









Transformer爆火之后,时间序列领域基本上算是被占领了,围绕此类相关的研究也是非常之卷。这种情况下,我们不妨了解一下时序卷积。
在大规模时间序列数据处理任务中,时序卷积是一种非常重要的方法,它结合了传统CNN的特点和适应序列数据的能力,在并行处理能力、感受野配置、梯度传播稳定性、内存占用以及特征提取能力等方面都遥遥领先。
这些优势让时序卷积在Transformer卷上天的如今依旧坚挺,不过它确实还存在着许多问题等我们解决,而这部分也是我们重点关注的,可以挖掘创新点的地方。
目前研究者们专注于在时序卷积与其他技术相结合这方面做创新,且已经有了不少效果很好的成果。我从中总结了10种时序卷积最新的创新方案,有论文需求的同学可以拿来作参考,已开源的代码都贴上了,需要的同学可无偿获取。
全部方案+开源代码需要的同学看文末
+Attention
这种方法可以有效处理时间序列数据中的复杂模式和依赖关系,核心在于利用因果卷积保持时间序列的因果关系,通过膨胀卷积扩大感受野,残差连接缓解梯度消失问题,同时注意力机制帮助模型动态关注重要信息,从而提高预测准确性和效率。
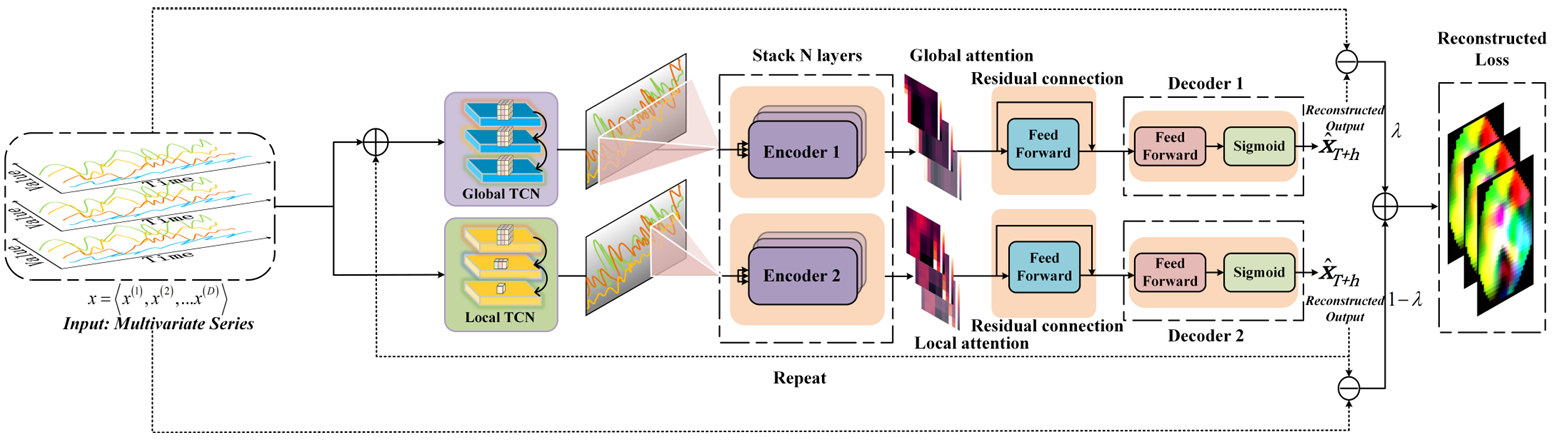
比如异常检测模型DTAAD,具体创新思路是:
结合了双时间卷积网络(Dual TCN)和注意力机制,通过整合局部TCN和全局TCN来分别模拟全局和局部时间模式,然后将这些时间序列数据送入单独的编码器中以研究不同序列之间的依赖关系。模型进一步利用Transformer的编码层来捕获多变量时间序列之间的动态关联,并通过引入反馈机制和损失比例来提高检测精度和扩大异常差异,最终实现了一个在多个基准数据集上性能优异的异常检测框架,特别是DTAAD将F1分数提高了8.38%,并将训练时间减少了99%。
+PINN
将深度学习的数据处理能力与物理规律的先验知识相结合,可以提高模型对时间序列数据的预测准确性和泛化能力。这种方法核心在于:首先通过因果卷积保持时间序列的因果关系,膨胀卷积扩大感受野,残差连接缓解梯度消失问题。同时,PINNs利用物理定律作为约束条件,引导神经网络学习符合物理规律的解,从而提高模型对未知数据的泛化能力。
