z 必须为正值(该标准是否假设图像识别是准确的???)。特征采样过程采用最近邻插值,**并使用“后更新”策略解决多视图区域的重叠问题。**最终的粗粒度体素查询Q通过元素级加法得到:

4.体素查询编码器
为了增强和细化体素查询,我们采用了一个基于Transformer的L层架构进行特征编码。受文献 [21, 26, 32] 的启发,我们采用了可变形注意力进行跨视图特征聚合。这种方法不仅缓解了遮挡和模糊问题,还通过减少训练时间提高了效率。
在跨视图注意力模块中,输入包括体素查询 Q ∈ RC×HV×WV×ZV、对应的3D参考点 Pref ∈ RHV× WV× ZV× 3和图像特征 FI = {Fi I}NC。3D参考点通过相机参数投影到2D视图中,图像特征从命中视图中进行采样和加权。输出特征QO可以表示为:

其中,i表示图像视图索引, Qp和 QPO分别表示第 p个体素特征及其输出特征,Proj(Pp ref,i)表示将3D参考点投影到第 i 个图像视图的投影函数,Vhit表示可见视图的集合。与文献 [32] 类似,我们采用3D卷积来代替计算成本高昂的3D自注意力,以实现邻近体素特征的交互。
4.双分支时间编码器
时间信息在感知系统中起着至关重要的作用。现有的方法 [21, 78] 已经证明,利用时间特征可以有效地解决遮挡问题,增强场景理解,并提高运动状态估计的准确性。然而,这些方法仅限于在单一特征空间中进行时间建模,使得难以捕捉全面的时空表示。
为了解决这一局限性,我们提出了一种新颖的双分支时间编码器模块,该模块在鸟瞰图(BEV)和体素空间中并行处理多模态时间特征,如图4所示。具体来说,雷达BEV分支擅长捕获全局几何特征,而图像体素分支则专注于保留细粒度的语义信息。这种互补的双分支设计不仅在特征表达和时间建模方面提供了多样化的表示能力,还实现了计算成本和特征表达能力之间的优化平衡。此外,特征冗余机制显著增强了感知系统的鲁棒性。
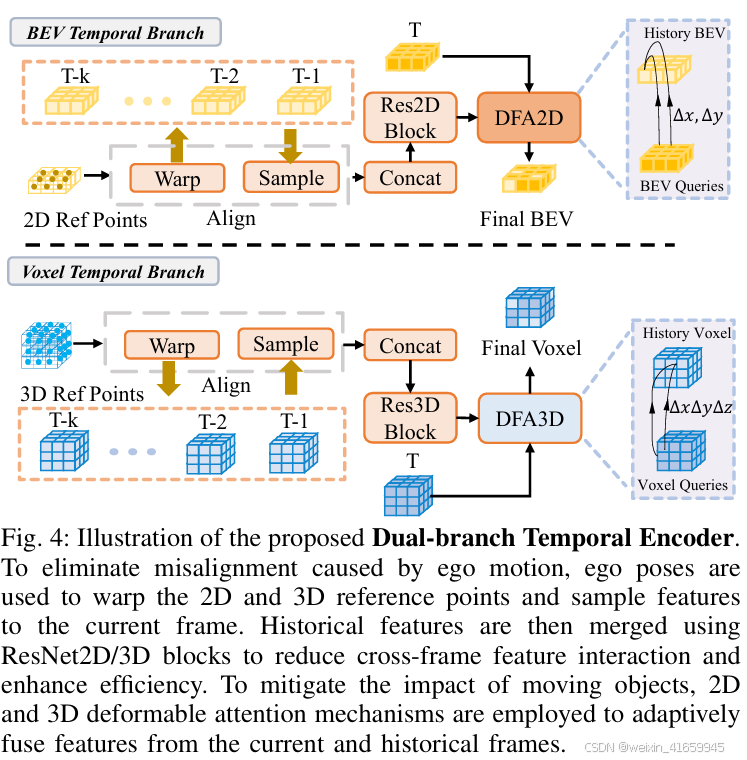
在时间特征融合中,一个关键挑战是由自我运动和动态物体运动导致的特征错位。为了解决由自我运动引起的特征位移问题,我们提出了一种基于姿态变换的特征对齐策略,该策略能够精确地将历史特征与当前帧对齐。具体来说,在体素时间分支中,给定当前帧t 在自车坐标系中的3D参考点P3D t ∈ RHV×WV×ZV×3,我们利用当前帧和历史帧的姿态序列 {Tt,Tt−1,Tt−2,…,Tt−k|Tt−i ∈ R4× 4}将这些参考点变换到对应的历史时间戳。随后,我们采用三线性插值来采样时间对齐后的特征。详细的计算过程如下:
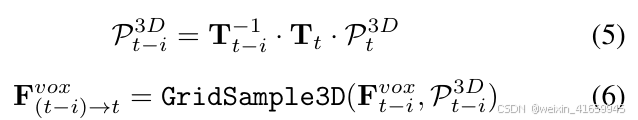
其中,P3D t-i表示在历史时间戳 t-i处变换后的3D参考点, Fvox (t−i)→t ∈ RC× HV× WV× ZV 表示对齐后的历史特征,形成一个时间特征序列 {Fvox (t−1)→t,Fvox (t−2)→t,…, Fvox (t−k)→t}。
同样地,在鸟瞰图(BEV)时间分支中,我们通过将高度维度设置为零来定义2D参考点P2D
t ∈ RH×W×3。历史特征是通过将这些参考点变换到对应的时间戳后,使用双线性插值采样得到的,这可以表示为: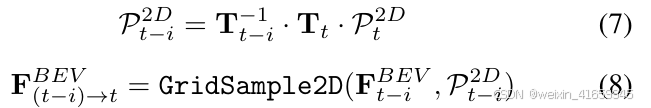
