









本讲主要讲述了衡量真实网络结构性质的几种代表性的特征,包括节点度的分布,路径长度,聚集系数和连通性等;以真实社交网络数据为例,介绍了真实图的基本结构特征;另外介绍了几种经典的图生成模型的算法,以及这些图生成模型在上述特征上与真实图的异同点。图的结构性质的不同,对于算法性能影响是巨大的;了解图的基本性质,对于图算法的设计与优化具有重要的指导意义。
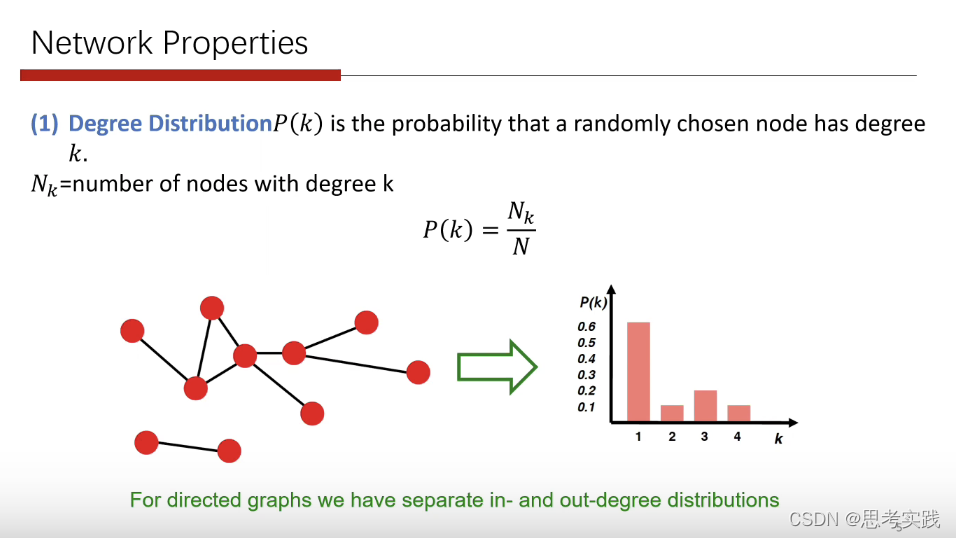
节点度是指和该节点相关联的边的条数,又称关联度。 

Part1 Key Network Properties


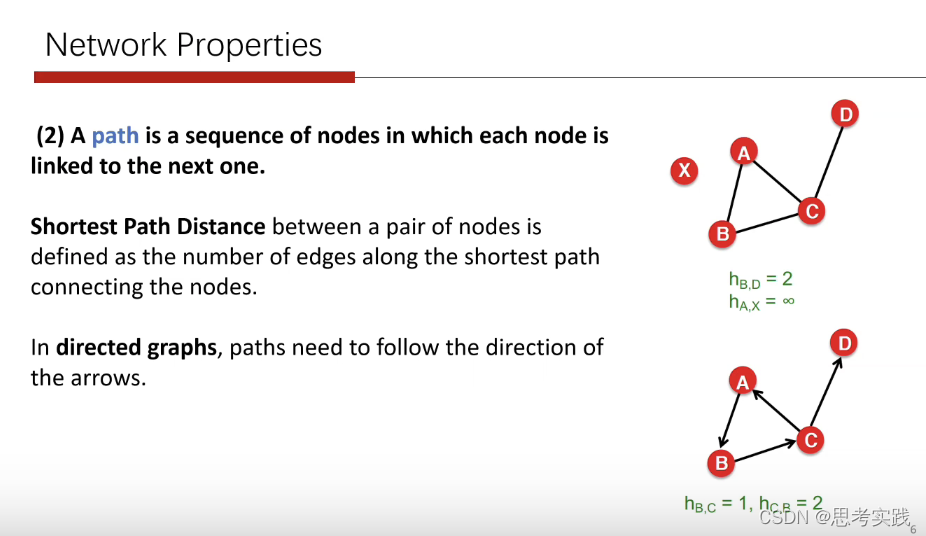
对于路径而言我们在图当中经常要考虑的两个非常具有代表性的参数
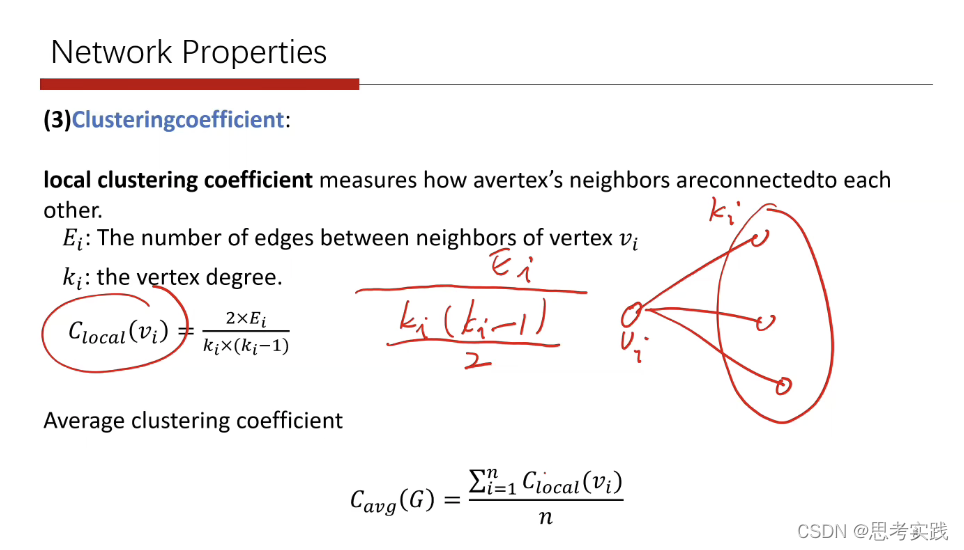
理论上所有ki个结点所能组成的总数是
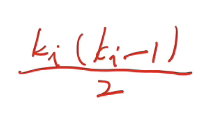
实际上只有Ei条边,所以用
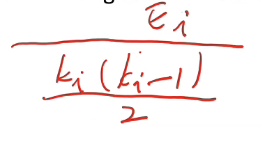
来表达平均聚集系数
实际例子 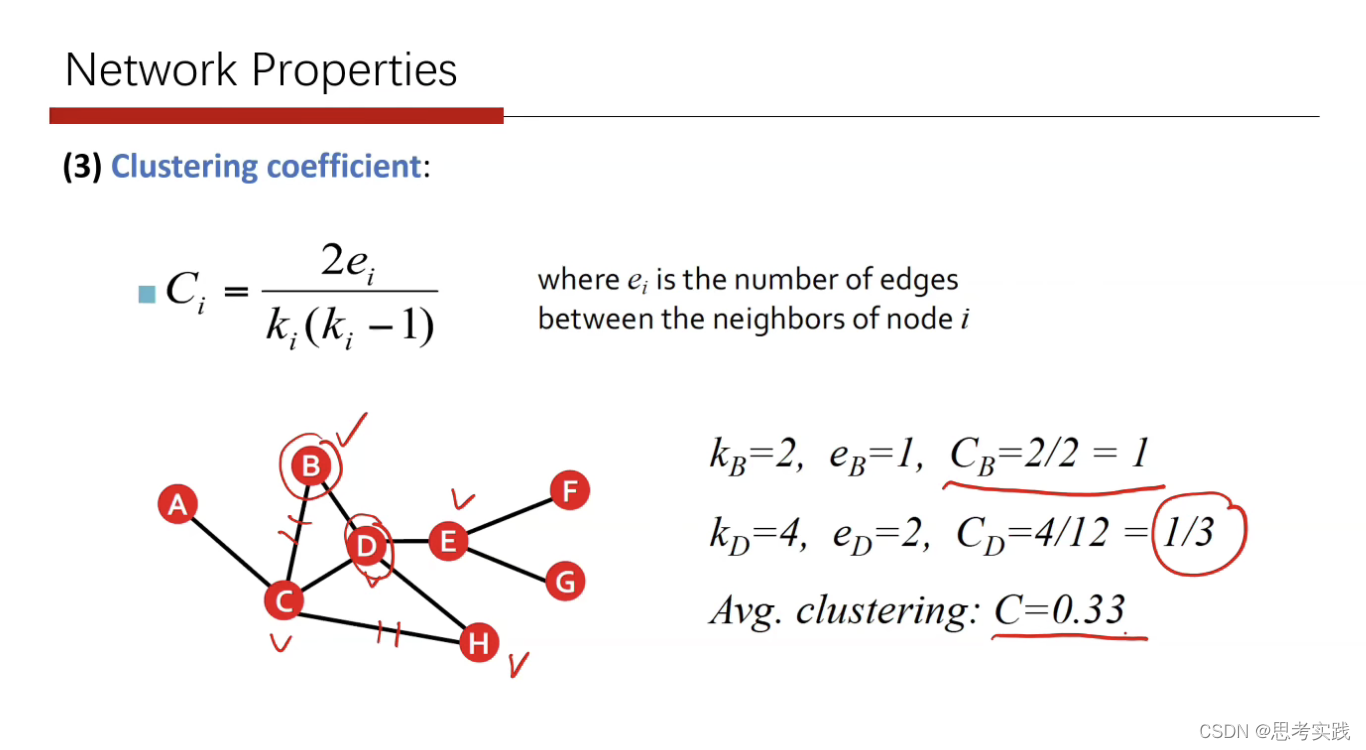
注意ei,拿B点来说,只有C、D两个邻居结点,然后cd之间只有一条边。
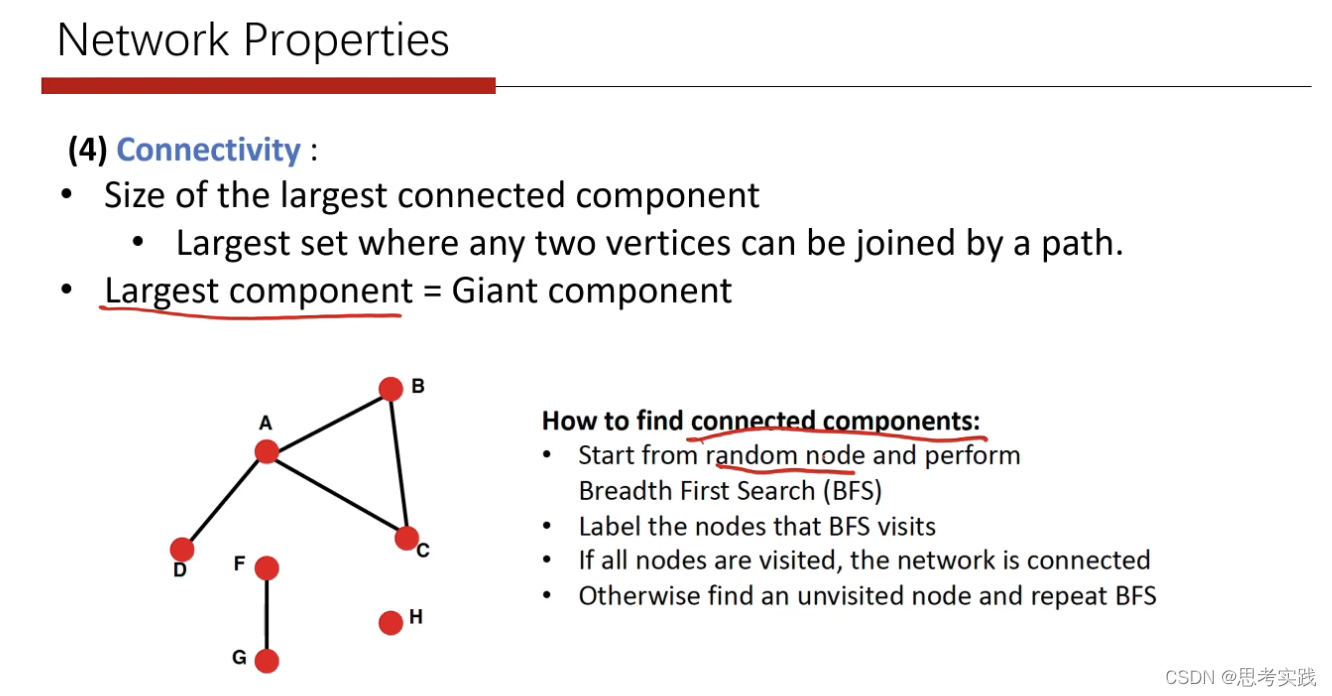
Largest component也就是最大连通分量
Part 2 Meausre Real-world Networks



