






预测噬菌体:宏基因组测序数据中噬菌体鉴定工具的基准测试

Article,2023-04-21,Microbiome,[IF 14.652]
DOI:https://doi.org/10.1186/s40168-023-01533-x
原文链接:
https://microbiomejournal.biomedcentral.com/articles/10.1186/s40168-023-01533-x
第一作者:Siu Fung Stanley Ho1
通讯作者:Willem van Schaik1
主要单位:
1英国伯明翰大学医学与牙科学院微生物与感染研究所
2英国莱斯特大学遗传学和基因组生物学系
- 摘要 -
在宏基因组数据集中预测噬菌体序列已经成为一个备受关注的话题,促进了许多新的生物信息学工具的发展。为了帮助微生物组研究中的工具选择,对十种最先进的噬菌体识别工具进行了比较分析。
由RefSeq完整基因组生成的人工contigs代表噬菌体、质粒和染色体,以及先前测序的包含四种噬菌体的模拟群落,用于评估工具的精度、召回率和F1分数。我们还生成了一个随机打乱序列的数据集,以量化假阳性判断。此外,还使用了一组先前模拟的病毒组来评估每种工具输出中的多样性偏差。
在RefSeq人工contigs数据集中,VIBRANT和VirSorter2获得了最高的F1分数(0.93),其他几个工具也表现良好。Kraken2在模拟群落基准中F1得分最高(0.86),比排名第二的DeepVirFinder高出0.3,这主要是因为它的精度很高(0.96)。一般来说,基于k-mer的工具比参考相似性工具和基于基因的方法表现更好。一些工具,尤其是PPR-Meta,在随机打乱的序列中发现了大量的假阳性。当分析每个工具从病毒组预测的基因组多样性时,大多数工具产生的病毒基因组集具有与原始种群相似的α和β多样性模式,但Seeker是一个例外。
本研究提供了用于评估噬菌体检测工具性能的关键指标,为进一步比较其他病毒发现工具提供了框架,并讨论了使用这些工具的最佳策略。我们强调,在宏基因组数据集中选择噬菌体鉴定工具及其参数可能会对结果产生偏差,并为不同的使用场景提供指导。我们还提供了我们的基准数据集供下载,以便于将来对噬菌体鉴定工具进行比较。
- 引言 -
噬菌体和古病毒在全球范围内普遍存在,种类繁多,在大多数生物群落中的数量通常超过其原核宿主。噬菌体在微生物群落中发挥着关键作用,通过促进共同进化关系、进行必需营养物质的生物地球化学循环,以及通过水平基因转移促进微生物进化,从而塑造和维持微生物生态。尽管噬菌体在所有微生物生态系统中都非常丰富且具有影响力,但它们仍然是复杂微生物群落中研究最少、理解最少的成员之一。噬菌体是专性寄生生物,它们需要宿主的细胞机制来复制,并通过细胞裂解进行传播。它们可以是溶菌性或温和性噬菌体,而前者只能遵循溶菌周期,温和性噬菌体则可以选择溶菌周期或溶原周期。在溶菌周期中,噬菌体会劫持宿主细胞的机械系统来产生新的病毒颗粒。在溶原周期中,噬菌体可以将其基因组整合到其细菌或古菌宿主基因组的染色体中,作为线性DNA或自我复制的自主质粒。此外,还记录了第三种生活周期,称为伪溶原性,在这种情况下,溶菌性噬菌体感染被中止,或者没有形成前噬菌体。