其中,P2D t−i 表示在历史时间戳t−i 处变换后的2D参考点, FBEV (t−i)→t 表示对齐后的历史特征,形成一个时间特征序列 FBEV (t−1)→t,FBEV (t−2)→t,…, FBEV (t−k)→t,用于鸟瞰图(BEV)分支。
为了进一步缓解由动态物体引起的特征错位,我们采用可变形注意力来适应性地融合当前帧和历史帧之间的特征。对于体素时间分支,我们首先将对齐后的历史特征进行拼接,并通过一个简单的Res3D块进行高效的特征集成,这可以表示为:
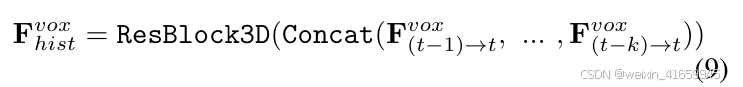
随后,我们采用可变形注意力来适应性地整合当前和历史特征。融合过程可以表示为:

其中, Fvoxp 和 Fvoxp o 分别表示位于p3D = (x,y,z)处的体素特征及其输出特征。
对于鸟瞰图(BEV)时间分支,应用了类似的过程。首先将历史BEV特征进行拼接,并通过一个Res2D块进行处理:
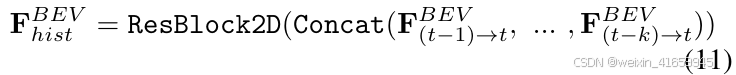
然后,采用可变形注意力进行特征融合:

其中, FBEVp和 FBEVp o分别表示位于 p2D = (x,y)处的BEV特征及其输出特征。
这种综合方法通过结合BEV分支中的全局几何模式和体素分支中的细粒度语义细节,确保了鲁棒的时间特征融合,从而实现了更准确的感知结果。
5.跨模态BEV-Voxel 融合模块
为了有效利用来自体素和鸟瞰图(BEV)空间的时间增强特征,我们提出了一种跨模态BEV-体素融合模块,该模块生成几何和语义丰富的多模态表示,用于下游多任务解码。如图5所示,该模块通过注意力加权机制自适应地融合异构特征,同时利用辅助任务进一步提高生成特征的质量。
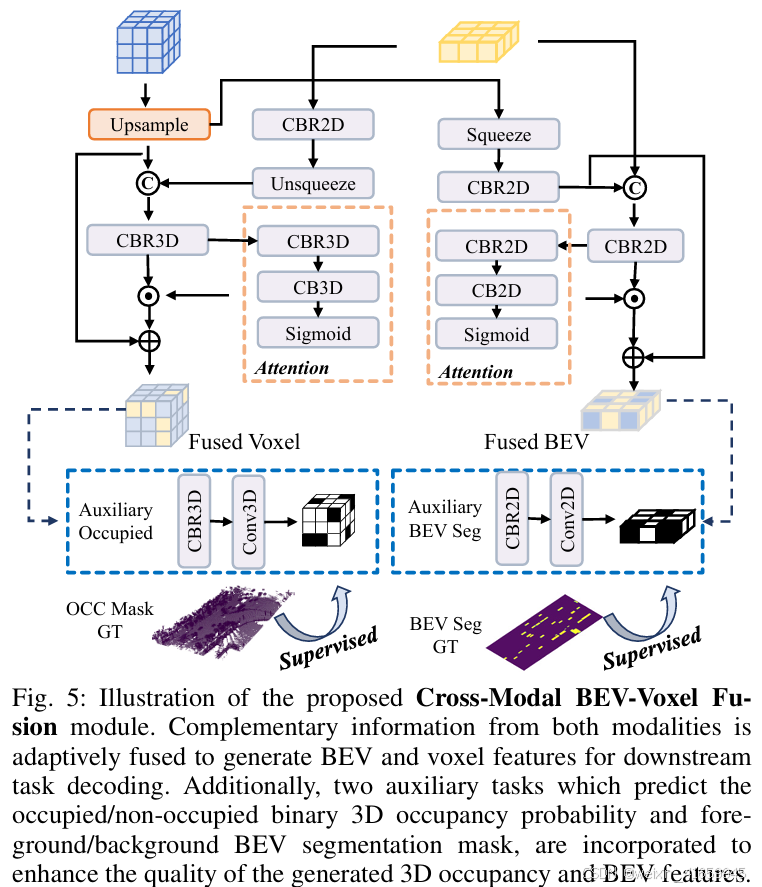
具体来说,该模块首先通过3D反卷积块对低分辨率体素特征进行上采样,以获得用于后续融合的高分辨率特征 Fvox ∈ RC×H×W×Z 。为了增强体素特征,雷达BEV特征FBEV 首先通过2D中的Conv-BN-ReLU块进行处理,以重塑特征通道,然后通过unsqueeze操作沿高度维度扩展2D BEV特征。扩展后的特征随后与体素特征进行拼接,并通过卷积块处理以减少通道维度。最后,通过带有注意力机制的交叉模态跳跃连接的残差结构得到融合特征。该过程表示如下:
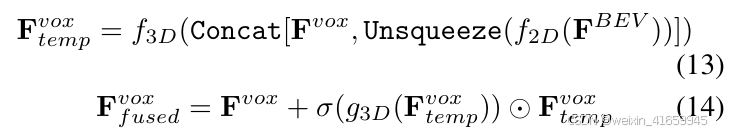
其中,f2D(·)和f3D(·)分别表示2D和3D中的Conv-BN-ReLU块,g3D(·) 表示注意力块中的卷积操作, σ(x) = 1/(1 + e−x) 是sigmoid函数, ⊙ 表示元素级乘法。Fvox temp和 Fvox fused分别是中间和最终融合的体素特征。
同样地,对于BEV特征增强,首先通过squeeze操作将体素特征Fvox 沿高度维度压缩,然后通过CBR2D块调整特征通道,得到变换后的特征FBEV′ ∈ RC×H×W。处理后的特征随后与雷达BEV特征进行拼接,并通过卷积块进行精炼。采用类似的残差注意力结构来获得最终融合的BEV特征。这一过程可以表示为:
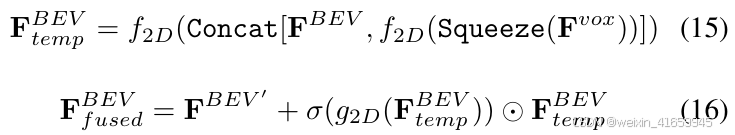
