









最近大热的KAN终于搭上CNN了,有新的研究将卷积的经典线性变换更改为每个像素中可学习的非线性激活函数,提出了开源KAN卷积CKAN。
这是一种将KAN的优势整合到CNN架构中的创新尝试。众所周知,KAN有着训练速度慢的局限,通过引入卷积神经网络,我们可以利用CNN高效的空间处理能力来优化KAN的结构,从而提升训练速度。
这方面还有一个效果更优的成果KonvNeXt,遥感图像分类领域的,通过将KAN层与多个预训练的CNN模型结合,实现了98.1%的准确率,以及16倍提速。
可见这种结合策略具备高效率和高准确性的优势,是我们构建更高质量深度学习模型的更优选择,已经有不少新研究可以证明,我从中挑选了8个KAN+CNN的新成果分享给大家,建议想发论文的同学抓好这一轮热点。
论文原文+开源代码需要的同学看文末
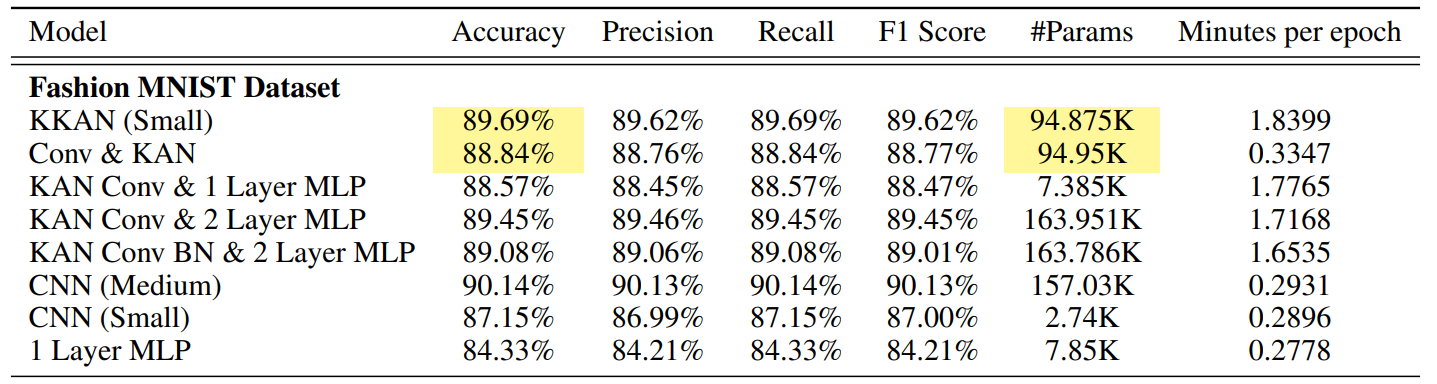
Convolutional Kolmogorov-Arnold Networks
方法:论文提出了一种新型的神经网络架构CKAN,它将KAN中的非线性激活函数集成到卷积操作中,构建了一种新的层,旨在提高模型的表达能力,同时减少参数数量和提高优化效率。

创新点:
-
利用Kolmogorov-Arnold定理在神经网络中的应用是理论上的一大突破,可以增强神经模型的表达能力和效率。Kolmogorov-Arnold定理提供了一种将多元连续函数表示为单变量函数和加法组合的方法,这在Kolmogorov-Arnold网络的设计中得到了应用。
-
将KANs适应于卷积层是另一个重要的创新。传统的卷积神经网络在计算机视觉中广泛使用,但它们使用固定的激活函数和线性变换,而KANs通过使用基于样条的卷积层,可以更有效地捕捉非线性关系。
Combining KAN with CNN: KonvNeXt's Performance in Remote Sensing and Patent Insights
方法:论文介绍了将KAN模型应用于遥感数据集,通过与ConvNeXt算法结合来提高效率和性能。KonvNeXt模型在遥感图像分类任务中表现出色,特别是在Merced数据集上达到了98.1%的准确率,并在处理Optimal-31和Merced数据集时展现出了107.63秒的快速处理速度,这比之前使用ViT模型训练相同数据集平均需要30分钟的时间要快得多。
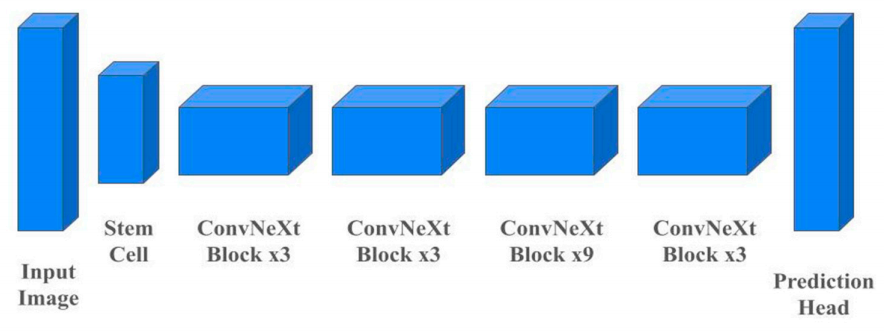
创新点;
-
本文首次将KAN应用于遥感数据集,通过将其与ConvNeXt算法集成,为遥感分类任务提供了一种新的有效方法。
-
通过使用遮挡敏感性方法,该模型还展示了其在解释性方面的潜力,证实了其在医学影像和天气预测等领域的应用可能性。

