










 NeurIPS2023年会议公布,收录3200余篇论文,涵盖深度学习、计算机视觉等多个领域。亮点包括高效语音翻译模型DASpeech、基于凸函数的文本生成、白盒Transformer的稀疏化方法等。论文展示了创新技术在AI领域的应用和进展。
NeurIPS2023年会议公布,收录3200余篇论文,涵盖深度学习、计算机视觉等多个领域。亮点包括高效语音翻译模型DASpeech、基于凸函数的文本生成、白盒Transformer的稀疏化方法等。论文展示了创新技术在AI领域的应用和进展。
上周机器学习顶会NeurIPS 2023的接收论文列表公布了,有同学的论文中了嘛,可以评论区分享分享。
这次NeurIPS 2023共录用论文3221篇左右,录用率26.1%,与2022年的25.6%相比还是有所增加的。有想法的同学冲冲冲。
NeurIPS属于CCF A类,是与ICML并称为人工智能领域难度最大,水平最高,影响力最强的会议,每年的大会上讨论的内容包含深度学习、计算机视觉、大规模机器学习、学习理论等众多细分领域。今年的会议将在12 月 10 日-16 日的路易斯安那州新奥尔良市举行。
今天我就和大家分享几篇已被录用的优秀论文,篇幅原因这里只做简单介绍,论文原文以及代码合集可以看文末,NeurIPS历年的录用论文清单我也整理在内了,大家收藏了记得学习。
1、DASpeech: Directed Acyclic Transformer for Fast and High-quality Speech-to-Speech Translation
标题:DASpeech:用于快速高质量语音到语音翻译的有向无环Transformer
简单概括:DASpeech是一种快速高质量的非自动回归直接语音到语音翻译模型。它采用两阶段架构,先用语言解码器生成目标文本,然后由音频解码器基于语言解码器的隐状态生成目标语音。在测试集上,DASpeech实现了与SOTA模型相当或更好的翻译质量,同时保留了高达18.53倍的加速比。相比之前的非自动回归S2ST模型,DASpeech无需知识蒸馏和迭代解码。此外,DASpeech还展示了保留源语音说话人声音特性的能力。
2、Beyond MLE: Convex Loss for Text Generation
标题:超越MLE:文本生成的凸损失函数