其中, g2D(·) 表示2D注意力块中的卷积操作,FBEV temp 和 FBEV fused 分别是中间和最终融合的BEV特征。
此外,为了增强最终的特征表示并提高特征质量以用于后续解码,我们引入了带有显式监督的辅助任务。对于融合后的体素特征,我们通过3D卷积块估计二进制占用掩码Mvox ∈ RH×W×Z,并由从语义占用标签中得出的二进制占用/非占用真实值进行监督。同样地,对于融合后的BEV特征,我们将检测真实值投影到BEV平面上,以获得代表前景物体和背景的二进制分割真实值,并通过2D卷积块生成相应的预测掩码 MBEV ∈ RH×W。这两个辅助任务都使用Dice损失和二进制交叉熵(BCE)损失的组合进行监督。这些辅助的二进制监督信号有助于引导特征学习过程,确保在适合下游任务的区域中逐步生成更具判别性的特征,并包含更具体的语义信息,即3D语义占用预测和3D目标检测。不懂,后续研读
6.多任务训练
基于增强的几何和语义感知的鸟瞰图(BEV)和体素表示,我们可以进行端到端的联合训练,以实现3D目标检测和占用预测,从而实现全面的感知能力。
对于3D目标检测,除非另有说明,我们采用基于DETR的检测头。该检测头以融合后的BEV特征 FBEV fused作为输入,并直接预测目标类别和属性。具体来说,每个3D边界框由10个参数参数化:尺寸 ((l, w, h)、中心位置 (x_o, y_o, z_o)、方向 (cosθ,sinθ)和速度 (vx,vy)。这种端到端的方法消除了诸如非极大值抑制(NMS)等后处理步骤的需要。检测损失 Ldet包括用于分类的焦点损失和用于回归的L1损失,可以表示为:
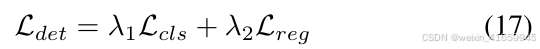
其中, λ1 = 2.0和λ2 = 0.25是用于平衡分类和回归损失的超参数。
对于占用预测,我们在融合后的体素特征 Fvox fused上使用简单的多层感知机(MLP)来预测每个体素的语义占用情况。占用预测损失 Locc 包含三个部分:主要的交叉熵损失Lce 用于基本监督,以及两个亲和损失 Lgeo scal 和 Lgeo scal ,后者由文献 [33] 提出,分别用于优化场景级和类别级指标。占用损失 Locc 可以表示为:
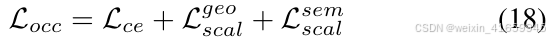
对于前景/背景BEV分割和占用/非占用二进制占用预测辅助任务,我们采用BCE损失和Dice损失的组合进行监督。辅助损失Laux 可以表示为:
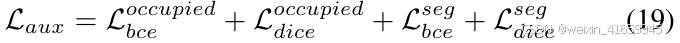 总损失表示为:
总损失表示为:
 —
—
四、试验与性能分析
1.数据集&评估指标
a) 数据集:
在OmniHD-Scenes、VoD、TJ4RadSet 3个数据集对模型性能进行评价。数据集提供了由同步传感器测量的数据,这些传感器包括4D成像雷达、摄像头和激光雷达,同时还提供了3D目标标注。值得注意的是,OmniHD-Scenes还提供了静态场景的语义标签和密集的3D占用真实值,使得能够对我们的多任务框架进行全面评估。
