






基于 关系感知异构图Transformer 的 药物相互作用预测双通道学习框架
第三十八届人工智能大会 AAAI
机构 中国科学院大学
原文 https://ojs.aaai.org/index.php/AAAI/article/view/27777
摘要
识别新型药物-药物相互作用(DDI)
近年来,出现了多种基于网络的技术来预测DDI。然而,主要关注DDI相关网络内的局部结构,往往忽视了从全局角度看待药物节点之间间接连接的重要性。
此外,有效处理生物医学知识图和药物分子图中的异构信息仍是提高DDI预测性能的一个挑战。
为了解决,本文提出了一种基于Transformer的关系感知图表示学习框架(TIGER)。
1.使用Transformer架构有效地利用异构图的结构,使其能够直接学习长依赖和高阶结构。
2.结合了关系感知的自注意力机制,能够捕获异构图中节点对之间的多样化语义关系。
3.使用双通道网络模拟DDI预测任务,将药物分子图和生物医学知识图分别输入两个通道,从而提高了预测准确性。通过整合在图和节点级别获得的嵌入,TIGER能够受益于药物的结构特性以及生物医学知识图提供的丰富上下文信息。
1 介绍
与仅由药物实体组成的同构图相比,异构图在抽象和建模复杂系统方面更出色,从而产生了更大的兴趣。在DDI预测领域,常用的是两种异构图。
一种是生物医学知识图谱,其中每个节点代表一个分子,如药物或蛋白质,边是它们之间的关系。
另一种是药物分子图,其中每个节点代表一个原子,每条边代表一个键。
鉴于图神经网络(GNN) 的成功,有几种尝试采用GNNs对异构图进行学习。
在生物医学知识图谱的情况下,设计了一种特定关系的转换来编码实体之间的语义关系。随后,可以使用消息传递框架在整个图中传播和聚合信息,从而实现药物节点级表示的学习。
另一方面,一种常见的范式是为每个原子分配一个[ VNode ] (虚拟节点),或者使用池化函数来聚合单个原子的信息。这允许创建药物图级表示,以捕获药物分子的整体结构。
事实上,基于GNN的方法在DDI预测任务中表现出了令人印象深刻的性能,显著地推进了生物医学知识图谱和药物分子图谱的分析。但是,它们的确存在一定的局限性。
仅仅通过聚合来自本地邻居的信息来学习药物表征。因此,它们在有效捕获复杂的图结构和长程依赖关系方面可能会遇到挑战。这种局限性可能会妨碍他们充分理解生物医学知识图谱和药物分子图谱中固有的错综复杂的关系。此外,这些方法还存在过度压扁的问题。过度挤压会导致迭代消息传递过程中的信息丢失和失真,从而影响模型性能。
为了解决,Transformer架构,因为它能够直接对远程节点进行建模,并捕获整个图的依赖关系。一个例子是Graphormer ( Ying et al 2021),这是最近为分子图级表示学习量身定制的基于Transformer的模型。Graphormer增强了Transformer架构,可以有效地处理图结构数据。这是通过包含同时考虑节点和边特征的图位置编码和注意力机制来实现的。因此,该模型不仅评估了单个节点属性,而且掌握了全局拓扑信息。
虽然Graphormer在图级别的表示学习任务中是有效的,但其将整个图作为输入的特性限制了它的可扩展性和对大规模图的适用性。
另一方面,生物医学知识图谱具有丰富的语义信息,其中的节点对可能存在多种关系。例如,药物可能通过不同的机制与蛋白质相互作用,也可能根据环境的不同而表现出不同的副作用。然而,大多数现有的基于Transformer架构的方法缺乏区分一对节点之间多种关系重要性的能力。
为了解决上述问题,我们提出了一种新的基于Transformer的关系感知的图表示学习框架TIGER,用于在图和节点级别对DDI预测进行建模。