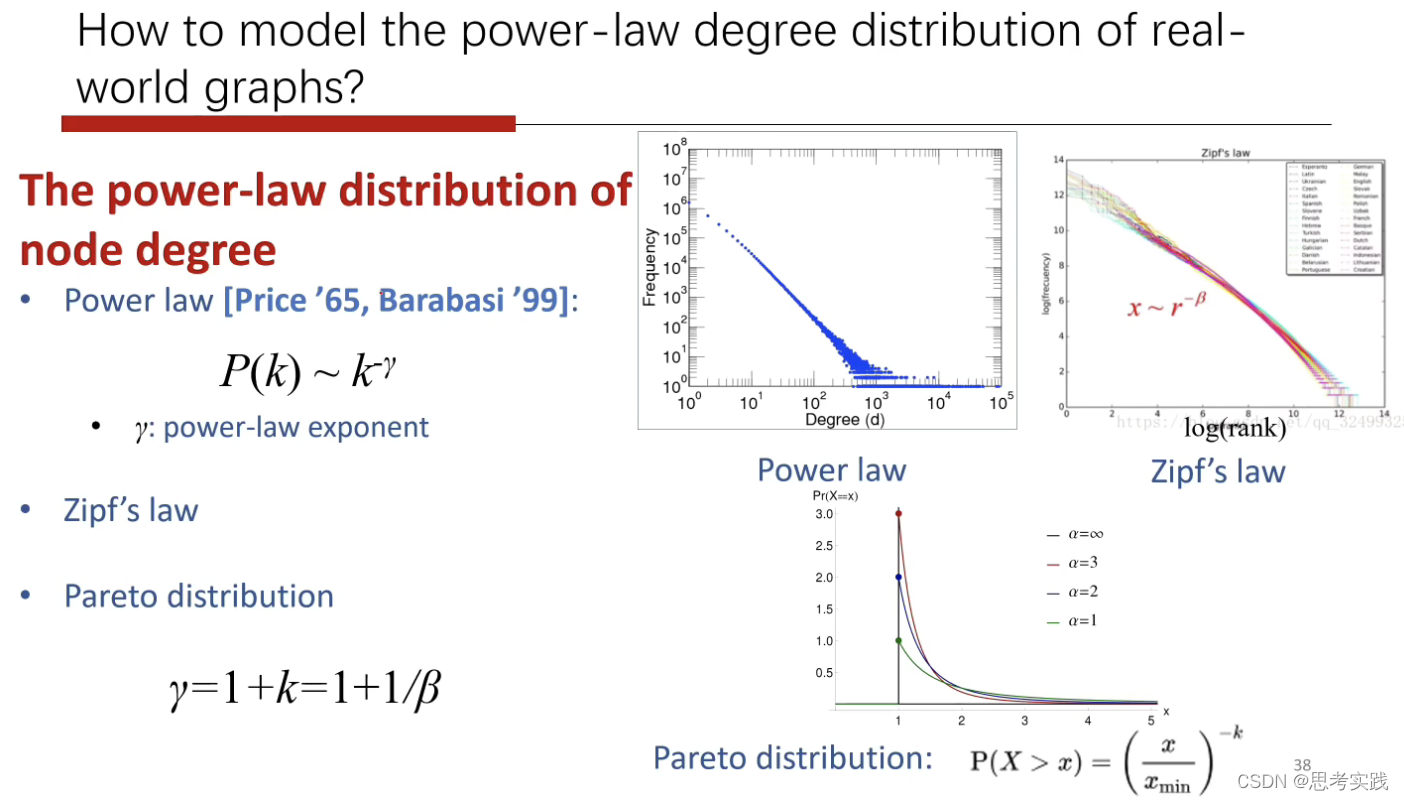
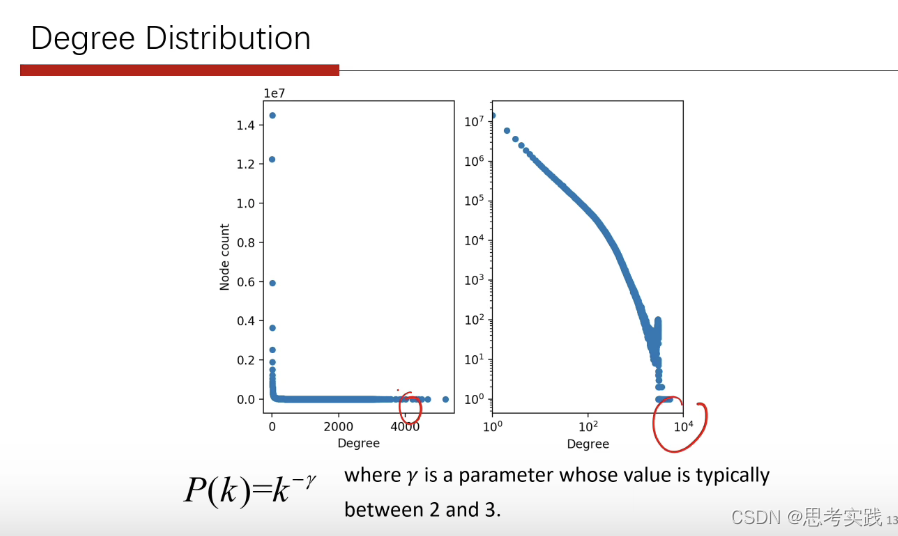 degree大的点数量很少,而degree小的点数目是非常大的。
degree大的点数量很少,而degree小的点数目是非常大的。
对社交网络而言,大v的结点非常的少,其follower特别的多,而大部分人的邻居数目非常少。
这种分布通常也叫做幂律分布,因为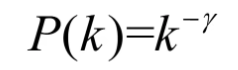
 同样,degree比较大的点,你会发现聚集系数比较小,可以理解为大v和他的邻居之家构建好友的可能性比较小,然后构成社区关系的概率也小,比如b站up主大v关注的人很少,而普通用户关注的人贼多,比如我,嘿嘿。
同样,degree比较大的点,你会发现聚集系数比较小,可以理解为大v和他的邻居之家构建好友的可能性比较小,然后构成社区关系的概率也小,比如b站up主大v关注的人很少,而普通用户关注的人贼多,比如我,嘿嘿。
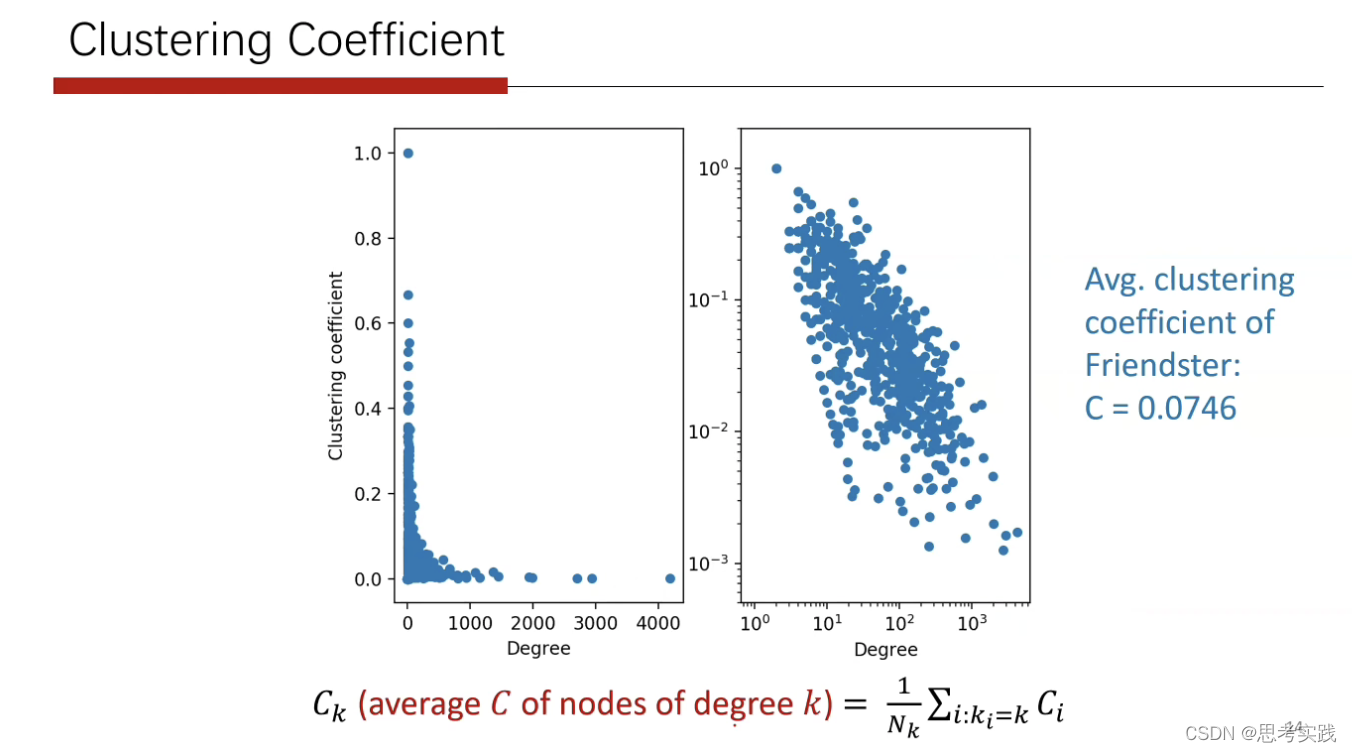
反映了给一个图,其中大部分的结点,都在最大的component当中,这就是真实图的一种基本特性。
另外在提到这个路径长度方面,大家都听说过在社交网络当中有
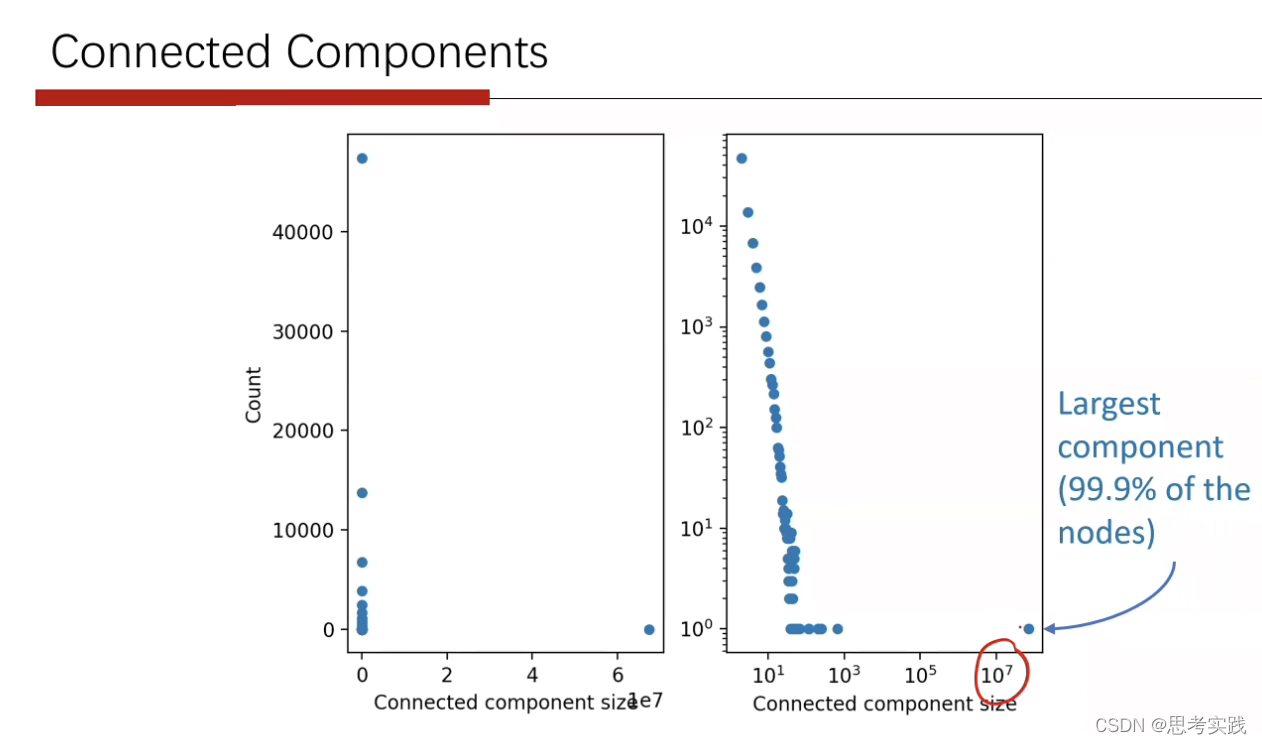
 到了2011年,Facebook联合米兰大学研究了7.21亿活跃用户构建的好友网络,估计出了任意两个用户之间的距离分布,发现 Facebook 网络的平均距离只有4.74,代表只需要3.74个中间人就能够让人们相互认识,据此他们写出了名为“四度分离”的论文。
到了2011年,Facebook联合米兰大学研究了7.21亿活跃用户构建的好友网络,估计出了任意两个用户之间的距离分布,发现 Facebook 网络的平均距离只有4.74,代表只需要3.74个中间人就能够让人们相互认识,据此他们写出了名为“四度分离”的论文。