OmniHD-Scenes 是一个近期的大型多模态数据集,具有全面的全方位传感器套件,包括六个摄像头、六个4D成像雷达和一个128线激光雷达。该数据集包含1501个序列,每个序列时长30秒,在包括夜间、雨天和复杂交通状况在内的多样化场景下进行捕捉。目前,200个片段提供了标注,包括3D跟踪标注、静态场景分割标注和密集语义占用真实值。3D边界框标注涵盖了四类目标:汽车、行人、骑行者和大型车辆,而占用真实值包括11个语义类别。标注数据总共包含11921个关键帧,其中8321个用于训练,3600个用于测试。
VoD 数据集在代尔夫特的校园、郊区和老城区收集,包含5139个训练帧和1296个验证帧。
TJ4DRadSet 数据集包含5717个训练帧和2040个测试帧,涵盖城市街道、高架高速公路和工业区等多样化道路场景。这两个数据集都提供了来自前向设置的同步传感器数据,包括4D成像雷达、摄像头和激光雷达,以及3D边界框标注。前者包含三类目标:汽车、行人和骑行者,而后者还补充了卡车类别。
b) 评价指标:
对于 OmniHD-Scenes 数据集,我们使用官方定义的指标来评估在以自车为中心、纵向 ±60m 和横向 ±40m 的检测区域内的 3D 检测和占用预测性能。对于 3D 检测,我们采用平均精度均值(mAP)和四个平均真正例指标(mTP):平均平移误差(mATE)、平均尺度误差(mASE)、平均方向误差(mAOE)以及平均速度误差(mAVE)。此外,我们还采用 OmniHD-Scenes 检测得分(ODS)来评估综合性能,计算公式如下:
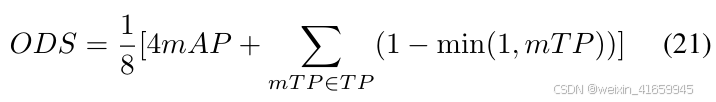
对于 3D 占用预测评估,我们采用两个关键指标:语义准确性的平均交并比(mIoU)和几何准确性的场景补全交并比。mIoU 通过对所有语义类别的 IoU 分数取平均计算得出,其中 IoU 衡量了每个类别中预测占用状态与真实占用状态的重叠程度。场景补全交并比则专门评估模型区分自由空间和占用空间的能力,通过计算这两种空间状态的 IoU 指标来实现。具体细节如下:
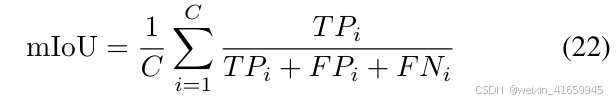
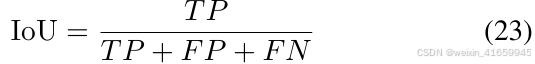
对于VoD和TJ4DRadSet数据集,根据官方定义的评估指标采用AP和mAP进行3D目标检测。
2. 详细设置
对于 OmniHD-Scenes 数据集,我们将点云范围限制在 X 轴的 (−60,60) 米、Y 轴的 (−40,40)米和 Z 轴的 (−3,5)米。雷达输入由 3 帧累积的点云组成,每个点由特征向量 [x,y,z,Power,SNR,vxr,vyr] 表示,其中Powe 和SNR分别表示幅度和信噪比,而 vxr和 vyr表示补偿后的绝对速度分量。所有六个摄像头图像被调整为 544×960的尺寸。低分辨率体素查询维度 HV × WV ×ZV 设置为 80×120×8,鸟瞰图(BEV)特征图大小H×W为 160×240,占用真实值的分辨率为 160 ×240×16。我们采用基于 DETR 的检测头,包含 900 个对象查询,并在推理期间保留置信度最高的前 300 个预测框。对于 VoD 和 TJ4DRadSet 数据集,我们遵循了与大多数最新技术相同的设置。