TIGER使用以药物节点为中心的采样子图来处理节点级的表示学习任务,而不是整个图。
TIGER还通过关系感知的自注意力机制实现其编码器,用于处理节点对之间的多种关系,而不是自注意力机制。
通过这两种设计,TIGER能够同时学习图级和节点级的表示。然后通过融合来自不同层次的表示来获得药物表示。
最后,TIGER利用得到的药物表示进行DDI预测。
3 方法
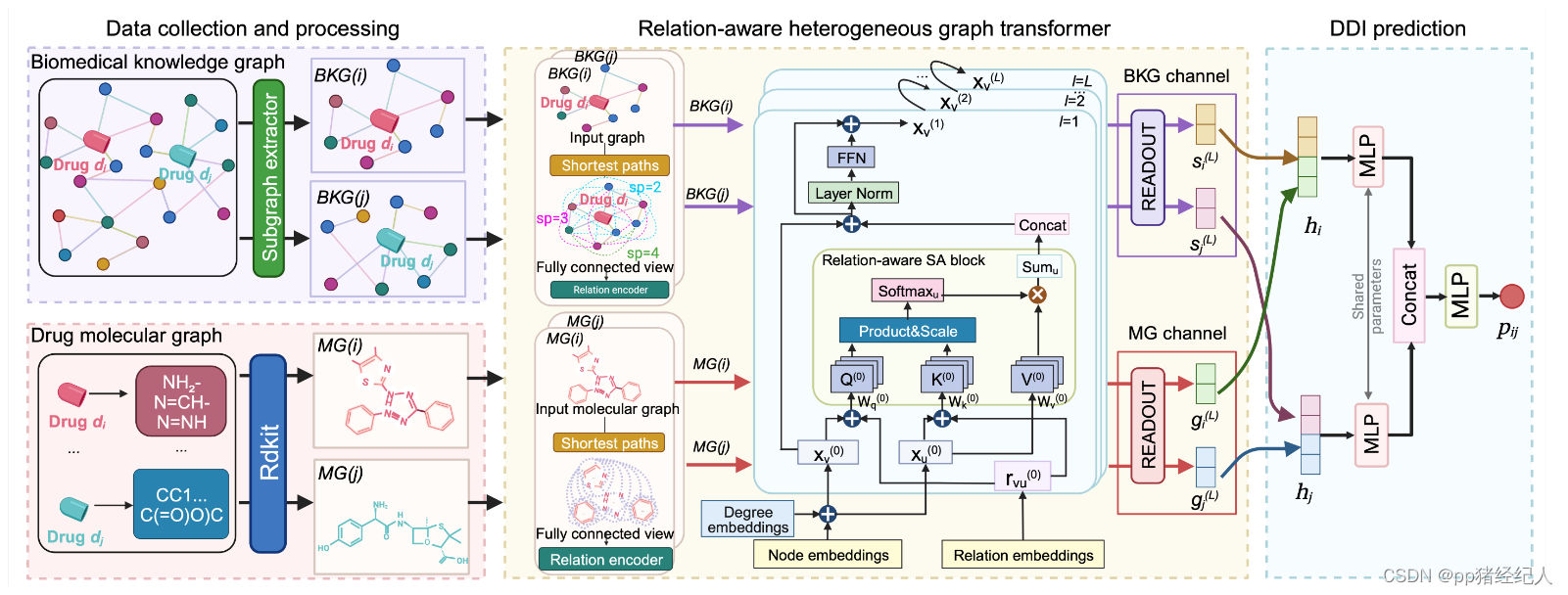
关系感知异构图Transformer
自注意力机制是Transformer体系结构的基本组件。然而,它本质上是位置感知的,忽略了节点对之间不同类型关系的本质。
此外,注意到两个问题:远程节点通常缺乏显式关系;一个节点对可以有多个关系。
为了解决这些问题,作者采用以下策略引入了关系感知自注意力的概念:
(1)为了合并远距离节点,根据它们最短路径的距离建立它们之间的关系;
(2)为了解决多重关系的存在,将每个关系视为一个独特的边。
首先,将节点的度嵌入与节点嵌入相加,将节点度指定的位置嵌入到每个节点特征中获得初始节点特征:
x
v
(
0
)
=
x
v
+
z
d
e
g
(
v
)
,
∀
v
∈
V
(3)
x_v^{(0)}=x_v+z_{deg(v)},\forall v\in V\tag 3
xv(0)=xv+zdeg(v),∀v∈V(3)其中
x
v
(
0
)
x_v^{(0)}
xv(0) 是关系感知自注意力块的输入,
z
(
⋅
)
z ( · )
z(⋅) 是由节点的度指定的嵌入层。
接着,计算 attention logits:
ψ
(
x
v
,
x
u
,
r
v
⇔
u
c
)
=
(
x
v
+
r
v
→
u
)
W
q
T
W
k
(
x
u
+
r
u
→
v
)
=
x
v
W
q
T
W
k
x
u
(
I
)
+
x
v
W
q
T
W
k
r
u
→
v
(
I
I
)
+
r
v
→
u
W
q
T
W
k
x
u
(
I
I
I
)
+
r
v
→
u
W
q
T
W
k
r
u
→
v
(
I
V
)
(1)
\begin{aligned} \psi(x_{v},x_{u},r_{v\Leftrightarrow u}^{c})& =(x_v+r_{v\to u})\boldsymbol{W}_q^T\boldsymbol{W}_k(x_u+r_{u\to v}) \\ &=x_v\boldsymbol{W}_q^T\boldsymbol{W}_kx_u(\mathrm{I})+x_v\boldsymbol{W}_q^T\boldsymbol{W}_kr_{u\to v}(\mathrm{II}) \\ &+r_{v\to u}\boldsymbol{W}_q^T\boldsymbol{W}_kx_u(\mathrm{III}) \\ &+r_{v\to u}\boldsymbol{W}_q^T\boldsymbol{W}_kr_{u\to v}(\mathrm{IV}) \end{aligned} \tag{1}
ψ(xv,xu,rv⇔uc)=(xv+rv→u)WqTWk(xu+ru→v)=xvWqTWkxu(I)+xvWqTWkru→v(II)+rv→uWqTWkxu(III)+rv→uWqTWkru→v(IV)(1)其中
r
v
⇔
u
c
r_{v\Leftrightarrow u}^{c}
rv⇔uc 表示当图
G
G
G 是无向图时,
r
v
→
u
=
r
u
→
v
r_{v\to u} = r_{u\to v}
rv→u=ru→v 之间的
