







在一个pcl群了,一个学友推荐的三篇比较实用的bin-picking论文,最近就做这方面的了解、学习,就想看看主要思路,记录一下。
第一篇:Fast and Robust Pose Estimation Algorithm for Bin Picking Using Point Pair Feature
这篇文章相对比较容易理解,其基本思路基于PPF(上一篇有写自己的总结)。
1.第一步跟PPF一样,建立模型的点对特征哈斯表,不过在所选择的抽取点的点对特征计算用到的法向量,是在原始点云上计算的。但在投票中只选取20%的场景点 Si。
2.跟PPF第三部投标出来的α进行聚类平均不同,该方便不用聚类,而是采取了建立体格(voxel),进行霍夫投票。大致如下:在场景点云中建立体格素,对PPF中选取的场景点集S,每个点都丢进体格里面,并建立一个立体表,初始化时每个位置赋值-1,把每个Si的位置更新赋予值i,同时对Si的邻近点(左右上下前后)的位置也给与赋值i,主要是为了容忍误差。然后在PPF第二部投票出的α中(设置阈值过滤过的),利用这些α,每次分别对模型点集M中的点Mi进行变换,变换后Mi‘丢进之前建立的场景体格里面,看落在哪个位置,如果该位置所建立的立体表里面不为-1,则该Mi为匹配点,并收集其对应的Si点(通过里面的值i确定),遍历完M集得到该α下的SS(α)集(就是M变换到场景后对应的Si集),对这些SS(α)集计算总数(通过一个二进制Si存在集累加得到,一开始所有Si都得到一个存在值表exist(Si)=1,然后就挑哪些属于SS(α)的出来累加即可)。最后遍历所有α,exist(Si)累加得分最高的即为检测出的目标,其相应的姿态就根据对应的α得到。
3.在多目标检测的情况下,并不是简单的循环,每次找到最大的α,并删除对应的场景点,在重新计算找出最大得分的α。而是充分利用建好的体格和立体记录表。大致如下:一开始,对应得分最大的α,找出其场景中对应目标和姿态得到第一个检测目标,之后把在场景点云中属于该检测目标的点删掉,并更新存在制表,把哪些删掉的Si的exist(Si)更新为0,在重新计算剩下的α对应的exist(Si)累加值,再进行查找最大累加值,其对应的α即为变换值即变换姿态,这里查找最累加值的时候用循环,但有个提取跳出判断条件,即如果当前的exist(Si)累加值大于或等于上一轮最大累加值就跳出,因为理论上删除了一些点,其后面得到的累加值不可能超过上一轮的。以此遍历所有候选α
github上有开源:https://github.com/ktgiahieu/Fast-PPF
二、第二篇 Point Pair Feature-Based Pose Estimation with Multiple Edge Appearance Models (PPF-MEAM) for Robotic Bin Picking
主要思想:基于PPF,但有些改动,包括建立模板时不再用整个CAD模型所有点进行建立,而是通过N=6个视角获得6个模型文件(不同角度),并用PCL库的boundary计算边界点,然后计算每个模型中一定比例的点对特征描述,这里他用的是切线而不是法向量作为计算特征描述的来源。建立Hash表,这里他用voxel的思想去排除同一对点的重复入表(因为不同视角模型可能存在重合部分点云)。对于场景点云,他利用RGB图像通过candy边缘检测获得边缘rgb图,再划分hw常的一个个ROI区域,然后对场景点云做XY上的投影结合一个个ROI进行划得到一组组边界点云共有S组(分组主要是利用组内点计算每一个点的切线方向)。然后就去投票,再聚类筛选pose,最后refinepose(后面的思路跟PPF类似)。
1.整个流程

2.利用CAD模型建立多角度模型(6个),6个模型里面的点的index都是唯一的

3.计算点的描述子(B2B-TL)
(1)计算每个点的切线方向
利用2D 图片RGB图转成灰度图,然后进行canny边界过滤得到边缘图,在边缘图按照每个大小为HW的块进行划分切割成S个ROI,然后对点云图进行XY上的投影,在同一个ROI上的点就sample一起,共Spset 个,然后对每一Spset (i) 内求点的切线方向,有了每个点的切线方向就可以点对的特征描述子B2B-TL了。
切线的计算方法:

(2)计算点对描述子

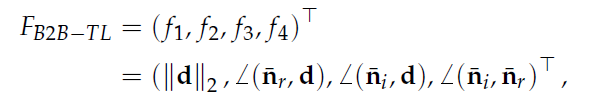
角度都是计算锐角的。
3.建立hash表
用特征描述子作为key,有个问题:不同视角模型的可能存在重复的一些点,这样有可能点对选取时有完全重合的,这里文章给出了一个解决方案,每个点丢进建立的voxel里面,得到一组3个数字的索引即三个方向的位置,这样就可以判断是否是重复的点对了。
4.投票
这部分跟PPF基本一样,只不过该文不用法向量而是用切线方向,最后是以(Mi ,α)进行投票

4.pose确认
这里要把候选pose进行场景到模型的变换,看看inline点个数来打分,这里的变换模型不用整个模型而是用该pose对应的(Mi ,α),Mi来自那个示教模型就用哪个模型,候选pose是取自每个视角模型的前N个候选pose,然后对这些pose进行聚类,选出每一类的最高分的那个,然后进行排序,这样就可以得到多个目标了,且排在前面的基本都是没有什么遮挡的,因为没遮挡的得分肯定高。
5.最后ICP
GitHub资源(不是原作者的)
第三篇:待续
本人正在做bin-picking的尝试,有在这方面一起起步的吗,欢迎留言给我加qq。















 3634
3634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