我们的模型实现基于 MMdetection3D [79] 框架,并使用 NVIDIA GeForce RTX 4090D GPU 进行训练。对于摄像头编码器,我们使用了 FCOS3D [16] 的预训练权重作为骨干网络,与 [21] 保持一致。4D 雷达编码器继承自 RadarPillarNet [68],并在各自的数据集上从零开始训练以用于 3D 检测。我们采用 AdamW 优化器进行训练,每个数据集的学习率不同:对于 OmniHD-Scenes,我们以 2 ×10(−4) 的学习率训练 16 个epochs;对于 VoD 和 TJ4DRadSet,我们分别以 1 ×10(−4)的学习率训练 16 epochs和 20 epochs。
除非另有说明,所有消融实验均在 OmniHD-Scenes 数据集上进行,采用多任务学习设置,并使用两个时间帧。
3. 与state-of-the-arts 的性能对比
a) 基于OmniHD-Scenes数据集:3D目标检测:
表 I 展示了在 OmniHD-Scenes 测试集上不同方法在 3D 检测任务上的性能比较。我们提出的 Doracacamom 在整体性能上(39.12 mAP 和 46.22 ODS)优于其他基于 4D 雷达、摄像头或其融合的方法。具体来说,与 BEV-Fusion [80] 相比,我们的方法在 mAP 上提高了 5.17,在 ODS 上提高了 3.22;与 RCFusion [68] 相比,在 mAP 上提高了 4.24,在 ODS 上提高了 4.69。即使在没有 DTE 模块的单帧设置中,我们的模型在 mAP 上仍然优于所有其他方法。此外,Doracacamom 显著缩小了与基于激光雷达的 PointPillars [3](46.22 ODS 对 55.54 ODS)的性能差距,这表明了我们提出的架构的有效性以及低成本传感器配置在自动驾驶感知系统中的巨大潜力。在 TP 指标方面,我们的方法在 mAOE 和 mAVE 上表现最佳,分别达到 0.3545 和 0.6151。
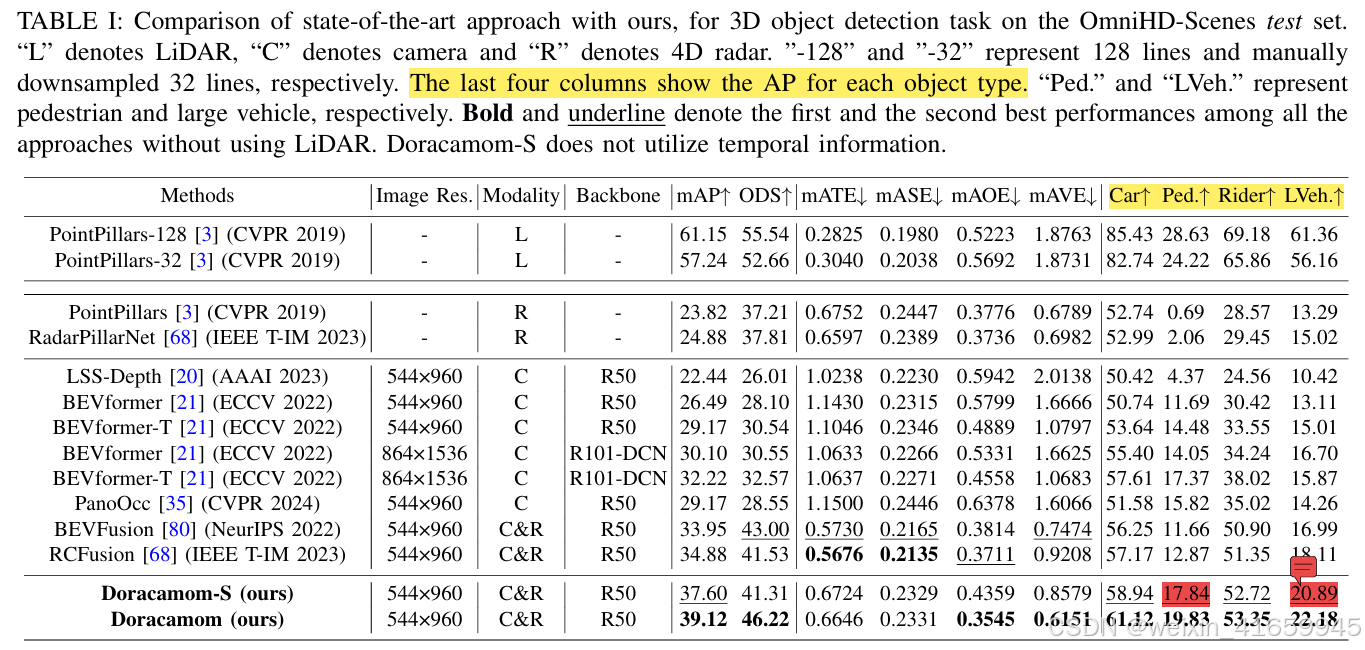
值得注意的是,得益于 4D 雷达固有的多普勒信息,独立使用 4D 雷达或将其与摄像头融合的方法在速度估计精度上显著优于仅使用摄像头或基于激光雷达的方法,速度预测的误差明显较低。此外,Doracacamom 通过高效利用 4D 雷达特征和 DTE 模块,实现了更精确的速度估计。对于每个目标类别,我们的方法在所有类别(汽车、行人、骑行者和大型车辆)中均取得了最高的 AP 分数。特别是,所有方法在行人和大型车辆上的检测精度相对较低,这可以归因于数据集中存在的几个挑战性因素。数据集中包含许多拥挤的场景,小区域内有数十人,导致严重遮挡。此外,从图像和雷达数据中提取的特征通常不完整且不够显著。此外,行人在 BEV 特征中仅占据几个网格,进一步增加了检测难度。对于大型车辆,其较大的尺寸通常导致在雷达和摄像头视图中轮廓不完整,从而产生显著的尺寸差异。
图6的可视化结果表明,Doracacamom能够在白天和夜间场景中提供可靠的性能。它在拥挤和复杂的场景中实现了高检测精度,只有偶尔出现远处被遮挡物体的漏检情况。

图7展示了不同方法的鸟瞰图(BEV)特征图。可以观察到,Doracacamom的特征图显示出明显的物体边界和高度可区分的特征,没有显著的问题,例如物体的严重拉伸或变形。

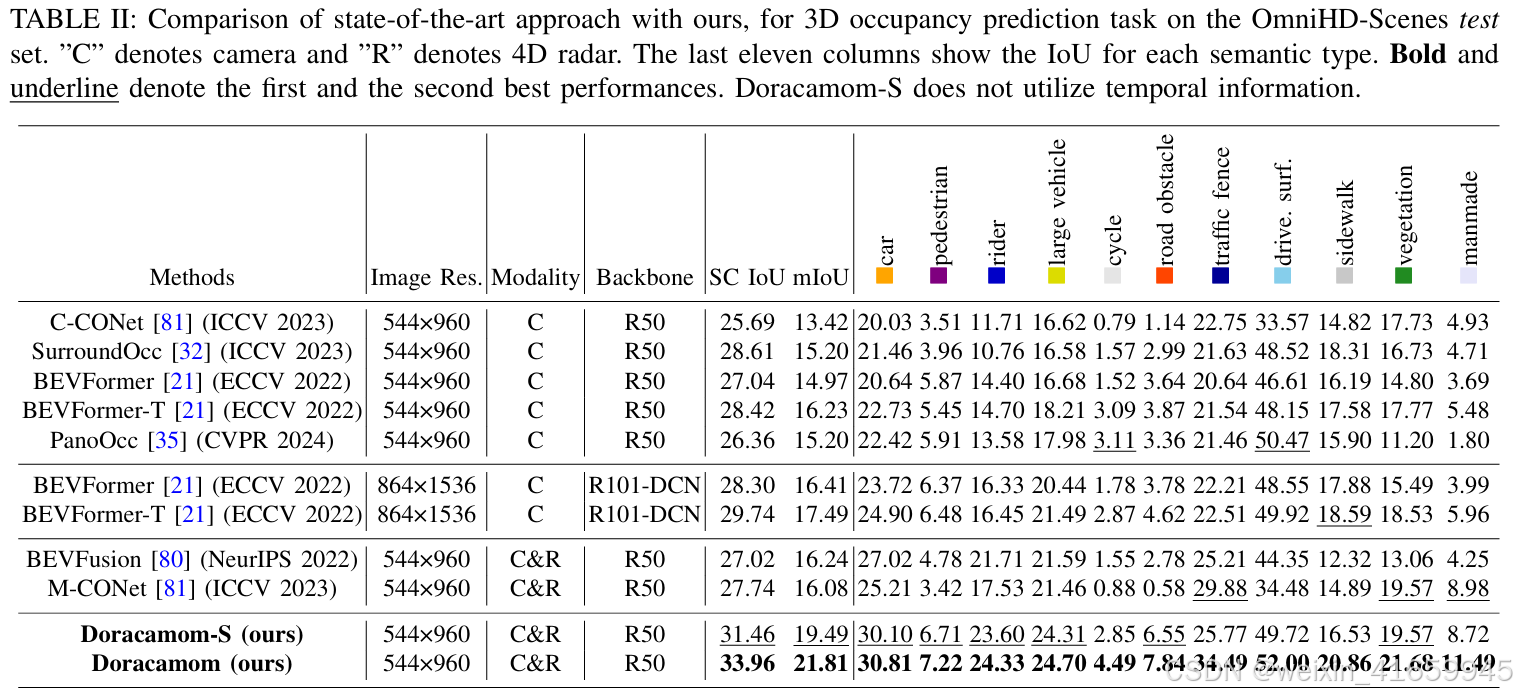