c
c
c 类型关系。
C
≥
1
C≥1
C≥1 种关系
新定义的 ψ ( ⋅ , ⋅ , ⋅ ) ψ ( · , · , ·) ψ(⋅,⋅,⋅) 允许模型在关注不同位置( I )时,同时考虑源特定( II )和目标特定( III )关系。它还有助于模型通过普遍关系偏差( IV )捕获整个输入中存在的共同模式或依赖关系。
注意,对成对的距离较远的节点,函数
ψ
(
⋅
,
⋅
,
⋅
)
ψ ( · , · , ·)
ψ(⋅,⋅,⋅) 也能够捕捉它们的结构信息,因为它们之间的关系是根据它们最短路径的距离来初始化的。关系感知自注意力计算公式如下:
R
A
t
t
n
(
x
v
)
=
∑
u
∈
V
∑
c
∈
C
f
(
x
v
,
x
u
,
r
v
⇔
u
c
)
∑
w
∈
V
∑
c
∈
C
f
(
x
v
,
x
w
,
r
v
⇔
w
c
)
ϕ
(
x
u
)
(2)
\mathrm{RAttn}(x_v)=\sum_{u\in V}\frac{\sum_{c\in C}f(x_v,x_u,r_{v\Leftrightarrow u}^c)}{\sum_{w\in V}\sum_{c\in C}f(x_v,x_w,r_{v\Leftrightarrow w}^c)}\phi(x_u)\tag{2}
RAttn(xv)=u∈V∑∑w∈V∑c∈Cf(xv,xw,rv⇔wc)∑c∈Cf(xv,xu,rv⇔uc)ϕ(xu)(2)其中
f
(
⋅
,
⋅
,
⋅
)
=
exp
(
ψ
(
⋅
,
⋅
,
⋅
)
/
d
k
)
f(\cdot,\cdot,\cdot)=\exp(\psi(\cdot,\cdot,\cdot)/\sqrt{d_k})
f(⋅,⋅,⋅)=exp(ψ(⋅,⋅,⋅)/dk),
ϕ
(
x
u
)
=
W
v
x
u
\phi(x_u)=\boldsymbol{W}_vx_u
ϕ(xu)=Wvxu。
随后,将经过关系感知自注意力块的输出经过跳跃连接和两层前馈神经网络生成更新的表示:
X
(
l
)
^
=
X
(
l
−
1
)
+
R
A
t
t
n
(
X
(
l
−
1
)
)
(4)
\hat{\boldsymbol{X}^{(l)}}=\boldsymbol{X}^{(l-1)}+\mathrm{RAttn}(\boldsymbol{X}^{(l-1)})\tag{4}
X(l)^=X(l−1)+RAttn(X(l−1))(4)
X
(
l
)
=
F
F
N
(
X
(
l
)
^
)
:
=
R
e
L
U
(
X
(
l
)
^
W
1
(
l
)
)
W
2
(
l
)
(5)
\boldsymbol{X}^{(l)}=\mathrm{FFN}(\hat{\boldsymbol{X}^{(l)}}):=\mathrm{ReLU}(\hat{\boldsymbol{X}^{(l)}}\boldsymbol{W}_1^{(l)})\boldsymbol{W}_2^{(l)}\tag{5}
X(l)=FFN(X(l)^):=ReLU(X(l)^W1(l))W2(l)(5)接着,双通道表示学习
分子图通道 给定药物 d i d_i di 的分子图 M G ( i ) = ( A , B , T ) MG ( i ) = ( A,B,T) MG(i)=(A,B,T),其中 A A A 为原子集合, B B B 为键集合, T T T 为关系集合。药物图级表示 g i ∈ R d g_i∈\mathbb R^d gi∈Rd 是通过 READOUT ( ⋅ ) \text{READOUT} (·) READOUT(⋅) 函数在 X ( L ) \boldsymbol{X} ^{( L )} X(L)上的汇总: g i = READOUT ( { x a ( L ) } a = 1 ∣ A ∣ ) (6) g_i=\text{READOUT}(\{x_a^{(L)}\}_{a=1}^{|A|})\tag{6} gi=READOUT({xa(L)}a=1∣A∣)(6)READOUT函数可以是任意置换不变函数。这里平均。