90%的结点在8跳以内都可以reachable


小世界模型用数学的方式来表达,随着结点数目N(用户)的增加,这个节点之间的距离Length并没有显著增加,这种现象被称为Small World Graphs

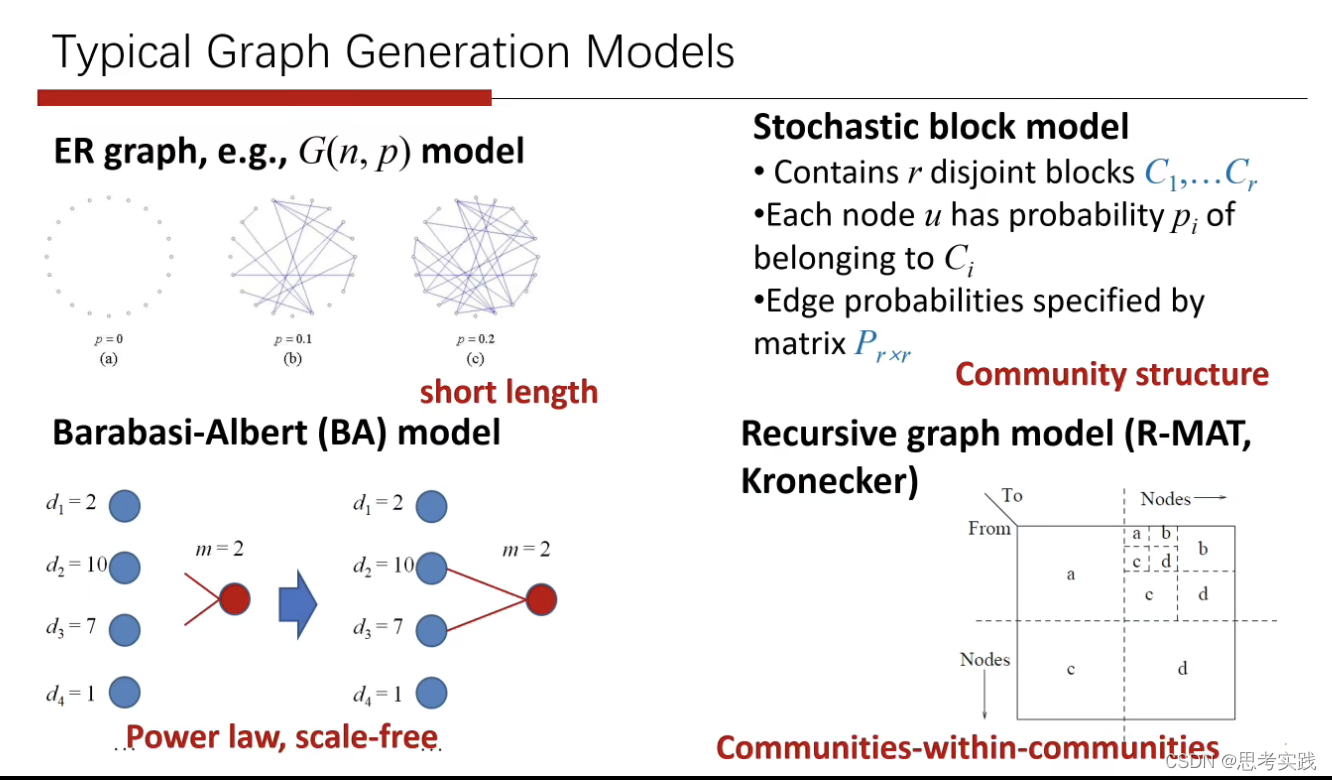
Part3 Graph Generation Model

图的基本性质描述了图的一些不同的特征,比如它的路径长度与degree分布,也用了真实图举例看这些性质在真实情况中是什么样的,然后发现degree的分布是满足power,log这样的特征,为什么需要图的生成模型呢,需求有很多不同的场景,比如用户数据的隐私性,我们需要一个数学模型它可以尽量的模拟真实图的一些特性,使得我们可以在生成图上面做算法性能的评估,生成模型的好处是可以产生不同大小的不同尺寸的图从而测试算法或者这个系统的可扩展性和健壮性。
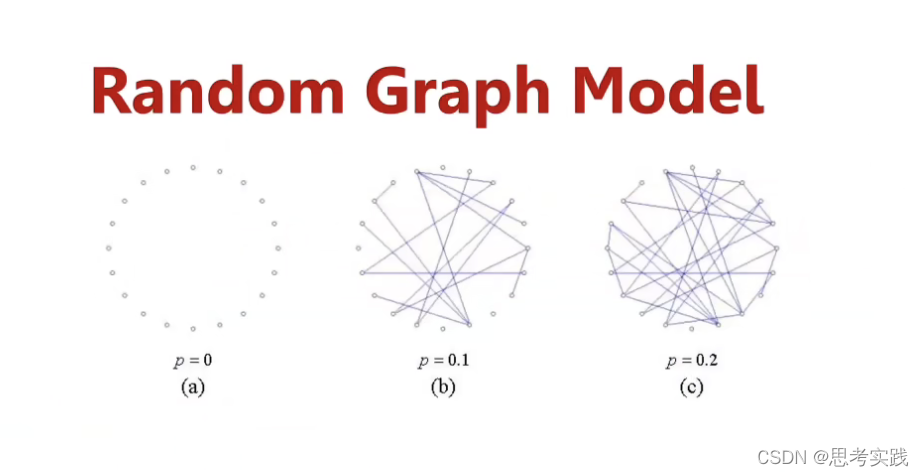
随机图模型思想特别的简单,它有两个版本,基本思路是一样的,

