










论文标题:Cooperative LIDAR Object Detection via Feature Sharing in Deep Networks
发表会议/期刊:2020 IEEE 92nd Vehicular Technology Conference (VTC2020-Fall)
问题:由传感和通信系统的固有限制(遮挡和有限的通信带宽)引起的可扩展性和可靠性问题仍然是具有挑战性的问题。自动驾驶汽车系统的安全性取决于感知和inference系统的稳健性。但是,提高传感系统的质量是昂贵的,即使是高质量的LiDAR设备也不能克服遮挡问题。
1 特征共享协同目标检测(FS-COD)
提出了特征共享协同目标检测(FS-COD)框架来缓解车载传感器和通信带宽限制的影响,通过在配备LiDAR的合作车辆之间共享部分处理过的数据(特征)来改善目标检测表现。具体来说,通过调整Complex-yolo中提出的网络结构和YOLO中的损失函数设计了一个CNN目标检测器(其他基于CNN的目标检测方法也可以只需稍作修改即可在所提出的方案中使用)。
FS-COD结构
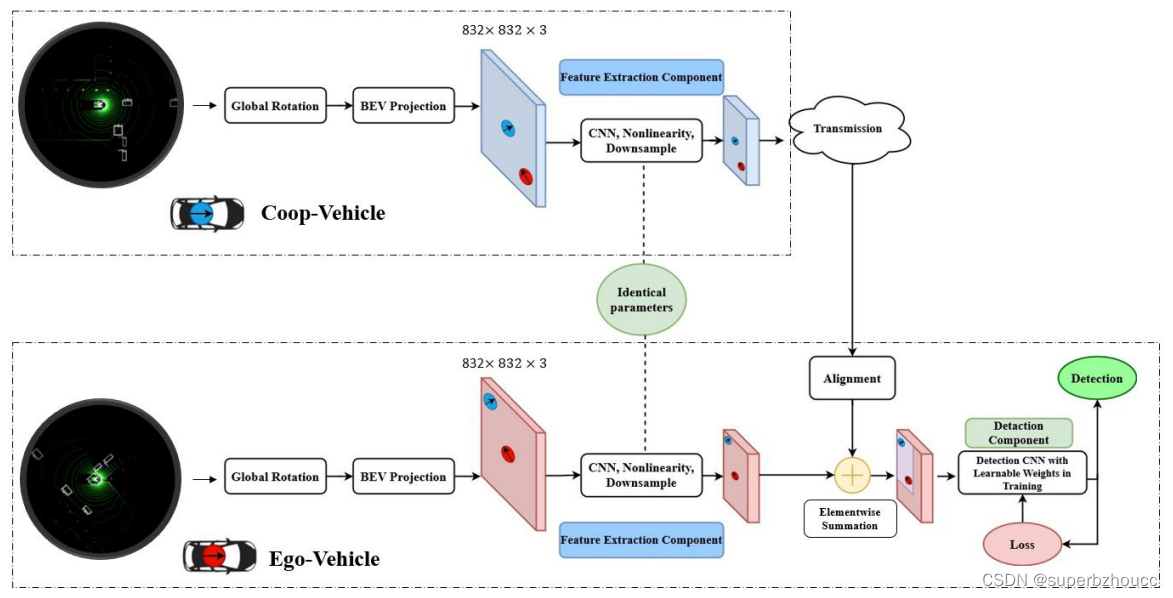
每个参与合作的车辆的FS-COD架构包含BEV投影、特征提取、特征融合和目标检测模块,以及一个空间对齐模块。
1) 将车辆LiDAR设备获得的点云和车辆的航向与全局坐标系对齐。
2) BEV投影单元将空间对齐后的LiDAR点云投影到二维图像平面上。与Complex-yolo的投影方法不同的是,本文的BEV图像有3个通道,每个通道提供在3个不同高度范围内的反射点密度。3个高度范围被定义为[-∞, 2m], [2m, 4m]和[4m, ∞]。
3) BEV图传给特征提取网络以获得周围环境的特征图。
4) 产生的特征图与车辆的GPS信息一起传送给合作车辆。特征提取器最后一层的filters数量决定了在合作车辆之间共享数据的大小。因此,通过调整最后一个卷积层的过滤器,可以满足带宽要求。