生物医学知识图谱通道 首先提取BKG中每个药物 d i d_i di 的子图 B K G ( i ) BKG ( i ) BKG(i),将采样后的子图 B K G ( i ) BKG ( i ) BKG(i) 送入关系感知的图Transformer模块。药物节点水平表示 s i s_i si 定义为 s i = X ( L ) [ i d x ] s_i = X^{ ( L )} [ idx ] si=X(L)[idx],其中 i d x idx idx 表示药物 d i d_i di 在 B K G ( i ) BKG ( i ) BKG(i) 中的指数。
使用读出函数获得图级表示,级联BKG的表示与分子图的表示并通过多层感知器( MLP ),生成药物的双通道表示:
h
i
=
M
L
P
(
g
i
(
L
)
∣
∣
s
i
(
L
)
)
(7)
h_i=\mathrm{MLP}(g_i^{(L)}||s_i^{(L)})\tag{7}
hi=MLP(gi(L)∣∣si(L))(7)其中
g
i
(
L
)
g_i^{(L)}
gi(L) 和
s
i
(
L
)
s_i^{(L)}
si(L) 表示第
L
L
L 个关系感知的图Transfomer的输出。
DDI预测
将两个药物的表示拼接并输入MLP以预测链接预测分数:
p
i
j
=
M
L
P
(
h
i
∣
∣
h
j
)
(8)
p_{ij}=\mathrm{MLP}(h_i||h_j)\tag 8
pij=MLP(hi∣∣hj)(8)所有DDI对的交叉熵损失表示为:
L
l
a
b
e
l
=
−
∑
(
i
,
j
)
∈
Y
y
i
j
log
(
p
i
j
)
+
(
1
−
y
i
j
)
log
(
1
−
p
i
j
)
(9)
\mathcal{L}_{label}=-\sum_{(i,j)\in Y}y_{ij}\log(p_{ij})+(1-y_{ij})\log(1-p_{ij})\tag{9}
Llabel=−(i,j)∈Y∑yijlog(pij)+(1−yij)log(1−pij)(9)其中
Y
Y
Y 表示药对集合,
y
i
j
y_{ij}
yij 表示药对的真实值。
为了保证获得具有判别性的药物双通道表征,在药物双通道表征
h
i
h_i
hi 上采用Jensen - Shannon ( JS )互信息( MI )估计器。
分别在给定的药物分子图
g
i
g_i
gi 和抽取的药物子图
s
B
K
G
(
i
)
=
READOUT
(
{
x
v
(
L
)
}
v
=
1
∣
B
K
G
(
i
)
∣
)
s_{BKG ( i )} = \text{READOUT} ( \{ x ^{( L )}_ v \} ^{| BKG ( i ) |}_{ v = 1} )
sBKG(i)=READOUT({xv(L)}v=1∣BKG(i)∣) 上最大化估计MI。
通过引入判别器
D
:
R
d
×
R
d
→
R
\mathcal{D}:\mathbb{R}^d\times\mathbb{R}^d\to\mathbb{R}
D:Rd×Rd→R,
可以将
h
:
h_:
h:和
g
:
g_:
g: 之间的MI增强损失函数
L
M
I
h
g
\mathcal{L}_{MI}^{hg}
LMIhg 表示为二元交叉熵损失:
L
M
I
h
g
=
1
n
+
n
n
e
g
(
∑
i
∈
D
n
log
(
D
(
h
i
,
g
i
)
+
∑
k
∈
D
n
n
e
g
log
(
D
(
h
i
,
g
k
~
)
)
)
)
(10)
\mathcal{L}_{MI}^{hg}=\frac{1}{n+n_{neg}}(\sum_{i\in D}^{n}\log(\mathcal{D}(h_{i},g_{i})+\sum_{k\in D}^{n_{neg}}\log(\mathcal{D}(h_{i},\tilde{g_{k}}))))\tag{10}
LMIhg=n+nneg1(i∈D∑nlog(D(hi,gi)+k∈D∑nneglog(D(hi,gk~))))(10)其中
n
n
e
g
n_{neg}
nneg 表示负样本的个数,负样本
g
k
~
\tilde{g_k}
gk~ 是通过批处理方式生成的虚假样本,目的是帮助训练判别器区分真实的和虚假的表示对。
L
M
I
h
s
\mathcal{L}_{MI}^{hs}
LMIhs 的计算公式与
L
M
I
h
g
\mathcal{L}_{MI}^{hg}
LMIhg 相同。
利用监督分类损失
L
l
a
b
e
l
\mathcal{L}_{label}
Llabel 和自监督互信息损失
L
M
I
\mathcal{L}_{MI}
LMI,训练目标函数为跟随者的TIGER:
TIGER模型的最终目标函数为:
L
=
L
l
a
b
e
l
+
β
1
L
M
I
h
g
+
β
2
L
M
I
h
s
(11)
\mathcal{L}=\mathcal{L}_{label}+\beta_1\mathcal{L}_{MI}^{hg}+\beta_2\mathcal{L}_{MI}^{hs}\tag{11}
L=Llabel+β1LMIhg+β2LMIhs(11)其中
β
1
β_1
β1 和
β
2
β_2
β2 是权衡不同损失分量的超参数。
实验
对比实验 选取了三种类型的基线,分别是
基于分子图的方法:SSI-DDI、Molormer;
基于生物医学知识图谱的方法:KGNN、KG2ECapsule;
基于多层次的方法:Bi-GNN、MIRACLE和MDDNN。
同时,作者比较了三种提取子图的性能。结果显示:
(i)基于概率的提取器(PageRank)在处理低密度数据集时效果较好;
(ii)基于DeepWalk的提取器在处理密集数据集时表现更好;
(iii)基于k-子树的提取器在不同类型的网络中提取子图时有较好的鲁棒性,但可能会导致一定程度的精度损失。
消融实验 进一步研究了知识图谱和分子图是否对模型预测提供了互补信息,结果显示BKG对DDI预测任务的贡献更大,同时使用BKG和分子图能够使模型得到最佳性能。
结论
本文提出了一种新型的双通道关系感知图转换模型TIGER,旨在预测药物-药物相互作用(DDI)。TIGER利用药物分子图和生物医学知识图的联合表示学习来预测DDI。
它能够有效捕获长依赖和高阶结构,这对于准确的DDI预测至关重要。
此外,TIGER在处理图内的多种关系方面表现出色。
通过为DDI预测提供有价值的见解,TIGER增强了对药物相互作用背后复杂生物系统的理解。















 2071
2071

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