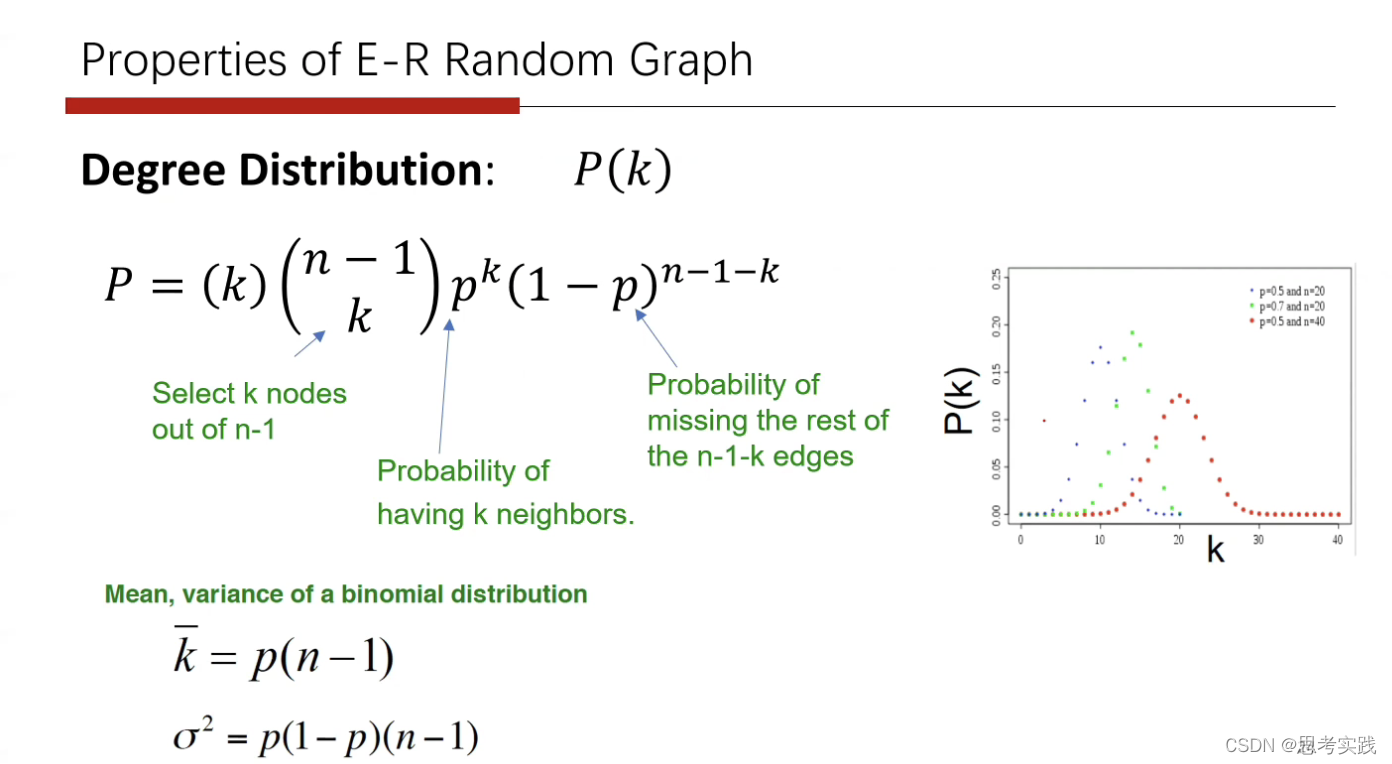 degree分布呈现二项式分布并没有呈现对数分布,这一点与真实图情况不太一样。
degree分布呈现二项式分布并没有呈现对数分布,这一点与真实图情况不太一样。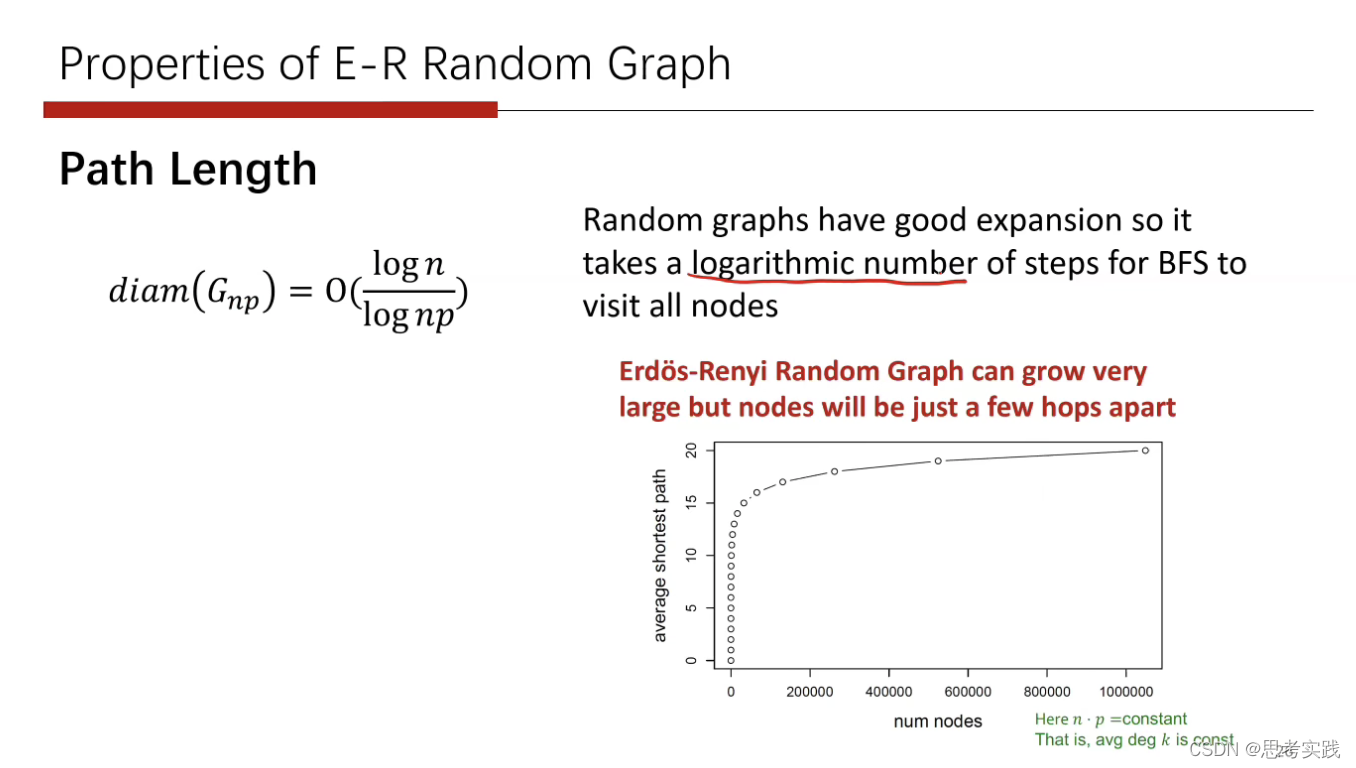
随着结点数量的增长,路径长度并没有显著的增长,这个属性表现的情况与真实图情况非常一致。

当我们发现这个平均deg=1的时候,它是一个分界点,超过1,发现图会迅速出现一些最大连通区域。
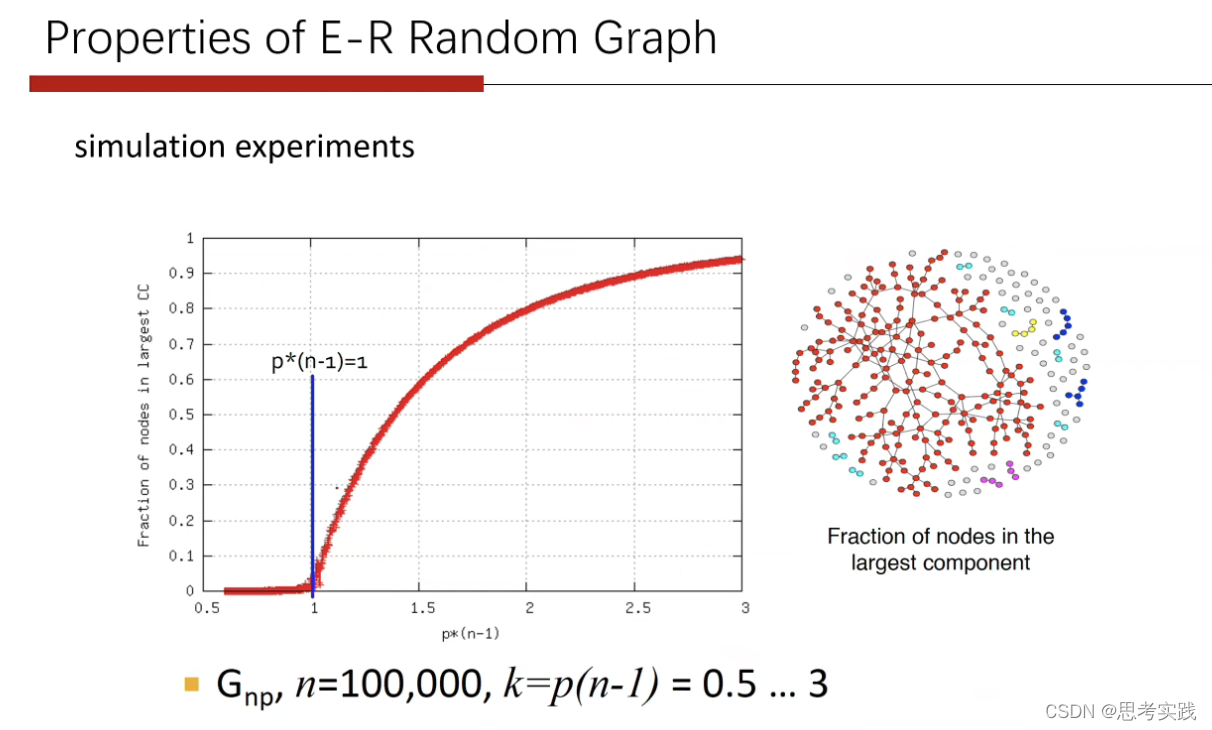
当平均deg比1小一点,你会发现所有的component都是比较小的且规模只有(logn ),
当平均deg超过1的时候,这个E-R图表现出来的是与真实图一样是有一个非常大的连通区域(涵盖了绝大部分的结点)。