简单概括:作者提出使用基于凸函数的新颖训练目标,以代替文本生成任务中的最大似然 estimation (MLE)。相比 MLE 需要估计整个数据分布,凸函数使模型可以关注高概率输出。作者证明凸函数可以使最优分布更尖锐,关注高概率区域。在多个文本生成任务上实验证明,相比 MLE,凸函数训练目标可以使自动回归模型贪心解码接近束搜索,并显著提升非自动回归模型的性能。
3、White-Box Transformers via Sparse Rate Reduction
标题:通过稀疏速率降低实现白盒Transformer
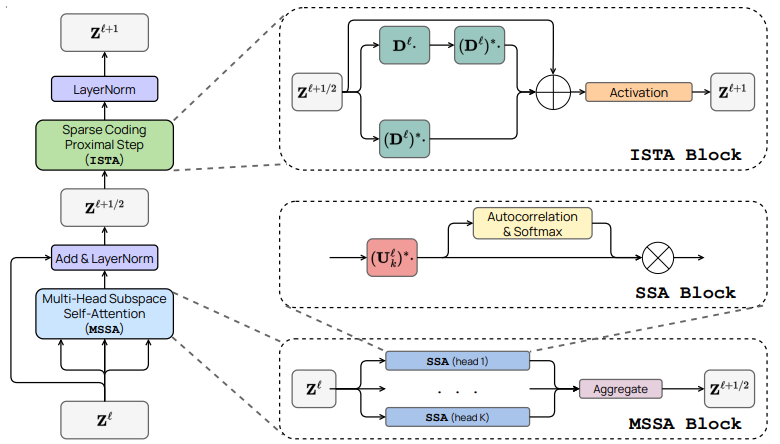
简单概括:论文提出表示学习的目标是使数据分布变换为低维高斯分布的混合,支持在不相干子空间上。基于这个观点,可以将transformer等深度网络自然地看作是渐进优化该目标的迭代方案。具体而言,标准的transformer模块可以看作是交替优化目标的两个互补部分:多头自注意力实现压缩,多层感知机实现稀疏化。这导致了一个数学上可解释的白盒transformer网络家族。实验表明,这种简单的网络可以有效地优化表示的压缩和稀疏化,并接近完整设计的transformer的性能。
4、Scan and Snap: Understanding Training Dynamicsand Token Composition in 1-layer Transformer
标题:扫描与拍照:理解1层Transformer的训练动态和标记组成
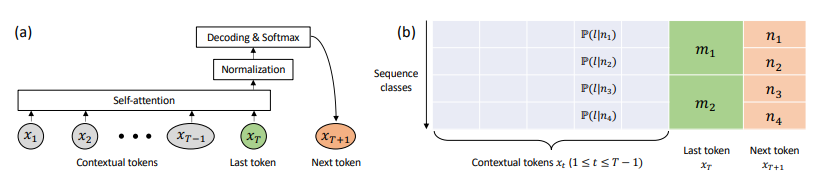
简单概括:本文分析了1层Transformer在next token预测任务上的训练动态,假设长输入序列及解码层学习快,证明自注意力层实现了一种逐步关注关键标记的“扫描”过程。它先均匀关注所有标记,然后逐渐聚焦对特定标记更独特的键,减少对常见键的注意力。学习率控制了这个过程的终止,"扫描"最终锁定了固定的标记组合。在数据上验证了这种“扫描与锁定”的训练动态。
5、Landscape Surrogate: Learning Decision Losses forMathematical Optimization Under Partial Information
标题:环境代理:在部分信息下学习数学优化的决策损失
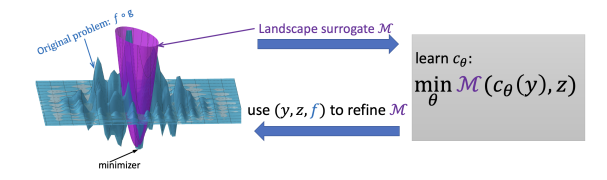
