






0. 论文信息
标题:LaPose: Laplacian Mixture Shape Modeling for RGB-Based Category-Level Object Pose Estimation
作者:Ruida Zhang, Ziqin Huang, Gu Wang, Chenyangguang Zhang, Yan Di, Xingxing Zuo, Jiwen Tang, Xiangyang Ji
机构:Tsinghua University、Technical University of Munich、California Institute of Technology
原文链接:https://arxiv.org/abs/2409.15727
代码链接:https://github.com/lolrudy/LaPose
1. 摘要
虽然基于RGBD的类别级物体姿态估计方法很有前途,但它们对深度数据的依赖限制了它们在不同场景中的适用性。作为回应,最近的努力已经转向基于RGB的方法;然而,由于缺乏深度信息,它们面临着巨大的挑战。一方面,深度的缺乏加剧了处理类内形状变化的难度,导致形状预测的不确定性增加。另一方面,仅RGB输入引入了固有的比例模糊,使得对象大小和平移的估计成为不适定的问题。为了应对这些挑战,我们提出了LaPose,一种新的框架,它将对象形状建模为用于姿态估计的拉普拉斯混合模型。通过将每个点表示为概率分布,我们明确量化了形状的不确定性。LaPose利用广义的3D信息流和专门的特征流来独立地预测每个点的拉普拉斯分布,从而捕捉对象几何形状的不同方面。然后,这两个分布被集成为拉普拉斯混合模型,以建立2D-3D对应关系,该对应关系被用于通过PnP模块求解姿态。为了减少尺度模糊,我们引入了一种与尺度无关的对象大小和平移的表示,提高了训练效率和整体鲁棒性。在NOCS数据集上的大量实验验证了LaPose的有效性,在基于RGB的类别级物体姿态估计中产生了最先进的性能。
