






参考:
最强攻略5:史上最全转录因子数据库汇总解读 - 知乎 (zhihu.com) https://zhuanlan.zhihu.com/p/343884679
https://zhuanlan.zhihu.com/p/343884679
1. Cistrome DB
| 人 + 小鼠 |
| 侧重于ChIP-seq和DNase-seq 的分析结果 |
| Cistrome DB |
收录了30451人和26013小鼠的TFs、组蛋白修饰和染色质可及性 样本,是迄今为止经整理和分析ChIP-seq 和 DNase-seq 数据最全面的数据库。使用统一的pipeline对其进行处理,并展示了每个样本的分析结果。
可在Cistrome DB查看转录因子调控的基因,详细的数据注释、分析结果和单个数据集的详细信息(数据的QC情况、motif分析结果、潜在的靶基因预测)、同时还可以在基因组浏览器中查看数据的分布及下载分析的结果文件。
2. dbCoRC
| 人 + 小鼠 |
| H3K27ac ChIP-seq ---增强子 |
| http://dbcorc.cam-su.org/ |
CRC:Core transcriptional Regulatory Circuitries
全面的交互式CRC数据库
基于H3K27ac ChIP-Seq数据的计算分析,包含来自188个人类和50个鼠类样本的CRC模型。利用该数据库,可以获得单个样品的超级增强子(SE)、增强子和H3K27ac景观、CRC内SE区中每个核心转录因子(TF)的假定结合位点。
3. TRRUST
| 人 + 小鼠 |
| 人工注释,TF-target、TF-TF |
| http://www.grnpedia.org/trrust/ |
800个人类TF和828个小鼠TF的8,444和6,552个TF-target调节关系
4. TFtarget
| 人 |
| 来自ChIP-seq的 TF-target调控 |
| http://bioinfo.life.hust.edu.cn |
hTFtarget has curated comprehensive TF-target regulations from large-scale of ChIP-Seq data of human TFs (7,190 experiment samples of 659 TFs) in 569 conditions (399 types of cell line, 129 classes of tissues or cells, and 141 kinds of treatments).
所有的 ChIP-Seq 数据都来自 NCBI GEO、NCBI SRA 和 ENCODE 数据库等公共资源。
TFBS的位置权重矩阵(PWM)来自TRANSFAC、JASPAR和HOCOMOCO数据库,包含699个TFs的2737个TFBS主题。

功能有:1) 浏览和研究给定转录因子的靶基因;
2) 探索哪些转录因子可以调控给定基因;
3) 调查给定转录因子的公共 ChIP-Seq 样本;
4) 以用户定义的方式查看查询 TF 的峰值;
5) 调查所选细胞系中 TF 之间的潜在共轭关系;
6) 查询 TFs 对查询基因的候选共调作用;
7) 预测 TF 在给定序列上的结合位点。
5. TransmiR
| 19种生物 |
| 收集TF-microRNA 调控关系 |
| http://www.cuilab.cn/transmir |
涵盖约623个TF,约785个miRNA,19种生物和1,349种出版物。还有5个物种通过ChIP-seq证据得到的1,785,998 TF-miRNA信息 及相关注释。
6. JASPAR
| 脊椎动物、植物、昆虫、线虫、真菌和尾索动物六大类不同类生物 |
| 收录TF-motif |
| http://jaspar.genereg.net/ |
收集转录因子与DNA结合位点以及结合方式
7. HOCOMOCO
| 人 + 小鼠 |
| ChIP-seq实验中获得的,PWM |
| https://hocomoco11.autosome.ru/ |
TF的binding motif,PWM
8. footprintDB
| 现有数据库中的所有物种 |
| 根据搜集到的数据 有效识别(/预测)TF与DNA之间的结合关系 |
| http://floresta.eead.csic.es/footprintdb/index.php |
定期从公共数据库和文献中收集TFs,整合了JASPAR/HOMOCOMO/Human TF等多个数据库的TF、DNA-binding motifs和DNA-binding sites 数据。
预测与特定DNA site或motif结合的TF;预测可能被DNA-binding 蛋白质识别的DNA motifs 或sites。
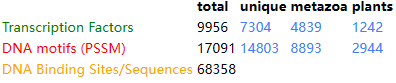
9. AnimalTFDB
| 183个物种 |
| TF与转录辅因子 的DBD、结合位点等多种信息 |
| AnimalTFDB4 (wchscu.cn) |
有经过鉴定、分类和注释的97个物种全基因组水平的125,135个TF基因和80,060个转录辅因子基因。根据DBD 对 TF和辅因子进行功能分类。提供多种搜索预览方式,2个在线预测工具Predict TF和Predict TFBS(分别可以批量预测TF和预测DNA序列上的TF结合位点)、Blast工具和数据下载功能。
10. KnockTF
| 人 |
| TF敲除前后的基因表达谱 |
| http://www.licpathway.net/KnockTF/ |
提供了大量与转录因子敲降/敲除相关的人类基因表达谱数据集、转录因子及其靶基因的注释信息、转录因子的上游通路信息和下游靶基因的功能注释信息,以及转录因子结合到靶基因启动子、增强子和超级增强子的详细结合信息。
另外:
Joung J, Ma S, Tay T, Geiger-Schuller KR, Kirchgatterer PC, Verdine VK, Guo B, Arias-Garcia MA, Allen WE, Singh A, Kuksenko O, Abudayyeh OO, Gootenberg JS, Fu Z, Macrae RK, Buenrostro JD, Regev A, Zhang F. A transcription factor atlas of directed differentiation. Cell. 2023 Jan 5;186(1):209-229.e26. doi: 10.1016/j.cell.2022.11.026. PMID: 36608654; PMCID: PMC10344468.
也是通过文献手工查询并总结的1836 TF,只包含了这些基因名称等信息,网站没找到
创建了一个涵盖了人类所有TF异构亚型(1836 TF genes encoded by 3548 splice isoforms)的条形码文库,并将其用于构建TF图谱(TF Atlas),以单细胞分辨率绘制了每个TF过表达在人类胚胎干细胞(110万个hESCs)中引起的表达谱变化。该TF Atlas既可以系统的识别 驱动细胞状态改变 的TF,也可以对TF分类,还可以用来预测和验证不同TF组合对细胞的影响。

















 1221
1221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









