







现代控制理论
第三章
说明:
介绍了状态反馈的形式,以及引入状态反馈配置极点的问题,进一步引出镇定问题
其中可能涉及到四阶行列式的计算,可以用“ Σ \Sigma Σ矩阵某一行元素*代数余子式”的方法算。
1. 状态反馈
对系统:
x ˙ = A x + B u y = C x \dot x=Ax+Bu\\ y=Cx x˙=Ax+Buy=Cx
引入状态正反馈:
u = K x + v u=Kx+v u=Kx+v
得到状态反馈系统:
x ˙ = ( A + B K ) x + B v y = C x \dot{x}=(A+BK)x+Bv\\y=Cx x˙=(A+BK)x+Bvy=Cx
框图:
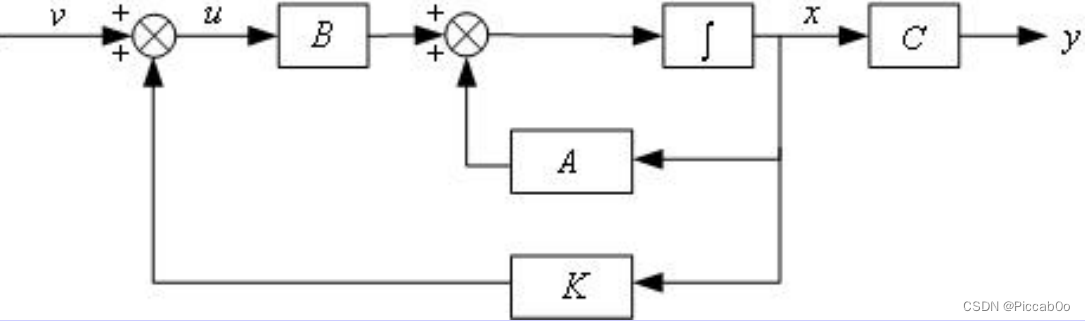
可以看出,状态反馈的引入改变了系统矩阵,但不改变能控性:

2. 状态反馈的闭环极点配置问题
目标:
通过状态反馈的引入,改变系统矩阵,使闭环极点定位于目标位置。
状态反馈极点配置的前提:
系统是能控的。
2.1 单输入系统的极点配置步骤:
① 根据A求出原系统的特征多项式: d e t ( s I − A ) = a 0 + . . . + a n − 1 s n − 1 + s n det(sI-A)=a_0+...+a_{n-1}s^{n-1}+s^n det(sI−A)=a0+...+an−1sn−1+sn
② 根据闭环极点求出目标多项式: α ( s ) = a ˉ 0 + . . . + a ˉ n − 1 s n − 1 + s n \alpha(s)=\bar a_0+...+\bar a_{n-1}s^{n-1}+s^n α(s)=aˉ0+...+aˉn−1sn−1+sn
③ 求出 K ^ = [ a 0 − a ˉ 0 , . . . , a n − 1 − a ˉ n − 1 ] \hat K=[a_0-\bar a_0,...,a_{n-1}-\bar a_{n-1}] K^=[a0−aˉ0,...,an−1−aˉn−1]
④ 计算变换矩阵,并求逆 T − 1 T^{-1} T−1:
T = [ A n − 1 b ⋯ A b b ] [ 1 a n − 1 ⋱ ⋮ ⋱ ⋱ a 1 ⋯ a n − 1 1 ] T=\begin{bmatrix}A^{n-1}b&\cdots&Ab&b\end{bmatrix}\begin{bmatrix}1\\a_{n-1}&\ddots\\\vdots&\ddots&\ddots\\a_1&\cdots&a_{n-1}&1\end{bmatrix} T=[An−1b⋯Abb] 1an−1⋮a1⋱⋱⋯⋱an−11
⑤ 确定反馈增益矩阵: K = K ^ T − 1 K=\hat KT^{-1} K=K^T−1
2.2 多输入系统的极点配置
情况相对复杂,需要对A进行分类讨论
1)A为循环矩阵时:

2)A不是循环矩阵时:

因此,只要 ( A , B ) (A,B) (A,B)能控,则一定存在状态反馈使闭环系统 ( A + B K , B ) (A+BK,B) (A+BK,B)有任意配置的极点。
同时,有:

说明:
对于多输入的系统(其实对于单输入系统也可),其可以采用“偷懒”的方法进行状态反馈配置,思路为:
根据期望配置的极点求出的特征多项式 α ( s ) = s 4 + 6 s 3 + 14 s 2 + 16 s + 8 \alpha(s)=s^4+6s^3+14s^2+16s+8 α(s)=s4+6s3+14s2+16s+8,我们可以得到期望的系统矩阵 A + B K A+BK A+BK为:
A + B K = [ 0 1 0 0 0 0 1 0 0 0 0 1 − 8 − 16 − 14 − 6 ] A+BK=\begin{bmatrix}0&1&0&0\\0&0&1&0\\0&0&0&1\\-8&-16&-14&-6\end{bmatrix} A+BK= 000−8100−16010−14001−6
由已知的 ( A , B ) (A,B) (A,B)可以反求出 K = . . . K=... K=...
2.3 状态反馈对传函零点的影响

对于多输入系统整体的零点也不变,但是状态反馈的引入可能改变某一元的零点。
3. 线性定常系统的镇定问题
定义:
对于引入状态反馈的系统,若增益阵 K K K使 A + B K A+BK A+BK的特征值全部位于左半平面,则称系统是能稳的。
→ 能控,则状态反馈可以任意配置极点,则一定能稳。
→ 需能控分解时,系统特征值是可控和不可控部分的组合,因此:

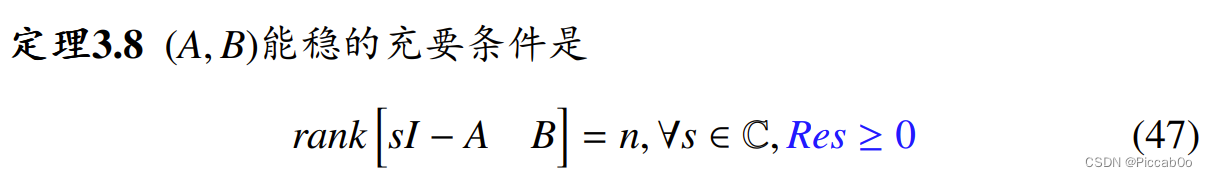
进一步,若系统能通过状态反馈构成的闭环系统,使之渐近稳定(特征值全部位于左半平面),则称是状态反馈可镇定的。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