我们把ER模型与1真实图做一下比较


GCC代表最大连通区域giant connected component如果你是做一个社区发现算法,你不能在ER图上去做测试,因为这个ER图并没有这样一个社区,不能很好的反映这个算法对社区发现的效率。但是你如果做一些路径相关(比如两个人之间的社交距离)的算法的话,你实际上是可以在ER图上去做这个测试的,因为在路径长度方面此ER图与真实图是比较接近的。
所以说我们在做算法评估的时候,我们需要选择不同的生成模型来接近真实情况。
改善ER图与真实图不一致的地方,比如平均系数小的这样一个问题,提出来了一个small world模型。

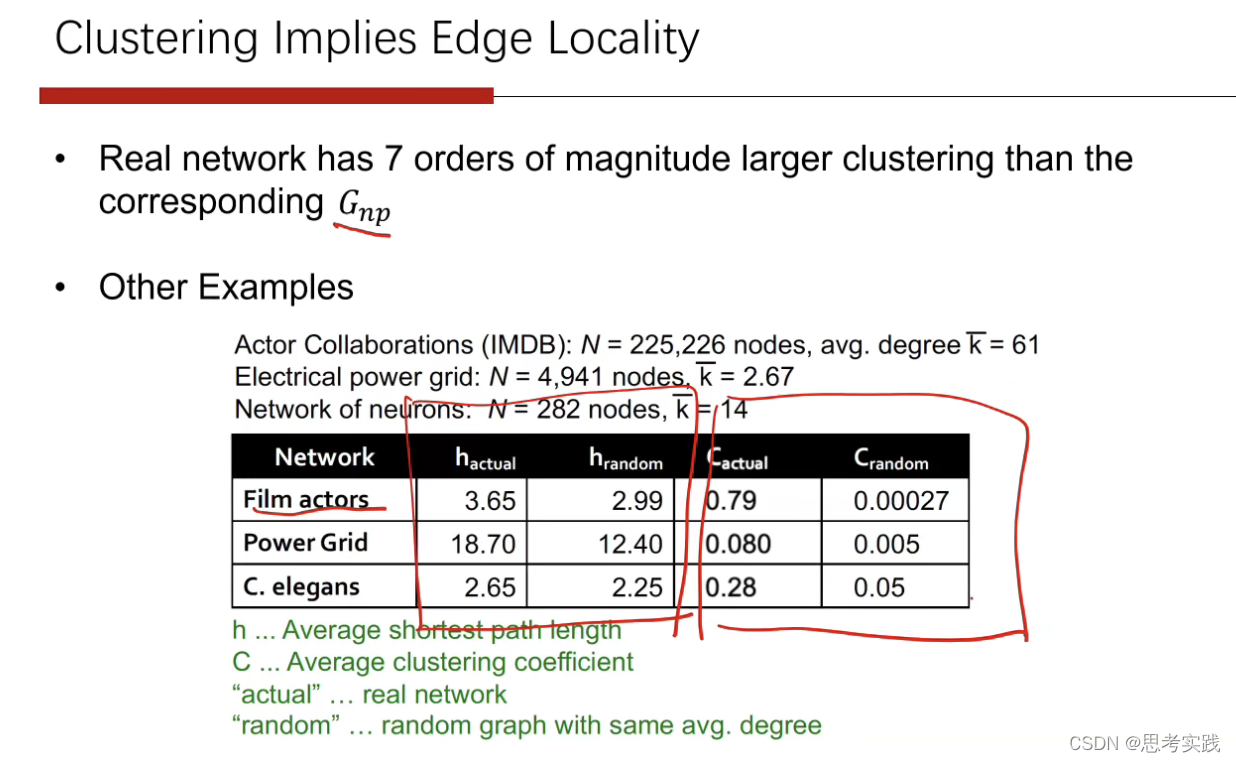 ER图的平均聚集系数是比真实图小几个数量级的 ,路径长度是比较接近的,聚集系数差的相当的远。
ER图的平均聚集系数是比真实图小几个数量级的 ,路径长度是比较接近的,聚集系数差的相当的远。
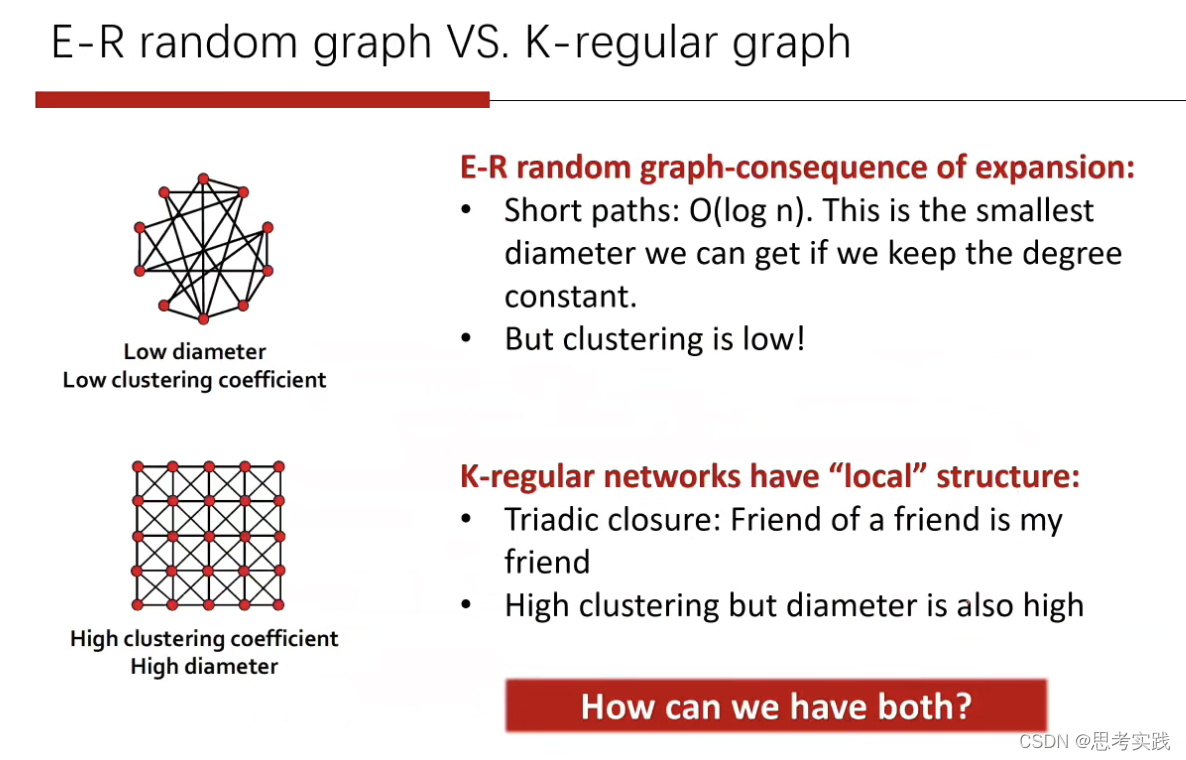
K-regular graph意思是每个结点的邻居都是k个,K-regular网络具有很好的local structure,聚集性是非常强的。
但是K-regular graph最大的一个问题就是说两个结点之间的距离是非常大的,图的直径diameter是非常大的,这一点不好,而ER图是diameter较小也比较接近真实图的。
为了合二为一才产生small world这样的模型
如果一个结点它的朋友也相互有联系也就代表着,那么这个这个vi结点具有很强的local clustering coefficient值,所以说聚集系数反映的是一个“locality”.
确实真实图是这样一个特性,但是随机图不是这样子,对于k-regular这样的图之所以有很强的聚集系数是也是因为局部性的特征,但其diameter比较强.
所以我们通过引入"shortcuts"来降低图的diameter——我们两个人有很多共同的好友所以咱俩能构建好友的机率就非常大,还有可能我们随机的与远方的人构建随机关系(而这种好友关系我们称作为shortcuts,这是随机性产生的)
