










最近参加了深蓝学院举办的 《大型语言模型前沿技术系列分享》,该系列分享以大模型(LLM)为背景,以科普、启发为目的,从最基本的Transformer开始讲起,逐步涉及一些更高阶更深入的课题,涵盖大模型基础、大模型对齐、大模型推理和大模型应用等内容。
系列讲座的内容由浅入深,讲解非常细致,没有任何水分,很适合我这种NLP刚入门的小白,听了这些讲座之后感觉收获满满👍👍👍
8.26 讲座安排(实际时长17:30-21:30)

本篇博客记录第一个讲座:《人工智能发展史和ChatGPT初探》
1. 人工智能发展史
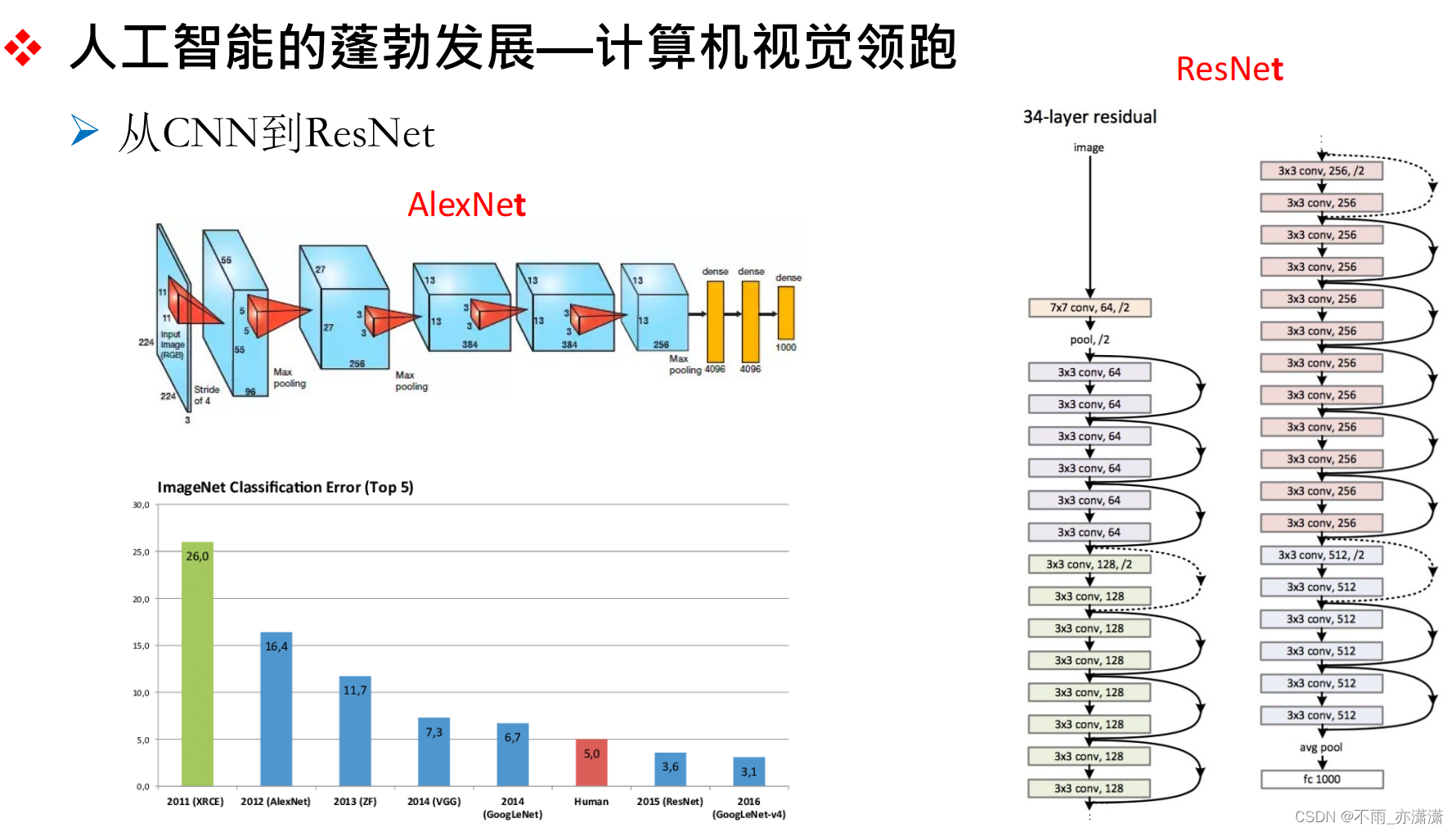
人工智能发展不是一帆风顺的。在早期,计算机视觉领域的发展是领先的,一个重要原因是斯坦福大学公开了lmageNet数据集,基于这个超大的数据集,研究人员提出了不同的模型,一个典型代表就是AlexNet.
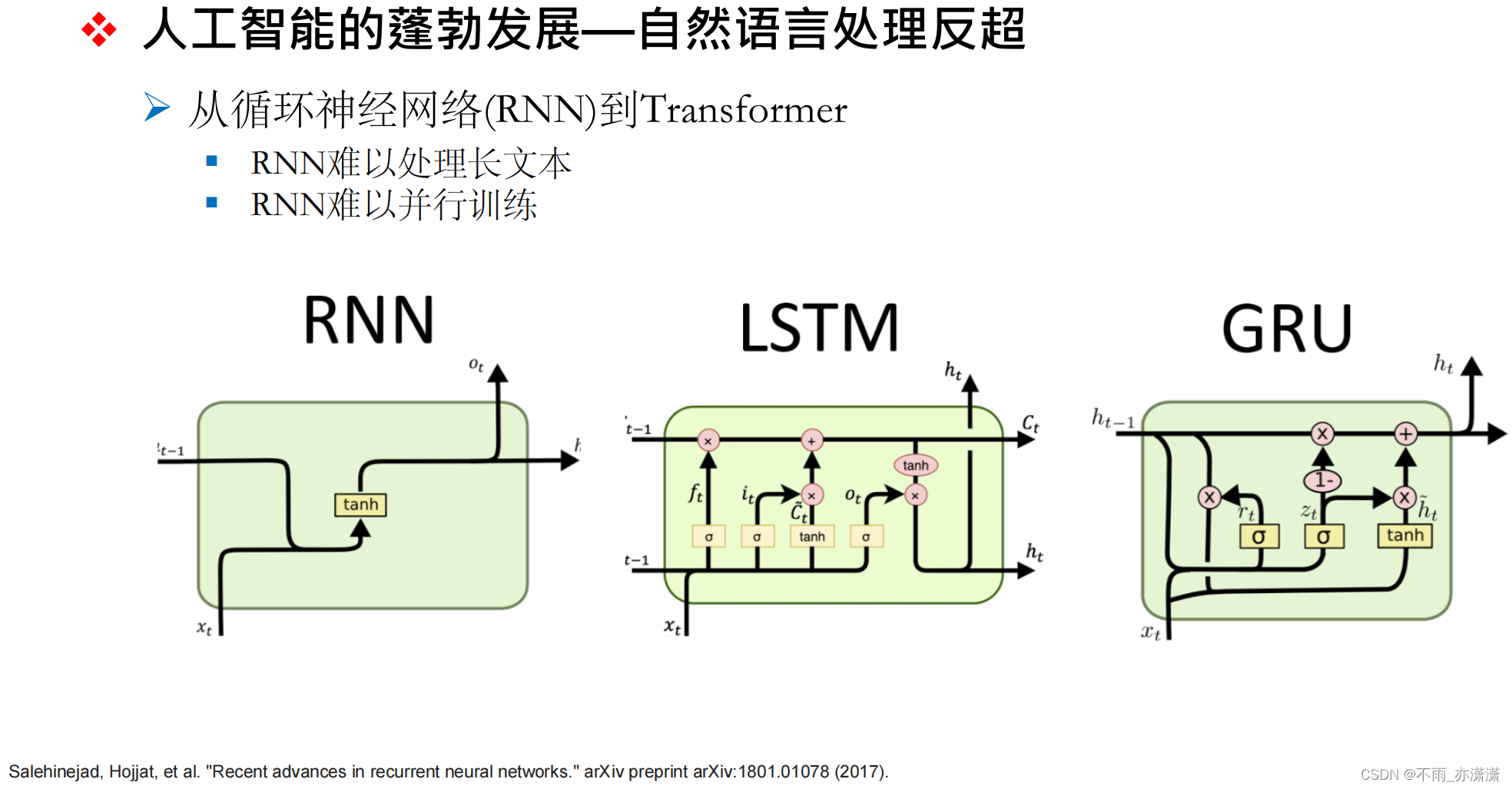
