






摘要
Logit知识蒸馏因其实用性在近年来的研究中越来越受到重视。然而,与特征知识蒸馏相比,它的性能往往较差。在本文中,我们认为现有的基于Logit的方法可能是次优的,因为它们只利用了耦合多个语义知识的全局Logit输出。这可能会把模棱两可的知识传递给学生,误导他们学习。为此,我们提出了一种简单而有效的logit知识蒸馏方法,即尺度解耦蒸馏(SOD)。SOD**将全局logit输出解耦为多个局部logti输出,并为它们建立蒸馏管道。这有助于学生挖掘和集成细粒度和明确的logit知识。**此外,解耦后的知识可以进一步划分为传递语义信息的一致logit知识和传递样本歧义的互不logit只是。通过增加互补部分的权重,SOD可以引导学生更多的关注模棱两可的样本,提高其辨别能力。
介绍
迄今为止,已经提出了许多logit蒸馏方法,大致可分为两类。第一组旨在通过引入多个分类器或通过自监督学习来提取丰富的Logit知识。第二组旨在通过动态温度或知识解耦等技术优化知识转移。虽然,这些方法取得了很好的结果,但我们认为他们导致次优结果,因为他们仅仅依赖于整个输入的全局logit知识。
具体来说,整幅图像通常耦合多个类别信息,从而导致误分类。一方面,两个类可能属于同一个超类,在他们的样本中共享相似的全局信息。如图1(a)第一列所示,第5类和第6类都属于超类“鱼”,并且具有相似的形状。此外,

如图1(a)第二列所示,场景可能包含来自多个类的信息,例如类6和类983,从而创建语义混合的logit输出。因此,全局logit输出融合了各种细粒度的语义知识。这可能会将模棱两可的知识转移给学生,误导其学习,导致次优表现。
为此,我们提出了SOD方法,通过在尺度水平上解耦Logit输出来辅助logit蒸馏。具体而言,如图1(b)所示,SOD将整个输入的logit输出解耦为多个局部区域的logit输出。然而,SOD将解耦后的logit输出按类进一步划分为一致项和互补项。一致项与全局logit输出属于同一类,将对应类的多尺度知识传递给学生。互补项属于不同于全局Logit输出的类,为学生保留样本的模糊性,避免了对模糊样本的过拟合。最后,SOD对所有logit输出进行蒸馏,将教师的综合知识传递给学生,提高其对模糊样本的识别能力。
总的来说,我们的贡献以及与现有方法的区别如下:
(1)我们揭示了多类知识耦合导致的经典logit蒸馏的局限性。这阻碍了学生对模棱两可的样本继承准确的语义信息。1)
(2)提出了一种简单而有效的logit知识蒸馏方法,即SOD方法。SOD将全局Logit输出解耦为一致和互补的局部logit输出,并为它们建立蒸馏管道,以挖掘和转移更丰富和明确的语义知识。
方法
本节中,我们将回顾传统的KD,然后描述所提出的尺度解耦知识蒸馏的细节。
Notation. 给定图像输入x,设T和S分别表示教师和学生网络。我们将这些网络分为两部分:
(1)一个卷积特征提取器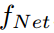 ,
,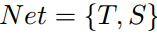 ,则倒数第二层的特征映射记为
,则倒数第二层的特征映射记为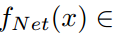
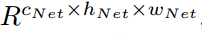 ,其中
,其中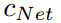 特征通道数,
特征通道数, 为空间维度。
为空间维度。
(2)另一个是投影矩阵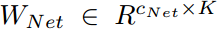 ,它将从
,它将从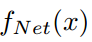 中提取的特征向量投影到K类logit
