






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
在简历里我写了“采用B样条曲线和LQR的弧线转弯策略”,在此整理一下具体内容。
无代码
一、基于B样条曲线的路径生成
上层调度层给的目标路径通常只有极少几个点,尤其在转弯过程,此时就需要使用某种策略生成一段连续平滑的路径,常用的有B样条曲线和贝塞尔约束曲线等。
在此我们选择B样条曲线作为我们的路径生成策略。
1.B样条曲线基本概念(复制的gpt)
B样条(B-spline)是一种用于生成平滑曲线的数学方法,可以灵活地通过控制点创建不同形状的曲线。B样条曲线具有连续的曲率,因此适合在需要平滑路径的场景(如机器人路径规划)中使用。
B样条曲线由一组控制点和一个称为基函数的数学函数共同定义,主要参数包括:
控制点:决定了B样条曲线的形状。曲线不会严格通过这些点,但会在这些点周围生成平滑曲线。
阶数:B样条的阶数决定了曲线的平滑度。常用的三阶B样条曲线(立方B样条)具有平滑的曲率变化。
节点向量:定义了控制点在曲线生成中的位置权重,决定了曲线在控制点附近的形状和光滑度。
 使用B样条的步骤
使用B样条的步骤
选择控制点:确定曲线的控制点,这些点决定了曲线的形状。在机器人路径规划中,控制点通常由关键位置组成。
设定阶数:一般使用三阶B样条(立方B样条)来生成平滑曲线。
生成节点向量:节点向量可以均匀生成,也可以在需要的地方增加密集节点以控制曲线形状。在最简单的均匀B样条中,可以设置节点向量为等间隔的数列。
计算基函数:使用递归定义计算每个控制点的基函数。
生成曲线点:根据参数𝑢从曲线起点到终点的变化,计算每个点的位置𝐶(𝑢),从而生成完整的B样条曲线。
2.B样条曲线最终输出
一段离散的平滑路径点,计算其每一点的曲率获得机器人目标航向角。
3.B样条曲线相较贝塞尔约束曲线的优势(gpt)
B样条和贝塞尔曲线在路径规划中都可以生成平滑曲线,但在一些特定的应用中,B样条相比贝塞尔曲线更具优势。以下几点阐述了在路径规划中选择B样条而不使用贝塞尔曲线的原因:
1. 局部控制能力
- B样条具有较强的局部控制能力。调整某个控制点时,只会影响曲线的局部区域,而不会改变整条曲线的形状。这对于路径规划尤其重要,因为局部调整路径(例如避障或实时调整)时,不会对整体路径产生影响。
- 贝塞尔曲线的局部控制能力较差。调整一个控制点会影响整条曲线的形状。对于复杂路径或动态调整的场景,贝塞尔曲线不够灵活。
2. 高阶曲线的控制点数量
- B样条在构造高阶曲线时可以增加控制点数目,同时仍保持平滑的形状,且不会引起曲线大幅波动。控制点越多,曲线的可调节性越高,适合复杂路径规划。
- 贝塞尔曲线在控制点较多的情况下会产生较大的计算复杂度,并且曲线会出现“膨胀”或不受控制的波动。高阶贝塞尔曲线的控制点对曲线的形状影响较为显著,容易导致曲线过度弯曲或产生波动,不利于生成自然的路径。
3. 平滑过渡与连续性
- B样条可以通过设置节点向量和阶数来控制平滑度和连续性。三阶B样条(立方B样条)能够保证曲线的连续性和平滑的曲率变化,尤其适合机器人路径规划中的平滑转弯。
- 贝塞尔曲线在复杂曲线路径的过渡上,曲率的变化不如B样条平滑。尤其是多段贝塞尔曲线拼接时,会产生突兀的转折点,除非精确调整每段的切线方向,但这会增加实现复杂度。
4. 节点插值
- B样条曲线可以控制在靠近控制点的区域,并且可以进行节点插值,使曲线更加接近控制点。对于需要精确经过某些点的路径规划,B样条更为灵活。
- 贝塞尔曲线无法直接在曲线中插值控制点。增加控制点会改变曲线的整体形状,这对于路径规划中的精确定位控制来说是个缺点。
5. 复杂路径生成的灵活性
- B样条适用于生成复杂的、多段的平滑路径,可以通过增加控制点和调节节点向量来生成复杂曲线,在路径规划中非常灵活。
- 贝塞尔曲线适合用于生成简单的曲线,通常在控制点较少、需要控制简单曲线路径的场景下更适合。