相比于计算机视觉,自然语言处理领域的发展稍微滞后,这是由于处理对象(语言/文本)的特殊性,没有特定规律可循,研究人员针对此提出了RNN、LSTM、GRU等多种模型,但遇到了难以处理长文本,同时不利于并行训练的问题。
NLP的兴起 ⭐️
直到2017年Google提出了Transformer架构,并引入了自注意力机制,NLP的研究才进入了一个新的阶段。由于训练时间缩短,出现不少预训练模型,比如Bert和GPT,两者都是基于Transformer架构的,具体而言,Bert利用了Transformer的Encoder部分,GPT利用了Transformer的Decoder部分。
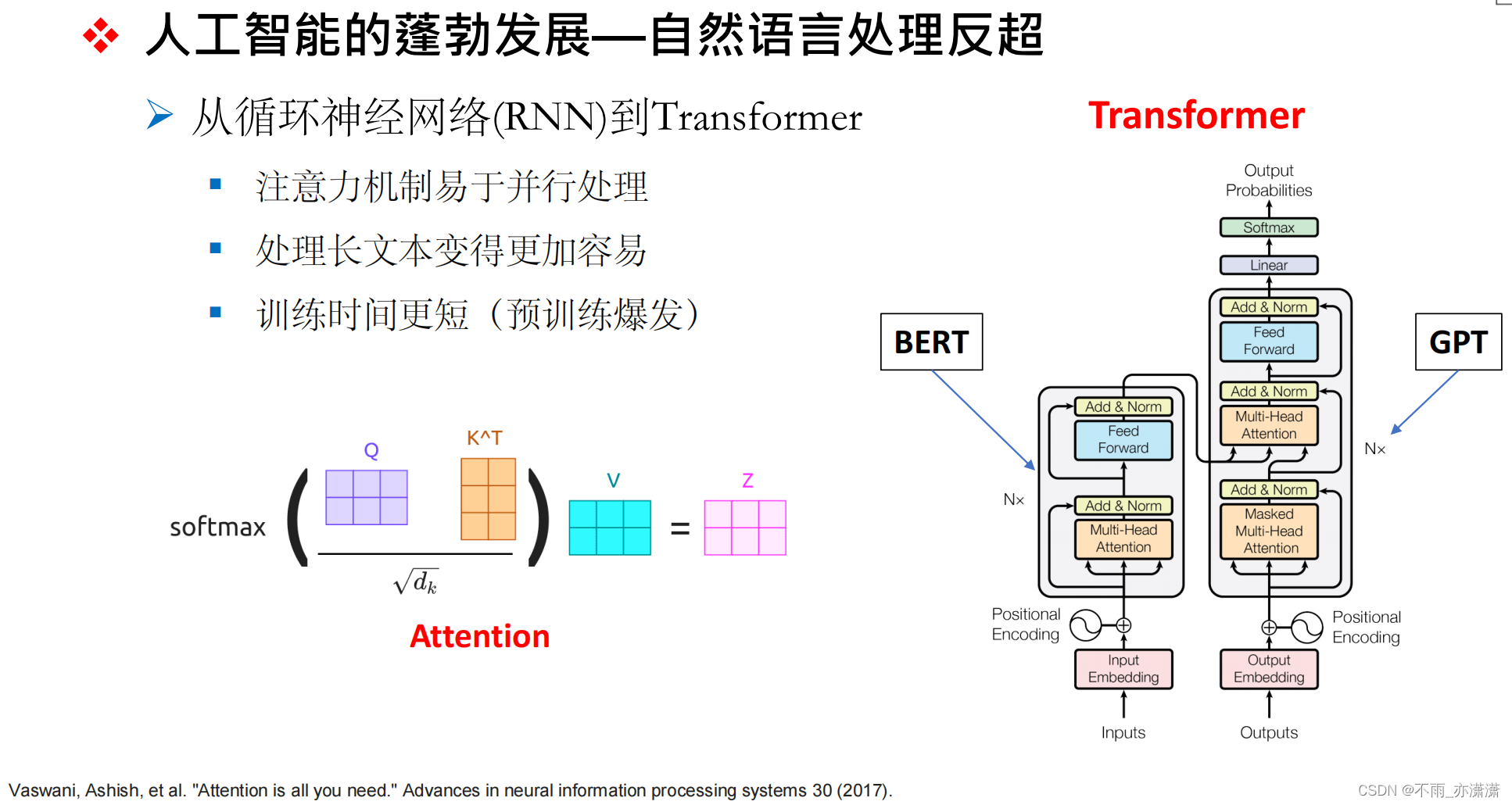
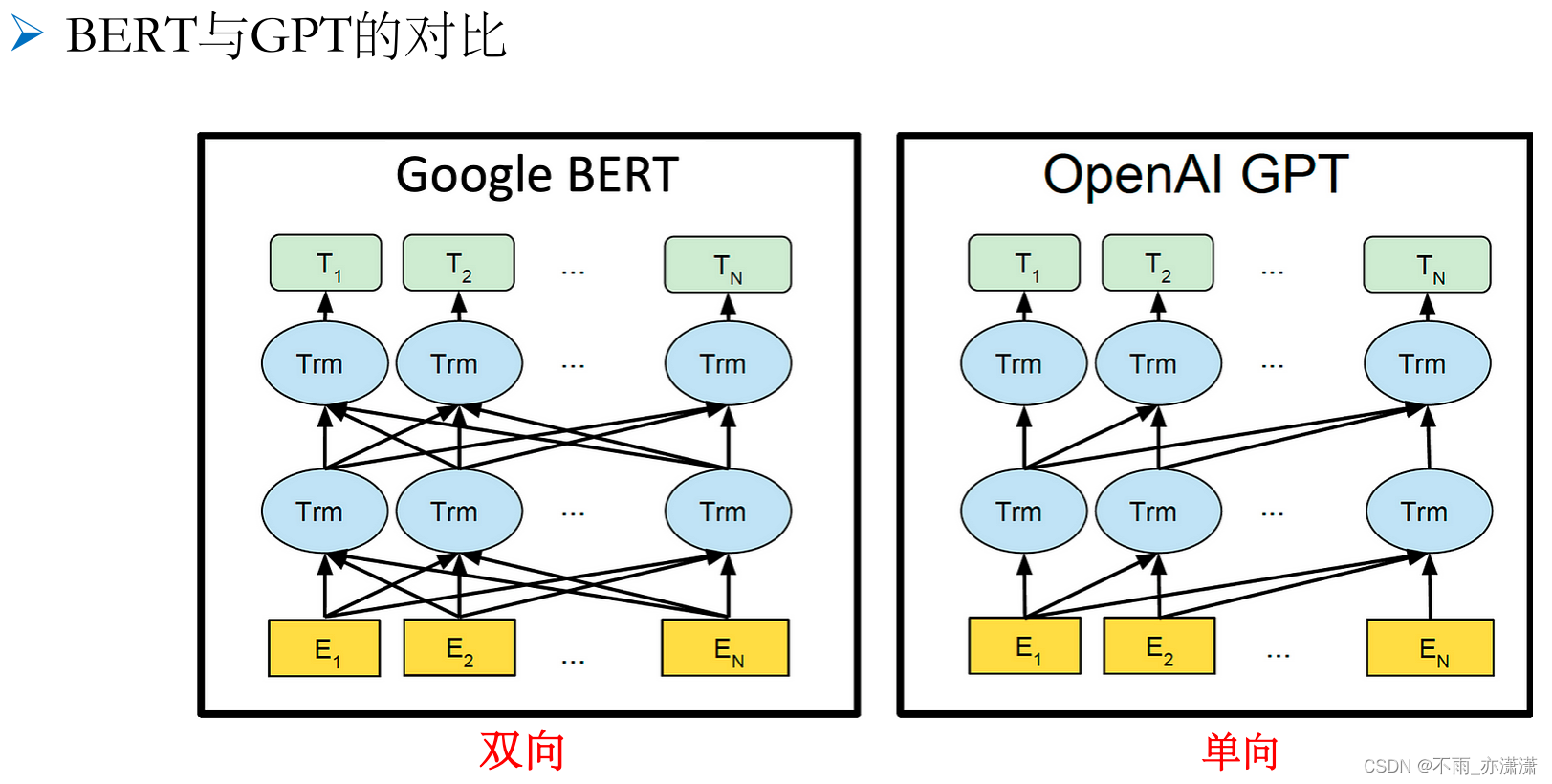
Bert采用了 双向 transformer的结构,它能看到前后的信息,而GPT采用了 单向 transformer的结构,它只能看到前面的信息。
由于结构上的区别,二者的应用也有所不同,Bert侧重于自然语言理解任务,而GPT更适用于自然语言生成任务。
原作者出现了!将会在后面的讲座分享!