传统上,噬菌体的鉴定和表征依赖于分离和培养技术,这些方法耗时且通常需要丰富的专业知识。此外,由于许多宿主及其噬菌体无法在实验室条件下培养,这些方法往往不切实际。高通量下一代测序技术的出现使得可以常规地从各种环境中生成宏基因组数据。宏基因组测序允许直接鉴定和分析样本中所有的遗传物质,无论它们是否可培养。
宏基因组研究可以选择对整个群落的宏基因组进行测序,然后通过计算方法分离病毒序列,或者在文库制备前物理分离病毒组分,从而生成一个病毒基因组。后一种方法有可能由于噬菌体与细胞组分相关联而消除掉大量噬菌体。这种情况发生是因为噬菌体整合到其宿主基因组中作为前噬菌体,附着在宿主表面,或者处于伪溶原状态。净化方法也可能会去除某些类型的噬菌体,例如,氯仿可以使带有脂质包膜或丝状噬菌体失活,从而增加了取样偏差。这个过程还会导致DNA产量低,导致一些病毒组研究不得不使用多重置换扩增来获得足够数量的DNA用于文库生成。研究表明,MDA会显著偏向病毒组的组成,优先扩增小的环状单链DNA噬菌体,例如Microviridae科的噬菌体。尽管存在这些缺点,净化步骤产生的病毒组基因组中几乎没有宿主污染,尽管要生成完全没有任何细胞物质的病毒组分非常困难。病毒组基因组还具有在相同测序深度下能够鉴定低丰度噬菌体的优势,这是因为细菌和古菌的基因组大约比噬菌体的基因组大100倍,因此被排除在外。另一种选择是对整个群落进行宏基因组测序,这种方法可以同时提供宿主和病毒组分的见解,允许分析宿主-噬菌体的动态。由于在这个过程中宿主基因组也被测序,因此可以鉴定出一些环境中普遍存在的整合噬菌体或前噬菌体。在本研究中,我们重点关注从整个群落的宏基因组中计算提取噬菌体序列,因为相比于宿主,它们通常只占测序数据的一小部分。
在过去的五年里,已经开发了许多从混合的宏基因组和病毒组装中识别病毒序列的工具(表1)。VirSorter是其中最早的工具之一,之前的工具侧重于前噬菌体预测(如PhiSpy、Phage_Finder、PHAST/PHASTER、ProPhinder)或病毒组分析(如MetaVir2、VIROME)。VirSorter通过检测与参考数据库具有同源性的病毒标志基因,并基于不同指标(如病毒样基因、Pfam基因、未表征基因、短基因和链切换)构建概率模型来识别噬菌体序列,从而衡量每个预测的置信度。自VirSorter发布以来,已经开发了其他基于基因和同源性的工具,如VIBRANT和VirSorter2。
VIBRANT使用基于多个数据库的隐马尔可夫模型(HMM)命中的蛋白质注释的多层感知器神经网络来恢复感染细菌和古菌的各种噬菌体,包括整合的前噬菌体。此外,它在识别后还会表征辅助代谢基因和途径。VirSorter2在其前身的基础上,结合了五种不同的随机森林分类器,分别针对五个不同的病毒组,集成到一个算法中,以提高其准确检测病毒多样性的能力。与上述工具不同,MetaPhinder使用基于BLAST的同源性命中自定义数据库来计算平均核苷酸身份和序列具有病毒起源的可能性。