2. 引言
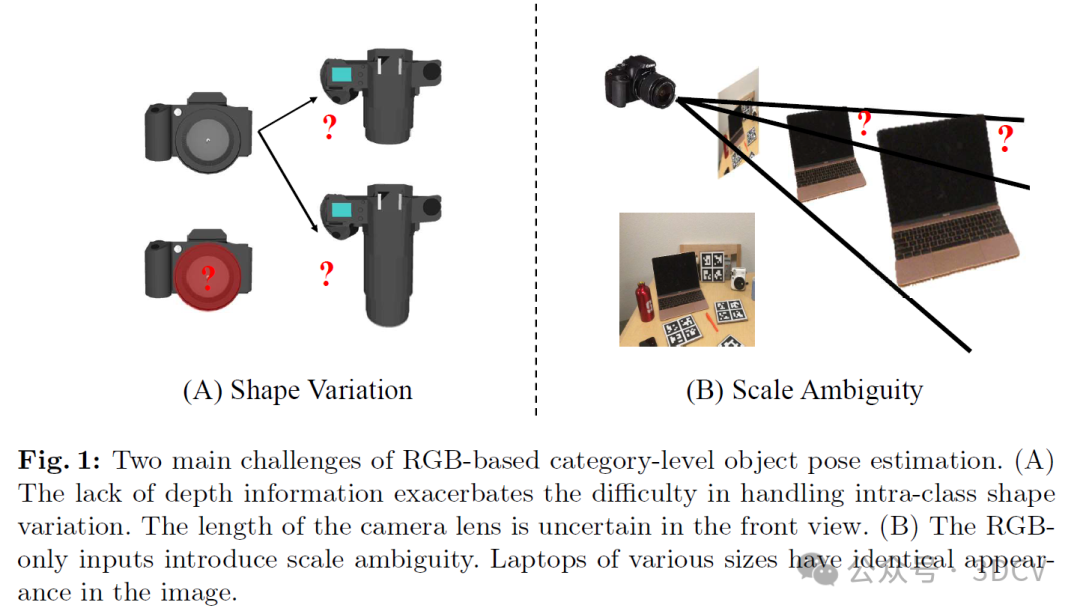
类别级物体姿态估计的任务包括预测未见过的物体在给定类别集合中的9DoF姿态,包括3D旋转、3D平移和3D度量尺寸。该领域因其在机器人技术、增强现实(AR)、虚拟现实(VR)和3D理解[中的广泛应用而引起了越来越多的研究兴趣。尽管基于RGBD的方法展示了有前景的结果,但其中大多数严重依赖深度传感器,这限制了它们在一般场景中的应用。
因此,提出了基于RGB的类别级物体姿态估计方法,这些方法适合部署在嵌入式设备(如AR头显和移动电话)上。然而,如图1所示,缺乏深度信息带来了两大挑战:首先,缺乏深度信息使物体形状的预测变得复杂,并加剧了处理类内形状变化的难度;其次,仅依赖RGB输入引入了固有的尺度模糊性,使得平移和尺寸的估计成为了一个不适定问题。
为了应对这些挑战,最近的方法提出了两种解决方案。一方面,MSOS和OLD-Net通过估计度量深度和归一化物体坐标空间(NOCS)坐标来建立3D-3D对应关系,并通过Umeyama算法求解姿态。另一方面,DMSR利用预训练的DPT模型预测的物体法线和相对深度作为附加输入,来估计NOCS坐标图以及物体度量尺度,然后使用PnP算法求解姿态。
然而,这些方法在两个关键方面存在局限性。首先,如图1(A)所示,缺乏深度信息使得准确测量物体形状变得困难。形状的不确定性在图像的某些区域(如图1(A)中的相机镜头)尤其明显,这使得建立精确的对应关系变得复杂。所有这些方法都将每个像素的预测对应关系视为等同,并依赖RANSAC来过滤异常值,这减慢了预测过程并削弱了鲁棒性。其次,MSOS和OLD-Net没有考虑尺度模糊性。