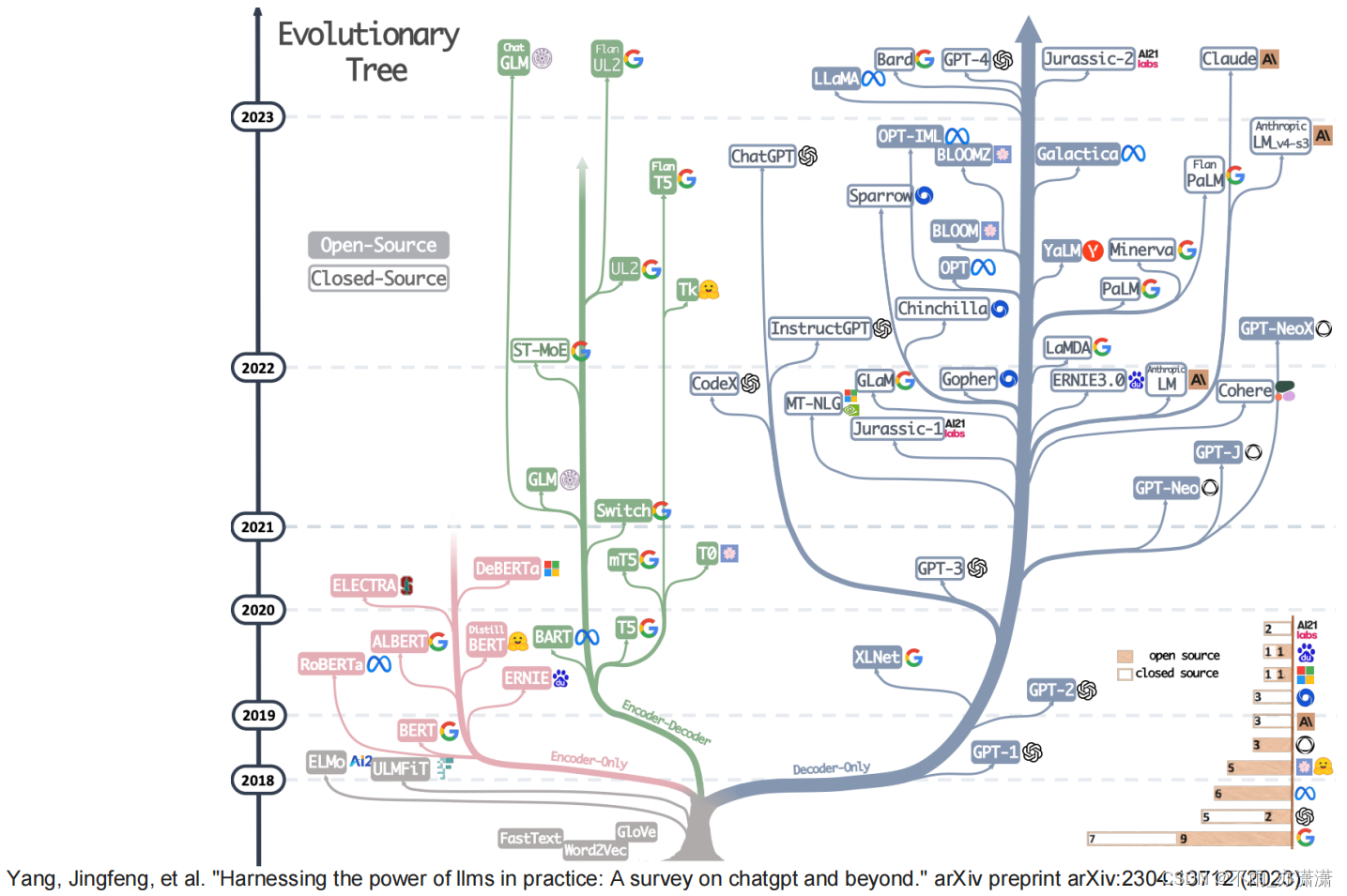
多模态的出现 ⭐️
多模态-数据模态更为多元,包含图像、视频和文本等。
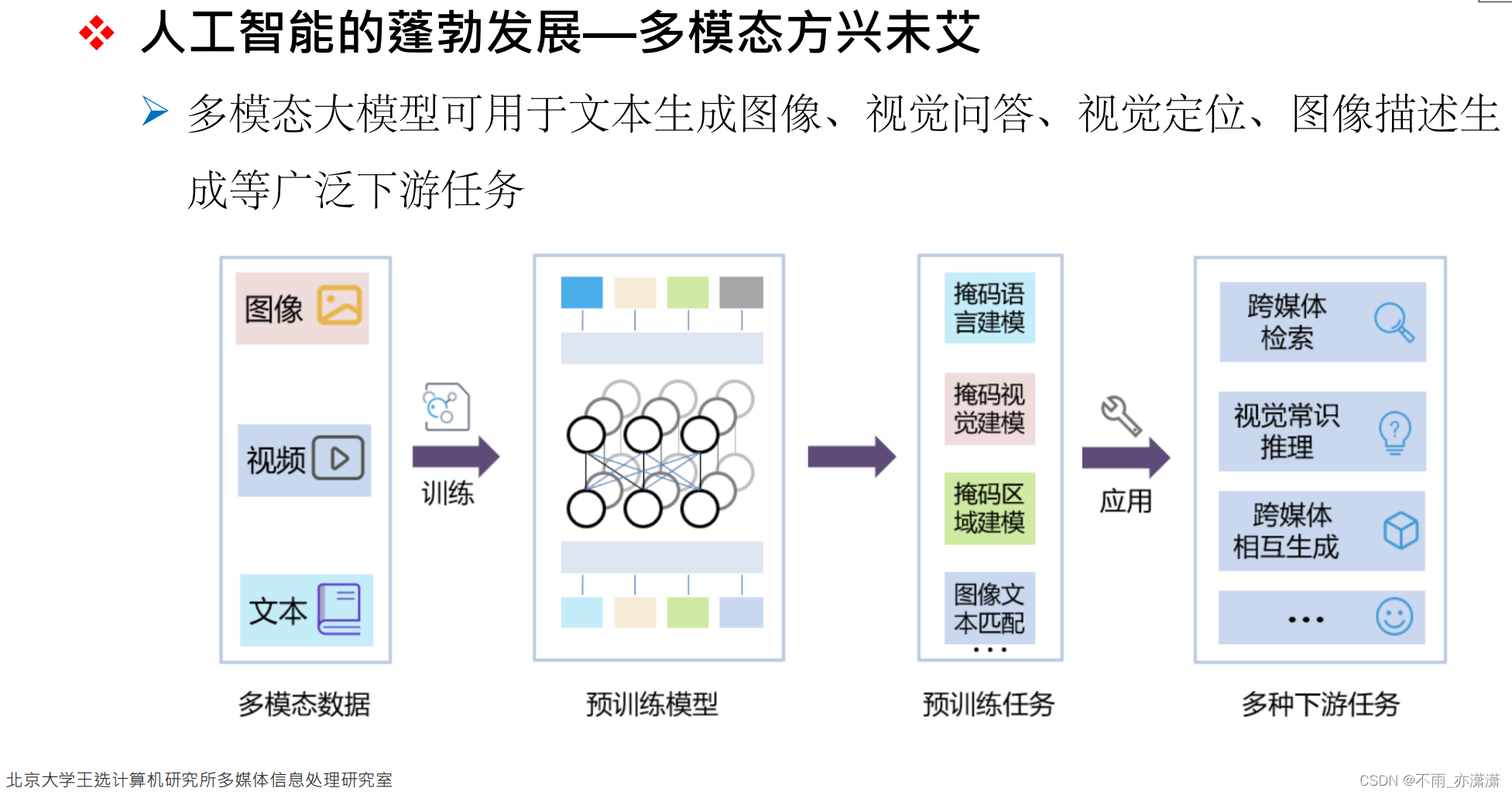
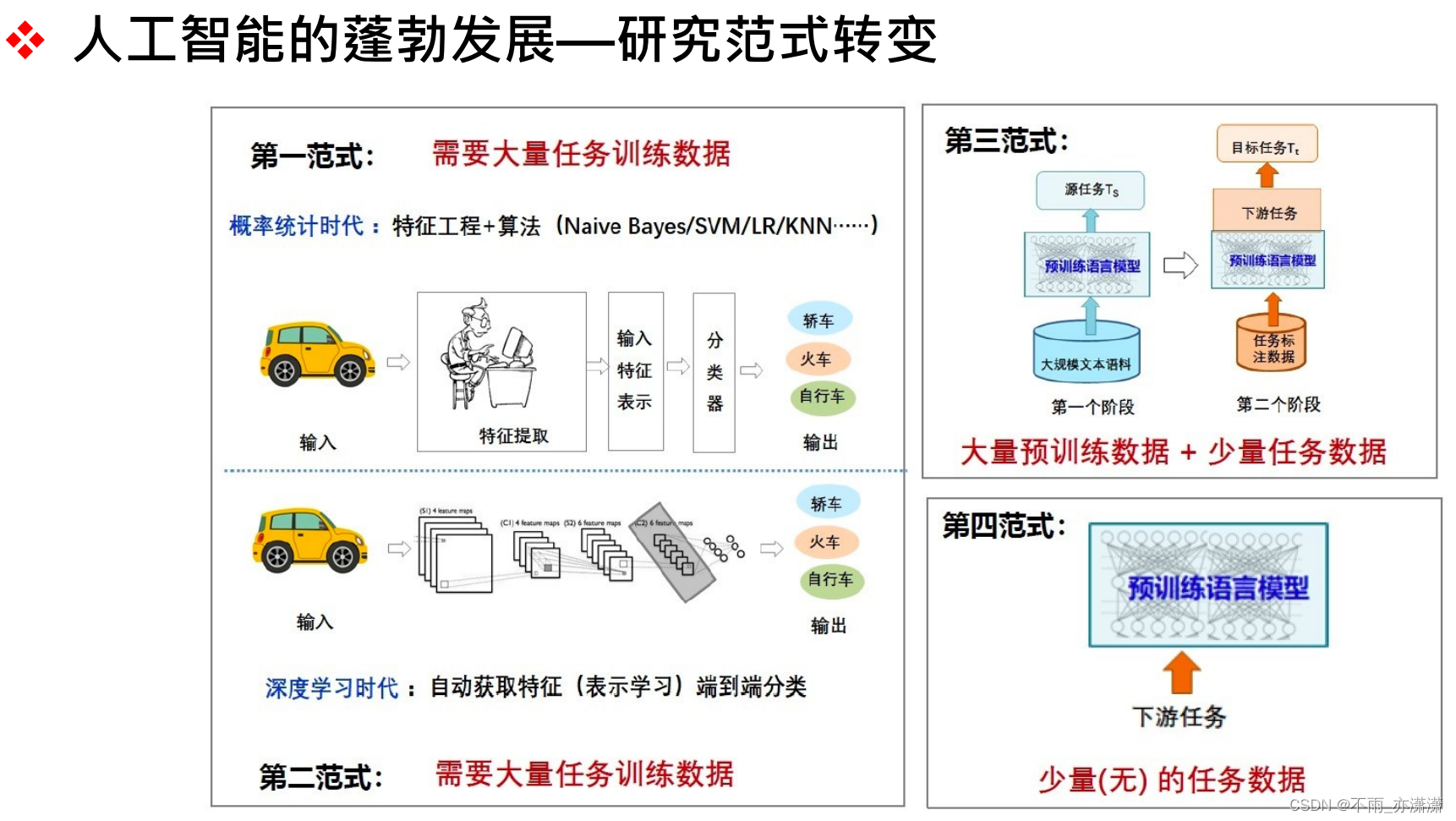
特征工程 > 深度学习(避免人为因素的干扰,但是需要大量的训练数据) > 预训练(大量数据预训练+少量数据微调) > 大模型
2. ChatGPT初探
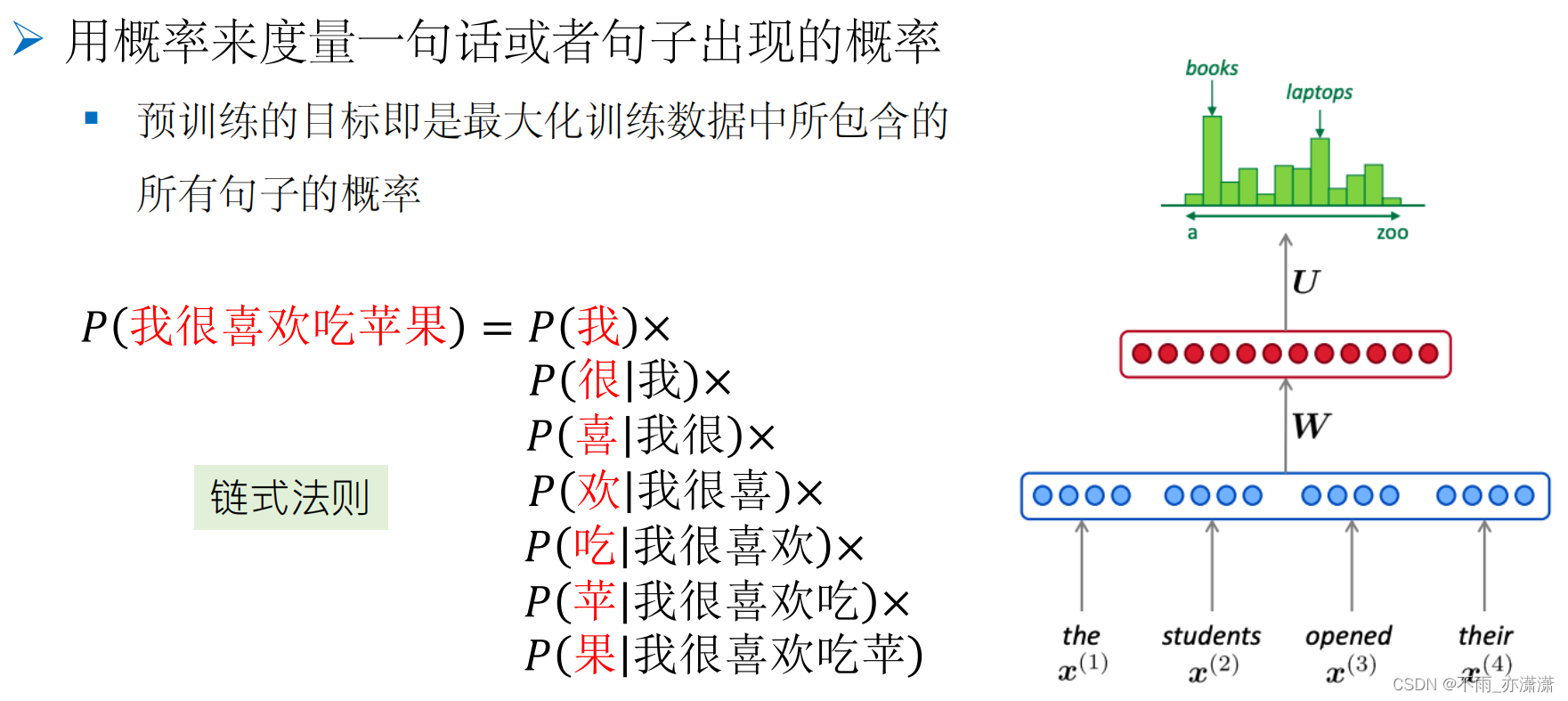
基础技术—语言建模(Language Modeling)