3D 语义分割:表 II 展示了在 OmniHD-Scenes 验证集上不同方法在占用预测任务上的性能比较。我们提出的 Doracacamom 实现了更优的整体性能(33.96 SC IoU 和 21.81 mIoU),优于其他方法。当 BEVFormer [21] 使用更大的骨干网络(R101-DCN)和更高分辨率的图像输入(846×1536)时,其性能超过了像 M-CONNet [81] 这样结合摄像头和 4D 雷达数据的多传感器融合方法。然而,凭借我们精心设计的架构,即使不使用时间信息,Doracacamom-S 在 SC IoU 和 mIoU 上仍显著优于 BEVFormer-T,分别提高了 1.72 和 2.00。此外,在各类别的 IoU 指标上,Doracacamom 和 Doracacamom-S 在检测对目标检测特别感兴趣的前景物体(即汽车、行人、骑行者和大型车辆)方面,性能优于其他模型。这种性能优势表明,在多任务设置中,目标检测和占用预测可以协同工作,以促进两项任务的完成。这种显著优势在图6中也得到了直观体现,表明 Doracacamom 在白天和夜间场景中均保持了强大的占用预测性能。在某些情况下,它甚至成功填补了真实值中存在的地面孔洞。然而,该模型在遮挡区域仍存在一些预测错误。
恶劣环境性能表现:
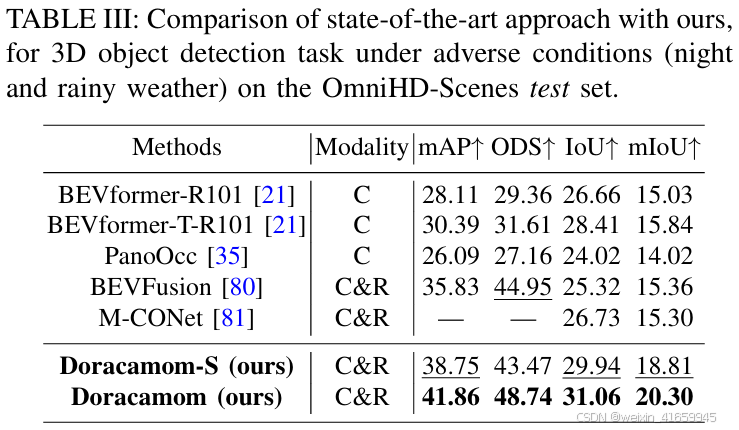
在恶劣条件下,Doracacamom 的性能优于其他模型,其平均精度(mAP)达到 41.86,综合检测得分(ODS)达到 47.74,展现出更强的鲁棒性。与表 I 的结果相比,基于摄像头的方法检测精度下降,而结合 4D 雷达和摄像头的方法性能有所提升。Doracacamom 在占用预测任务中也取得了 31.06 的场景交并比(SC IoU)和 20.30 的平均交并比(mIoU),持续优于其他模型,表明其卓越的鲁棒性。然而,与表 II 相比,所有模型的性能均有所下降,突显了摄像头输入在占用预测中的关键作用,因为摄像头性能的恶化直接影响整体模型性能。尽管如此,在 4D 雷达的辅助下,性能下降仍在可接受范围内,这表明 4D 雷达在恶劣条件下提供了更好的环境适应性。
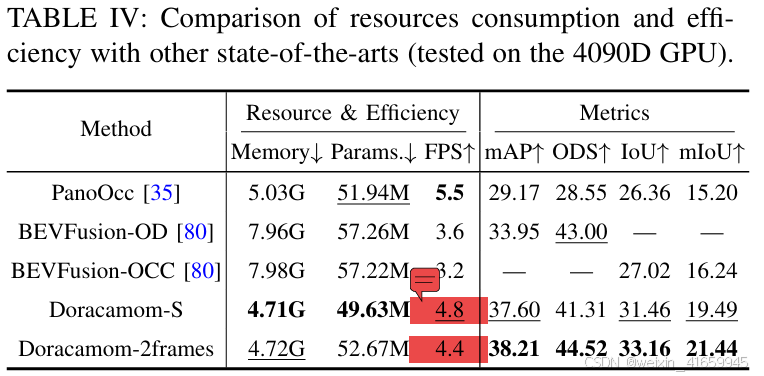
资源消耗与实时性:
表 IV 展示了不同模型在资源消耗和效率方面的比较。与现有方法相比,我们的 Doracacamom 系列模型在性能和效率之间取得了出色的平衡。在资源消耗方面,Doracacamom-S 仅需 4.71G 内存和 49.63M 参数,比 BEVFusion(约 8G 内存和 57M 参数)和 PanoOcc(5.03G 内存和 51.94M 参数)更轻量化。即使在引入 2 帧的情况下,Doracacamom-2frames 仍保持较低的资源占用(4.72G 内存和 52.67M 参数)。
在推理效率方面,Doracacamom-S 和 Doracacamom-2frames 分别实现了 4.8FPS 和 4.4FPS,显著优于 BEVFusion 系列(3.2-3.6FPS)。尽管略低于 PanoOcc(5.5FPS),但我们的模型在性能上具有显著优势:Doracacamom-2frames 在所有评估指标上均实现了最佳性能,显著优于其他方法。
b) 基于VoD & TJ4DRadSet数据集:
3D目标检测:
表 V 展示了在 VoD 和 TJ4DRadSet 数据集上各种方法的检测性能。由于现有的最新方法未利用时间信息,我们进行了无时间数据的实验以确保公平比较。在 VoD 数据集上,Doracacamom-S 实现了 59.76 的平均精度(mAP),略优于当前的最新方法 SGDet3D [71],尽管后者利用了额外的激光雷达数据进行深度监督。与 HGSFusion [72] 和 LXL [70] 相比,我们的方法分别提高了 0.8 mAP 和 3.45 mAP。在每种类别的 AP 指标方面,我们的方法在汽车检测方面表现最佳,在骑行者检测方面表现第二佳。
在 TJ4DRadSet 数据集上,Doracacamom-S 展现出更显著的领先优势,其平均精度(mAP)达到 44.24,超过了 SGDet3D [71] 和 HGSFusion [72] 分别 2.42 和 7.03 的 mAP。值得注意的是,我们的方法在包括行人、骑行者和卡车在内的多个类别上均取得了最新技术的结果。这些结果表明,我们的方法能够有效处理既有大量雷达反射点的大物体,也有反射点较少的小物体,验证了该架构在复杂场景中特征融合和利用方面的卓越能力。
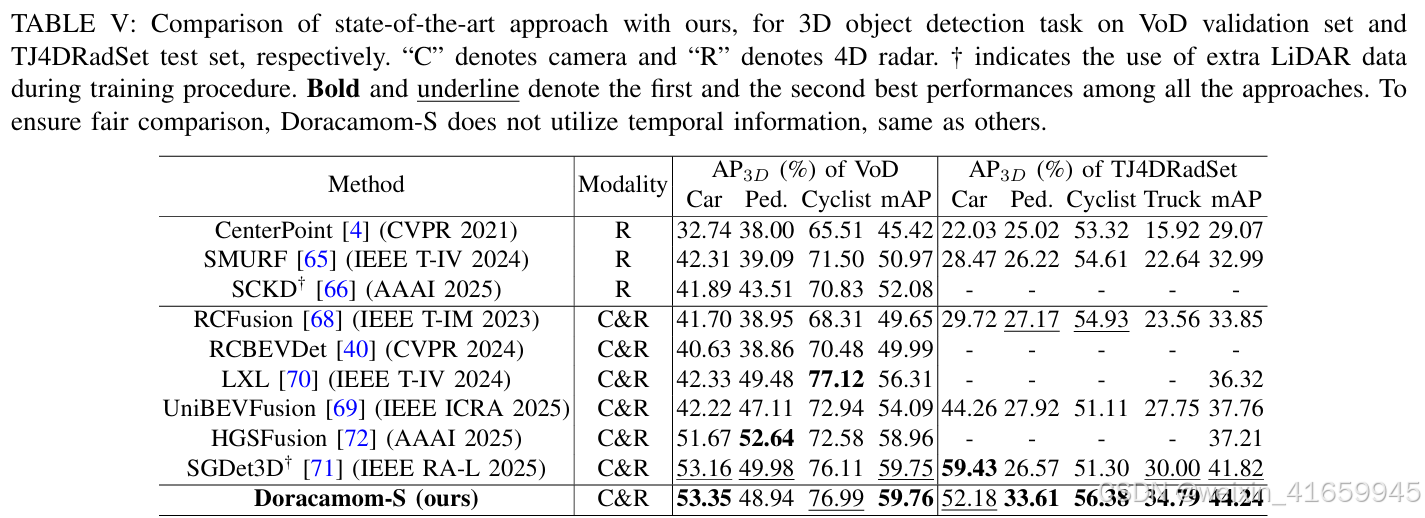
图8展示了来自TJ4DRadSet和VoD数据集的可视化结果。结果表明,Doracacamom-S在多种场景中保持了出色的性能,显示出较低的定位预测误差和准确的类别预测。只有在具有挑战性的遮挡条件下才偶尔观察到漏检现象。

4. 消融试验
主要组件的消融研究
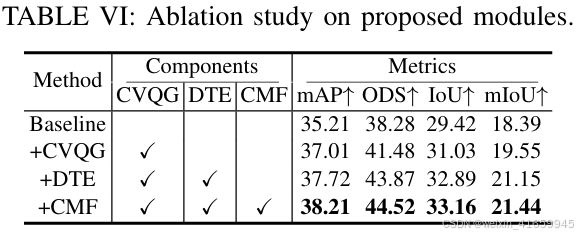
表 VI 展示了我们的核心组件对模型性能的影响,包括粗体素查询生成(CVQG)、双分支时间编码器(DTE)和跨模态 BEV-体素融合模块(CMF)。从一个基线模型(随机初始化、当前帧特征和特征求和)开始,我们逐步添加组件进行分析。
基线模型在检测任务中实现了 35.21 的平均精度(mAP)和 38.28 的综合检测得分(ODS),而在占用预测任务中达到了 29.42 的交并比(IoU)和 18.39 的平均交并比(mIoU)。引入体素查询生成(VQG)模块后,所有指标均显著提高(+1.80 mAP,+3.20 ODS,+1.61 IoU,+1.16 mIoU),验证了其在生成高质量初始查询方面的有效性。进一步加入双分支时间编码器(DTE)模块(2 帧)后,检测性能提升至 37.72 mAP 和 43.87 ODS,而占用预测改进为 32.89 IoU 和 21.15 mIoU,展示了其强大的时间特征融合能力。最后,完整模型在加入跨模态 BEV-体素融合(CMF)模块后,在所有指标上均达到最佳性能,确认了其强大的多模态特征融合能力。这些结果验证了所提出组件的有效性以及它们在我们框架内结合时的协同效益。
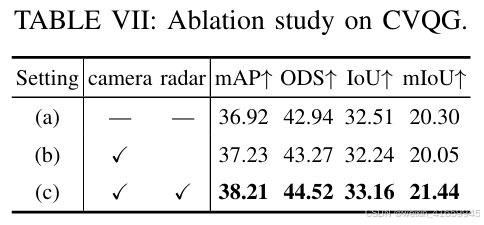
CVQG 的消融研究
表 VII 展示了 CVQG 模块的消融结果,以随机初始化作为基线。当结合图像语义特征进行查询初始化时,检测性能略有提升(+0.31 mAP,+0.33 ODS),但占用预测性能略有下降。进一步结合摄像头语义特征和4D雷达几何特征进行初始化时,所有指标均显著提升。与基线相比,检测性能提升了1.29 mAP和1.58 ODS,而占用预测提升了0.65 IoU和1.14 mIoU。这些结果表明,CVQG通过有效结合4D雷达的几何和动态特征与图像语义先验,成功提升了检测和占用预测任务的性能。