相比之下,DMSR利用相同的特征来预测NOCS图和度量尺度。然而,从单张RGB图像中推断度量尺度本质上是不适定的,这可能导致其他组件的训练不稳定和结果较差。推荐课程:国内首个Halcon深度学习项目实战系统教程。
为了解决这些问题,我们提出了LaPose,通过将物体形状建模为拉普拉斯混合模型(Laplacian Mixture Model, LMM),来进行基于RGB的类别级物体姿态估计。如图1所示,由于缺乏深度信息,每个像素的形状不确定性各不相同。与之前确定性预测NOCS图的方法相比,将NOCS坐标建模为概率分布引入了其方差的额外信息,这明确测量了每个点的形状不确定性。
为了更全面地理解物体形状,我们采用了拉普拉斯混合模型(LMM),该模型结合了从不同信息源推断出的两个独立的拉普拉斯分布。我们选择拉普拉斯分布是因为它与其他分布(如高斯分布)相比,在处理异常值方面具有更好的能力。我们利用两个并行信息流来捕捉物体几何形状的不同方面,并独立预测NOCS图的拉普拉斯分布。为了提取可泛化的、与类别无关的3D特征,我们利用DINOv2作为通用的3D信息流。多项研究已经证明了DINOv2封装3D信息的能力。具体来说,它能够提取SE(3)一致的局部特征,以在不同形状和姿态的物体之间建立语义对应关系。然而,由于DINOv2以与类别无关的方式进行训练,它在提取特定类别的特征方面较差。为了弥补这一点,我们训练了另一个骨干网络,专门用于捕捉特定类别的信息,作为专用特征流。
在估计拉普拉斯混合模型后,我们建立2D-3D对应关系,并利用类似于的卷积网络构建的PnP模块求解姿态。PnP模块在两个方面受益于LMM:首先,它可以动态地聚合由双信息流捕捉到的多样化的物体几何信息;其次,它能够识别不同区域的形状不确定性并过滤掉错误的对应关系,从而提高整体鲁棒性。LMM的这种新颖集成在姿态估计过程中促进了更明智的决策,提高了模型在挑战场景下的可靠性。