简单概括:该论文提出使用一个平滑可学习的环境代理来替代难以直接优化的部分可观测目标函数。环境代理以神经网络表示,可以快速计算,并提供平滑稠密的梯度。它通过交替优化进行学习,既可以处理合成问题,也可以推广到真实世界优化问题。相比直接调用优化器,环境代理减少了优化循环次数,降低了计算成本。实验表明,该方法达到了先进基准的水平,特别在高维问题上性能更佳。
6、H_O: Heavy-Hitter Oracle for Effcient Generative Inference ofLarge Language Models
标题:H_O:大型语言模型生成推理的高效重击者Oracle
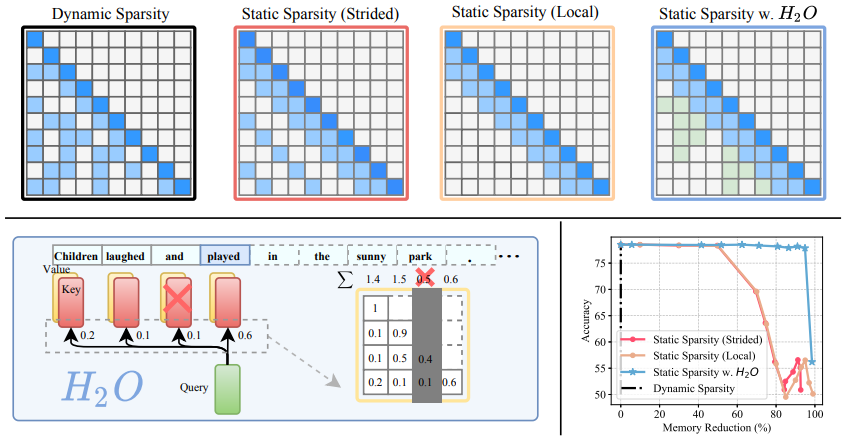
简单概括:论文提出了一种新的KV缓存实现方式,可以显著减小其内存占用。作者的方法基于一个显著的观察结果:少量词元对计算注意力得分贡献最大。论文将这些词元称为“重击者”(H2)。通过全面的研究,作者发现:(1) H2的出现很自然,与文本中词元的高频共现强相关;(2)删除H2会导致显著的性能下降。基于这些见解,作者提出了重击者Oracle(H2O),这是一种KV缓存释放策略,动态保留最近的和H2词元的平衡。作者将KV释放形式化为一个动态子模问题,并证明了该新释放算法的理论保证(在温和假设下),这可能有助于指导未来的工作。
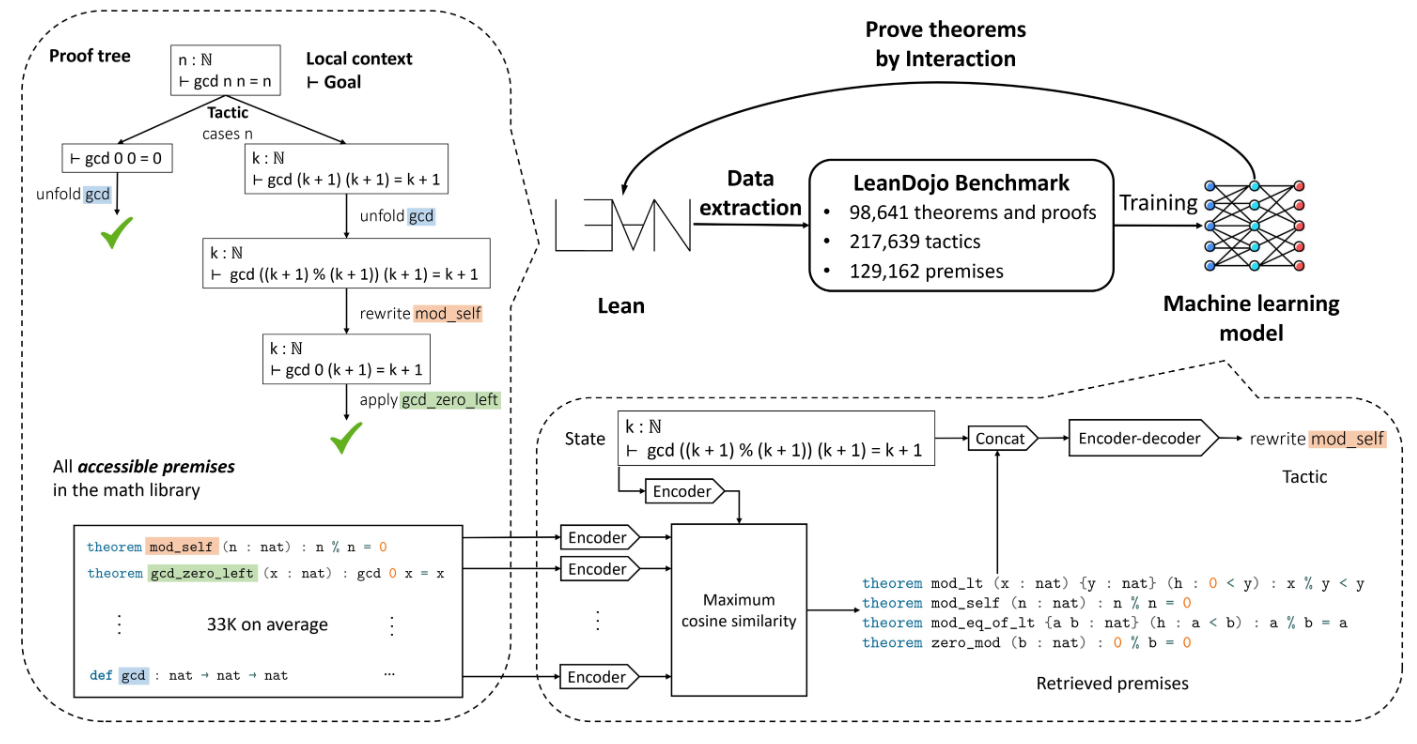
7、LeanDojo: Theorem Proving withRetrieval-Augmented Language Models
标题:利用检索增强的语言模型进行定理证明
简单概括:这篇论文提出了一个开源的Lean环境LeanDojo,它包含了工具、数据、模型和基准,以消除语言模型进行定理自动证明研究的障碍。基于该环境的数据,作者提出了ReProver模型,它是检索增强的语言模型证明器,可以从大规模数学库选择相关前提。作者还构建了一个新的基准测试用于评估。实验结果显示,ReProver优于非检索基线和GPT-4。
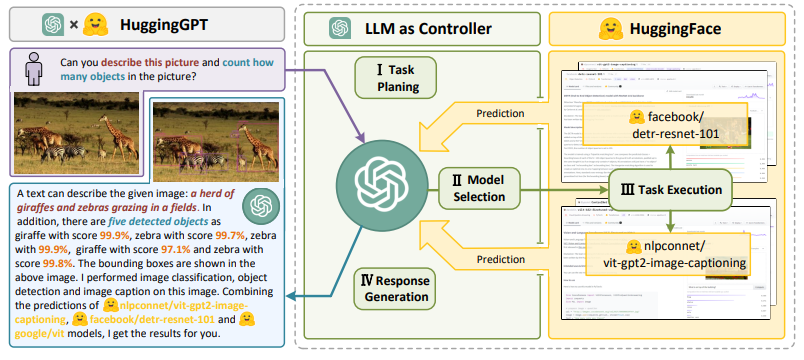
8、HuggingGPT: Solving AI Tasks with ChatGPT andits Friends in HuggingFace
标题:利用HuggingFace中的ChatGPT及其伙伴解决AI任务