用概率来度量一句话或者句子出现的概率(判断是人说的话的概率)
- 符合特定语言规则或约定俗成的使用习惯的句子的概率更大
- 概率分布跟语种相关
例如:P(我很喜欢吃苹果) > P(我吃苹果很喜欢),即句子“我很喜欢吃苹果”的出现概率比句子“我吃苹果很喜欢”的出现概率大。
预训练的目标即是最大化训练数据中所包含的所有句子的概率。基于链式我们可以把句子的概率拆成每个词的概率,然后把每个词的概率相乘即可。
相比于监督学习,自监督学习无需收集数据的标签。
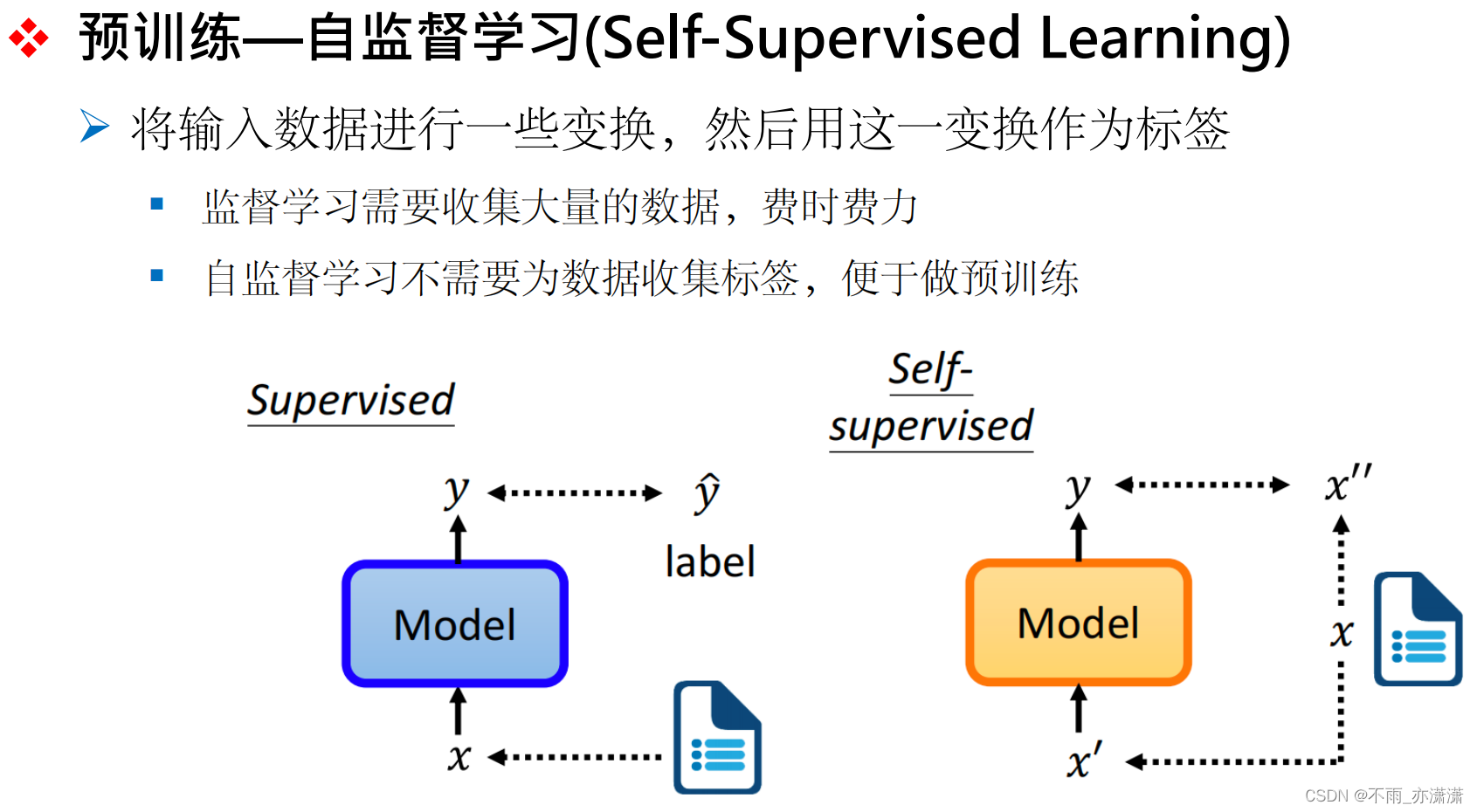
GPT采用自回归,例如:输入“我很喜欢”,预测“吃苹果”;