此外,为了应对姿态预测中固有的尺度模糊性挑战,我们为平移和尺寸提出了一种与尺度无关的表示。通过将姿态预测与度量尺度解耦,我们的方法通过切断由尺度模糊性引起的误差传播到姿态估计中,提高了训练效率。此外,这种方法还导致了更具信息量的评估指标,提供了对不同物体尺度下姿态估计方法性能的深入见解。
3. 效果展示
如图5所示,由于我们采用了LMM形状建模方法,LaPose在处理形状变化较大的类别(如相机)时表现优于DMSR。图6也证明了我们的方法在处理相机类别时(图6中的绿线)大大超过了DMSR。此外,值得注意的是,LaPose在预测旋转方面表现出色,在小阈值下实现了更高的准确性(如图6中间部分所示)。

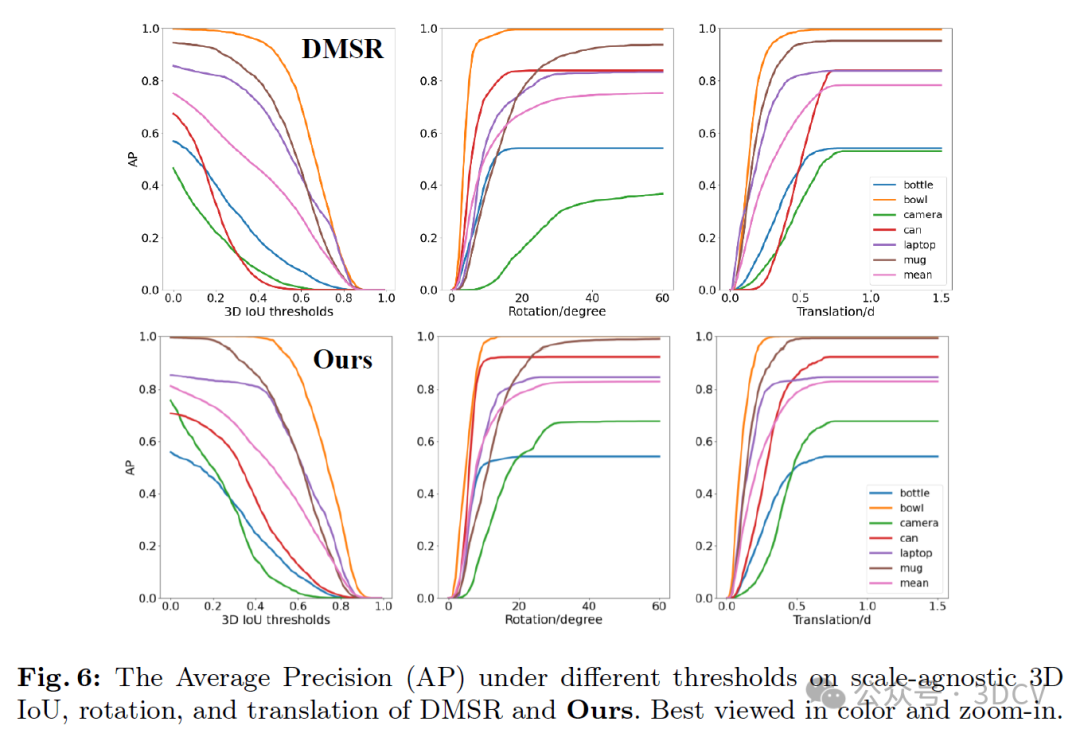
图4证明了我们的LMM建模方法的有效性。在NOCS预测误差较高的区域,方差也相应较高,与其他区域相比。这一观察结果表明,我们的LMM建模如何有效地引导PnP模块优先处理方差较低且NOCS预测更准确的区域。因此,这种能力使LaPose能够有效地解决由于缺少深度信息和类内形状变化而引起的形状不确定性问题。

4. 主要贡献
我们的贡献主要包括三个方面:首先,我们引入了拉普拉斯混合模型(LMM)来有效地建模物体形状,明确量化每个点的形状不确定性,并解决类内形状变化问题;其次,我们提出了一个双流框架来估计LMM的参数,该框架本质上利用了通用的3D信息流和专用的特征流来捕捉物体几何形状的多个方面;最后,我们提出了一种与尺度无关的9DoF姿态表示,提高了训练效率并提供了信息丰富的评估指标。LaPose在NOCS数据集上取得了最先进的性能,并通过广泛的实验验证了我们的设计选择的有效性。
5. 方法