简单概括:论文提出了 HuggingGPT 框架,利用大语言模型(如 ChatGPT)来连接机器学习社区中的各种 AI 模型(如 Hugging Face),以解决复杂的 AI 任务。具体来说,在接收到用户请求时,使用 ChatGPT 进行任务规划,根据 Hugging Face 中的模型功能描述选择模型,使用所选模型执行每个子任务,并根据执行结果总结响应。HuggingGPT 利用了 ChatGPT 强大的语言能力和 Hugging Face 中丰富的 AI 模型,能够覆盖不同模态和领域的许多复杂 AI 任务,并在语言、视觉、语音等具有挑战性的任务上取得令人印象深刻的结果。这为通用人工智能铺平了新的道路。
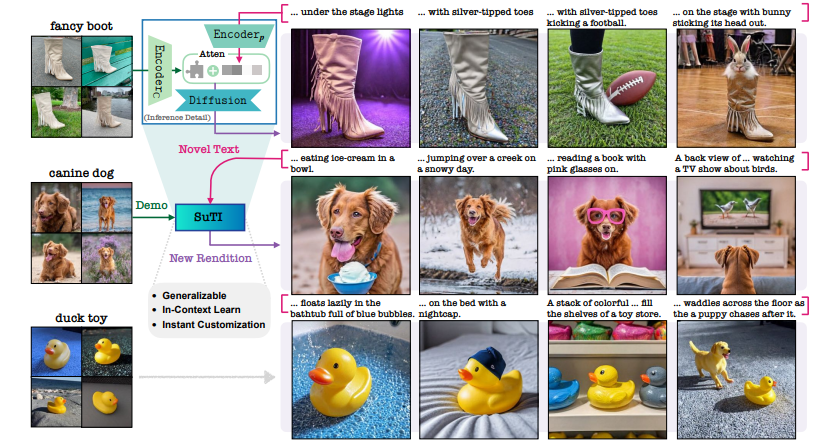
9、Subject-driven Text-to-Image Generation viaApprenticeship Learning
标题:基于学习方法的主体驱动式文本到图像生成
简单概括:这篇论文提出了 SuTI 文本到图像生成模型,它通过预训练一个学徒模型来模仿大量基于不同主题微调的专家模型,可以不需要针对每个主题进行调优就可以根据几个示例即时生成高质量、个性化的图像。在人类评估中,SuTI 在生成符合主题和文本的图像方面明显优于当前其他方法。
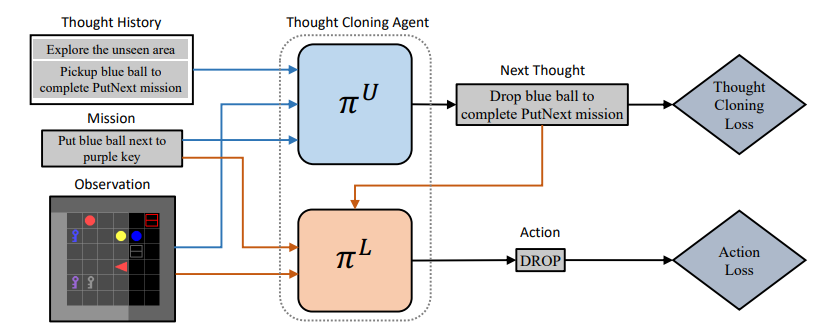
10、Thought Cloning: Learning to Think while Acting by Imitating Human Thinking
标题:思维克隆:通过模仿人类思维行动学习思维
简单概括:这篇论文提出思维克隆(Thought Cloning)框架,基于语言是人类思维的关键方面这一假设,通过让AI模型模仿人类思维过程中的语言来提高其推理和规划能力。作者使用合成生成的思维和行动数据进行实验。结果显示,相比仅模仿行为的方法,思维克隆可以更快地学习,在分布偏移的测试任务上的优势更大,体现了它处理新情况的更强能力。思维克隆还为AI安全性和解释性提供了重要好处,更容易调试和改进AI,因为可以观察到模型的思维,可以更容易诊断问题、修正思维、防止不安全的计划。
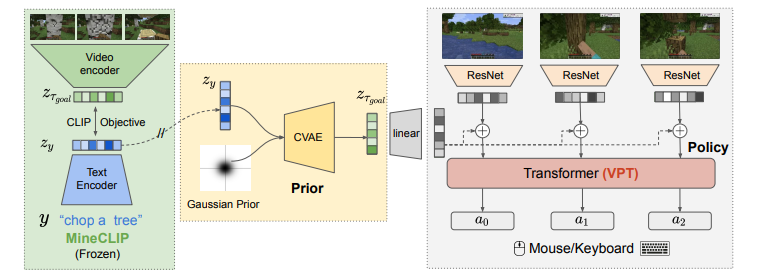
11、STEVE-1: A Generative Model for Text-to-Behavior in Minecraft