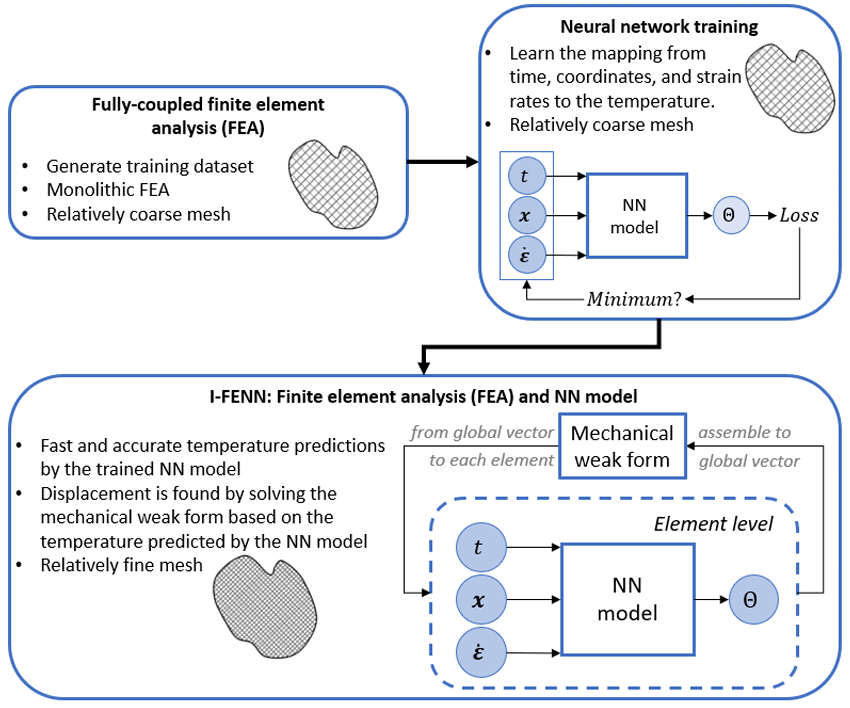
比如I-FENN框架,具体创新思路是:
使用PI-TCN模型来预测温度场,然后将这个模型的输出用于有限元分析中,以此来计算与温度相关的力学响应。I-FENN允许在保持传统FEM鲁棒性的同时,显著减少计算成本,并且能够处理更细的网格和/或更高阶的元素,为多物理场问题的高效数值求解提供了新的途径。
+Transformer
单独卷Transformer不如考虑考虑结合玩法,这种方法的优势和核心在于,通过因果卷积和膨胀卷积的组合,有效捕获数据中的长期依赖关系,并利用自注意力机制建模序列中不同位置之间的依赖关系,捕捉全局上下文信息,以实现高精度预测。
比如一种基于TCN和Transformer的多模态融合模型,具体创新思路是:
视觉和音频特征首先被送入各自的TCN模块进行时序编码,然后这些特征被拼接并送入Transformer编码器进行学习,最后使用多层感知机(MLP)进行预测。这种方法将视觉和音频特征统一到一个时序模型中,设计了一个高效的基于Transformer的情绪识别网络,从而提高了Valence-Arousal估计、动作单元检测和表情分类的评估准确性。

+LSTM
这种结合既能提高处理长序列数据的效率,又能增强对复杂时间序列模式的建模能力,核心在于利用TCN的因果卷积、扩张卷积和无偏移填充等技术来捕捉数据的局部特征和长期依赖,同时借助LSTM的门控机制处理序列数据中的时序信息和长期依赖关系,这样就可以实现对时间序列数据的高效预测和处理。
比如一种碳排放预测模型,具体创新思路是:
模型利用TCN的并行计算能力和LSTM的记忆能力来捕捉时间序列数据中的长期依赖关系,并通过注意力机制对历史数据中不同时间步的重要性进行加权,以提高预测的准确性。这里的方法包括数据的收集与预处理、模型架构设计、以及模型的训练与评估。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“时序卷积”获取全部方案+开源代码
码字不易,欢迎大家点赞评论收藏

















 593
593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









