






系列文章目录
目录
前言
一、安装
安装 ManiSkill 非常简单,只需运行几个 pip 安装程序即可
# install the package and a version of torch that is compatible with your system
pip install --upgrade mani_skill torch我们还提供更新更频繁的夜间版本,只要 ManiSkill 有变化,就会每日更新:
pip install mani_skill-nightly torch对于大多数 MacOS 用户来说,安装 Vulkan 驱动程序需要更多的设置,详情请查看 MacOS 安装页面。
注意事项
虽然基于状态的仿真不需要任何额外的依赖项,但需要安装了 Vulkan 驱动程序的 GPU 才能在 ManiSkill 中进行渲染。有关如何在 Ubuntu 上安装和配置 Vulkan,请参见此处。此外,我们目前最支持配备英伟达™(NVIDIA®)图形处理器的 Linux 机器,对其他系统的支持有限,详情请查看系统要求部分。
由 SAPIEN 支持的刚体任务在安装后即可使用。测试您的安装:
# Run an episode (at most 50 steps) of "PickCube-v1" (a rigid-body task) with random actions
# Or specify an task by "-e ${ENV_ID}"
python -m mani_skill.examples.demo_random_actionDocker Hub 上还提供了名为 maniskill/base 的 docker 镜像及其相应的 Dockerfile。
完成这里的工作后,你就可以前往快速入门页面试用一些实时演示,并开始使用 ManiSkill 编程。
你可能还需要设置 2 个环境变量。有许多资产、演示数据集等默认情况下不会下载。将 MS_ASSET_DIR 修改为保存 ManiSkill 所有数据的目录,默认为 ~/.maniskill/data。
export MS_ASSET_DIR=path/to/where/to/save/all/mani_skill_data您还可以执行以下操作来跳过下载资产的提示,这意味着如果您运行的代码需要访问未找到的资产,它将不再提示您下载。
export MS_SKIP_ASSET_DOWNLOAD_PROMPT=11.1 系统支持
我们目前最支持基于 Linux 的系统。对 Windows 的支持有限,目前还不支持 MacOS。我们正在努力尝试支持其他系统的更多功能,但这可能需要一些时间。大多数限制因素来自 SAPIEN 软件包的支持能力。
| System / GPU | CPU Sim | GPU Sim | Rendering |
|---|---|---|---|
| Linux / NVIDIA GPU | ✅ | ✅ | ✅ |
| Windows / NVIDIA GPU | ✅ | ❌ | ✅ |
| Windows / AMD GPU | ✅ | ❌ | ✅ |
| WSL / Anything | ✅ | ❌ | ❌ |
| MacOS / Anything | ✅ | ❌ | ✅ |
1.2 故障排除
1.2.1 Vulkan
Ubuntu
在 Ubuntu 上安装 Vulkan:
sudo apt-get install libvulkan1测试 Vulkan 安装情况:
sudo apt-get install vulkan-utils
vulkaninfo如果 vulkaninfo 无法显示有关 Vulkan 的信息,请检查是否存在以下文件:
- /usr/share/vulkan/icd.d/nvidia_icd.json
- /usr/share/glvnd/egl_vendor.d/10_nvidia.json
- /etc/vulkan/implicit_layer.d/nvidia_layer.json(可选,但对于某些 GPU(如 A100)是必要的
如果 /usr/share/vulkan/icd.d/nvidia_icd.json 不存在,请尝试创建内容如下的文件:
{
"file_format_version" : "1.0.0",
"ICD": {
"library_path": "libGLX_nvidia.so.0",