中提取的特征向量投影到K类logit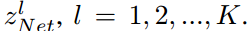 .。然后,令
.。然后,令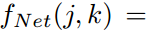
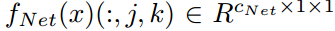 表示
表示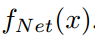 所在位置(i,j)处的特征向量。根据[6,12]中的感受野理论,
所在位置(i,j)处的特征向量。根据[6,12]中的感受野理论,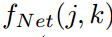 可以看做是x中区域
可以看做是x中区域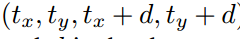 的表示。
的表示。
传统知识蒸馏
知识蒸馏的概念是在[7]中首次提出的,通过以下损失将教师到学生的logit知识提炼出来。
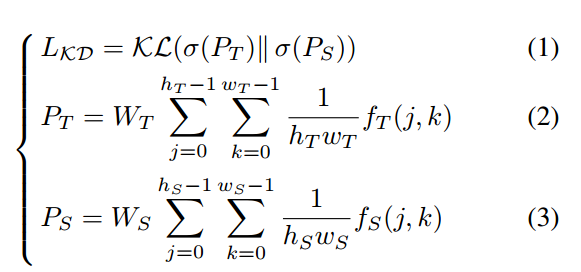
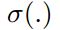 表示softmax方法,
表示softmax方法,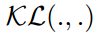 表示KL散度。
表示KL散度。
由于全连接层的线性,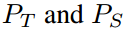 可以改写为:
可以改写为:
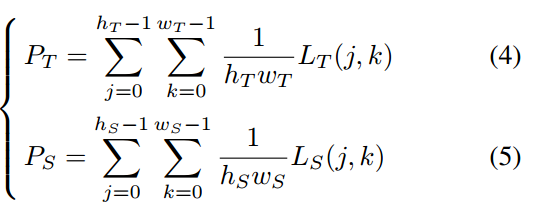
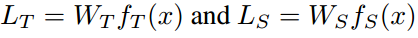 分别表示教师和学生的logit输出映射。
分别表示教师和学生的logit输出映射。
从上面的方程中,我们可以看到,传统的基于logit的蒸馏只利用平均logit输出,混合了从不同的局部特征向量计算的不同的局部logit知识。然而,如图1(a)所示,不同的局部输出通常包含不同的语义信息。简单地将它们融合在logit输出中会将模糊的知识传递给学生并误导其学习。
为了克服这一挑战,我们提出了在尺度水平上解耦logit输出的SOD,以挖掘更丰富和明确的logit知识供学生学习。
尺度解耦知识蒸馏
SDD如图2(b)所示。
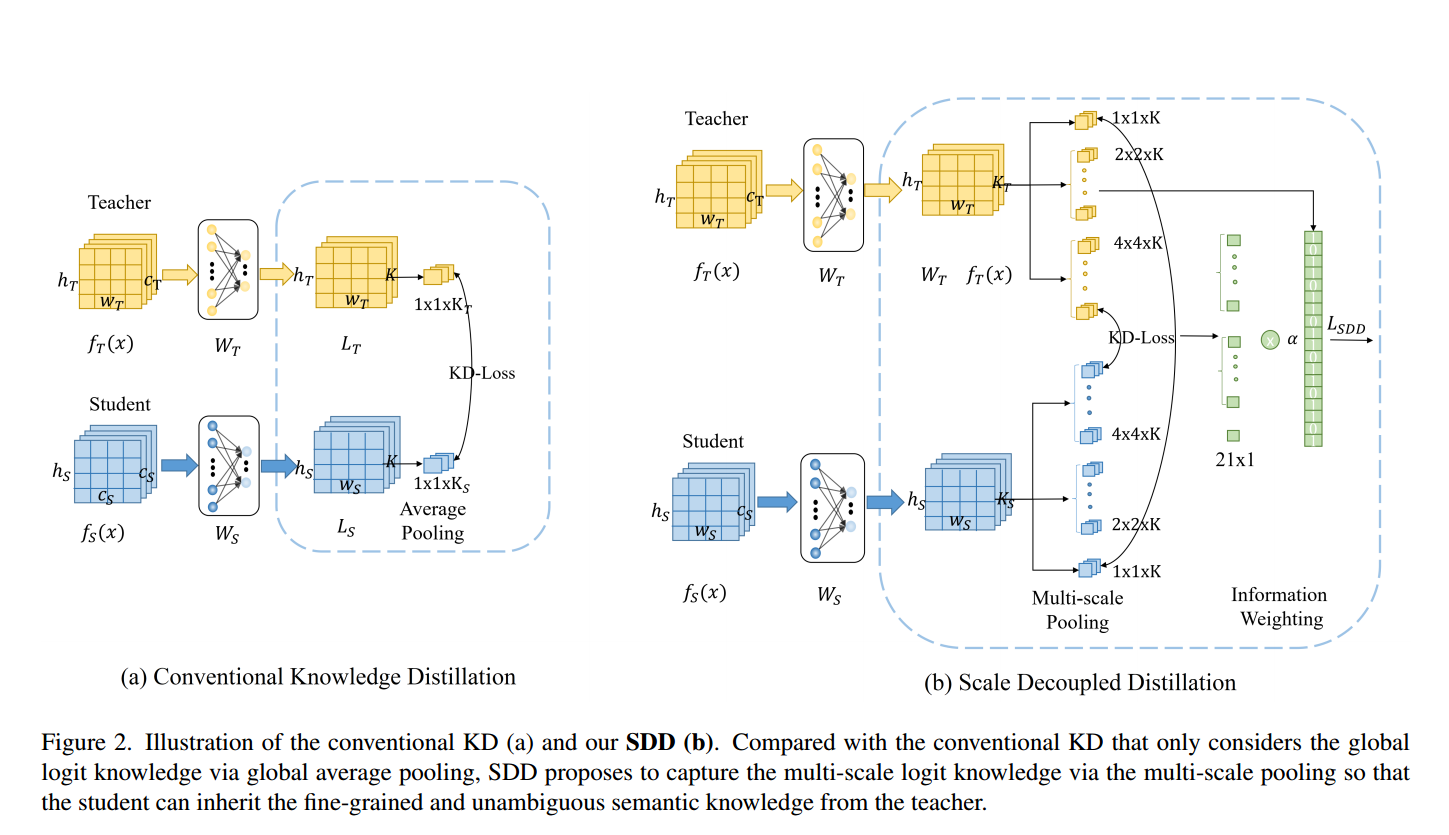
SDD包含两部分:多尺度池化和信息加权。具体地,给定教师和学生的logit输出图,即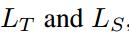 。多尺度池化在不同尺度上运行平均池化,并获取输入图像不同区域的logit输出。与只考虑全局logit知识的传统KD相比,这有助于为学生保留具有清晰语义的细粒度知识。然后,对每个尺度的logit输出建立知识蒸馏管道。最后,对于类与全局Logit不一致的局部logit,信息加权增加了蒸馏损失的权重。这引导学生网络更加关注局部和全局类别不一致的模糊样本。
。多尺度池化在不同尺度上运行平均池化,并获取输入图像不同区域的logit输出。与只考虑全局logit知识的传统KD相比,这有助于为学生保留具有清晰语义的细粒度知识。然后,对每个尺度的logit输出建立知识蒸馏管道。最后,对于类与全局Logit不一致的局部logit,信息加权增加了蒸馏损失的权重。这引导学生网络更加关注局部和全局类别不一致的模糊样本。
具体来说,多尺度池化把logit输出映射划分为不同尺度的单元,并执行平均池化操作作为聚合每个单元中的logit知识。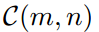 表示第n个单元格在第m个尺度下的空间箱,
表示第n个单元格在第m个尺度下的空间箱,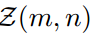 表示该单元格对应的输入区域。