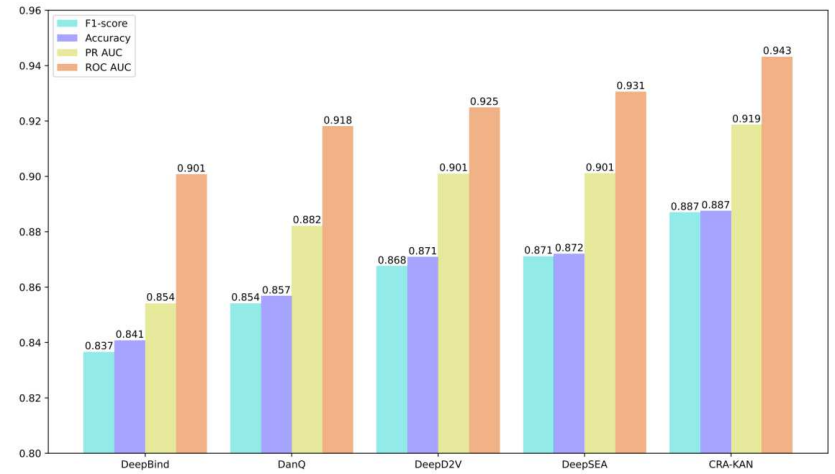
A KAN-based hybrid deep neural networks for accurate identication of transcription factor binding sites
方法:论文提出了一个名为CRA-KAN的模型,其中C代表卷积神经网络,R代表循环神经网络,A代表注意力机制。这个混合深度神经网络结合了KAN网络以替代传统的多层感知器,并且结合了CNN和双向长短期记忆网络,同时使用了注意力机制来专注于DNA序列中具有转录因子结合基序的区域。
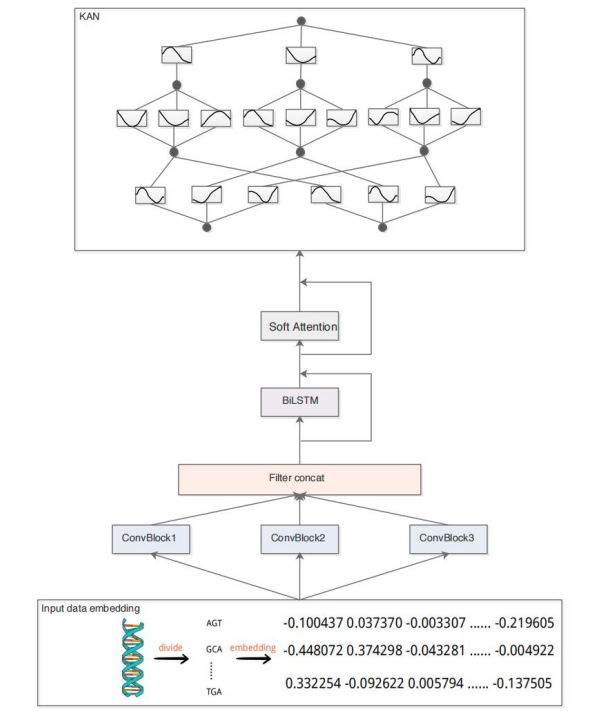
创新点:
-
CRA-KAN模型采用KAN网络取代传统的多层感知机,将卷积神经网络与双向长短期记忆网络结合起来,并利用注意力机制关注具有转录因子结合基序的DNA序列区域。引入残差连接以便于通过学习网络层之间的残差进行优化。
-
转移学习和Transformer模型的应用:转移学习在任务相似性较低的情况下也比随机初始化参数获得更好的结果。此外,Transformer模型在自然语言处理和图像处理方面取得了显著成功,有望提高转录因子结合位点的预测准确性。
Kolmogorov-Arnold Network for Satellite Image Classification in Remote Sensing
方法:本研究提出了一种将KAN与各种预训练的卷积神经网络模型结合起来用于遥感场景分类任务的方法KCN。作者使用了多个基于CNN的模型,包括VGG16,MobileNetV2,EfficientNet,ConvNeXt,ResNet101和ViT,并评估了它们与KAN配对时的性能。
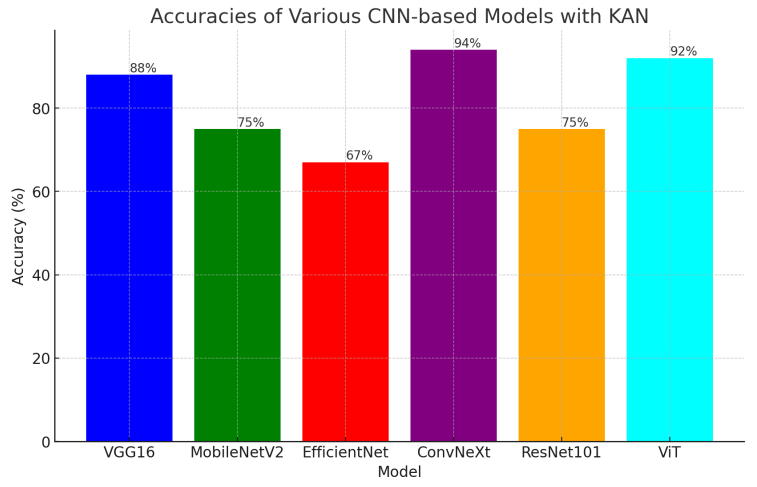
创新点:
-
本研究提出了将Kolmogorov-Arnold网络与各种预训练的卷积神经网络模型相结合,用于遥感场景分类任务的方法。
-
通过使用多个预训练的CNN和ViT模型,并进行比较,我们确定了与KAN最适配的模型组合。
-
结果表明,KAN可以替代传统的多层感知器,在遥感场景分类任务中获得令人满意的准确性。

关注下方《学姐带你玩AI》🚀🚀🚀
回复“KAN卷积”获取全部论文+开源代码
码字不易,欢迎大家点赞评论收藏

















 1102
1102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









