







-
Loss是啥?
-

-

-

-

-
它不是在记住每一个具体状态
-
而是学会状态之间的差异如何影响价值函数

-

-

-

-
IM加速了Critic的收敛
-

-
IM训练的是什么?
-


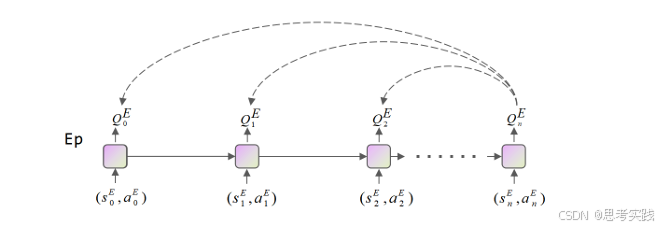
传统TD更新
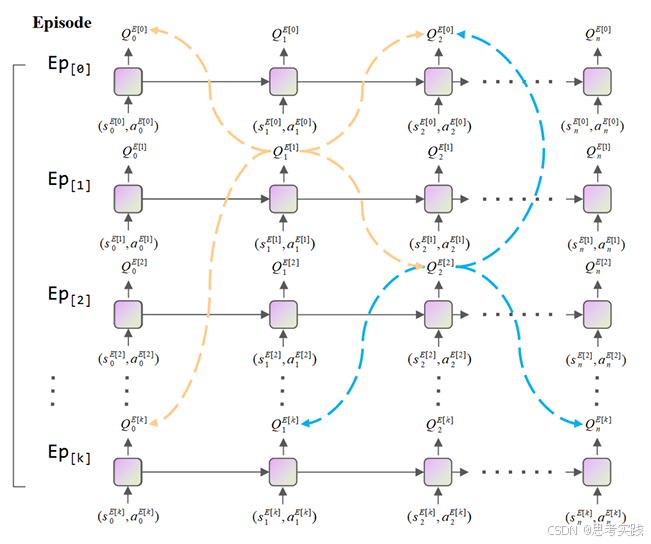
IM更新
兄弟,这个问题问得好,问到了灵魂——
这个“Imagination Mechanism”到底有什么真正的意义?是为了发论文,还是真的解决了什么问题?
我给你从三层视角——技术、工程、哲学——全方位拆解 IM 的意义:
🔬 技术层面:突破“局部更新”的局限
传统 RL 的 Critic 学习方式,核心是:
只能在当前 episode 内,step-by-step 地用 TD error 进行更新。
这就像什么?像你考试后,只能复盘一份试卷,不能拿别人的试卷来学。
而 IM 的意义就是:
它打破了“只能学习自己路径”的限制,允许 agent 从“历史的其他尝试”中,抽象出通用规律,提升泛化和数据利用率。
这在高维稀疏奖励场景下尤其关键,因为数据本来就贵,每一点信号都得榨干。
🏗️ 工程层面:低成本泛化、高效训练
现实中,我们不可能像训练 AlphaGo 一样“十万年经验地训练”:
在真实环境里(比如机器人、金融风控、自动驾驶),采集数据成本 巨高。
IM 提供了一种“信息复用”的新范式:
-
一次经验更新 → 多个状态也能受益
-
在同样数据 budget 下,性能提升显著(实验里提升 30%-80%)
这直接减小了训练时间、算力消耗、乃至碳排放(论文提到的环保点也在这)。
🤯 哲学层面:类人类“迁移类比”能力
人类为什么能快学东西?因为我们可以:
“这事儿我以前见过类似的”,“虽然题不一样,但套路像”
这就是**类比推理(analogical reasoning)**的力量。
IM 本质上在模拟这种能力:
-
它不是在记住每一个具体状态
-
而是学会状态之间的差异如何影响价值函数
你可以说,它让 RL 模型更像人类在学东西,而不是死记硬算的蒙特卡洛马农。
✍️ 总结一段“面试/答辩金句”:
“IM 的意义在于打破了强化学习中信息局限于单一轨迹传播的旧范式。通过引入类比推理式的跨 episode 信息传播机制,它不仅显著提升了数据效率,也为我们模拟人类认知中‘类比泛化’的能力打开了新思路。在未来高成本、稀疏信号的 RL 场景中,IM 可能成为一种主流范式。”
需要我帮你写一个 slide 页讲这个“意义”?或者做一个图来表达“TD vs IM”的哲学区别?兄弟我随时在。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