5) 自车收到的合作车辆的特征图后,将其与自车的坐标系对齐,并与自车的特征图相加,通过对自车和合作车辆的特征图进行元素相加来进行特征融合。
6) 得到的融合特征图传给目标检测CNN模块以检测环境中的目标。
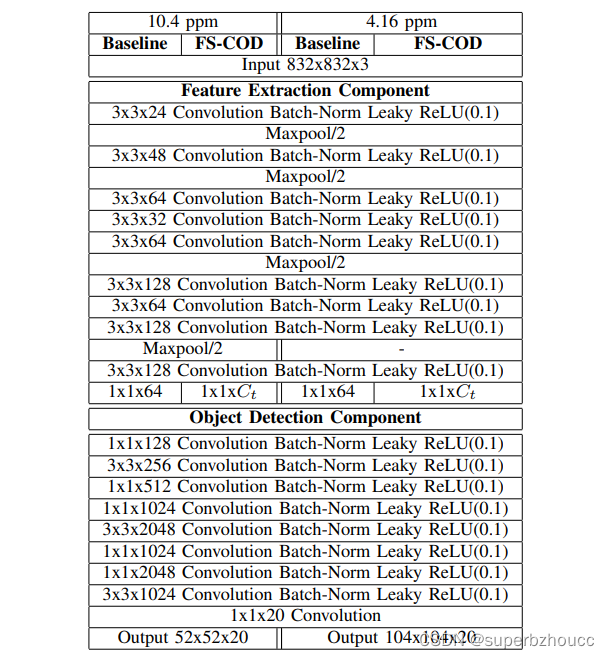
特征提取器CNN的结构、目标检测模块的结构:
2 实验和结果
2.1 数据收集和模拟
为了测试所提出的方法的性能,在CARLA的基础上开发了一个名为Volony的数据集收集工具,用户可以收集从合作车辆同时获得的RGBD图像和LiDAR点云数据等测量数据、物体的边界框信息、标签和车辆的GPS信息。
为了证明图像分辨率对FS-COD性能的影响,从模拟器上收集了两个不同的数据集。在第一个中,车辆配备了40米范围的激光雷达设备,在第二个数据集中,范围增加到100米。在这两种情况下,由BEV投影产生的二维图像的大小被固定为832×832像素。因此,图像分辨率分别为10.4ppm和4.16ppm。 对于这两种分辨率,数据集分别由5000和1000个捕获的时间帧组成,用于训练和验证。
在城市地区的CARLA模拟器中,从激光雷达设备捕获的点云与相应的BEV图像和RGB摄像机图像: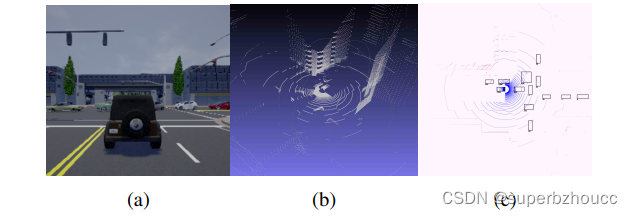
3 结论和未来的工作
提出了一个基于特征融合的协同目标检测方法(FS-COD),通过共享从LiDAR点云数据中提取的特征来有效地压缩和编码相关信息,缓解了遮挡和通信带宽的限制, 利用BEV图的特性修改了Complex-YOLO CNN的主干结构,可以在保持目标检测精度的同时减少带宽消耗。
局限:
假设从自车和其他合作车辆获得的信息具有相同的重要程度。















 1537
1537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