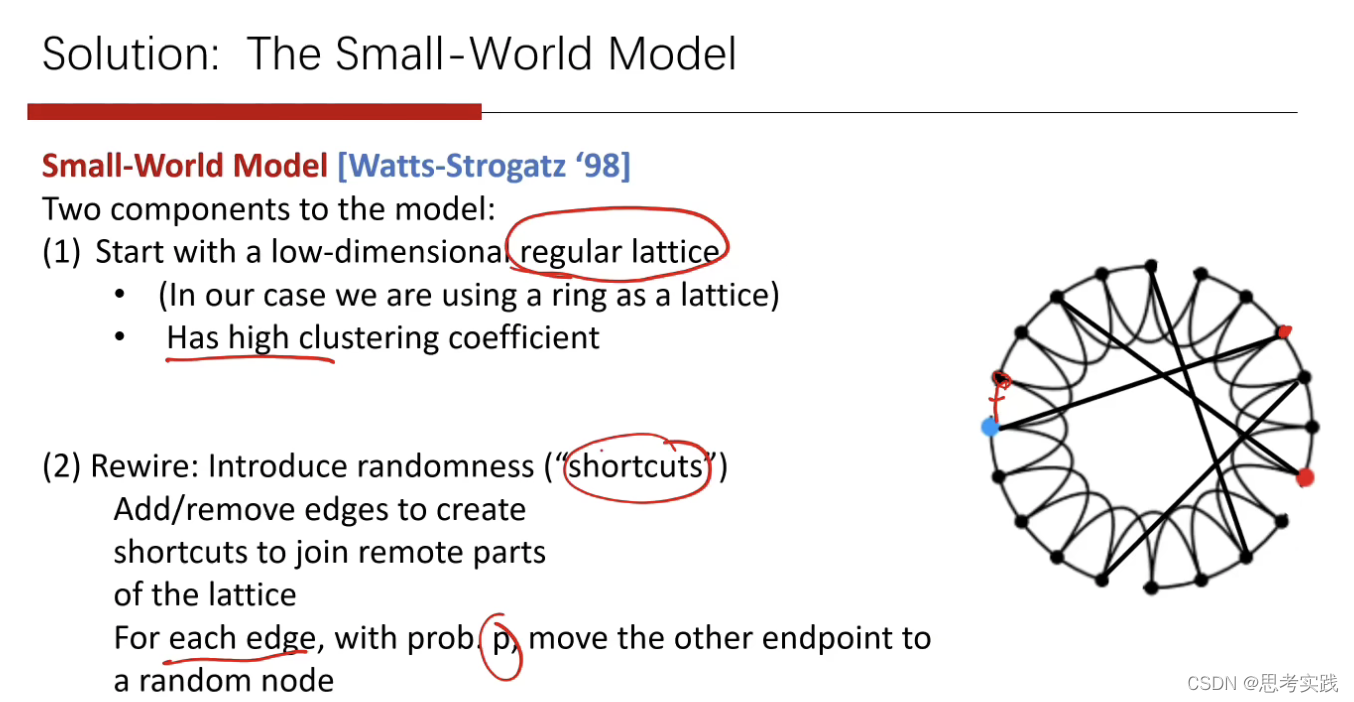
98年的一个小世界模型,过程如下:
1>首先产生一个小规模的regular lattice,k-regular这样的一个graph
2>对于任意一条边,以概率p,把另外一个端点移到随机结点
通过这样的方法可以增加图的随机性
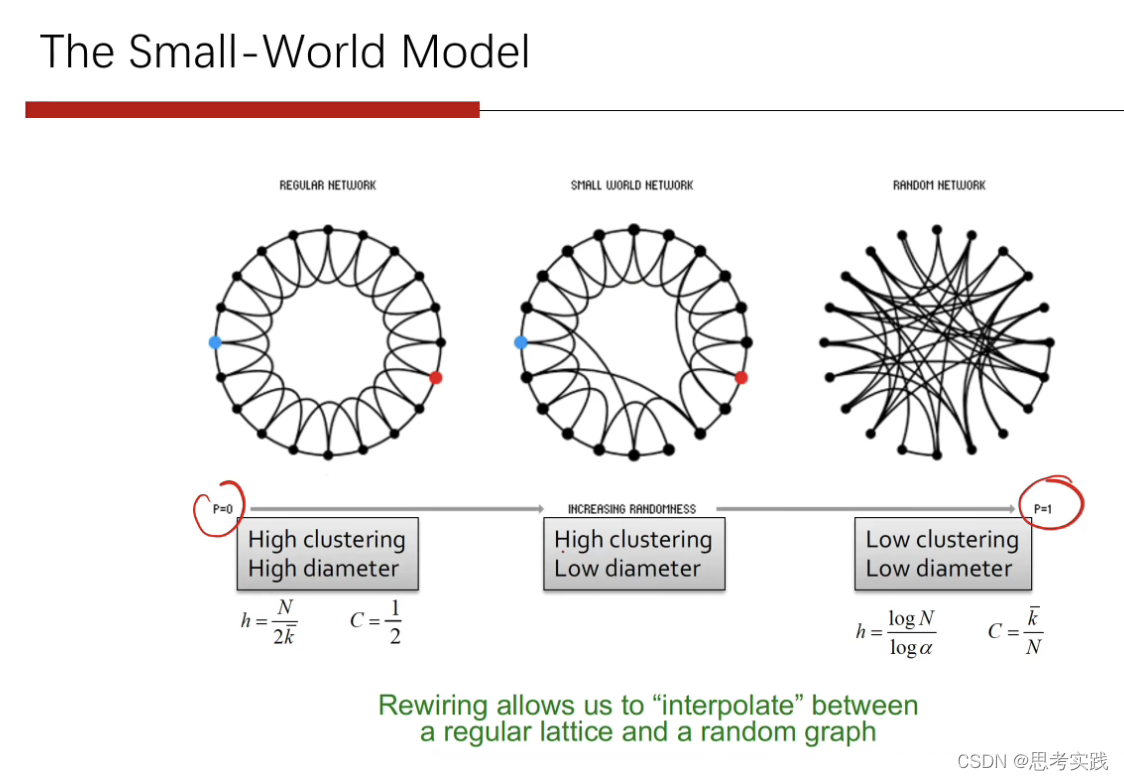 P=1的时候就是一个完全的随机图了也就是之前的ER图,需要很多的随机去破坏聚集性,但是很少的randomness就可以增加shortcuts,然后其可以降低图的diameter.
P=1的时候就是一个完全的随机图了也就是之前的ER图,需要很多的随机去破坏聚集性,但是很少的randomness就可以增加shortcuts,然后其可以降低图的diameter.
我们有很强的空间(region),其具有高聚集性,低路径距离的特点。
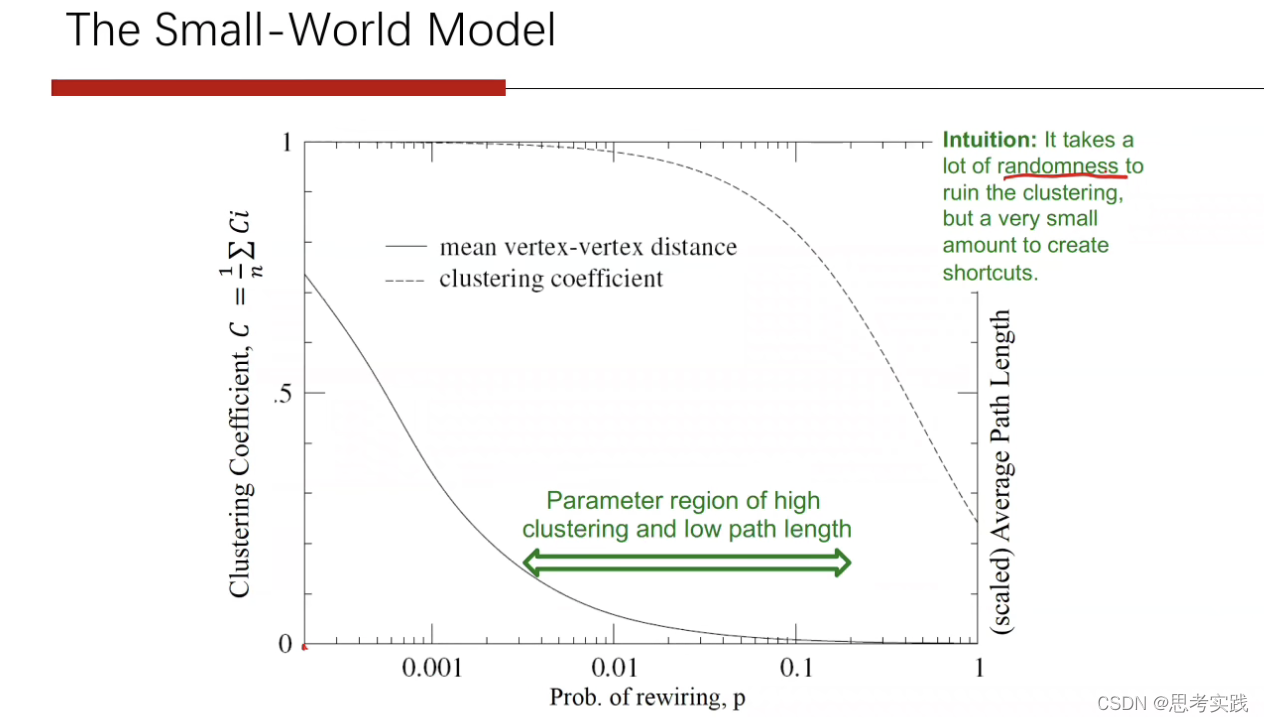
无论刚才的ER图还是Small world图,它们都是一种静态图生成模型,也就是你刚开始需要给定n个结点,但是很多真实情况下,图的生成是不断增长的一个过程,而这个BA图就是不断增长的一个图模型,同时BA图希望改善ER图与WS模型当中没有能做到这个度的分布接近真实情况.
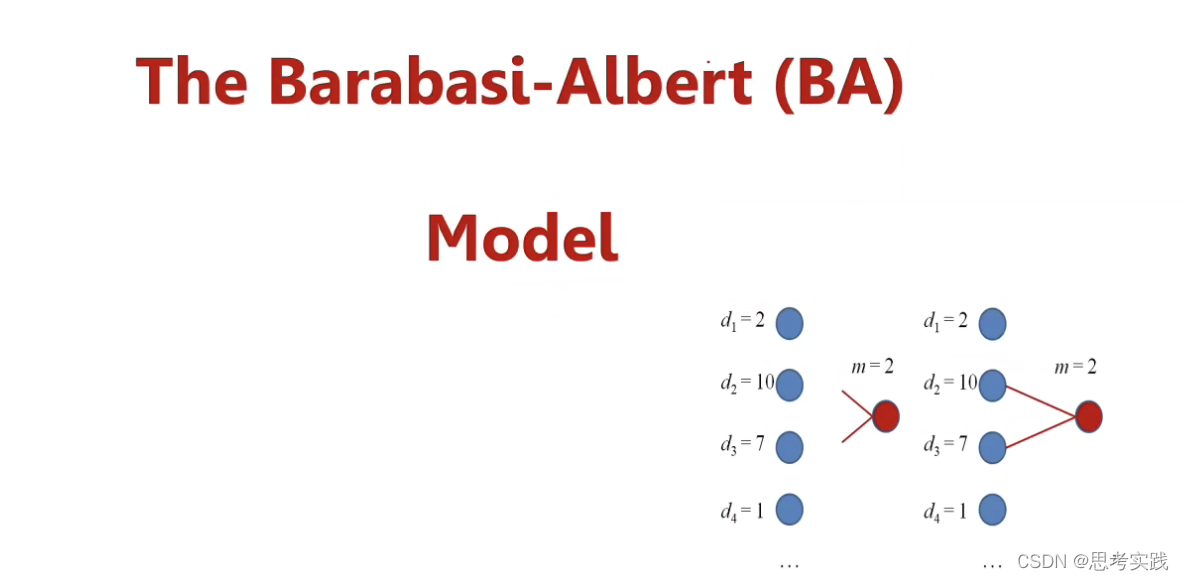
 BA模型是怎么做到的呢
BA模型是怎么做到的呢
 原来图中有更大degree的结点更容易以概率P与新结点相连接, 就是这个节点的deg除以所有节点的deg的和.
原来图中有更大degree的结点更容易以概率P与新结点相连接, 就是这个节点的deg除以所有节点的deg的和.
我们可以证明在这样的一个生成图模型它的这个deg distribution是满足power law的,并且这个分布的幂参数是3.

