







 本文分析了点云3D目标检测在自动驾驶中的重要性,着重比较了PointPillars、SE-SSD和CIA-SSD等模型的性能,指出CIA-SSD在精度和定位精度上有优势,推理时间适中,适合自动驾驶应用。
本文分析了点云3D目标检测在自动驾驶中的重要性,着重比较了PointPillars、SE-SSD和CIA-SSD等模型的性能,指出CIA-SSD在精度和定位精度上有优势,推理时间适中,适合自动驾驶应用。
1 调研目的及结论
点云3D目标检测检测为自动驾驶车辆提供精确的类别、方向及几何信息,为自动驾驶车辆更好的感知周围环境提供信息。基于激光雷达点云的3D目标检测主要基于视图、基于体素、基于Pillar、基于点和基于点-体素方法,目前使用目标检测算法PointPillars,由于推理速度快,移植方便,广泛应用于工业界,但PointPillars是通过生成伪图像的方式,损失一定的信息,检测精度不高,并且定位精度不够准确等。基于体素的方式,随着稀疏卷积提出与运用,在精度与速度上可以运用到自动驾驶领域。SE-SSD、CIA-SSD属于同一系列,在精度上相对于PointPillars提升十多个点,并且定位精度也较高,推理时间30-50ms左右,满足自动驾驶周期100ms,综合多种因素可将CIA-SSD可作为新模型测试开发。
2 3D目标检测方法
2.1 目标检测方法分类
自动驾驶系统对精度和速度的要求更高,检测器不仅需要快速识别周围环境的物体,还要对物体在三维空间中的位置做精准定位,因此3D目标检测的深度学习方法是目前自动驾驶领域研究的热点之一。3D目标检测的深度学习方法根据模型输入形式可以大体分为以下四类:
1)基于三维点云:此类主要以PointNet系列为代表,检测效果良好,但对显卡资源需求较高,推理时间较长。
2)基于体素:此类主要以VoxelNet系列为代表,通过体素网格化将无序点云编排为有序点云,通过3D卷积提取特征,转换后类似于图像深度学习方法,但要比图像多出一个维度,提取特征较为费时。随着Spconv(稀疏卷积)的提出,使得该系列可满足工业需求,例如SE-SSD、CIA-SSD推理时间在30-50ms,满足自动驾驶推理时效需求。
3)基于视图:基于视图是主要将三维点云生成前视图、俯视图等,然后通过图像深度学习方法的方式进行,该类方法运行时间快,但将三维度转成二维度,造成信息损失,检测效果稍低。
4)基于Pillar:此类代表为PointPillars,此类方法可看成基于体素的特例,即在X,Y轴方向进行网格划分,而不对Z轴方向进行划分,而形成柱状,这种方法推理速度较快,但由于Z轴没有精细的划分,在提取特征时有一定的损失,在目标定位精度这块也没有SE-SSD、CIA-SSD算法高。