而Bert属于掩码预训练模型,例如:去掉“吃”这个词,然后预测缺失的“吃”这个词。
GPT只能看到过去的信息,Bert可以看到全部的信息。

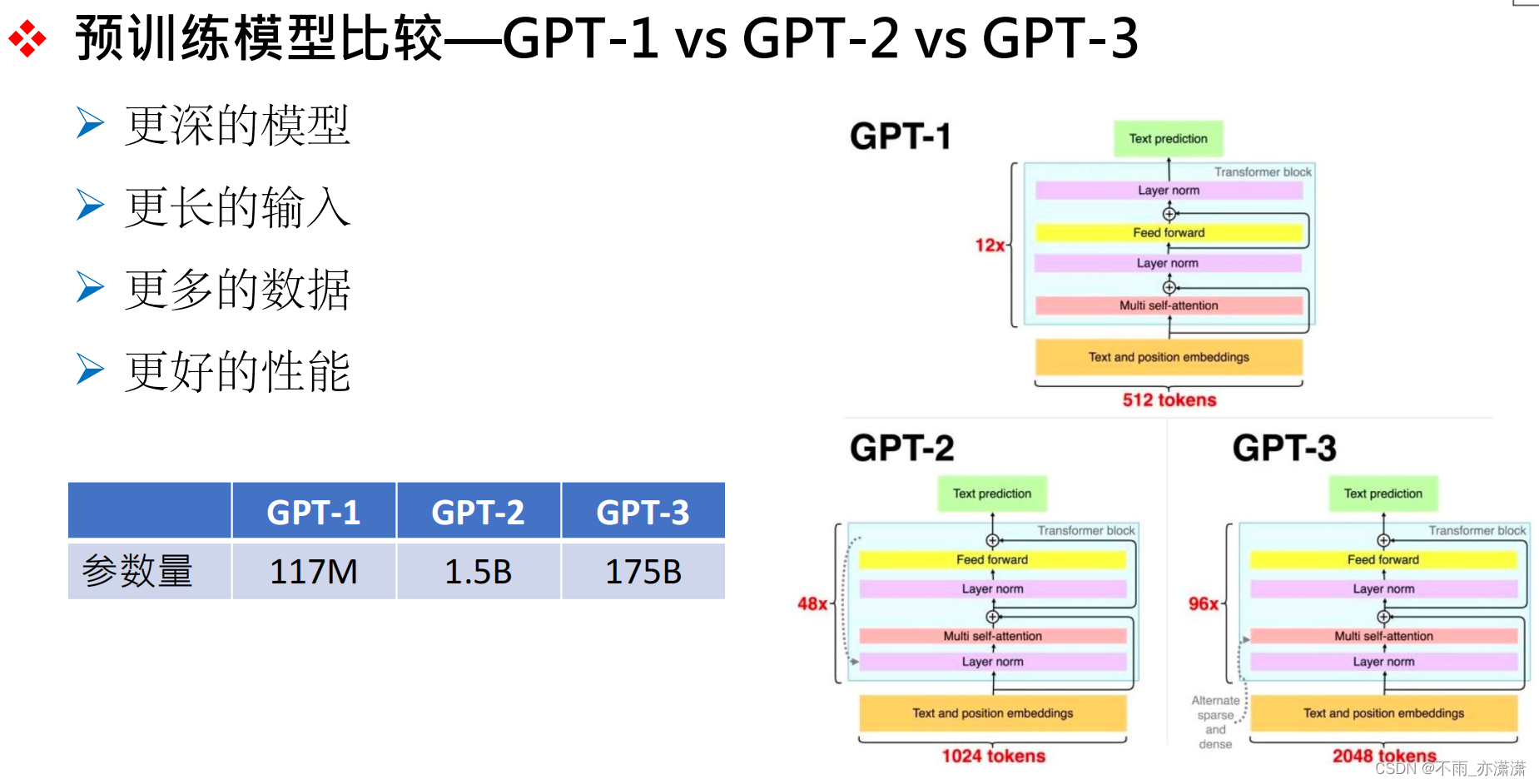
GPT的开发经过了多次迭代,参数量越来越庞大。
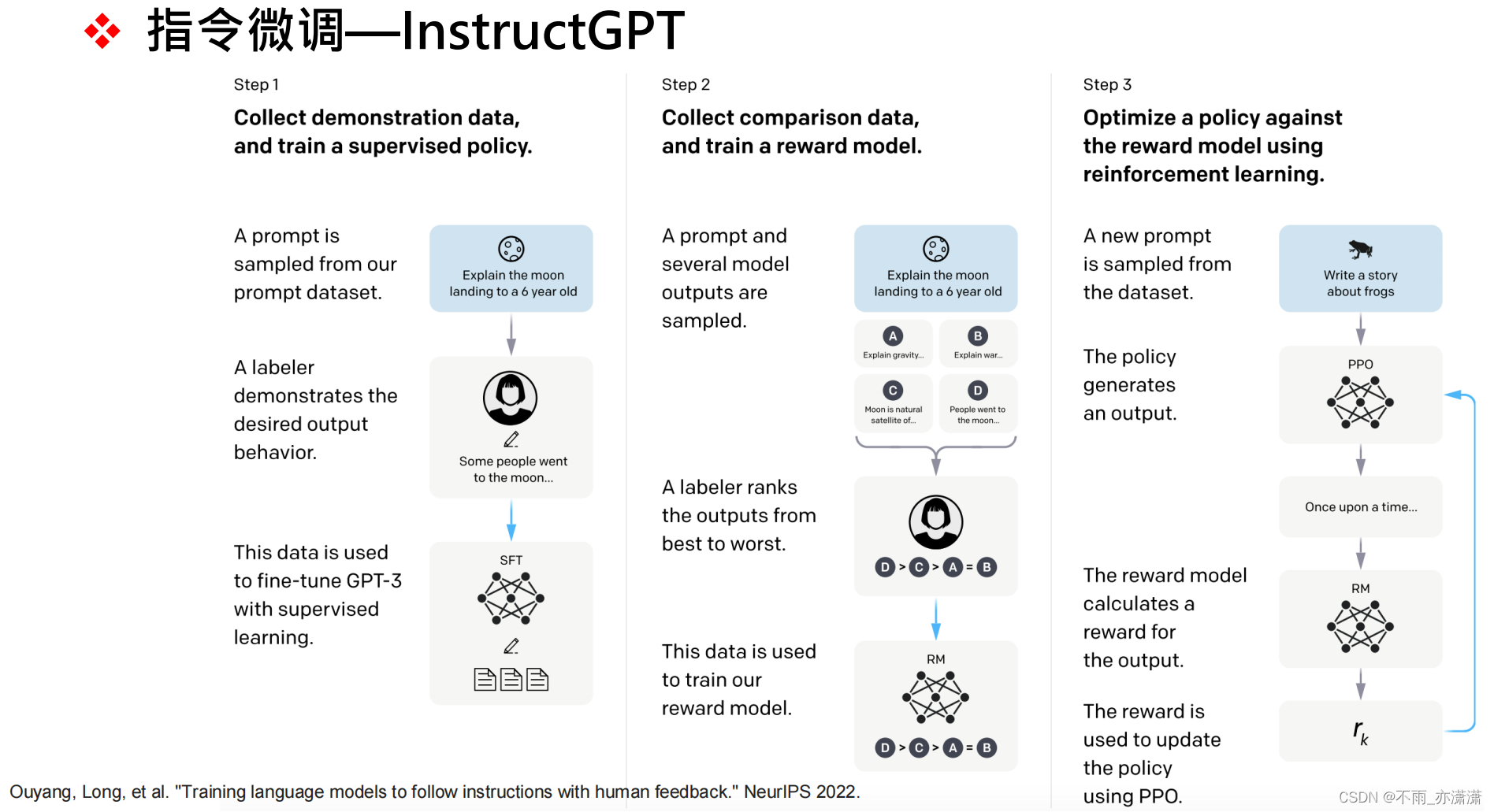
加入指令微调可以使模型与用户需求对齐。

指令微调的步骤:
1️⃣ 收集示例数据(人工完成),进行有监督的微调,形成基础模型
2️⃣ 为了让模型生成更符合人类偏好,对模型输出进行排序,训练奖励模型
3️⃣ 基于奖励模型,利用强化学习对基础模型进行微调
推理能力的提升