VirFinder是第一个利用k-mer特征的机器学习病毒识别工具。研究表明,VirFinder的病毒序列恢复率明显优于VirSorter,特别是在较短的序列(<5 kbp)上,但在不同环境中的表现存在差异,可能是由于用于训练机器学习模型的参考数据引入了偏差。DeepVirFinder通过应用卷积神经网络改进了VirFinder,该网络在包含环境病毒组测序数据的扩展数据集上进行了训练。与其前身VirFinder 相比,DeepVirFinder在所有contig长度上都显示出更高的病毒识别能力,同时减轻了VirFinder对于容易在实验室中培养的噬菌体的偏向。Kraken2是一种基于 k-mer的宏基因组分类器,可用于病毒检测。它通过查询 k-mer到数据库,并将其与最低共同祖先分类单元关联,从而用于分配分类标签。PPR-Meta使用三个卷积神经网络来识别序列是否来源于噬菌体、质粒或染色体。网络直接提取序列特征,而不是使用预先选择的特征,如k-mer特征或基因。这三个网络还针对不同长度的序列组进行了训练,以提高其在较短片段上的性能,而一些基于基因的工具由于可供分析的全长基因数量较少,在处理较短片段时表现不佳。Seeker也使用了神经网络,但采用的是长短期记忆(LSTM)模型,并且不基于预先选择的特征。MetaviralSPAdes采用了一种完全不同的方法,通过在组装图中利用病毒和细菌染色体深度的变化。该工具分为三个独立的模块:一个基于 metaSPAdes的专用组装程序(viralAssembly);一个使用朴素贝叶斯分类器将 contig分类为病毒/细菌/不确定的病毒识别模块(viralVerify);以及一个计算已构建的病毒contig与已知病毒相似性的模块(viralComplete)。
需要注意的是,机器学习工具有潜力识别新的物种,这在理论上尚未被充分认识到的噬菌体多样性方面尤为重要。随着采用多种方法开发了众多工具,迫切需要进行全面的比较和基准测试,以评估哪些工具最适合研究人员。每种方法的性能可能会根据样本内容、组装方法、序列长度、分类阈值和其他自定义参数而有所不同。为了解决这些问题,我们使用人工contig、模拟群落和真实样本对十种宏基因组病毒识别工具进行了基准测试。
表1 | 微生物生态系统中噬菌体序列鉴定和预测工具概述
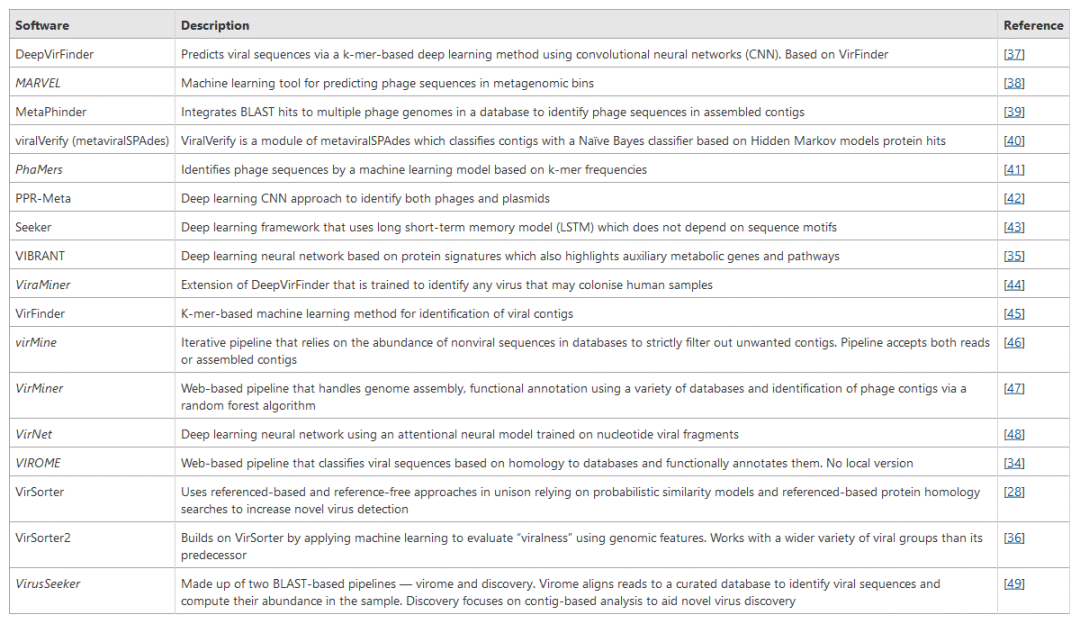
表中斜体表示工具未包含在本研究中,因为它们要么与本研究无关,要么在使用过程中遇到了技术问题。MARVEL被排除在外,因为它目前仅限于检测尾噬菌体目(Caudovirales)的噬菌体。
- 结果 -
使用RefSeq噬菌体和非病毒人工contigs进行基准测试
Benchmarking with RefSeq phage and nonviral artificial contigs
