






转载自:机器之心 | 编辑:Panda
视觉与机器人学习的深度融合。
当两只机器手丝滑地互相合作叠衣服、倒茶、将鞋子打包时,加上最近老上头条的 1X 人形机器人 NEO,你可能会产生一种感觉:我们似乎开始进入机器人时代了。

事实上,这些丝滑动作正是先进机器人技术 + 精妙框架设计 + 多模态大模型的产物。
我们知道,有用的机器人往往需要与环境进行复杂精妙的交互,而环境则可被表示成空间域和时间域上的约束。
举个例子,如果要让机器人倒茶,那么机器人首先需要抓住茶壶手柄并使之保持直立,不泼洒出茶水,然后平稳移动,一直到让壶口与杯口对齐,之后以一定角度倾斜茶壶。这里,约束条件不仅包含中间目标(如对齐壶口与杯口),还包括过渡状态(如保持茶壶直立);它们共同决定了机器人相对于环境的动作的空间、时间和其它组合要求。
然而,现实世界纷繁复杂,如何构建这些约束是一个极具挑战性的问题。
近日,李飞飞团队在这一研究方向取得了一个突破,提出了关系关键点约束(ReKep/Relational Keypoint Constraints)。简单来说,该方法就是将任务表示成一个关系关键点序列。并且,这套框架还能很好地与 GPT-4o 等多模态大模型很好地整合。从演示视频来看,这种方法的表现相当不错。该团队也已发布相关代码。本文一作为 Wenlong Huang。