"api_version" : "1.2.155"
}
}如果 /usr/share/glvnd/egl_vendor.d/10_nvidia.json 不存在,可以尝试 sudo apt-get install libglvnd-dev。10_nvidia.json 包含以下内容:
{
"file_format_version" : "1.0.0",
"ICD" : {
"library_path" : "libEGL_nvidia.so.0"
}
}如果 /etc/vulkan/implicit_layer.d/nvidia_layers.json 不存在,请尝试创建包含以下内容的文件:
{
"file_format_version" : "1.0.0",
"layer": {
"name": "VK_LAYER_NV_optimus",
"type": "INSTANCE",
"library_path": "libGLX_nvidia.so.0",
"api_version" : "1.2.155",
"implementation_version" : "1",
"description" : "NVIDIA Optimus layer",
"functions": {
"vkGetInstanceProcAddr": "vk_optimusGetInstanceProcAddr",
"vkGetDeviceProcAddr": "vk_optimusGetDeviceProcAddr"
},
"enable_environment": {
"__NV_PRIME_RENDER_OFFLOAD": "1"
},
"disable_environment": {
"DISABLE_LAYER_NV_OPTIMUS_1": ""
}
}
}更多讨论请点击此处。
如果 Vulkan 驱动程序损坏,可能会出现以下错误。请尝试按照上述说明重新安装。
- RuntimeError: vk::Instance::enumeratePhysicalDevices: ErrorInitializationFailed(初始化失败
- 某些所需的 Vulkan 扩展不存在。您可能无法使用渲染器进行渲染,但 CPU 资源仍然可用。
- 分段故障(核心转储)
如果仍有问题,可以检查英伟达驱动程序。首次运行
ldconfig -p | grep libGLX_nvidia如果找不到 libGLX_nvidia.so,则很可能安装了错误的驱动程序。要在 Linux 上获得正确的驱动程序,建议安装 nvidia-driver-xxx(不要使用软件包名称中包含 server 的驱动程序),并避免使用运行文件等其他安装方法。
MacOS
更多详情,请参阅 MacOS 安装页面。
1.3 卸载
如果 mani_skill 是通过 pip 安装的,请运行 pip uninstall mani-skill。
注意
软件包目录中可能存在一些生成的缓存文件(例如,已编译的共享库文件、由 SAPIEN 生成的凸网格)。也可能有数据下载到 ~/.maniskill 目录中。要完全卸载 mani_skill,请手动删除这些文件。
二、快速入门
ManiSkill 是建立在 SAPIEN 基础上的机器人仿真器。它提供了一个标准的 Gym/Gymnasium 界面,便于与强化学习(RL)和模仿学习(IL)等现有学习工作流程配合使用。此外,ManiSkill 还支持在 GPU 和 CPU 上进行仿真,以及快速并行渲染。
我们建议您先阅读本文档,并观看一些演示。然后,针对具体应用,我们推荐使用以下方法:
- 要开始使用 RL,请访问 RL 设置页面。
- 要开始使用 IL,请访问 IL 设置页面。
- 要了解如何创建自己的任务,请参阅任务创建教程。
2.1 接口
以下是一个基本示例,说明如何按照 Gymnasium 的接口运行 ManiSkill 任务,并使用一些基本选项执行随机策略
import gymnasium as gym
import mani_skill.envs
env = gym.make(
"PickCube-v1", # there are more tasks e.g. "PushCube-v1", "PegInsertionSide-v1", ...
num_envs=1,
obs_mode="state", # there is also "state_dict", "rgbd", ...