在本文中,我们的目标是解决基于RGB的类别级物体姿态估计问题。具体而言,给定一张包含来自预定义类别集合中物体的RGB图像,我们的目标是检测场景中所有物体的实例,并准确估计它们的9自由度(9DoF)姿态。这9DoF姿态包括3自由度旋转R ∈ SO(3)、3自由度平移t ∈ R3以及3自由度尺寸s ∈ R3。
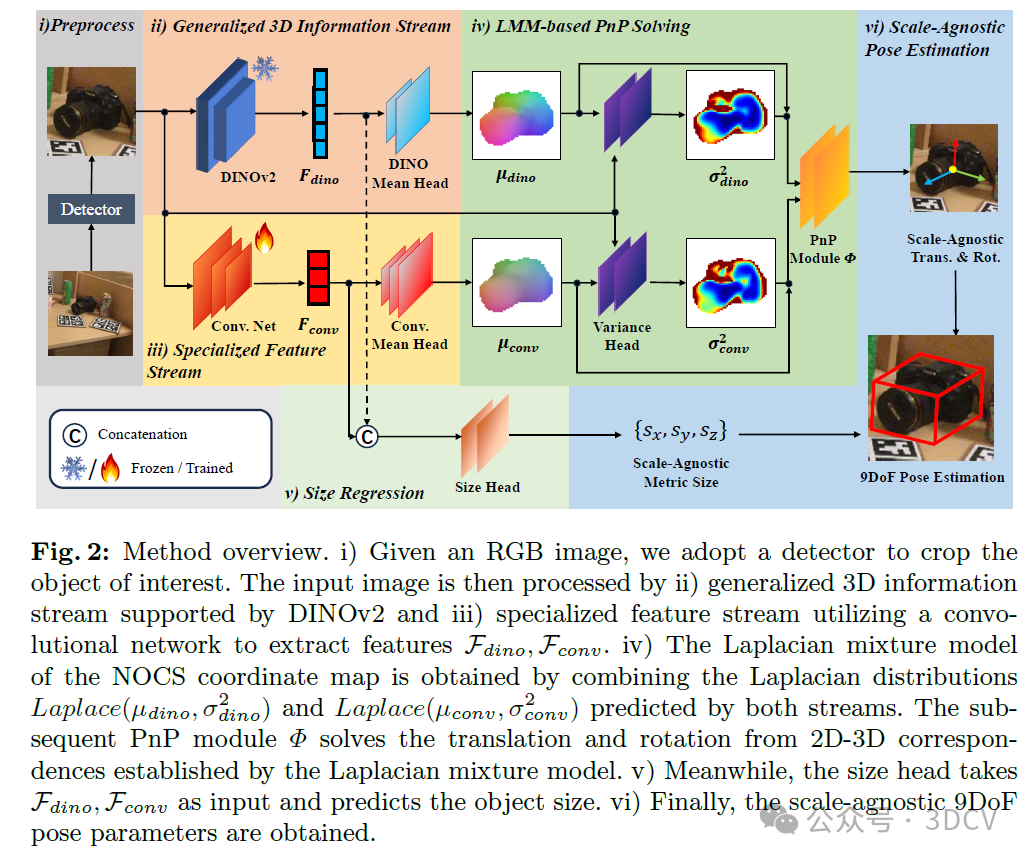
为此,我们提出了LaPose,这是一种使用拉普拉斯混合模型(Laplacian Mixture Model, LMM)进行姿态估计的新方法(图2)。我们首先采用现成的物体检测器MaskRCNN[14]裁剪出感兴趣的物体作为输入。然后,我们利用两条信息流来独立预测NOCS坐标图的两个拉普拉斯分布Laplace(μdino, σ²dino)和Laplace(μconv, σ²conv),从而估计LMM的参数。之后,通过基于LMM的PnP求解方法利用估计得到的LMM进行姿态估计。最后,通过PnP模块计算出与尺度无关的姿态{R, tnorm, snorm}。LaPose的概述如图2所示。
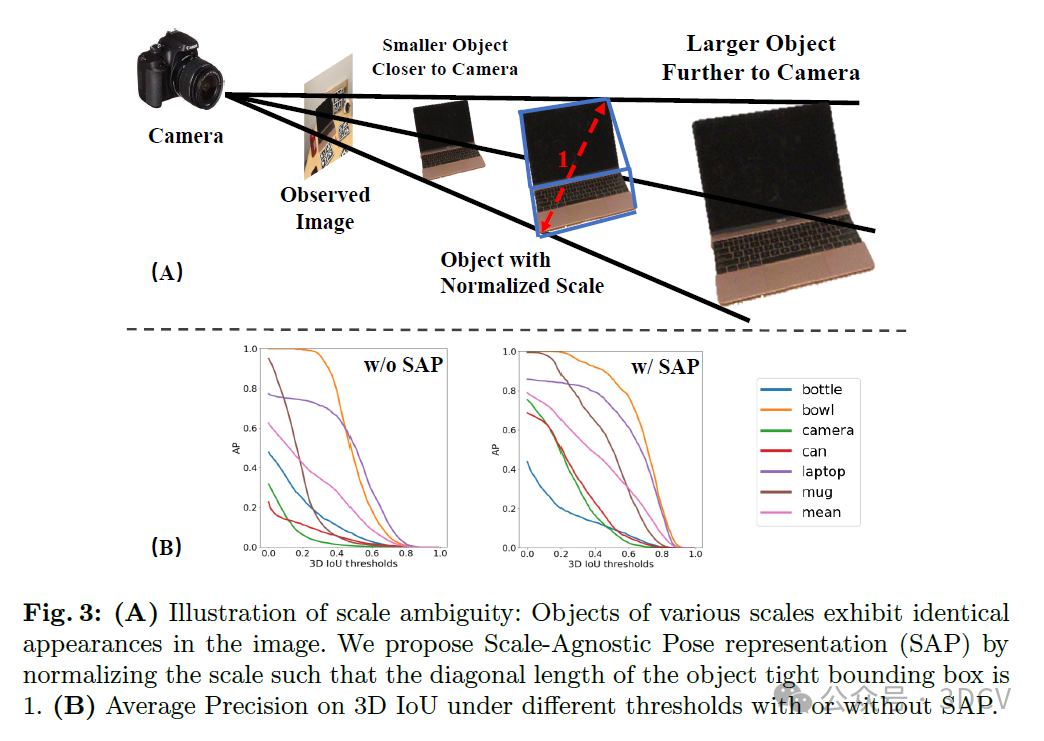
如图3(A)所示,仅凭单一的RGB图像无法确定物体的度量尺度。例如,考虑两种情况:一个较大的物体距离相机较远,而一个较小的物体距离相机较近。尽管它们在尺寸上形成对比,但这些物体在图像中可能看起来完全相同,从而导致尺度模糊。由于缺乏深度信息,仅根据视觉外观来预测物体的平移和尺寸是一个不适定问题。因此,我们提出了一种与尺度无关的姿态表示方法,其中我们将物体规范化以适合一个对角线长度为1的紧密边界框。图3(B)显示,采用所提出的与尺度无关的姿态表示(SAP)显著提高了性能。
6. 实验结果