另外,BA图的这个diameter也具有小世界模型这样一个特征,也就是贴近真实情况.

也有一些非线性的增长模型,也就是原结点与新结点连接的概率的degree计算不是安装线性的求和.

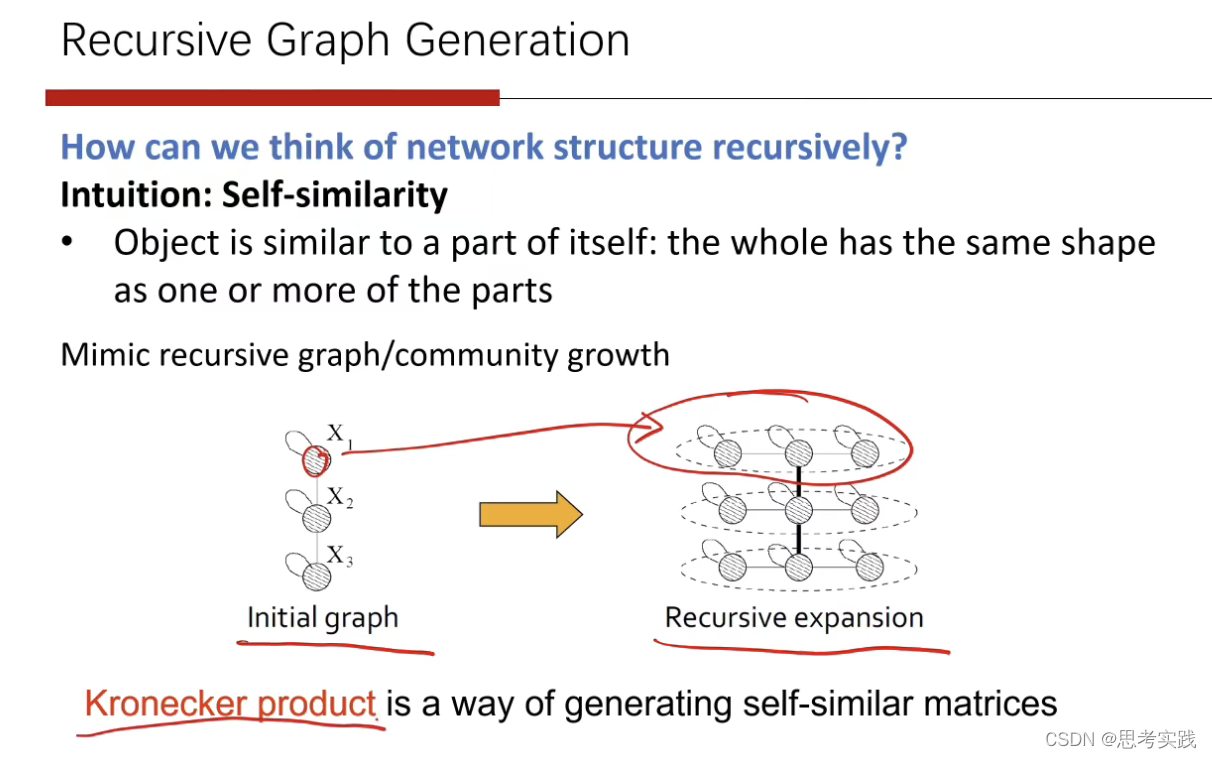
最后这个Kronecker Graph Model,这种我们称为recursive的一种生成模型.
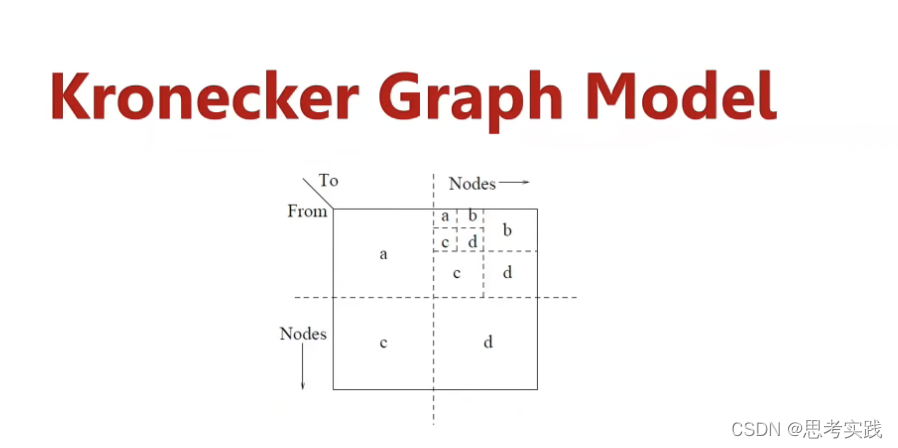
它的基本含义是Self-similarity,就是整个结构与其部分的结构比较接近,在数学上我们可以用这个科诺乐克积来实现
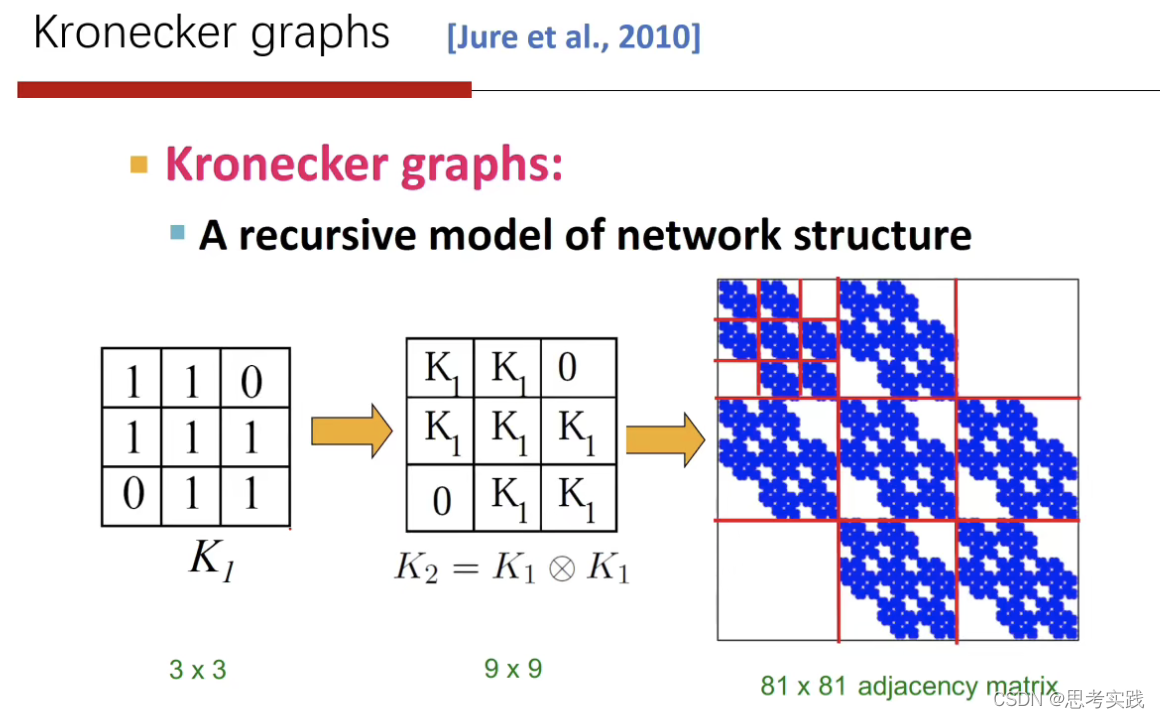