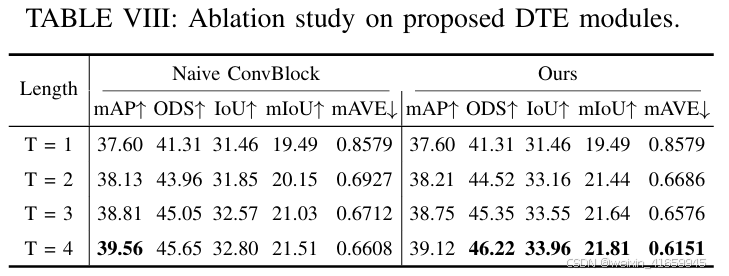
DTE 的消融研究
表 VIII 展示了 DTE 模块的消融研究结果。我们使用简单的特征拼接后跟卷积块作为基线,称为朴素卷积块。结果显示,两种方法的性能均随时间序列长度的增加而提升。在纳入两帧时间信息时,我们提出的 DTE 模块相比朴素卷积方法展现出更强的性能提升(38.21 mAP 对比 38.13 mAP,44.52 ODS 对比 43.96 ODS),在占用预测任务中提升尤为显著(+1.31 IoU,+1.29 mIoU)。当时间序列长度增加到四帧时,尽管朴素卷积方法达到了最优的 mAP,我们的方法在空间感知指标(ODS、IoU 和 mIoU)上表现最佳。这表明 DTE 模块通过其可变形注意力机制,能够自适应地融合时间特征,实现更全面的时空表示,从而在处理遮挡和增强场景理解方面表现出色。值得注意的是,我们的方法在速度估计方面也展现出显著优势(0.6151 对比 0.6608 的 mAVE),进一步验证了 DTE 模块在时空和动态目标表示方面的有效性。
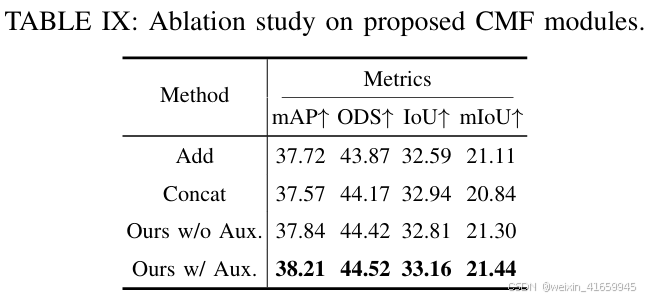
CMF的消融研究
表 IX 展示了跨模态 BEV-体素融合(CMF)模块的消融研究结果。我们比较了 CMF 与两种基本特征融合策略(add和Concat)。我们提出的 CMF 模块通过注意力加权机制自适应地融合来自 BEV 和体素空间的异构特征,即使在没有辅助任务的情况下(Ours w/o Aux.),也显示出明显的优势:与特征add相比,mIoU 提高了 0.19;与特征Concat相比,ODS 提高了 0.25。引入辅助任务(Ours w/ Aux.)——前景/背景 BEV 分割和占用/非占用二进制预测 BEV——使模型在各项性能指标上均有所提升(+0.37 mAP,+0.10 ODS,+0.35 IoU,+0.14 mIoU),超过了没有辅助任务的版本。这些实验结果不仅验证了我们自适应融合策略在整合多模态特征方面的有效性,还表明辅助任务可以通过额外的监督信号成功增强特征表示。
五、总结
在本文中,我们提出了 Doracamom,这是第一个结合多视图摄像头和 4D 雷达融合的统一多任务感知框架。具体来说,我们提出了一种粗体素查询生成器,用于初始化具有几何和语义感知能力的体素查询,以便有效利用多模态特征;一种双分支时间编码器,用于在考虑环境中的动态和静态元素的同时,自适应地融合 BEV 和体素空间中的时间特征;最后,我们提出了一个基于注意力的跨模态 BEV-体素融合模块,该模块通过整合辅助任务来解决特征模糊性问题,为下游任务生成高质量的特征表示。在 OmniHD-Scenes、VoD 和 TJ4DRadSet 三个数据集上的实验结果表明,我们的方法在 3D 目标检测和 3D 语义占用预测任务中均达到了最新技术的性能水平。
公众号:持续学习共同进步



















 656
656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