论文标题:ReKep: Spatio-Temporal Reasoning of Relational Keypoint Constraints for Robotic Manipulation
论文地址:https://rekep-robot.github.io/rekep.pdf
项目网站:https://rekep-robot.github.io
代码地址:https://github.com/huangwl18/ReKep
李飞飞表示,该工作展示了视觉与机器人学习的更深层次融合!虽然论文中没有提及李飞飞在今年 5 年初创立的专注空间智能的 AI 公司 World Labs,但 ReKep 显然在空间智能方面大有潜力。
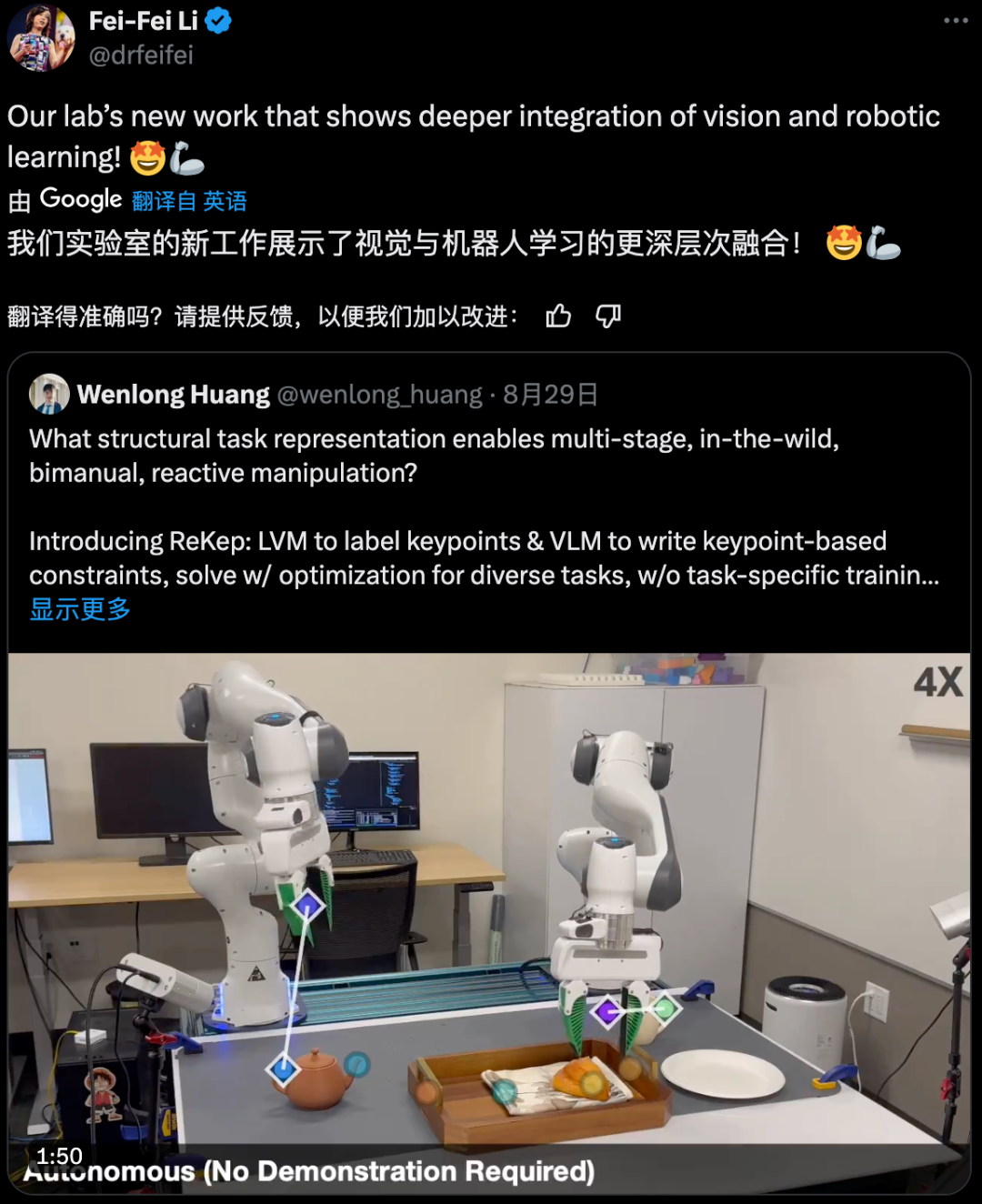
方法
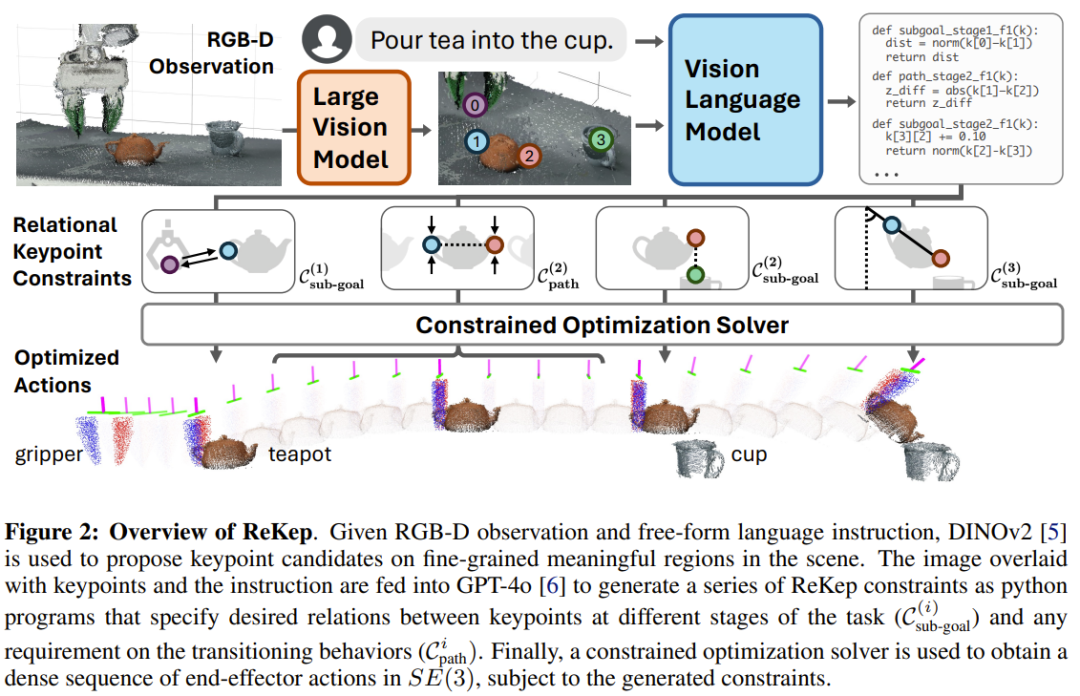
关系关键点约束(ReKep)
首先,我们先看一个 ReKep 实例。这里先假设已经指定了一组 K 个关键点。具体来说,每个关键点 k_i ∈ ℝ^3 都是在具有笛卡尔坐标的场景表面上的一个 3D 点。
一个 ReKep 实例便是一个这样的函数:𝑓: ℝ^{K×3}→ℝ;其可将一组关键点(记为 𝒌)映射成一个无界成本(unbounded cost),当 𝑓(𝒌) ≤ 0 时即表示满足约束。至于具体实现,该团队将函数 𝑓 实现为了一个无状态 Python 函数,其中包含对关键点的 NumPy 操作,这些操作可能是非线性的和非凸的。本质上讲,一个 ReKep 实例编码了关键点之间的一个所需空间关系。
但是,一个操作任务通常涉及多个空间关系,并且可能具有多个与时间有关的阶段,其中每个阶段都需要不同的空间关系。为此,该团队的做法是将一个任务分解成 N 个阶段并使用 ReKep 为每个阶段 i ∈ {1, ..., N } 指定两类约束:
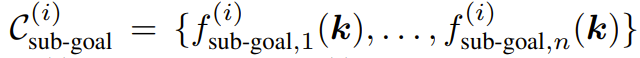
一组子目标约束
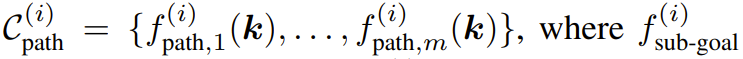
一组路径约束
其中 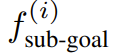 编码了阶段 i 结束时要实现的一个关键点关系,而
编码了阶段 i 结束时要实现的一个关键点关系,而 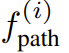 编码了阶段 i 内每个状态要满足的一个关键点关系。以图 2 的倒茶任务为例,其包含三个阶段:抓拿、对齐、倒茶。
编码了阶段 i 内每个状态要满足的一个关键点关系。以图 2 的倒茶任务为例,其包含三个阶段:抓拿、对齐、倒茶。
阶段 1 子目标约束是将末端执行器伸向茶壶把手。阶段 2 子目标约束是让茶壶口位于杯口上方。此外,阶段 2 路径约束是保持茶壶直立,避免茶水洒出。最后的阶段 3 子目标约束是到达指定的倒茶角度。
使用 ReKep 将操作任务定义成一个约束优化问题
使用 ReKep,可将机器人操作任务转换成一个涉及子目标和路径的约束优化问题。这里将末端执行器姿势记为 𝒆 ∈ SE (3)。为了执行操作任务,这里的目标是获取整体的离散时间轨迹 𝒆_{1:T}:
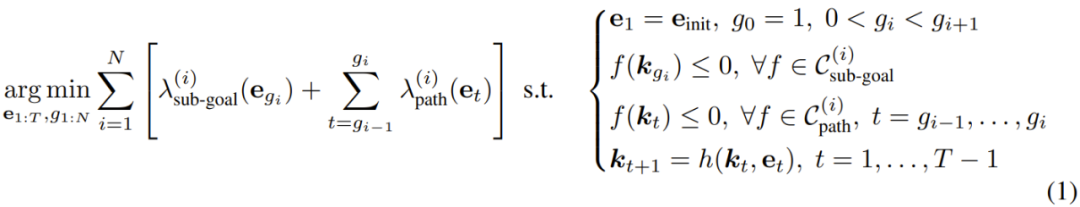
也就是说,对于每个阶段 i,该优化问题的目标是:基于给定的 ReKep 约束集和辅助成本,找到一个末端执行器姿势作为下一个子目标(及其相关时间),以及实现该子目标的姿势序列。该公式可被视为轨迹优化中的 direct shooting。
分解和算法实例化
为了能实时地求解上述公式 1,该团队选择对整体问题进行分解,仅针对下一个子目标和达成该子目标的相应路径进行优化。算法 1 给出了该过程的伪代码。