control_mode="pd_ee_delta_pose", # there is also "pd_joint_delta_pos", ...
render_mode="human"
)
print("Observation space", env.observation_space)
print("Action space", env.action_space)
obs, _ = env.reset(seed=0) # reset with a seed for determinism
done = False
while not done:
action = env.action_space.sample()
obs, reward, terminated, truncated, info = env.step(action)
done = terminated or truncated
env.render() # a display is required to render
env.close()将 num_envs 改为大于 1 的值将自动开启 GPU 仿真模式。下文将介绍更多快速细节。
您也可以通过命令行运行相同的代码,演示随机操作并玩转渲染选项
# run headless / without a display
python -m mani_skill.examples.demo_random_action -e PickCube-v1
# run with A GUI and ray tracing
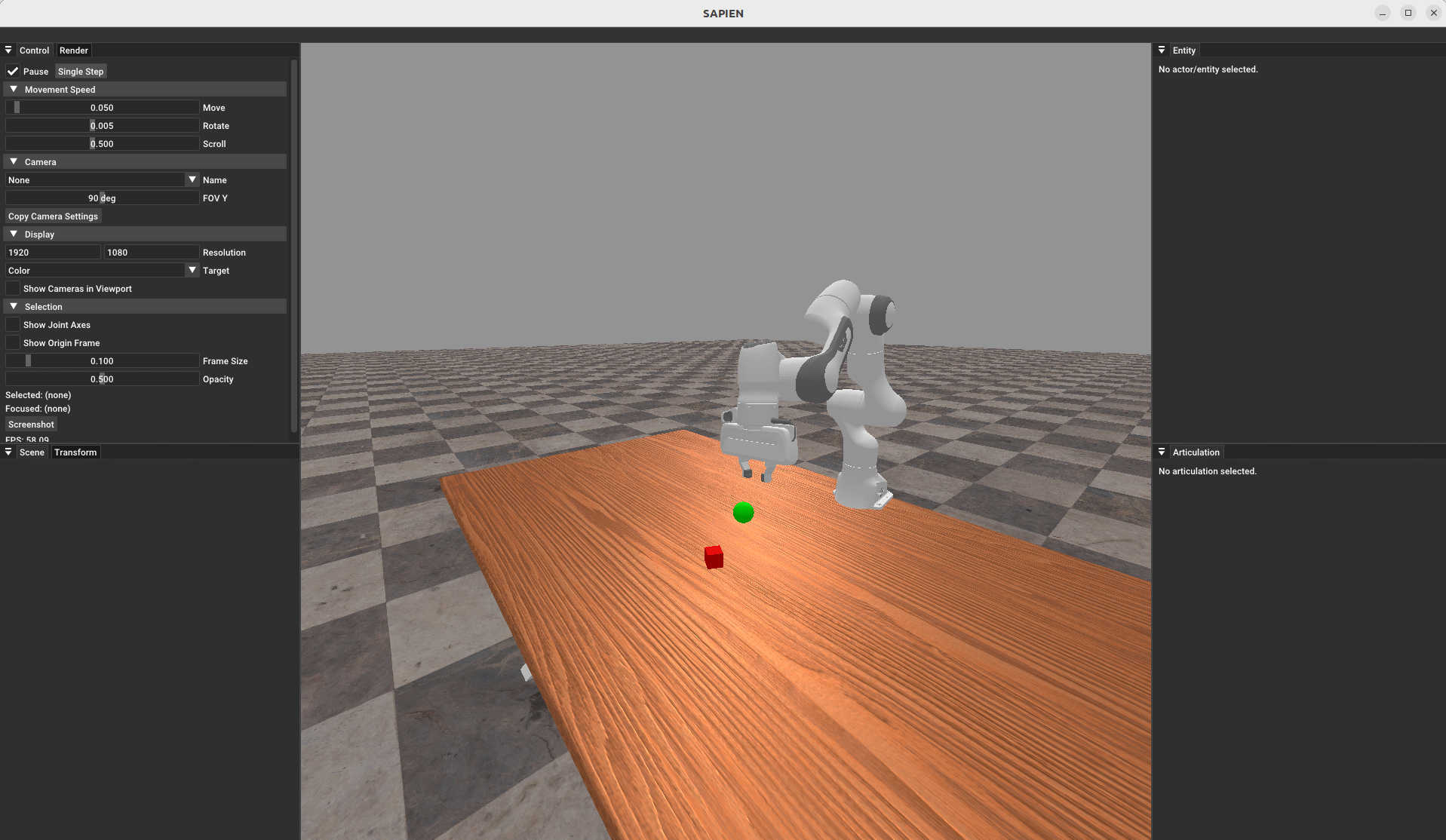
python -m mani_skill.examples.demo_random_action -e PickCube-v1 --render-mode="human" --shader="rt-fast"使用 render_mode=“human”(渲染模式=“人类”)运行时,将打开一个图形用户界面(如下图所示),您可以用它来交互式地探索场景、暂停/播放脚本、传送周围的物体等。
您还会注意到,所有返回的数据都是批次 torch 张量。为了减少处理 numpy 与 torch、cpu 与 gpu 模拟的额外代码,ManiSkill 中的所有内容都默认为提供/使用所有数据的批次 torch 张量。要更改环境以提供 numpy 非批处理数据,只需执行以下操作
from mani_skill.utils.wrappers.gymnasium import CPUGymWrapper
env = gym.make(env_id, num_envs=1)
env = CPUGymWrapper(env) # this also completely implements standard Gymnasium Env interface
obs, _ = env.reset() # obs is numpy and unbatched要在单一/矢量化环境中使用由 gym/gymnasium 定义的完全相同的 API,请参阅强化学习设置部分。
如需无需编写任何额外代码即可运行的演示汇编,请查看演示页面
有关环境实例化选项的完整列表,请参见 mani_skill.envs.sapien_env。
2.2 GPU 并行化/矢量化任务
ManiSkill 采用 SAPIEN 技术,支持 GPU 并行物理仿真和 GPU 并行渲染。这使得在单个 4090 GPU 上执行操作任务时,基于状态的仿真可达到 200,000+ FPS,渲染可达到 30,000+ FPS。FPS的高低取决于仿真的内容。完整的基准测试结果请参阅此页
要在 GPU 上运行大规模并行化任务,只需在 gym.make 中添加如下 num_envs 参数即可:
import gymnasium as gym
import mani_skill.envs
env = gym.make(
"PickCube-v1",
obs_mode="state",
control_mode="pd_joint_delta_pos",
num_envs=16,
)
print(env.observation_space) # will now have shape (16, ...)
print(env.action_space) # will now have shape (16, ...)