由于阴性数据集远大于阳性数据集,我们将阴性数据集下采样14.3倍,最终得到253条宿主染色体和309个宿主质粒(表2)。
表2 | RefSeq基准测试工作流程中每个阶段的序列数量
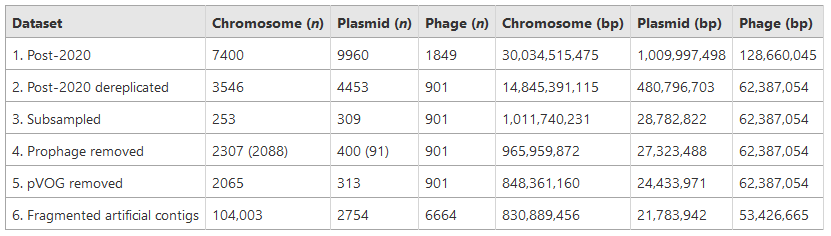
表中带有(n)标记的列表示每个步骤的序列数量,而带有(bp)标记的列表示每个步骤的碱基对数量。步骤编号如下:
1.从RefSeq下载的序列,这些序列在2020年1月1日至2021年8月12日期间存入。
2.从步骤1中提取的序列,然后与2020年1月1日之前存入RefSeq的序列及DeepVirFinder、Seeker、VIBRANT、VirFinder和VirSorter2的训练集进行去重复。
3.从步骤2中提取的宿主序列(染色体和质粒),并按14.3的因子进行采样。
4.从步骤3中提取的宿主序列,通过Phigaro和PhageBoost去除前噬菌体。括号中的数字表示移除的前噬菌体数量。
5.从步骤4中提取的宿主序列,其中开放阅读框有≥30%命中pVOG数据库的序列被移除。
6.从步骤5中提取的所有序列,随机并均匀地分割为1到15 kbp之间的大小,用于基准测试研究。
总共从染色体集合中移除2088个前噬菌体,从质粒集合中移除91个前噬菌体。随后,将这些序列分割成人工contig,并使用不同的工具进行分析(图1)。
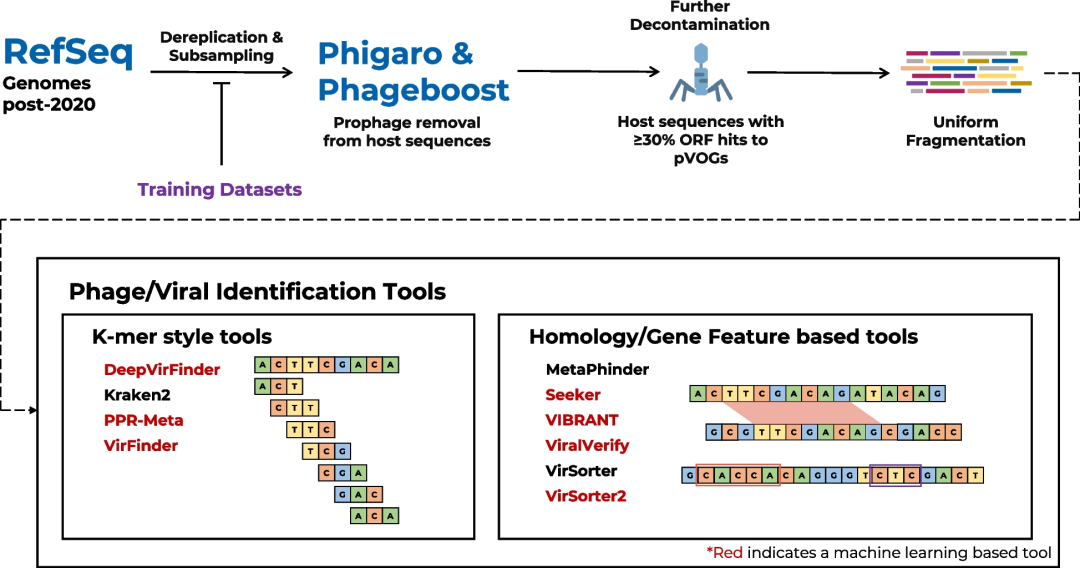
图1 | RefSeq基准测试工作流程等概述
下载了2020年1月1日至2021年8月12日期间存入RefSeq数据库的所有细菌和古菌的染色体、质粒以及噬菌体基因组。噬菌体基因组用于创建阳性测试集,而染色体和质粒用于创建阴性集。与每个基准测试的机器学习/深度学习工具(用红色标出)的训练集以及2020年前存入RefSeq的所有序列进行了去重复。为了模拟典型的肠道微生物群,阴性组采样,产生约1:19的阳性:阴性比例。使用Phigaro和PhageBoost鉴定并去除了前噬菌体。然后,删除了开放阅读框中有超过30%序列与原核病毒同源组数据库有命中的宿主序列。所有序列都被均匀地分割成长度在1-15 kbp之间的人工contig。最后,在这些人工contig集上运行了所有识别工具。
在大多数工具中,精确度和召回率之间存在权衡。这可能是由于放宽的阈值导致更多病毒和非病毒序列被检测到,从而增加召回率并同时降低精确度。对于VIBRANT和VirSorter,正性数据集分别以病毒组模式和病毒组去污模式运行,因为这可以通过调整工具的敏感性来提高主要由病毒序列组成的样本中的病毒恢复率。我们在该数据集上基准测试的工具在F1得分(0.44–0.93)、精确度(0.47–1.00)和召回率(0.46–0.96)方面表现出高度可变的性能(图2)。
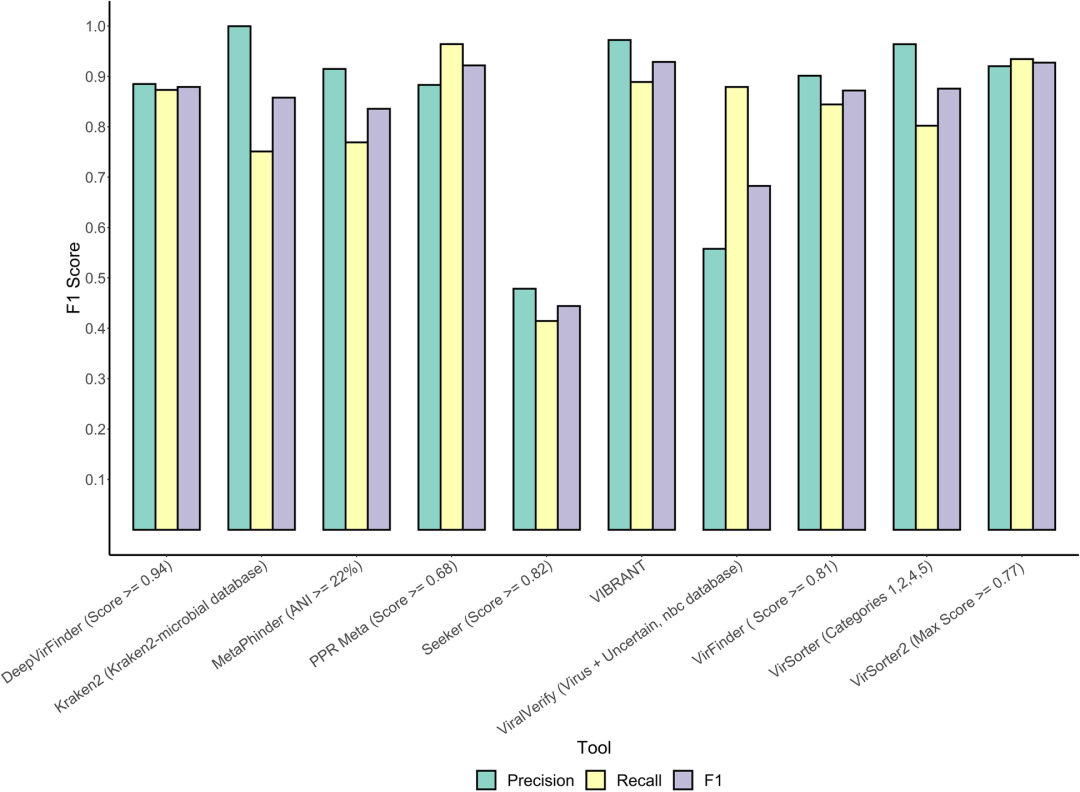
图2 | 人工RefSeq contig上的病毒识别工具对比