提示工程 ⭐️
提示工程(Prompting Engineering)定义:旨在引导和指导人工智能语言模型生成特定类型的输出。其通过设计和调整模型输入中的提示(prompt),以影响模型的行为和生成结果。提示工程的目标是通过精心构造的提示,引导模型更好地理解用户意图,并生成与之一致的回复,从而提高模型的可用性和准确性,使其更适应特定的应用场景和任务。提示工程是一个迭代的过程,需要进行实验和调整,以找到最佳的提示策略,可能涉及尝试不同的提示形式、修改关键词或短语的位置、添加额外的指令或约束条件等。通过不断改进和优化提示工程,可以改善语言模型的表现并满足特定需求。因此,提示工程在语言模型应用中具有重要意义。
两个常用技巧:In-Context Learning 和 Chain-of-Thought
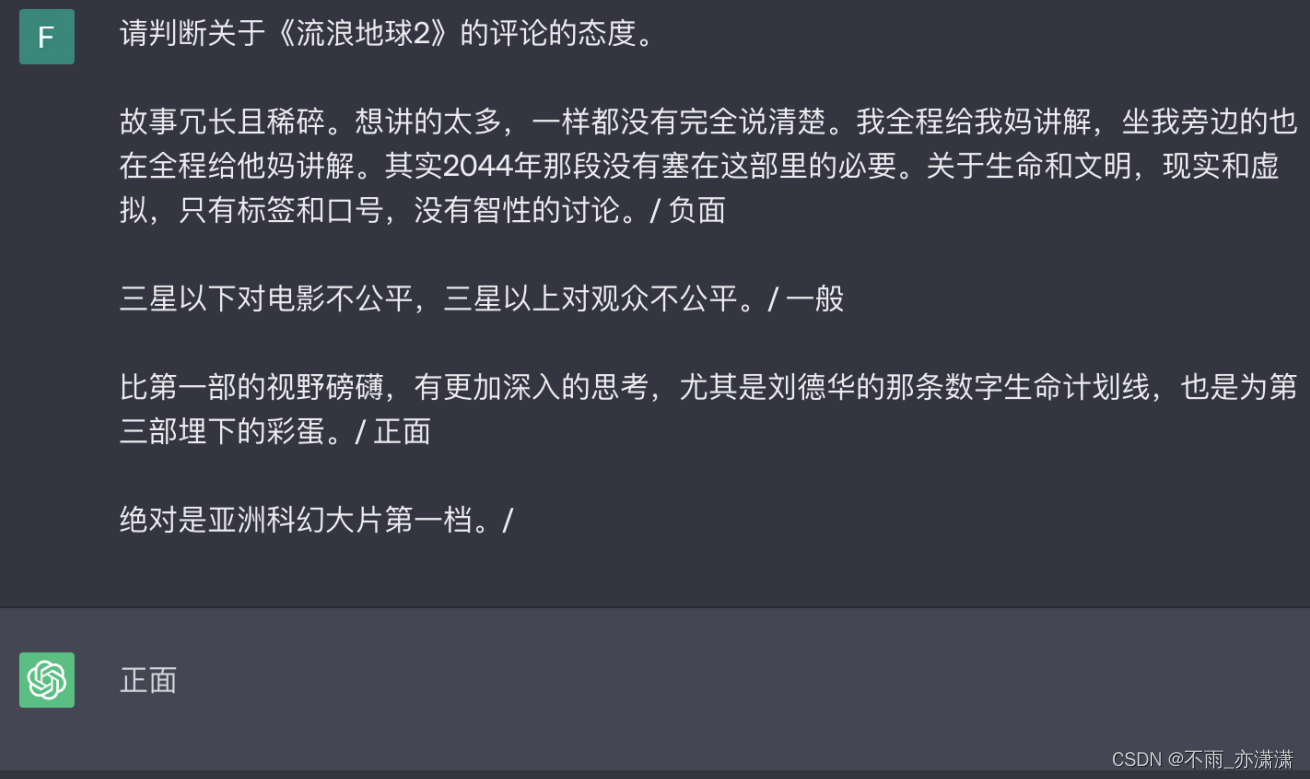
In-Context Learning 提供一些示例。
比如给出一些评论以及态度,然后再给出一条评论时,可以根据示例预测态度。
Chain-of-Thought 清晰展现模型推理的中间过程。
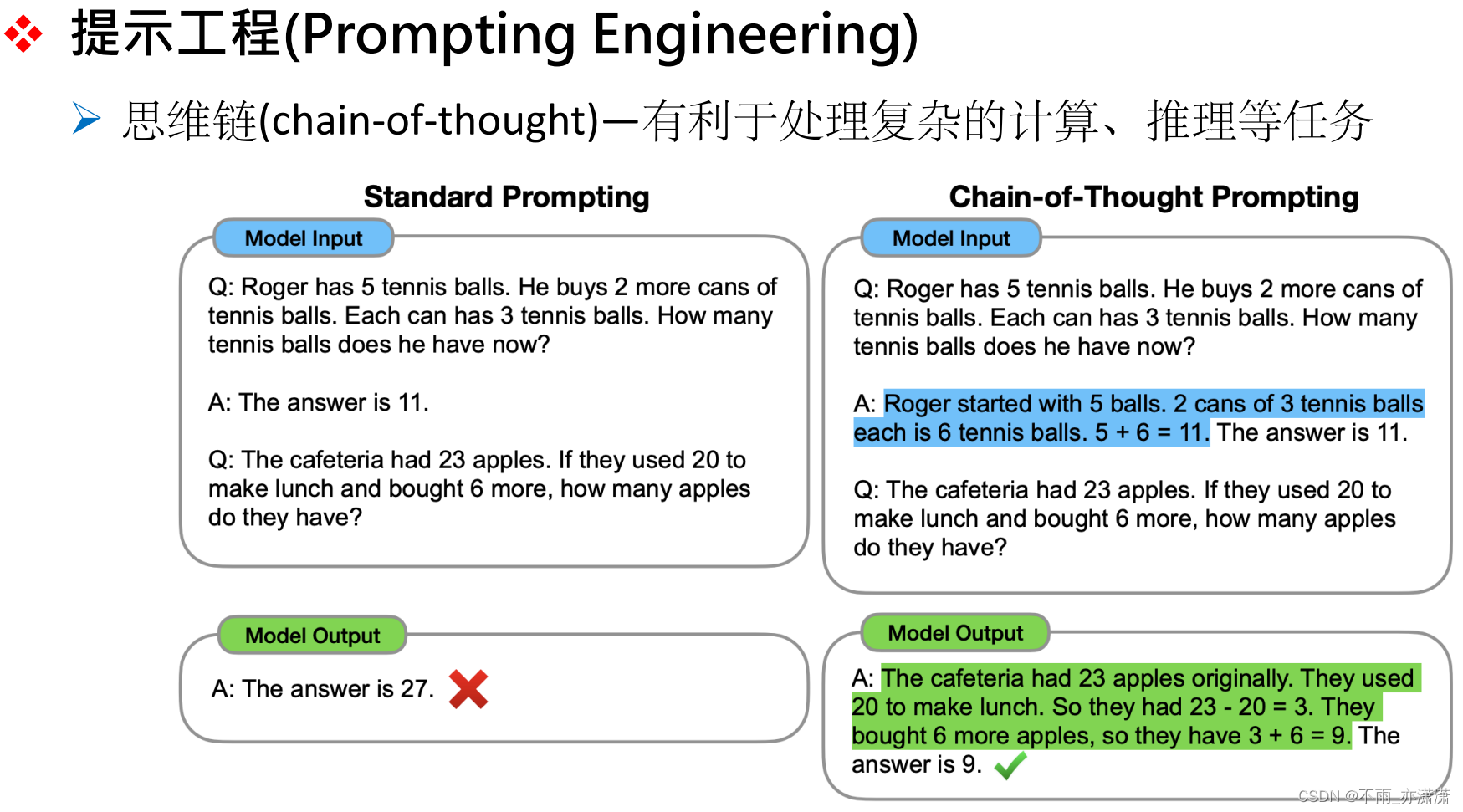
比如对于鸡兔同笼问题,分步计算比直接计算的准确度更高。

GPT-3 & ChatGPT & GPT-4 已经展现出一定程度的智能,那智能从何而来?
