







注意:本文章有很多图,但是都是YOLOv3的结构图,只是每张图表达出的信息都各有特色,可将这些结构图结合起来,能更好的理解。
1.Darknet-53 模型结构
在论文中虽然有给网络的图,但我还是简单说一下。这个网络主要是由一系列的1x1和3x3的卷积层组成(每个卷积层后都会跟一个BN层和一个LeakyReLU)层,作者说因为网络中有53个convolutional layers,所以叫做Darknet-53(2 + 12 + 1 + 22 + 1 + 82 + 1 + 82 + 1 + 4*2 + 1 = 53 按照顺序数,不包括Residual中的卷积层,最后的Connected是全连接层也算卷积层,一共53个)。下图就是Darknet-53的结构图,在右侧标注了一些信息方便理解。(卷积的strides默认为(1,1),padding默认为same,当strides为(2,2)时padding为valid)
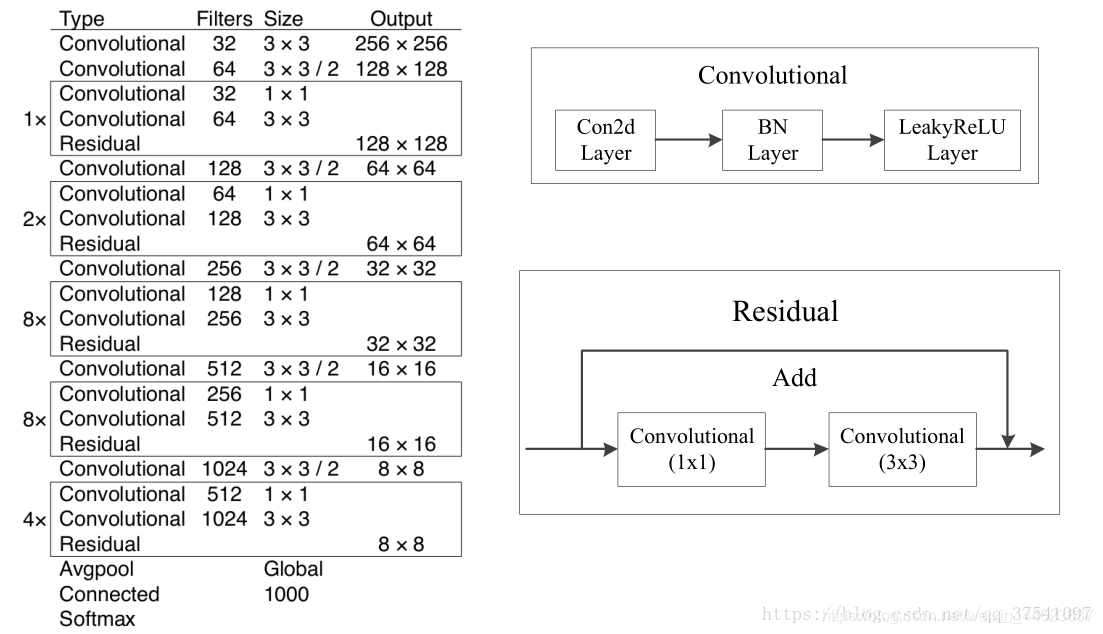
看完上图应该就能自己搭建出Darknet-53的网络结构了,上图是以输入图像256 x 256进行预训练来进行介绍的,常用的尺寸是416 x 416,都是32的倍数。下面我们再来分析下YOLOv3的特征提取器,看看究竟是在哪几层Features上做的预测。
YOLOv3模型结构
作者在论文中提到利用三个特征层进行边框的预测,具体在哪三层我感觉作者在论文中表述的并不清楚。Darknet-53是yolov3的前置网络,yolov3在Darknet-53的基础上进一步抽象和融合后才得到三个预测特征层。
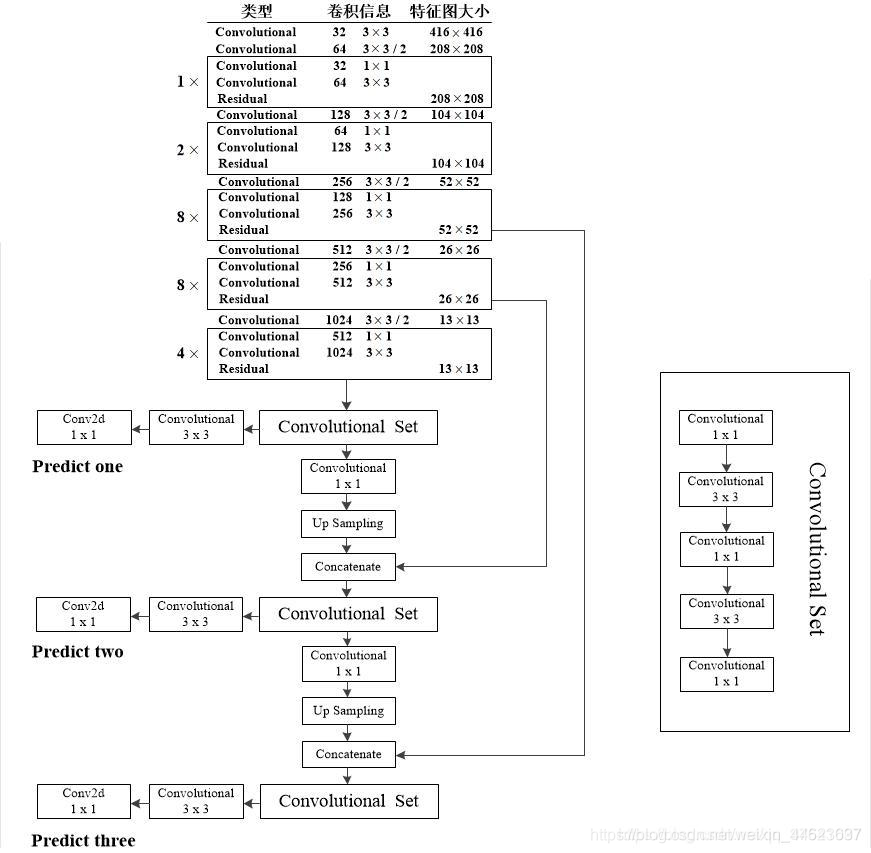
在上图中我们能够很清晰的看到三个预测层分别来自的什么地方,以及Concatenate层与哪个层进行拼接。注意Convolutional是指Conv2d+BN+LeakyReLU,和Darknet53图中的一样,而生成预测结果的最后三层都只是Conv2d。通过上图就能更加容易地搭建出YOLOv3的网络框架了。
yolo输出时的显示:
layer filters size input output
0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BF
1 conv 64 3 x 3 / 2 416 x 416 x 32 -> 208 x 208 x 64 1.595 BF
2 conv 32 1 x 1 / 1 208 x 208 x 64 -> 208 x 208 x 32 0.177 BF
3 conv 64 3 x 3 / 1 208 x 208 x 32 -> 208 x 208 x 64 1.595 BF
4 Shortcut Layer: 1
5 conv 128 3 x 3 / 2 208 x 208 x 64 -> 104 x 104 x 128 1.595 BF
6 conv 64 1 x 1 / 1 104 x 104 x 128 -> 104 x 104 x 64 0.177 BF
7 conv 128 3 x 3 / 1 104 x 104 x 64 -> 104 x 104 x 128 1.595 BF
8 Shortcut Layer: 5
9 conv 64 1 x 1 / 1 104 x 104 x 128 -> 104 x 104 x 64 0.177 BF
10 conv 128 3 x 3 / 1 104 x 104 x 64 -> 104 x 104 x 128 1.595 BF
11 Shortcut Layer: 8
12 conv 256 3 x 3 / 2 104 x 104 x 128 -> 52 x 52 x 256 1.595 BF
13 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BF
14 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BF
15 Shortcut Layer: 12
16 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BF
17 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BF
18 Shortcut Layer: 15
19 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BF
20 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BF
21 Shortcut Layer: 18
22 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BF
23 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BF
24 Shortcut Layer: 21
25 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BF
26 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BF
27 Shortcut Layer: 24
28 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BF