表1和表2在NOCS-REAL275数据集上,分别使用与尺度无关和绝对尺度的评估指标,对LaPose与最先进的方法(包括MSOS、OLD-Net和DMSR)进行了全面比较。
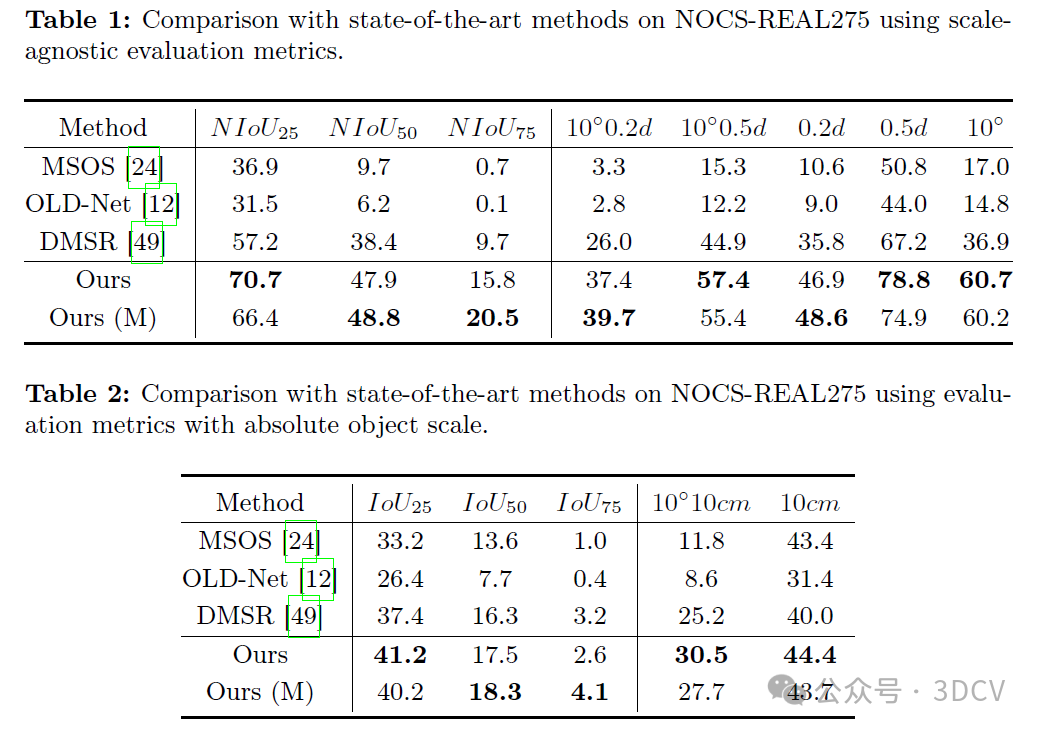
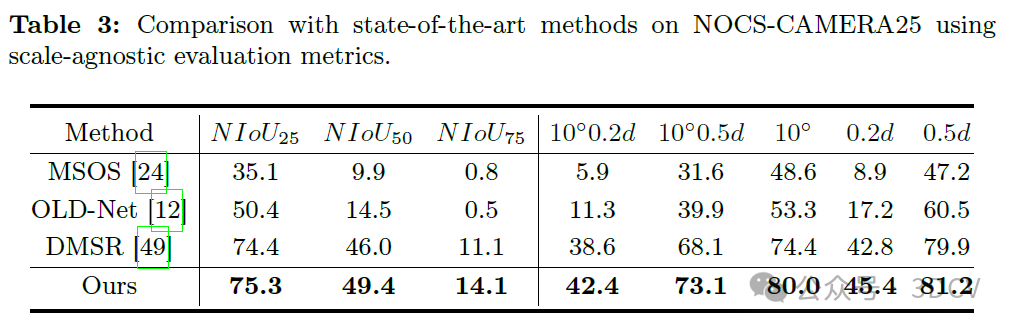
如表3所示,在NOCS-CAMERA25数据集上,LaPose也达到了最先进的性能。具体而言,在最严格的指标NIoU75和10◦0.2d上,我们分别超过了DMSR 3.0%和3.8%。在NIoU50和10◦0.5d指标上,LaPose与DMSR之间的性能差距分别为3.4%和5.0%。与OLD-Net相比,LaPose在10◦和0.2d上的准确率分别为80.0%和45.4%,分别比OLD-Net高出26.7%和28.2%。这些结果强调了LaPose在不同场景下的有效性。
7. 总结 & 未来工作
在本文中,我们提出了LaPose,这是一个新颖的框架,它使用拉普拉斯混合模型(LMM)对基于RGB的类别级物体姿态进行建模。具体而言,我们整合了两个来自不同特征流的独立拉普拉斯分布。我们利用估计得到的LMM建立二维到三维的对应关系,并通过PnP模块求解姿态。我们提出的与尺度无关的姿态表示有效地解决了尺度模糊性问题,并确保了训练过程的稳定性和高效性。在NOCS数据集上进行的大量实验表明,LaPose达到了最先进的性能。展望未来,我们计划将LaPose扩展到机器人操作的应用中。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~

















 1168
1168

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