智能来源 ⭐️
解释1:压缩
预训练的过程就是训练一个数据压缩器来对大量数据进行压缩,模型则学习一系列的压缩规则。在理想情况下,模型是一个无损的压缩器,对于新的数据进行压缩也是无损的,则说明这个模型具有较好的 泛化能力,即具有智能。
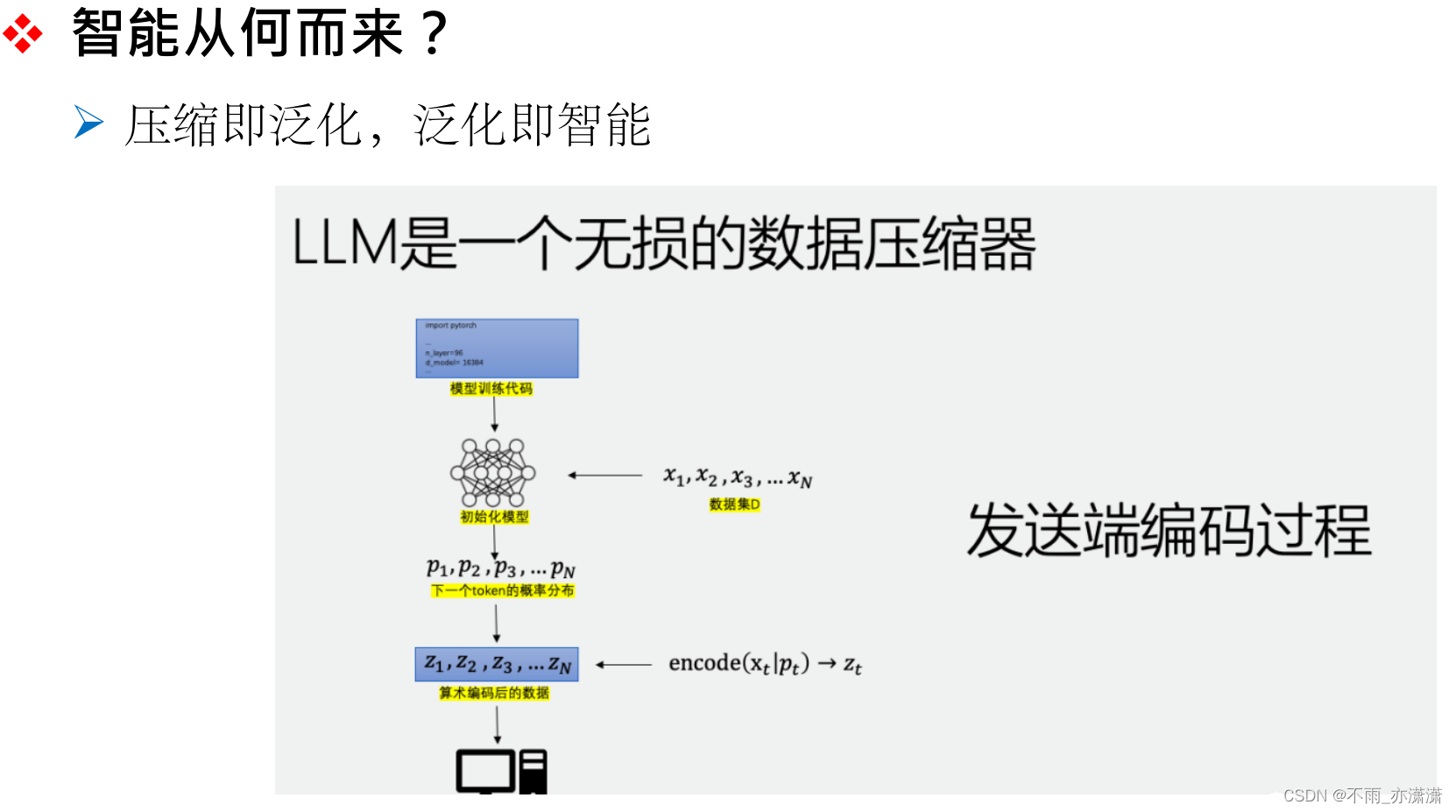
解释2:规模容量

解释3:预测/逻辑推理

总结 ⭐️
- 通过自监督学习在大量无标签数据上进行预训练,训练目标为最大化下一个单词出现的概率;
- 通过增大模型的参数量和训练数据量来提升基础模型的基本能力;
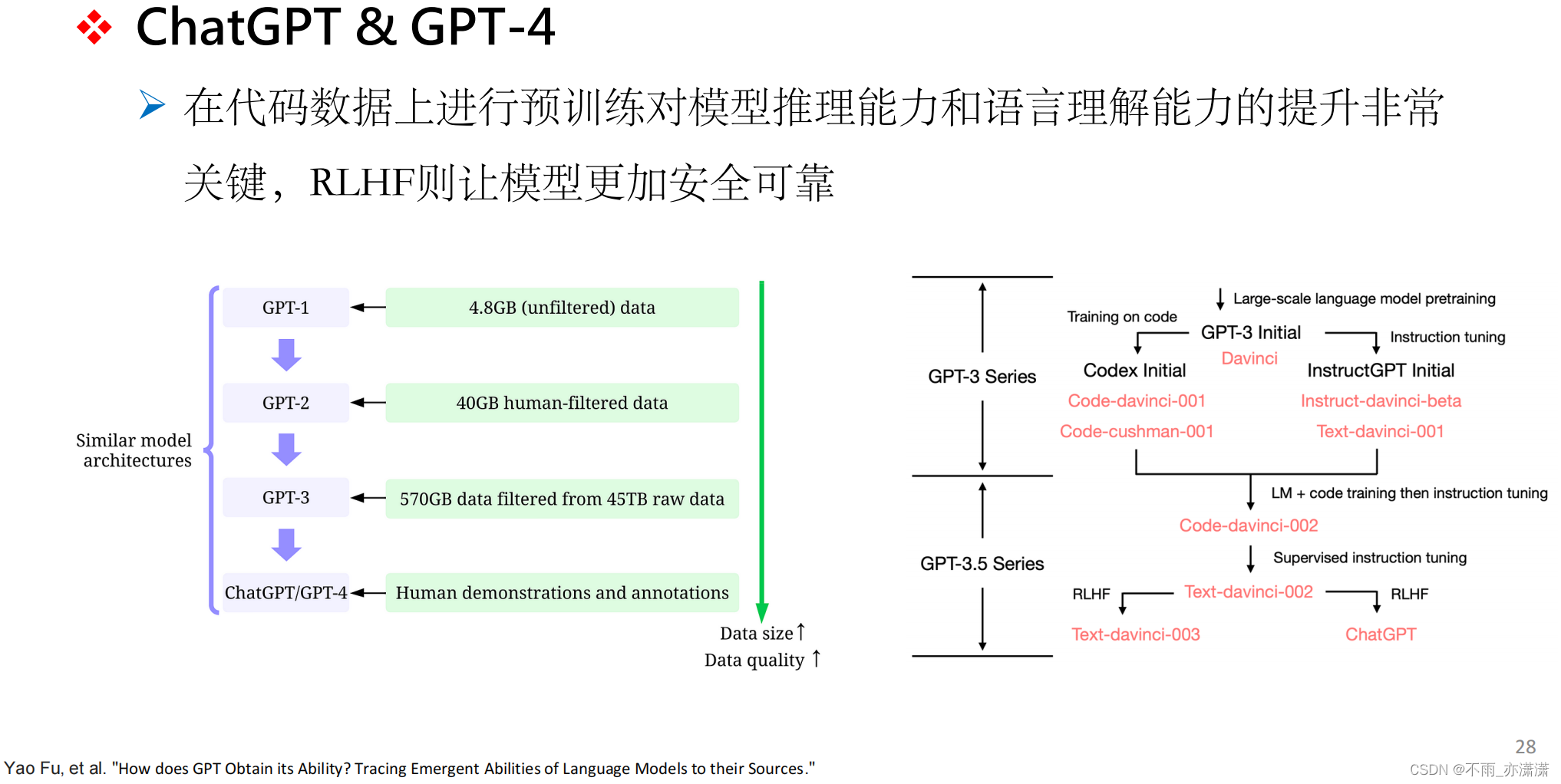
- 融入代码数据进行预训练提升基础模型的推理能力;
- 通过指令微调让基础模型与用户的需求对齐;
- 基于人类反馈的强化学习(RLHF)则进一步让模型生成更加安全可靠的内容;
- 大模型已经具备一定程度的智能。
注意事项:
- 缺乏实时信息;
- 缺乏常识推理;
- 对偏见和歧视的反映;
- 容易出现幻觉(hallucination),不可靠;
- 缺乏判断力,可能给出不合适或不道德的建议。















 34
34











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