表示该单元格对应的输入区域。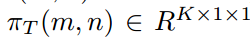 表示教师对
表示教师对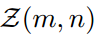 区域的logit输出,也就是这个单元格的logit知识的聚合。
区域的logit输出,也就是这个单元格的logit知识的聚合。
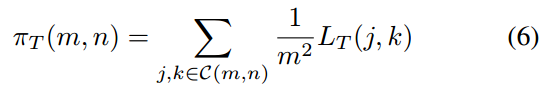
(j,k)表示C(m,n)中logit输出的坐标。学生对同一区域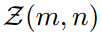 的对数配对输出为
的对数配对输出为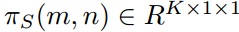 。
。
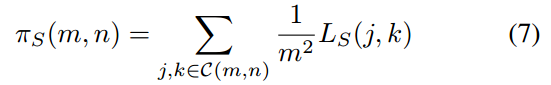
其中m和n与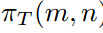 中的相同。对于没对logit输出,将区域Z(m,n)处的logit知识从教师传递给学生的蒸馏损失D(m,n)定义如下:
中的相同。对于没对logit输出,将区域Z(m,n)处的logit知识从教师传递给学生的蒸馏损失D(m,n)定义如下:
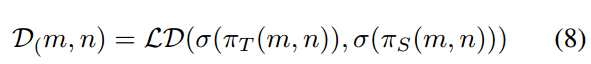
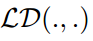 为传统的基于对数的蒸馏损失,如[7]中的KL散度和[24]中的解耦损失。遍历所有尺度m中
为传统的基于对数的蒸馏损失,如[7]中的KL散度和[24]中的解耦损失。遍历所有尺度m中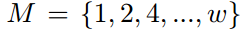 及其对应的细胞
及其对应的细胞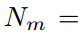
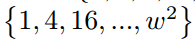 ,我们可以得到最终的SDD损失如下:
,我们可以得到最终的SDD损失如下:
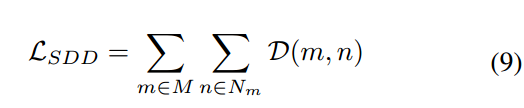
此外,我们可以进一步将解耦后的logit输出通过其类进一步分为两组。一种是与全局logit输出属于同一类的一致项。另一个是来自全局logit输出的属于不同类的互补项。在这里,一致的术语将相应班级的多尺度知识传递给学生。补充术语为学生保留了样本的模糊性。具体来说,当全局预测正确而局部预测错误时,不一致的局部知识鼓励学生保持样本的模糊性,避免了模糊样本的过拟合。另一方面,当全局预测错误而局部预测正确时,不一致的局部知识可以鼓励学生从不同类别的相似组件中学习,减轻教师造成的偏见。
在这里,我们为互补项引入独立的超参数来控制正则化水平,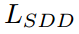 可以重写为:
可以重写为:
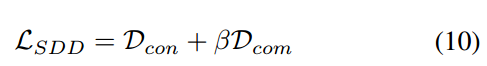
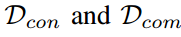 分别为logit一致知识和互补知识的损失和。
分别为logit一致知识和互补知识的损失和。
最后,根据标签监督,学生利用教师的多尺度模式来提高绩效的总训练损失定义如下:
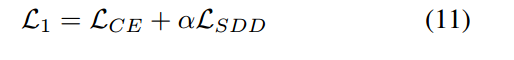
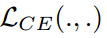 表示标签监督损失,
表示标签监督损失,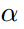 是一个平衡因子。
是一个平衡因子。














 109
109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