通过随机分割2018年1月1日至2020年7月2日期间存入NCBI参考序列数据库(RefSeq)的完整细菌/古菌/噬菌体基因组和质粒,生成了均匀分布的contig。然后分别在真实阳性(噬菌体基因组片段)和阴性(细菌/古菌染色体和质粒片段)数据集上运行每个工具。对于可以手动调整分数/概率阈值或分类的工具,根据最佳F1得分选择相应的值/分类。
使用随机打乱的序列对工具进行基准测试
Benchmarking tools with randomly shuffled sequences
为了进一步作为阴性对照,阳性RefSeq基准contig在核苷酸水平上被随机打乱,以生成任何工具都不应识别为病毒的序列。在测试的工具中,MetaPhinder、viralVerify、VirSorter和VirSorter2均未识别出任何打乱的contig,Kraken2分类了3个contig,DeepVirFinder和VirFinder分别检测到了742个和1070个,而其余工具则识别了超过2500个打乱的contig为病毒,其中PPRMeta错误地将99.2%(6608/6664)的打乱contig分类为病毒(表3)。
表3 | 在随机打乱的人工噬菌体contig上工具的性能表现

使用模拟群落宏基因组测序数据对工具进行基准测试
Benchmarking tools with mock community shotgun metagenomes
在RefSeq基准测试中找到的优化参数被用于每个工具,除了viralVerify和VirSorter。这些工具具有分类阈值,阈值的变化会显著改变识别出的病毒contig的特征,并且各阈值之间的F1得分非常接近,因此在本次基准测试中进一步分析了这些参数。总体而言,这些工具在该数据集上的F1得分明显低于在RefSeq人工contig上的得分,与RefSeq基准相比,F1得分平均下降了40.6%(见图3)。
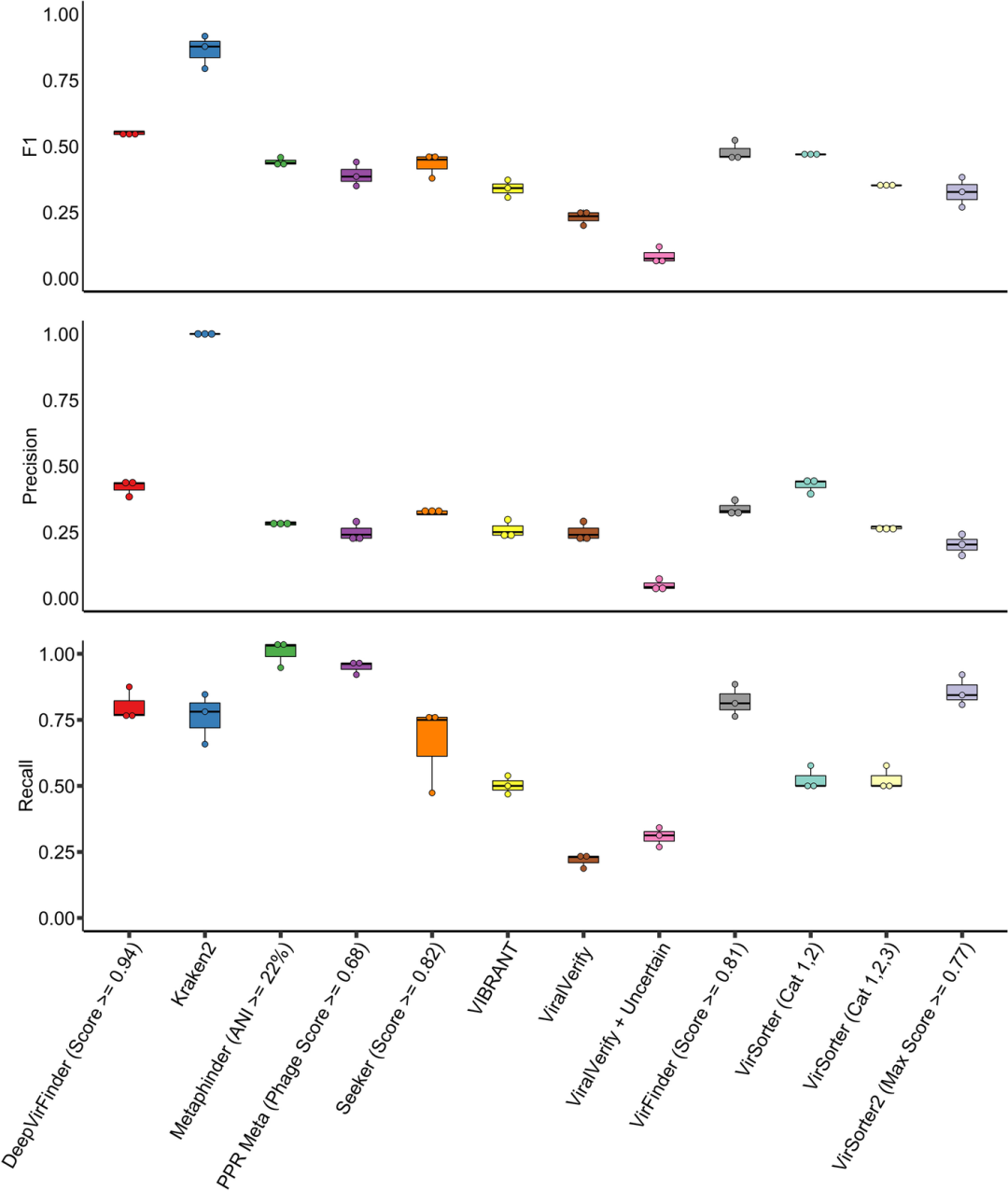
图3 | 病毒识别工具在不均匀模拟群体样本上的比对
模拟群体的reads来自于先前的研究,并使用metaSPAdes进行组装。在运行每个识别工具之前,使用Phigaro和PhageBoost检测并去除了前噬菌体,使用的阈值基于先前的基准测试优化,除了viralVerify和VirSorter。F1得分、精确度和召回率以单独面板显示。每个样本在每个工具上绘制为一个点,箱线图显示了所有三个样本的四分位范围、极值和平均值。
工具预测对多样性指标估计的影响
Impact of tool prediction on diversity metric estimation
与初始群体相比,所有工具每个样本返回的基因组数量都较少,尽管工具之间存在显著差异。PPR-Meta、MetaPhinder和Kraken2分别恢复了86.8%、89.1%和83.7%的基因组(图4A)。除了Seeker和viralVerify之外,其他所有工具都能恢复超过50%的基因组,Seeker和viralVerify分别仅恢复了32.4%和41.3%的群体基因组。