







 本文介绍了单细胞测序数据的细胞注释过程,包括根据文献和数据库进行细胞鉴别,使用CellMarker进行初步判断,并通过Seurat对象进行聚类。此外,还详细阐述了如何在无法连接ExperimentHub服务器的情况下,利用SingleR的本地数据库进行细胞注释,以及分析注释结果与主观判断的差异。最后,展示了注释结果的热图和DimPlot对比图,提供了一种美化绘图的方法。
本文介绍了单细胞测序数据的细胞注释过程,包括根据文献和数据库进行细胞鉴别,使用CellMarker进行初步判断,并通过Seurat对象进行聚类。此外,还详细阐述了如何在无法连接ExperimentHub服务器的情况下,利用SingleR的本地数据库进行细胞注释,以及分析注释结果与主观判断的差异。最后,展示了注释结果的热图和DimPlot对比图,提供了一种美化绘图的方法。
1.细胞鉴别
在上一步对各类细胞进行featureblot后,可以根据文献或者在线数据库来对细胞进行鉴别。此处我使用的是CellMarker网站。
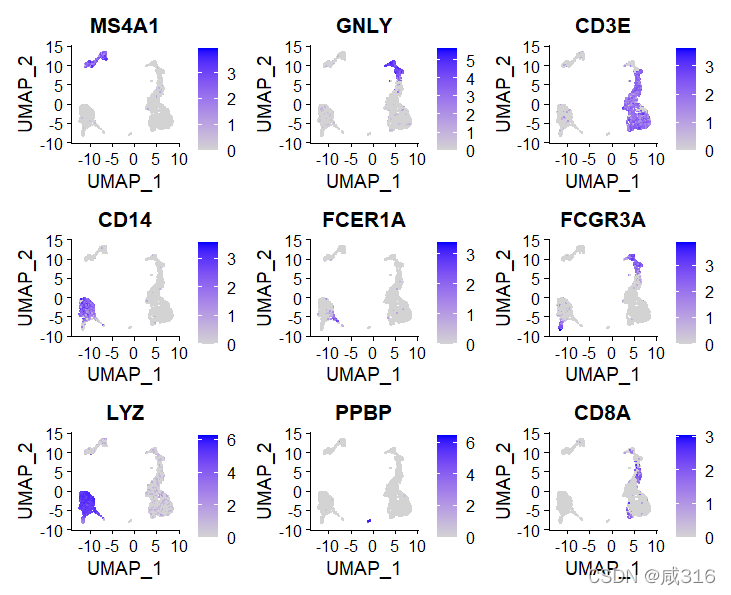
对照起来进行鉴别,但是有些细胞簇有两个marker,有些细胞簇的marker有重合,所以鉴别这一步具有比较大的主观性,需要结合多个数据库或者文献进行判断。
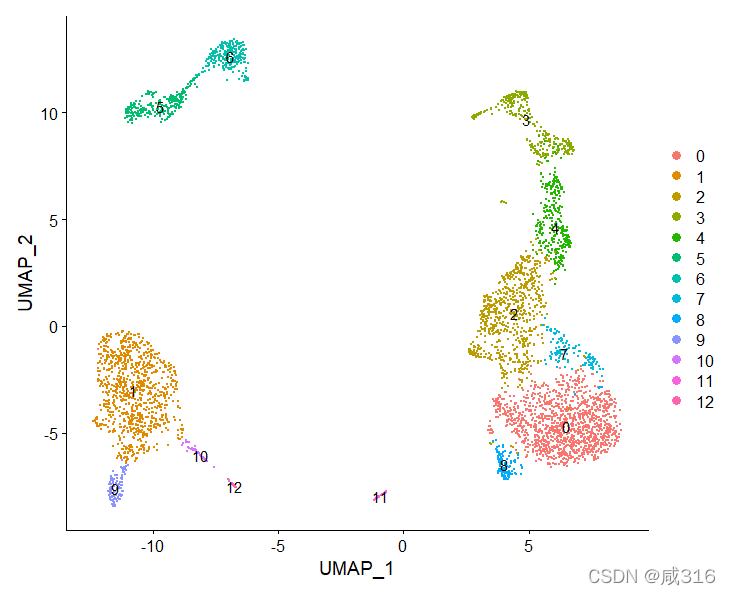
在完成鉴别后,创建一个新的字符向量保存细胞名称,顺序从0-12一一对应。
以下是我自己的判断结果:
new.cluster.ids <- c("Memory T cell","CD14+ Mono", "CD8 T",
+ "NK", "CD8 T", "B", "B", "undefined", "Cytotoxic T", "NK","DC",
+"Megakaryocyte progenitor cell","CD1C+_B dendritic cell")接下来,使用names()函数,将pbmc的levels和new.cluster.ids一一对应。
names<- 是通用替换函数。The default methods get and set the "names" attribute of a vector (including a list) or pairlist.用levels中的字符向量设置new.cluster.ids的names属性。
如果levels()比names()短,则会以NA填充names()。
names(new.cluster.ids) <- levels(pbmc)
> new.cluster.ids
0 1 2
"Memory T cell" "CD14+ Mono" "CD8 T"
3 4 5
"NK" "CD8 T" "B"
6  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1616
1616

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