标题:STEVE-1:一个Minecraft中文本到行为的生成模型
简单概括:作者提出了STEVE-1,这是一个可以响应文本指令的视频预训练Minecraft模型。STEVE-1使用了unCLIP方法,先适配预训练的视频模型以遵循MineCLIP潜在空间中的命令,然后训练先验以从文本中预测潜在代码。这允许通过自监督的行为克隆和回溯重新标记来微调视频模型,而无需昂贵的人工文本注释。STEVE-1利用了预训练模型和文本条件图像生成的最佳实践,训练成本只有60美元,可以遵循广泛的短期开放式文本和视觉指令。
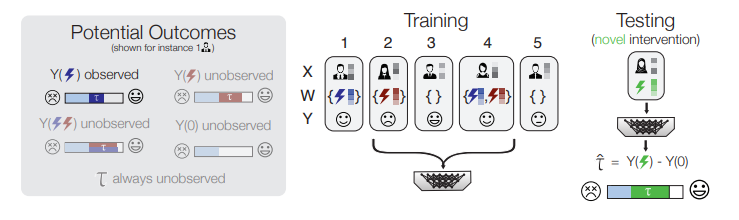
12、Zero-shot causal learning
标题:零样本因果学习
简单概括:论文提出了因果元学习框架CaML,将每个干预措施的个性化效果预测形式化为一个任务。CaML在成千上万个采样得到的任务上训练一个元模型。通过利用干预信息(如药物属性)和个体特征(如病史),CaML可以预测在训练时不存在的新干预的个性化效果。在大规模医疗保险索赔数据和细胞系扰动数据上的实验显示了该方法的有效性。
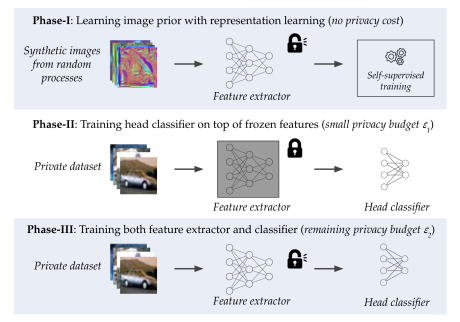
13、Differentially Private Image Classification by Learning Priors from Random Processes
标题:差分隐私图像分类通过从随机过程中学习先验
简单概括:这篇论文探索了如何通过从随机过程生成的图像中学习先验知识,来改进差分隐私随机梯度下降(DP-SGD)的隐私-效用权衡。作者提出了DPRandP,一个三阶段方法:第一阶段,从随机过程中采样图像,训练特征提取器来学习对视觉任务有益的图像先验。第二阶段,在私有数据的提取特征上花费少量隐私预算训练线性分类器。第三阶段,用剩余隐私预算更新所有参数。在CIFAR10、CIFAR100和MedMNIST数据集上,该方法达到新的状态。特别是在ε=1的隐私预算下,CIFAR10的准确率从之前最好的60.6%提高到72.3%。因此,学习随机过程的图像先验可以显着改进差分隐私训练。
14、Unified Segment-to-Segment Framework for Simultaneous Sequence Generation
标题:统一的段对段框架用于同步序列生成