其中子目标问题的求解公式为:
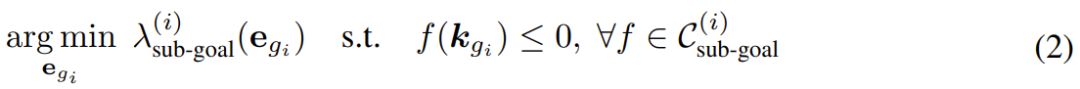
路径问题的求解公式为:
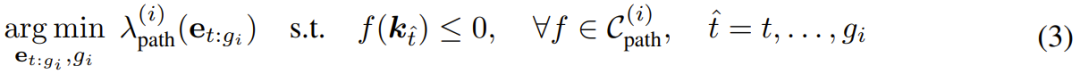
回溯
现实环境复杂多变,有时候在任务进行过程中,上一阶段的子目标约束可能不再成立(比如倒茶时茶杯被拿走了),这时候需要重新规划。该团队的做法是检查路径是否出现问题。如果发现问题,就迭代式地回溯到前一阶段。

关键点的前向模型
为了求解 2 和 3 式,该团队使用了一个前向模型 h,其可在优化过程中根据 ∆𝒆 估计 ∆𝒌。具体来说,给定末端执行器姿势 ∆𝒆 的变化,通过应用相同的相对刚性变换 𝒌′[grasped] = T_{∆𝒆}・𝒌[grasped] 来计算关键点位置的变化,同时假设其它关键点保持静止。
关键点提议和 ReKep 生成
为了让该系统能在实际情况下自由地执行各种任务,该团队还用上了大模型!具体来说,他们使用大型视觉模型和视觉 - 语言模型设计了一套管道流程来实现关键点提议和 ReKep 生成。
关键点提议
给定一张 RGB 图像,首先用 DINOv2 提取图块层面的特征 F_patch。然后执行双线性插值以将特征上采样到原始图像大小,F_interp。为了确保提议涵盖场景中的所有相关物体,他们使用了 Segment Anything(SAM)来提取场景中的所有掩码 M = {m_1, m_2, ... , m_n}。
对于每个掩码 j,使用 k 均值(k = 5)和余弦相似度度量对掩码特征 F_interp [m_j] 进行聚类。聚类的质心用作候选关键点,再使用经过校准的 RGB-D 相机将其投影到世界坐标 ℝ^3。距离候选关键点 8cm 以内的其它候选将被过滤掉。总体而言,该团队发现此过程可以识别大量细粒度且语义上有意义的对象区域。
ReKep 生成
获得候选关键点后,再将它们叠加在原始 RGB 图像上,并标注数字。结合具体任务的语言指令,再查询 GPT-4o 以生成所需阶段的数量以及每个阶段 i 对应的子目标约束和路径约束。
实验
该团队通过实验对这套约束设计进行了验证,并尝试解答了以下三个问题:
1. 该框架自动构建和合成操作行为的表现如何?
2. 该系统泛化到新物体和操作策略的效果如何?
3. 各个组件可能如何导致系统故障?
使用 ReKep 操作两台机器臂
他们通过一系列任务检查了该系统的多阶段(m)、野外 / 实用场景(w)、双手(b)和反应(r)行为。这些任务包括倒茶 (m, w, r)、摆放书本 (w)、回收罐子 (w)、给盒子贴胶带 (w, r)、叠衣服 (b)、装鞋子 (b) 和协作折叠 (b, r)。
结果见表 1,这里报告的是成功率数据。
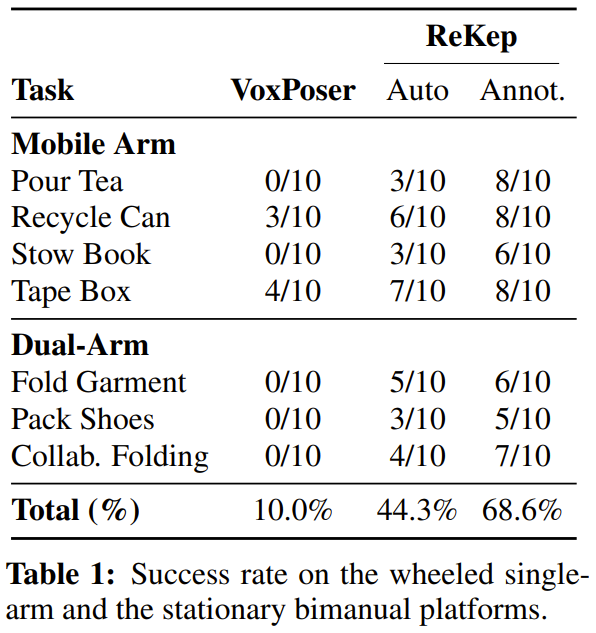
整体而言,就算没有提供特定于任务的数据或环境模型,新提出的系统也能够构建出正确的约束并在非结构化环境中执行它们。值得注意的是,ReKep 可以有效地处理每个任务的核心难题。
下面是一些实际执行过程的动画:


操作策略的泛化
该团队基于叠衣服任务探索了新策略的泛化性能。简而言之,就是看这套系统能不能叠不一样的衣服 —— 这需要几何和常识推理。
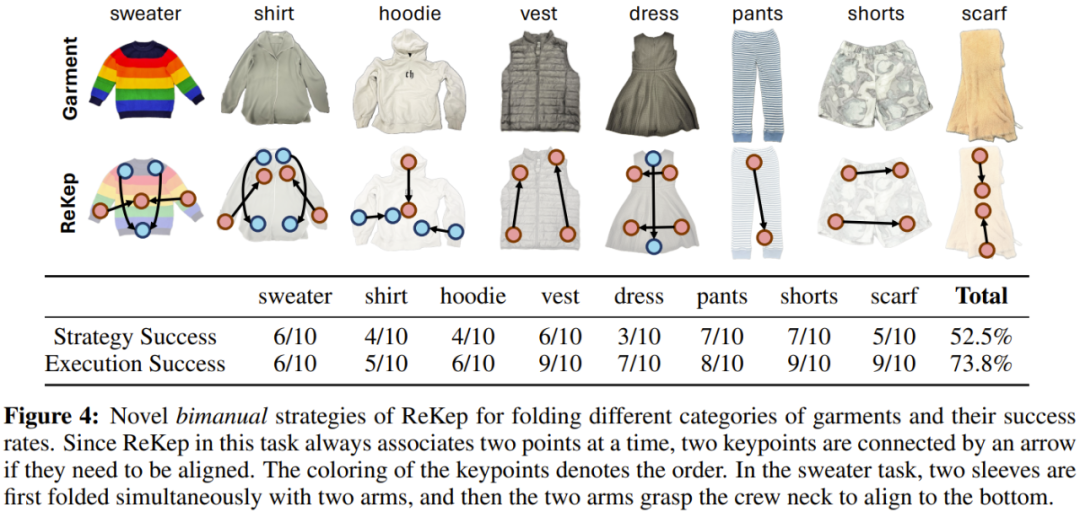
这里使用了 GPT-4o,提词仅包含通用指令,没有上下文示例。「策略成功」是指生成的 ReKep 可行,「执行成功」则衡量的是每种衣服的给定可行策略的系统成功率。
结果很有趣。可以看到该系统为不同衣服采用了不同的策略,其中一些叠衣服方法与人类常用的方法一样。


分析系统错误
该框架的设计是模块化的,因此很方便分析系统错误。该团队以人工方式检查了表 1 实验中遇到的故障案例,然后基于此计算了模块导致错误的可能性,同时考虑了它们在管道流程中的时间依赖关系。结果见图 5。

可以看到,在不同模块中,关键点跟踪器产生的错误最多,因为频繁和间或出现的遮挡让系统很难进行准确跟踪。
推荐阅读
欢迎大家加入DLer-计算机视觉技术交流群!
大家好,群里会第一时间发布计算机视觉方向的前沿论文解读和交流分享,主要方向有:图像分类、Transformer、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。
进群请备注:研究方向+学校/公司+昵称(如图像分类+上交+小明)

👆 长按识别,邀请您进群!


















 684
684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