从每个工具的计数矩阵计算得出的Shannon alpha多样性指数与默认群体相比,所有工具的H得分都在10%以内,除了Seeker,其H得分平均低了27.0%(图4B)。Simpson alpha多样性指数表现相似,所有工具的多样性得分与初始群体相比在1%以内,除了DeepVirFinder和Seeker,分别相差1.4%和5.1%(图4C)。PPR-Meta是唯一一个估计的alpha多样性指数比默认群体更高的工具。在beta多样性方面,除Seeker外,所有工具在样本内的成对Bray-Curtis相异性较小,Seeker的相似性分析(ANOSIM)与其他工具相比显示出显著的相异性(r = 0.3926,p = 0.0019,使用Benjamini-Hochberg修正进行多重比较,FDR = 0.05)(图4D;附加文件8)。
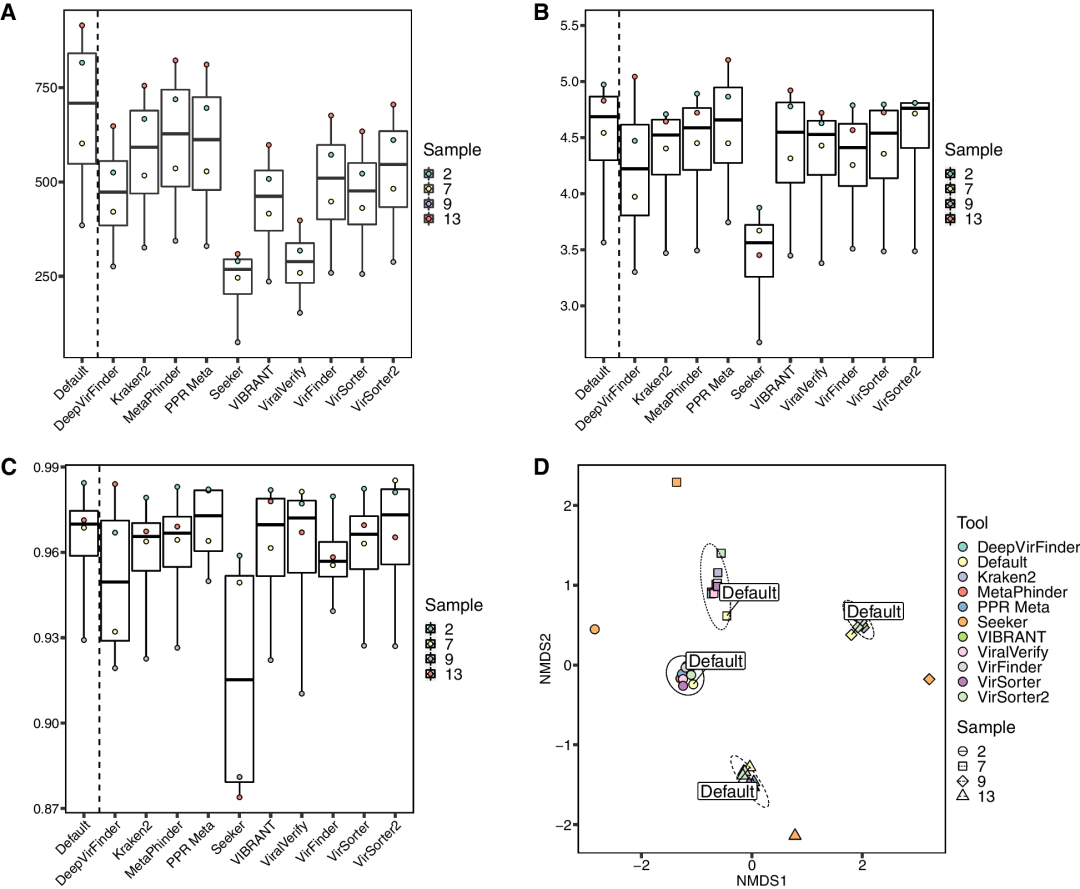
图4 | 工具预测的病毒群落多样性指标估算
为了评估每个工具对群落多样性的影响。下载了Roux等人的四个模拟病毒组装体。然后运行每个程序以确定预测的病毒contig子集。将reads映射到这些contig子集,并将映射的reads随后映射到一个群落contig池中。所有多样性指标均由R包“vegan”计算。每个图中的“Default”表示每个样本的原始组装。
A. 从reads映射到各工具预测的病毒contig群落中观察到的基因组数量。
B. 各工具的病毒组子集的香农多样性指数估算。估算基于经过contig大小和病毒组测序深度标准化的reads计数。
C. 各工具的病毒组子集的辛普森多样性指数比较。
D. 各病毒识别工具预测的病毒组子集的Bray-Curtis相异性的非度量多维尺度(NMDS)排序图。椭圆表示每个样本簇中心的95%置信区间。样本由相同的符号和椭圆线型表示;工具由颜色区分。
每个工具的运行时间和计算负载
Runtime and computational load of each tool
我们还记录了每个工具在高性能集群(16个虚拟CPU,108 GB内存)上运行RefSeq阳性数据集的时间(图5)。Kraken2和VirFinder是最快的工具,均在5分钟内完成。DeepVirFinder、MetaPhinder、PPR-Meta和Seeker在半小时内完成,而viralVerify稍超出这一时间。VirSorter和VirSorter2在该数据集上的运行时间最长,分别为2.9小时和3.8小时。
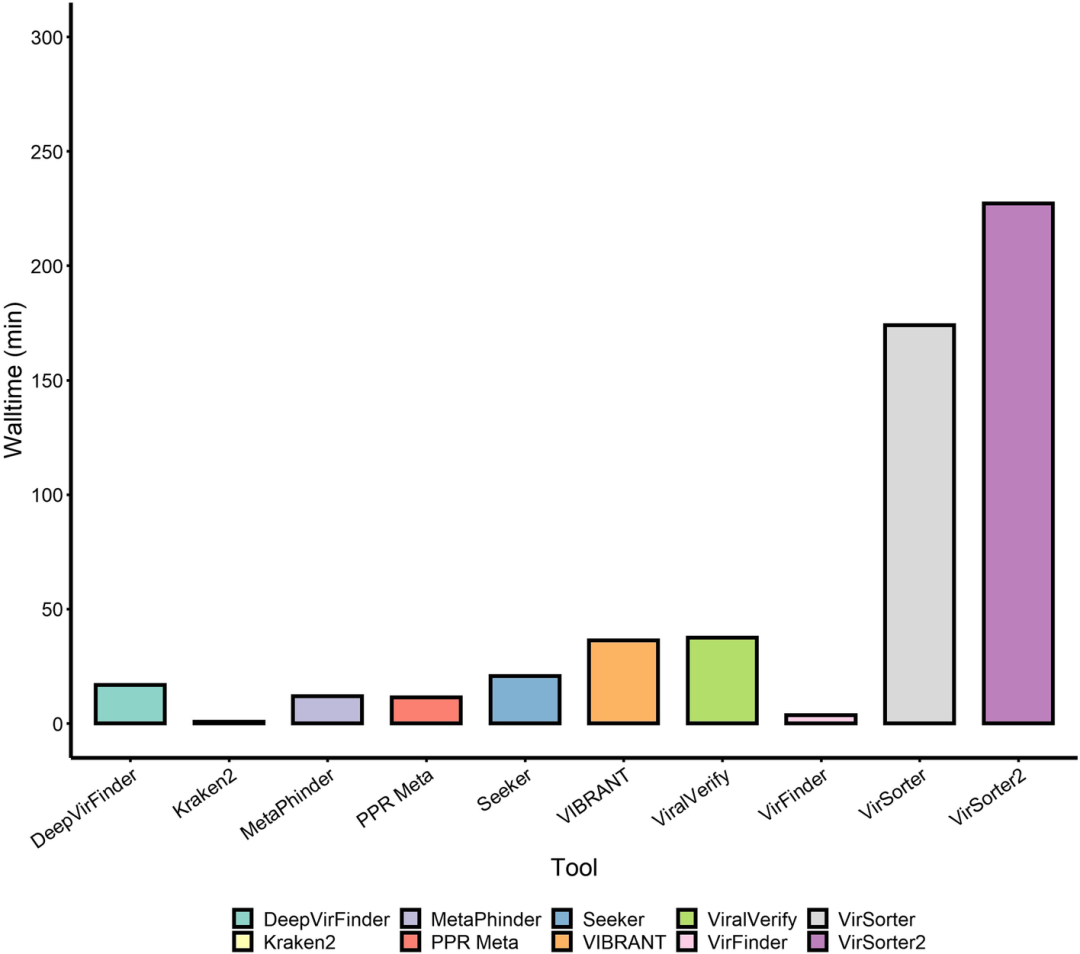
图5 | 工具在阳性RefSeq人工contig集上的运行时间对比
记录了每个工具在模拟群体样本上的Wall runtime,运行环境为16个虚拟CPU、108GB内存的Linux高性能集群,未使用GPU加速。对于可以设置线程数的工具(除了MetaPhinder、PPR-Meta和Seeker之外的所有工具),使用了16个线程进行运行。RefSeq阳性集大约包含5340万bp。