29 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BF
30 Shortcut Layer: 27
31 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BF
32 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BF
33 Shortcut Layer: 30
34 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BF
35 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BF
36 Shortcut Layer: 33
37 conv 512 3 x 3 / 2 52 x 52 x 256 -> 26 x 26 x 512 1.595 BF
38 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BF
39 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BF
40 Shortcut Layer: 37
41 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BF
42 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BF
43 Shortcut Layer: 40
44 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BF
45 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BF
46 Shortcut Layer: 43
47 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BF
48 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BF
49 Shortcut Layer: 46
50 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BF
51 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BF
52 Shortcut Layer: 49
53 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BF
54 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BF
55 Shortcut Layer: 52
56 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BF
57 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BF
58 Shortcut Layer: 55
59 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BF
60 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BF
61 Shortcut Layer: 58
62 conv 1024 3 x 3 / 2 26 x 26 x 512 -> 13 x 13 x1024 1.595 BF
63 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BF
64 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BF
65 Shortcut Layer: 62
66 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BF
67 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BF
68 Shortcut Layer: 65
69 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BF
70 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BF
71 Shortcut Layer: 68
72 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BF
73 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BF
74 Shortcut Layer: 71
75 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BF
76 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BF
77 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BF
78 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BF
79 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BF
80 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BF
81 conv 18 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 18 0.006 BF
82 yolo
83 route 79
84 conv 256 1 x 1 / 1 13 x 13 x 512 -> 13 x 13 x 256 0.044 BF
85 upsample 2x 13 x 13 x 256 -> 26 x 26 x 256
86 route 85 61
87 conv 256 1 x 1 / 1 26 x 26 x 768 -> 26 x 26 x 256 0.266 BF
88 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BF
89 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BF
90 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BF
91 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BF
92 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BF
93 conv 18 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 18 0.012 BF
94 yolo
95 route 91
96 conv 128 1 x 1 / 1 26 x 26 x 256 -> 26 x 26 x 128 0.044 BF
97 upsample 2x 26 x 26 x 128 -> 52 x 52 x 128
98 route 97 36
99 conv 128 1 x 1 / 1 52 x 52 x 384 -> 52 x 52 x 128 0.266 BF
100 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BF
101 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BF
102 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BF
103 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BF
104 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BF
105 conv 18 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 18 0.025 BF
106 yolo
YOLOv3工作流程
根据图来说明过程:
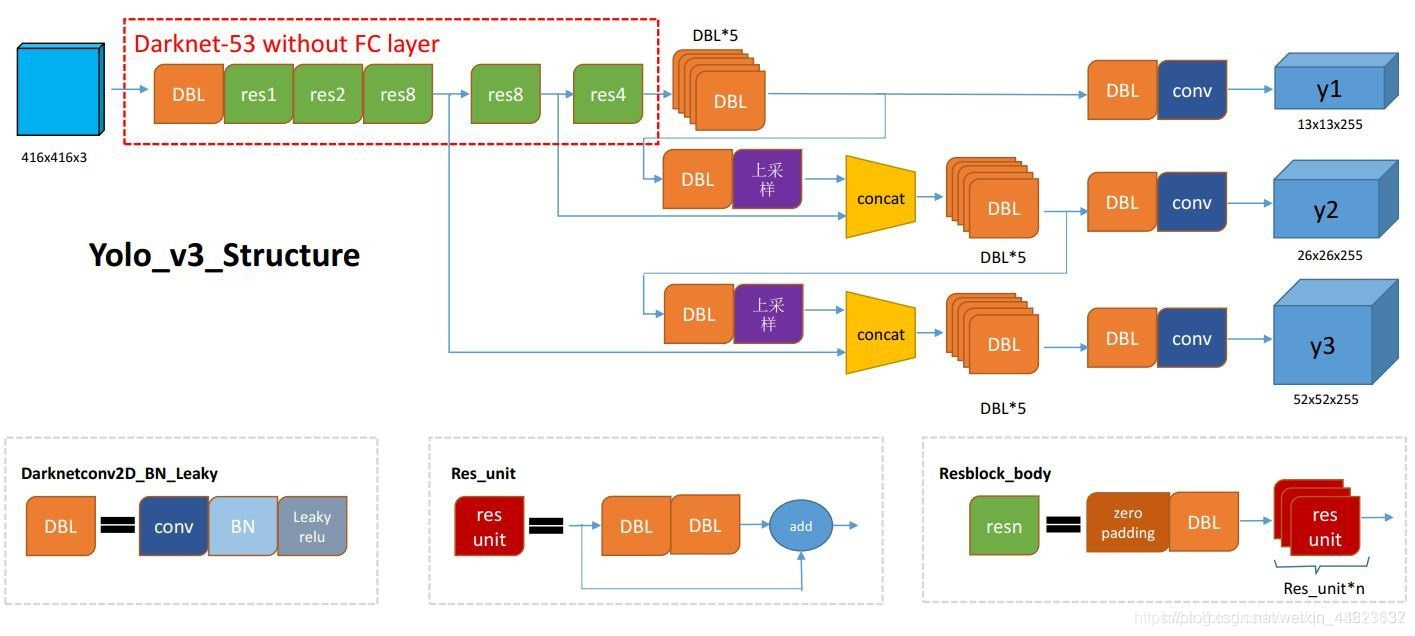
首先,将输入图片缩放到416x416,通过特征提取网络(Darknet53 without FC layer)进行了5次下采样,还用了残差网络,目的是使网络在深层能够很快的收敛继续训练下去,然后通过yolo层对输入图像提取特征得到大小一定的特征图13x13,输出的特征图经过DBL后的13×13的特征图上采样后与倒数第二次下采样的结果相加,二者都为26×26,然后在进行和尺度一同样的后续操作。最后是26×26的特征图上采样后与倒数第三次下采样的特征图相加,即还为26×26,在进行后续操作。
最后会输出三个不同尺度的特征图(即多尺度预测),每个尺度的特征图用来预测不同大小的目标,比如小尺度13x13可以预测大目标,中尺度26x26预测中目标,大尺度52x52预测小目标。而后,每个特征图对应3种anchor大小不同的负责预测目标。
最初图像还被分成13×13个网格,目标落在哪个网格中,哪个网格就负责预测目标,一个网格对应3个anchor(anchor的尺寸根据特征图相对于原图的比例等比缩小)。
不同尺寸特征图对应不同大小的先验框。
1313feature map对应【(11690),(156198),(373326)】
2626feature map对应【(3061),(6245),(59119)】
5252feature map对应【(1013),(1630),(3323)】
原因:
特征图越大,感受野越小。对小目标越敏感,所以选用小的anchor box。
特征图越小,感受野越大。对大目标越敏感,所以选用大的anchor box。
因此,最后的输出为S×S×3×(5+class_number)
预测时,yolov3采用多个独立的逻辑分类器来计算属于特定标签的可能性,在计算分类损失时,它对每个标签使用二元交叉熵损失,降低了计算的复杂度。
更详细的yolov3网络结构:

损失函数部分可以借助此博客,有很详细的讲解(虽然是yolov1,但也可借助来理解yolov3):
YOLOv1论文理解
YOLO v1深入理解

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