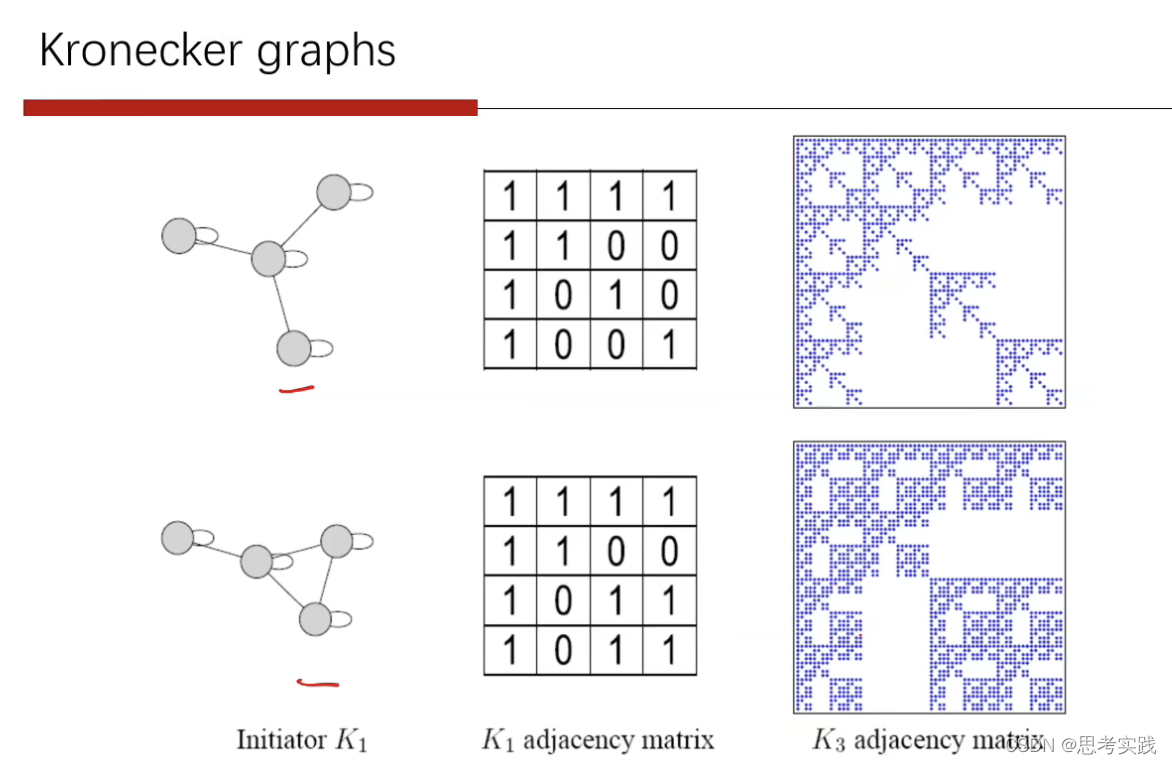
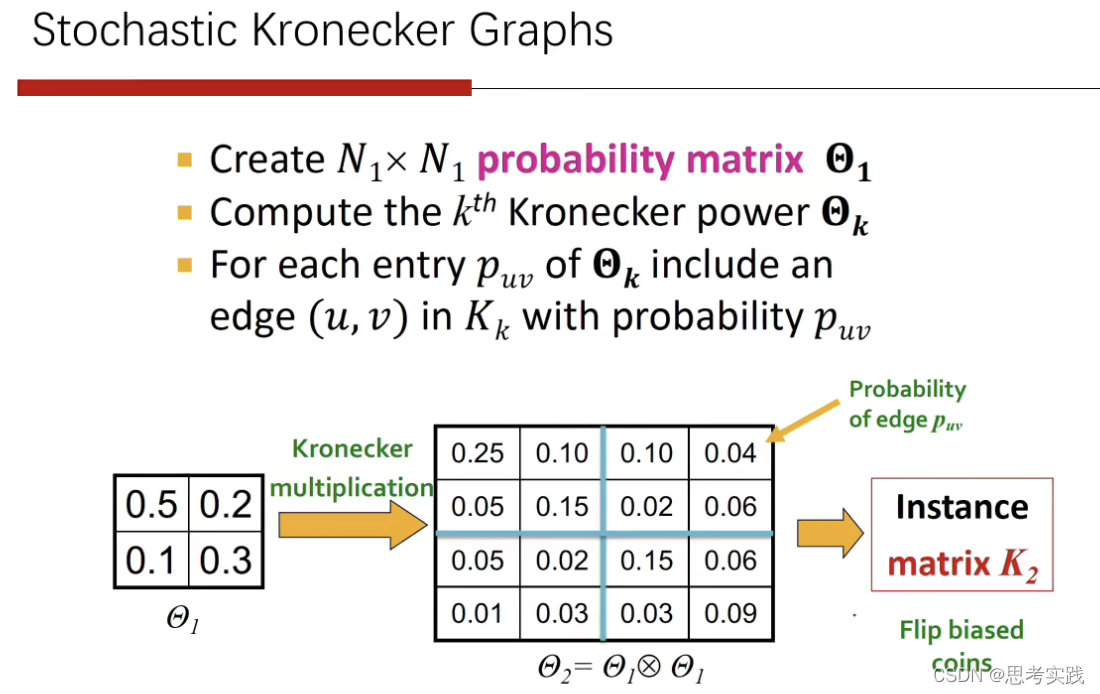 我们可以引入一个概率的kronecker graph
我们可以引入一个概率的kronecker graph
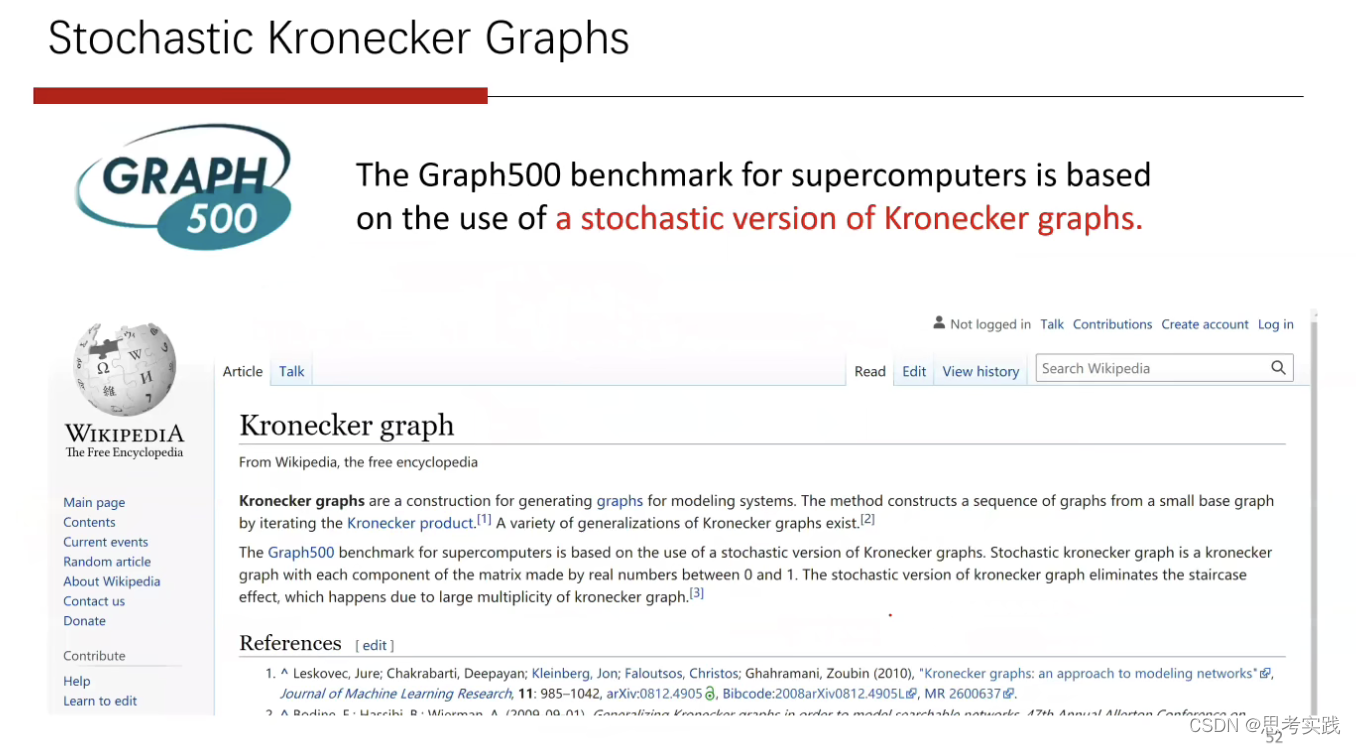
Graph500评估超级计算机的计算能力
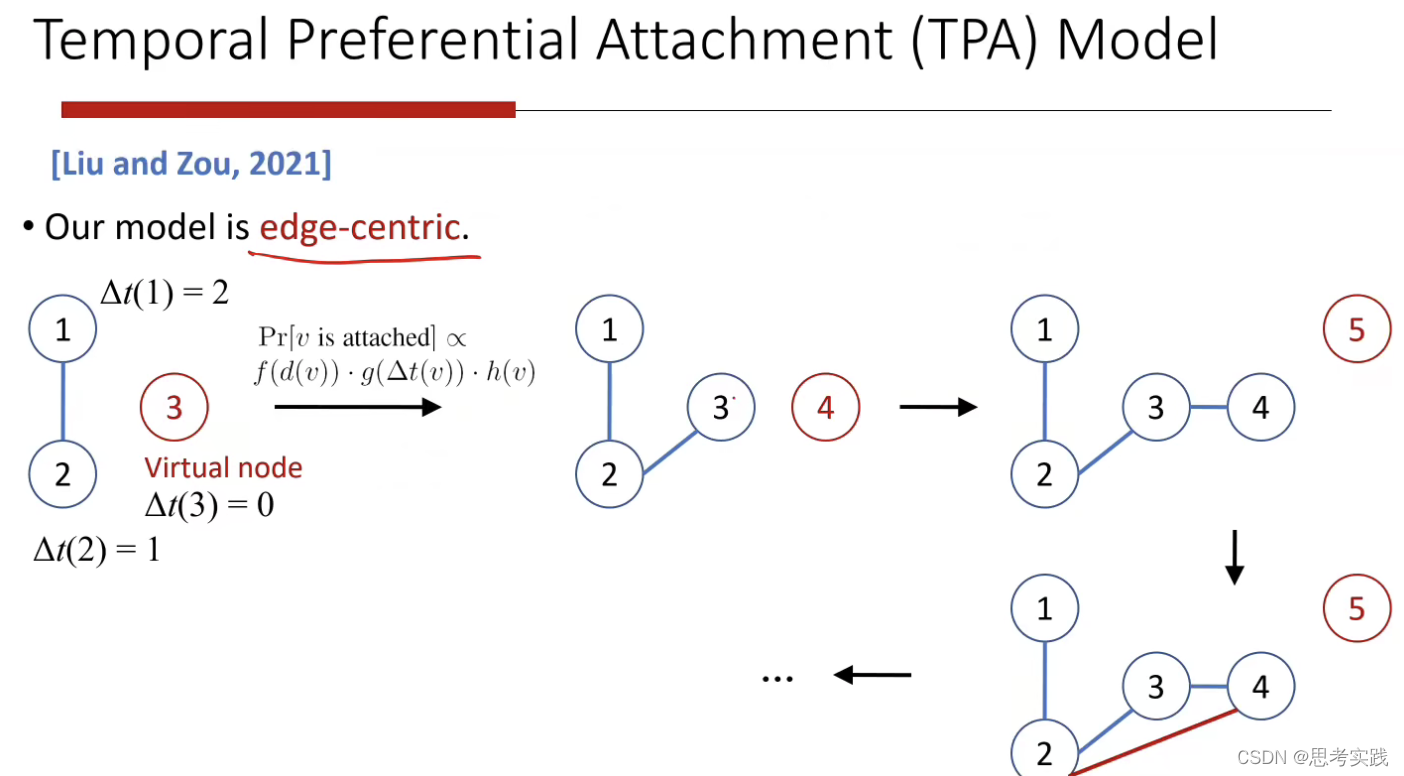
2021年王选博导课题组提出的模型,与BA模型的区别是以边为中心,就是来了一条边,它应该怎样去连.
可能是引入在已有的两个点之间,也可能是在新增的点和原始的点之间

参考资料


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