# env.single_observation_space and env.single_action_space provide non batched spaces
obs, _ = env.reset(seed=0) # reset with a seed for determinism
for i in range(200):
action = env.action_space.sample() # this is batched now
obs, reward, terminated, truncated, info = env.step(action)
done = terminated | truncated
print(f"Obs shape: {obs.shape}, Reward shape {reward.shape}, Done shape {done.shape}")
env.close()请注意,env.step 和 env.reset 返回的所有值都是批处理的火炬张量。然后,使用 GPU 还是 CPU 仿真决定了张量在什么设备上(CUDA 还是 CPU)。
要对并行仿真进行基准测试,可以运行
python -m mani_skill.examples.benchmarking.gpu_sim --num-envs=1024要试用并行化渲染,可以运行
# rendering RGB + Depth data from all cameras
python -m mani_skill.examples.benchmarking.gpu_sim --num-envs=64 --obs-mode="rgbd"
# directly save 64 videos of the visual observations put into one video
python -m mani_skill.examples.benchmarking.gpu_sim --num-envs=64 --save-video
2.2.1 一个场景中的并行渲染
我们进一步支持通过录制或图形用户界面一次性查看所有并行环境,您还可以打开光线追踪以获得更逼真的效果。请注意,除了生成炫酷的演示视频外,该功能对任何实际用途(如机器学习)都没有用处。
要开启并行图形用户界面渲染功能,只需在 gym.make 中添加参数 parallel_in_single_scene,如下所示
import gymnasium as gym
import mani_skill.envs
env = gym.make(
"PickCube-v1",
obs_mode="state",
control_mode="pd_joint_delta_pos",
num_envs=16,
parallel_in_single_scene=True,
viewer_camera_configs=dict(shader_pack="rt-fast"),
)
env.reset()
while True:
env.step(env.action_space.sample())
env.render_human()这样就会打开一个类似这样的图形用户界面:

2.2.2 额外的 GPU 仿真/渲染自定义功能
最后,在拥有多个 GPU 的服务器上,您可以通过设置 CUDA_VISIBLE_DEVICES 环境变量,直接选择使用哪些设备/后端来进行仿真和渲染。例如,您可以运行 export CUDA_VISIBLE_DEVICES=1,然后运行相同的代码。虽然一切都标注为设备 “cuda:0”,但实际上现在使用的是 GPU 设备 1,这一点可以通过运行 nvidia-smi 来验证。
我们目前不支持将多个可见的 CUDA 设备暴露给单个进程,因为它目前存在一些渲染错误。
2.3 任务实例化选项
有关环境实例化选项的完整列表,请参见 mani_skill.envs.sapien_env。这里我们列出了一些常用选项:
每个 ManiSkill 任务都支持不同的观察模式和控制模式,它们决定了任务的观察空间和行动空间。它们可以通过 gym.make(env_id, obs_mode=..., control_mode=...) 来指定。
常见的观测模式有状态模式、rgbd 模式和点云模式。我们还支持 state_dict(以分层字典形式组织的状态)和 sensor_data(未经后处理的原始视觉观测数据)。详情请参阅 “观测”。此外,仿真器生成的视觉数据可以通过着色器进行多种修改。详情请参阅传感器/摄像头教程。
我们支持多种控制器。不同的控制器会对算法产生不同的影响。因此,建议您先了解将要使用的动作空间。请参阅控制器了解更多详情。
有些任务需要下载未存储在 python 软件包中的资产。您可以通过 python -m mani_skill.utils.download_asset ${ENV_ID} 下载特定任务的资产。默认情况下,资产会下载到 ~/maniskill/data,但也可以使用环境变量 MS_ASSET_DIR 来更改目的地。如果不提前下载资产,运行环境时就会提示下载。
有些 ManiSkill 任务还支持交换机器人体现,例如 PickCube-v1 任务。您可以尝试使用获取机器人来代替,方法是运行
gym.make("PickCube-v1", robot_uids="fetch")您可能还会注意到参数中的 robot_uids 是复数,这是因为我们还支持包含多个机器人的任务,可以通过传递类似 robot_uids=(“fetch”、“fetch”、“panda”)这样的元组来实现。请注意,并非所有任务都支持加载任何机器人或多个机器人,因为它们在设计之初就是为了评估这些设置。
三、Docker
Docker 提供了一种便捷的方式,可将软件打包成标准化单元,用于开发、运输和部署。有关 Docker 的更多详情,请参阅官方网站。英伟达™(NVIDIA®)Container Tookit 使用户能够构建和运行 GPU 加速的 Docker 容器。
首先,按照官方说明安装 nvidia-docker v2。建议完成 Linux 的安装后步骤。
验证安装:
# You should be able to run this without sudo.
docker run hello-world3.1 在 Docker 中运行 ManiSkill
我们提供了一个 docker 镜像(maniskill/base)及其相应的 Dockerfile。
您应该能够同时运行 CPU 和 GPU 仿真,您可以在下面进行测试
docker pull maniskill/base
docker run --rm -it --gpus all --pid host maniskill/base python -m mani_skill.examples.demo_random_action
docker run --rm -it --gpus all --pid host maniskill/base python -m mani_skill.examples.benchmarking.gpu_sim请注意,在 docker 镜像中,你通常无法渲染图形用户界面来查看结果。你仍然可以录制视频,演示脚本也有录制视频而不是渲染图形用户界面的选项。

















 1667
1667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