- 讨论 -
噬菌体是几乎所有地球生态系统中微生物群落的重要成员,它们不仅负责控制宿主种群的规模,还对群落功能产生更广泛的影响。设计用于从混合群落宏基因组和病毒组样本中恢复病毒序列的工具对于研究噬菌体在其环境中的作用至关重要。该领域的进展已经产生了一系列广泛的病毒鉴定工具,每个工具都声称在性能上优于类似工具。因此,在这些工具中选择最适合数据集的工具并非易事,尤其是每种新工具通常只与两到三种现有工具进行基准测试。大多数为此目的开发的工具,特别是近年来发布的工具,已经利用机器/深度学习来分类序列,而其他工具则依赖于根据序列与数据库中序列的相似性进行分类。这两种方法都有可能随着新发现的病毒基因组被添加到训练数据集和数据库中而逐步改进。
在本文中,我们在三个数据集上比较了十种识别宏基因组中病毒序列的方法。我们首先在正、负数据集上对这些工具进行了基准测试,以评估它们在理想片段集(大小在1至15 kbp之间,无错误组装)上的表现,并确定了大致的最佳阈值。在这一阶段,大多数工具表现良好,检测到了大部分噬菌体序列,同时保持了较低的假阳性率。PPR-Meta、VIBRANT 和 VirSorter2,这三种使用不同机器学习方法的工具,在所有工具中表现最佳。通常,k-mer 工具的表现优于基于参考相似性和基因的工具。虽然我们确定的最佳阈值可能并不适合所有其他数据集,但我们认为它们可以作为进一步使用这些工具的基础,因为在每种情况下,它们都比默认参数产生了显著更好的结果。因此,我们鼓励研究人员在其预期数据集的背景下应用这些阈值和参数。噬菌体的分类并未影响工具的病毒预测,而染色体和质粒的分类则揭示了几个工具中的偏差。因此,在分析宏基因组时,重要的是要考虑在采样的微生物生态系统中可能存在哪些噬菌体宿主,以及所选病毒预测工具的偏差是否会影响下游分析。
在分析随机打乱的噬菌体序列的识别时,可以明显看出机器学习工具与更传统工具之间的鲜明对比。在使用机器/深度学习方法的六个工具中,有五个工具将相当大比例的序列识别为病毒,唯一的例外是VirSorter2,可能是因为它的分类器经过了一系列序列和基因特征的训练。其他四个工具中有三个返回了零假阳性,而Kraken2只返回了三个假阳性。这突显了虽然这些机器/深度学习算法具有检测新型噬菌体的能力,但当暴露于特征与训练集中的特征不同的新数据时,其表现可能会难以预测。
在实际宏基因组数据上进行测试时,大多数工具的表现显著低于在RefSeq基准测试中的表现,Kraken2和Seeker是例外。总体而言,与基于参考相似性/基因的工具相比,k-mer工具的F1得分从RefSeq基准测试中下降的幅度较小。这可能是由于从宏基因组读取数据中组装的噬菌体序列相对较短,提供的遗传背景较少,从而对参考相似性和基因工具的算法产生负面影响。MetaPhinder是唯一能够检测到在每个样本中组装的M13噬菌体单个片段的工具。不幸的是,这可能是由于MetaPhinder在此基准测试中的低精度导致了许多假阳性结果。大多数其他工具能够识别属于其他三个噬菌体的片段,Seeker除外,它只能识别每个样本中最丰富的噬菌体F0。这表明,当分析噬菌体物种可能稀少的宏基因组数据集时,基于k-mer的工具如Kraken2和DeepVirFinder是最佳选择,前者在精度特别重要时是首选,而后者由于其深度学习算法,如果对发现新型噬菌体感兴趣则适合使用。