2.2 现有点云深度学习模型对比
该对比主要针对KITTI排行榜上公开训练代码并排名较为靠前的模型,详见表1。
表1 3D目标检测精度与推理速度对比
| 模型 | 精度(MAP) | 推理时间(1core@2.5Ghz(C/C++)) |
| SFD | Easy:91.73% Moderate:84.76% Hard:77.92% | 100ms |
| SE-SSD | Easy:91.49% Moderate:82.54% Hard:77.15% | 30+ms |
| CIA-SSD | Easy:90.04% Moderate:79.91% Hard:78.8% | 40+ms |
| PointPillars | Easy:79.05% Moderate:74.09% Hard:68.3% | 30+ms |
1)SFD(Sparse Fuse Dense: Towards High Quality 3D Detection with Depth Completion)
SFD主要利于多传感器融合的方式进行检测,一个对于多模态feature增强的操作,其实就是将image投影到与lidar真实点云对齐的坐标后进行的点云的传统数据增强,只不过后面进行cpconv操作时是将伪点云投影回原来的image进行临近点搜寻,而后进行特征聚合。其点云提取特征的方式还是运用的体素的方法,网络结构见图1。
 图1 SFD网络结构
图1 SFD网络结构
2)CIA-SSD(Confident IoU-Aware Sigle Stage Object Detector From Point Cloud)
CIA-SSD以SECOND为Backbone提出了一种基于体素的一阶段目标检测模型,主要贡献有三个:(1)提出SSFA用来融合浅层的空间特征和深层的语义特征;(2) 对预测BBox和GTBBox之间的IoU进行预测,并用来矫正BBox的置信度,以减轻BBox定位精度和分类置信度不对齐的问题(也就是高置信度可能对应低IoU或者反过来);(3)提出了DI-NMS,在NMS的过程中,同时考虑了BEV视角上目标与视点的距离 和 高置信BBox周围的BBox(辅助BBox)信息。网络结构见图2。
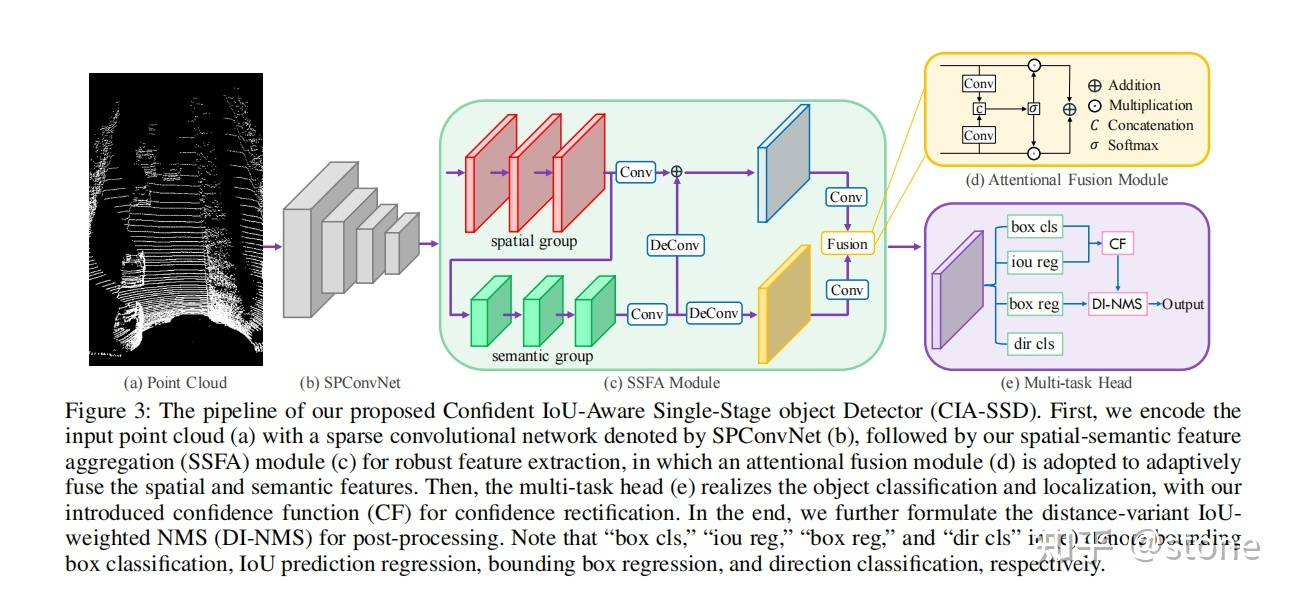 图2 CIA-SSD网络结构
图2 CIA-SSD网络结构
3)SE-SSD(Self-Ensembling single-stage Object Detector From Point Cloud)