6. 计算复杂度
- 在B样条和贝塞尔曲线的基础实现上,两者的计算复杂度相近,但B样条在高阶时仍能保持稳定,而贝塞尔曲线在控制点数增多时复杂度显著增加,因此在更高阶的复杂路径上,B样条的计算更高效。
总结
综上所述,虽然贝塞尔曲线在设计简单曲线路径时很方便,但在机器人路径规划或自动驾驶等复杂路径场景中,B样条的局部控制能力、灵活性和平滑度让它成为更适合的选择。
面试官问起来的时候,需要首先根据项目解释B样条曲线,然后说明其优势,最后与下面的LQR路径跟踪策略做衔接。
二、LQR路径跟踪策略
在使用B样条曲线得到目标路径后,跟踪策略采用的是LQR控制算法。
1.LQR基本概念(GPT)
LQR(Linear Quadratic Regulator)是一种常用的线性二次型最优控制算法,广泛应用于控制系统优化。它的目的是在满足稳定性条件下,最小化给定状态和控制的加权代价函数,从而获得最优的控制输入。在项目中,如果LQR用于控制机器人路径的跟踪,它可以用于平衡路径跟踪中的位置误差和控制能量,确保平稳的运动效果。
LQR原理概述
LQR控制器的核心目标是找到一个反馈增益矩阵,使系统能够在稳定性和控制成本之间达到最优平衡。控制律为:u=−Kx。
其中,𝐾 是反馈增益矩阵,𝑢 是控制输入,𝑥是状态向量。
反馈增益矩阵𝐾的求解过程是通过最小化一个二次代价函数来实现的,该代价函数通常表示为:
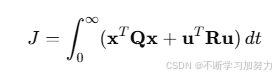
其中:
𝑄是状态误差的权重矩阵,表示对系统状态偏离目标的惩罚。
𝑅是控制输入的权重矩阵,表示对控制能量的惩罚。
2.系统模型和输入输出
LQR适用于线性时不变系统,其状态空间表示为:𝑥’(𝑡)=Ax(t)+Bu(t)
其中:
𝐴:系统矩阵,表示系统动力学。
𝐵:控制矩阵,表示控制输入对状态的影响。
在一个机器人路径跟踪项目中,LQR的输入与输出可以具体表示如下:
输入:
状态向量𝑥:通常包含机器人的位姿误差(位置和角度误差),可以从位置传感器(如激光雷达、相机、IMU等)测得当前位姿,然后与目标位姿进行对比得到误差。
目标位姿 𝑥target :期望的位姿,由路径规划模块提供。
权重矩阵𝑄:用来设定对位置误差和姿态误差的重视程度。
权重矩阵𝑅:用来设定对控制输入(如轮速)的重视程度,通常用于平衡对系统稳定性的需求和对控制能耗的要求。
输出:
控制输入𝑢:通常包含两个轮子的速度差(若为差速机器人),用于实现机器人的运动控制。
LQR具体的解释可以看我另外一篇博客。
https://blog.csdn.net/weixin_48386130/article/details/142924438?spm=1001.2014.3001.5501
3.求解过程(gpt)

4.为什么不选PID或者MPC
选择LQR的原因:LQR适合实时性要求高、已知模型、线性系统或已线性化系统的场景,例如路径跟踪和姿态控制等。LQR的计算效率高,适合嵌入式实现,不需要复杂约束管理。
PID的局限性:对于简单的系统,PID控制表现很好,但在多变量、耦合或高阶系统中无法满足性能需求,且调参难度较大。
MPC的局限性:MPC虽然具有良好的控制效果和预测能力,但实时计算开销较大,不适合实时性要求高的场景,尤其是在计算资源有限的情况下。
在实际应用中,PID控制器常用于简单的系统,而LQR和MPC则适合复杂的路径规划和姿态控制。在复杂多变量或多约束的场景中,MPC会更有优势,而LQR适合在已知线性系统或线性化系统中实现简单、高效的最优控制。
面试问起的话,先将两句LQR是什么,再将项目中实际输入输出,再将怎么计算说一下。
总结
其中有很多是gpt中的内容,还是需要理解后才能进行实际运用和面试。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











