







 NeurIPS2023大会聚焦大语言模型(LLM),揭示了QLoRA、Direct Preference Optimization、DoReMi等12篇优质论文,涉及高效微调、强化学习、多模态生成、3D整合、隐私保护等领域,展现了LLM的最新发展趋势和研究成果。
NeurIPS2023大会聚焦大语言模型(LLM),揭示了QLoRA、Direct Preference Optimization、DoReMi等12篇优质论文,涉及高效微调、强化学习、多模态生成、3D整合、隐私保护等领域,展现了LLM的最新发展趋势和研究成果。
2023最后一场AI行业大会NeurIPS已经结束了,这场盛会共接收了全球各地的3586篇优质论文,这些论文如今已全部在线上公开发表,展现出人工智能领域的最新研究成果。
大型语言模型(LLM)作为人工智能领域的重要分支,在NeurIPS 2023大会上,关于LLM的论文也有很多。今天特意从这些论文中整理出12篇大语言模型(LLM)优质论文分享给大家,看看LLM领域的最新研究成果和发展趋势!
1、QLoRA: Efficient Finetuning of Quantized LLMs
QLoRA:量化 LLM 的高效微调
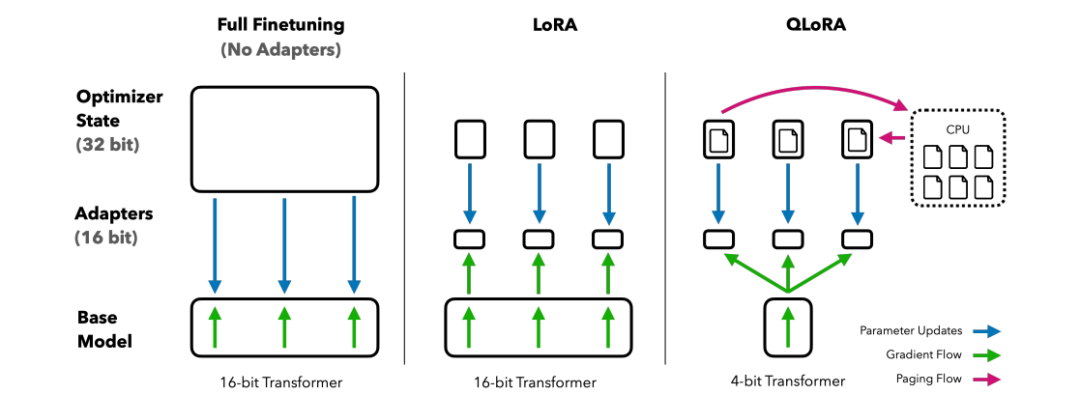
简述:本文提出了一种用于LLMs的微调方法QLORA,可在单个48GB GPU上微调65B参数模型,同时保持高性能。QLORA的创新包括4位NormalFloat、双量化、分页优化器。研究人员微调了1000多个模型,结果表明,使用小型数据集的QLORA微调可获得最佳结果,即使使用较小的模型。
2、Direct Preference Optimization: Your Language Model is Secretly a Reward Model
直接偏好优化:你的语言模型暗地里是一个奖励模型
简述:本文中提出了一种新的奖励模型参数化方法,简化了强化学习从人类反馈(RLHF)问题的标准解决方案,把这种算法称为直接偏好优化(DPO),它稳定、高效,计算需求低,简化了微调过程。与现有方法相比,DPO在满足人类偏好方面同样出色或更优,特别是DPO在控制文本情感方面表现优异,并且在文本摘要和对话生成中提供了质量相当或更高的响应,同时更易于实现和训练。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 439
439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