SE-SSD提出了Self-Ensembling single-stage目标检测器,其关注点是利用soft(teacher模型预测的)和hard(标注信息)的目标以及制定的约束来共同优化模型,且不在推理中引入额外计算。具体地说,SE-SSD包含一对teacher和student的SSD,并设计了一个有效的IOU-based的匹配策略来过滤teacher的soft目标,并制定一致性损失来使student的预测与它们保持一致。此外,为了最大限度地运用teacher的蒸馏知识,设计了一种新的数据增强方案来产生形状感知的增强样本来训练student SSD,以推断完整的目标形状。最后,为了更好地利用hard目标,还设计了一个ODIoU损失来监督约束预测的box中心和方向的student,速度可达30.56ms。网络结构见图3。

图3 SE-SSD网络结构
4)PointPillars
PointPillars,采用Pillar编码方式编码PointCloud:在点云的俯视图的平面进行投影使之变成伪2D图,对这种投影进行编码用的是Pillar方法,即在投影幕上划分为 H * W 的网格,然后对于每个网格所对应的柱子中的每一个点取原特征(x,y,z,r,x_c,y_c,z_c,x_p,y_p)共9个,再然后每个柱子中点多于N的进行采样,少于N的进行填充0,形成了(9,N,H * W)的特征图。使用2D Convolution进行处理:这一部分算得上是网络中的backbone,backbone包含两个子网络一个是top-down网络,另一个是second网络。其中top-down网络结构为了捕获不同尺度下的特征信息,主要是由卷积层、归一化、非线性层构成的,second网络用于将不同尺度特征信息融合,主要由反卷积来实现。网络结构见图4。
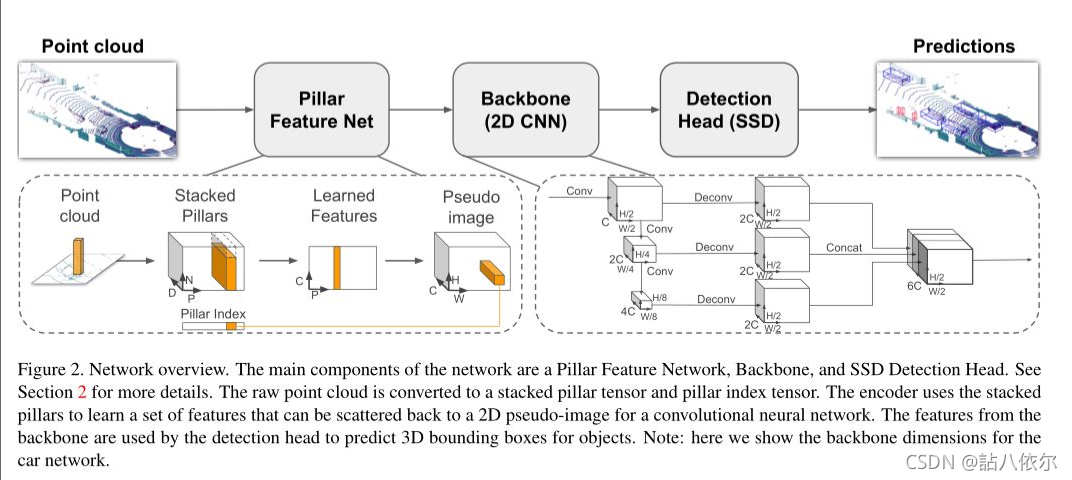
图4 PointPillars网络结构
3 可行性分析
SFD算法相较于SE-SSD、CIA-SSD精度提升并不多,而且其推理时间100ms,加上前后处理,难于满足自动驾驶车辆融合周期;SE-SSD、CIA-SSD属于同一系列,在精度上相对于PointPillars提升十多个点,并且定位精度也较高,推理时间30-50ms左右,满足自动驾驶周期100ms,并且对CIA-SSD有一定的了解和接触,此外CIA-SSD曾在3090显卡上部署成功,且满足推理要求。SE-SSD是在CIA-SSD基础上做的提升,整体网络基本接近,整体检测效果和推理时间也比较接近。综合检测精度、推理时间以及经验,CIA-SSD算法开发具有较高的可行性,可将CIA-SSD作为新的激光雷达点云目标检测模型。

















 6675
6675











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