简单概括:这篇文章提出一个统一的段到段框架,用于同时生成目标序列和接收源序列。关键是学习源序列和目标序列段之间的映射,以识别生成的最佳时机。该方法引入潜在段作为源和目标之间的枢纽,通过预期训练探索所有潜在的源-目标映射。在多个同步生成任务上,该方法实现了最先进的性能并展现出很好的通用性。
15、Leave No Stone Unturned: Mine Extra Knowledge for Imbalanced Facial Expression Recognition
标题:为不平衡的面部表情识别挖掘额外知识
简单概括:本文提出了一种新的面部表情识别方法,以解决样本不平衡问题。关键是从全部训练样本中提取少数类的额外信息,通过重新平衡的注意力图和标签来正则化模型,使其更关注少数类。该方法实现了状态最先进的性能。
16、Learning-to-Rank Meets Language: Boosting Language-Driven Ordering Alignment for Ordinal Classification
标题:提升语言驱动的顺序对齐进行序回归
简单概括:本文提出语言驱动顺序对齐方法改进序回归,该方法通过提示调优和跨模态序对损失,利用语言先验知识增强模型的排序表示能力,显著提高了序回归性能。
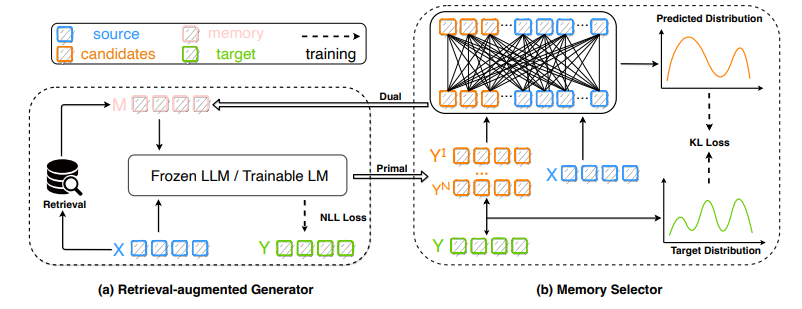
17、Lift Yourself Up: Retrieval-augmented Text Generation with Self Memory
标题:利用自我记忆增强的文本生成
简单概括:本文提出了一种利用自我记忆增强的文本生成框架Selfmem。与传统根据输入查询相似记忆不同,Selfmem通过生成器和选择器的迭代过程创建无限的自我记忆池。每轮生成器产生输出作为下一轮的记忆,选择器选择相关记忆输入到生成器。这样可以利用模型自己的输出作为记忆来改进生成。作者在机器翻译、文本摘要和对话三个任务上验证了该框架,取得了最优结果,证明了自我记忆增强检索式生成模型的效果。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“NeurIPS录用”获取论文+代码+录音清单合集
码字不易,欢迎大家点赞评论收藏!

















 3040
3040

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