我们还评估了这些工具对其预测的病毒群体多样性可能产生的潜在偏差和影响。大多数工具在Alpha多样性指数上表现良好,与默认群体相比,差异在10%以内,Seeker除外,其返回值明显较低,这是由于Seeker最初预测的病毒群体基因组数量非常少。一些工具如PPR-Meta预测的Alpha多样性高于默认群体。这是因为这些工具在其预测中遗漏了一些高丰度的基因组,导致了更均匀的多样性分布。在评估Beta多样性时,Seeker是唯一一个与其他工具的结果存在显著差异且未与其他程序聚类的工具,再次因为它在此数据集中恢复的基因组比例较低。因此,除Seeker外,这些工具的Beta多样性趋势与原始群体一致,即使只恢复了一半的基因组。
运行时间和计算负载也是需要考虑的重要因素,因为如果大样本需要数小时或数天的时间来分析,这些因素可能会成为实际限制。尽管VirSorter及VirSorter2需要数小时才能完成运行,但大多数工具运行速度还是相当快。需要注意的是,VIBRANT、VirSorter和VirSorter2会对识别出的病毒基因组进行注释并预测前噬菌体,这虽然会增加运行时间,但对于某些应用可能非常有用。Kraken2是迄今为止最快的工具,在我们的数据集上运行不到一分钟。然而,Kraken2与其他基准工具相比需要非常高的内存使用,因此对于计算能力有限的研究人员来说,可能不可行。
虽然这些基准测试全面比较了最先进工具的性能,但我们的研究仍存在一些局限性。首先,尽管我们使用RefSeq基因组和模拟的宏基因组群落对这些工具进行了基准测试,但我们并未评估这些工具识别属于不同噬菌体家族的病毒序列的能力。其次,我们使用了每个工具提供的默认数据库或原始训练模型。虽然为每个工具提供相同的数据库或数据集进行训练可能更公平地比较其底层算法,但这超出了我们研究的范围。我们注意到,大多数常规用户在使用这些工具之前也不太可能重新训练它们。第三,我们没有评估组合多种工具的性能,组合使用可能提供的见解在只使用单一工具时会被忽略,例如Marquet等人的研究中,作者将多种工具组合到一个工作流程中。第四,许多工具具有额外的功能,我们在此并未进行基准测试,但这些功能可能会影响研究人员的工具选择,例如前噬菌体预测(VIBRANT、VirSorter、VirSorter2)、质粒预测(PPR-Meta)、分类鉴定(Kraken2)和功能注释(VIBRANT)。最后,我们在研究过程中发现的几种最近开发的工具没有纳入基准测试,原因是(1)需要使用其自己的Web服务器,因此无法扩展(VIROME、VirMiner),(2)缺乏清晰的安装/运行说明(ViraMiner),或(3)在尝试使用该工具时出现错误,我们无法解决(PhaMers、VirNet、VirMine)。
- 结论 -
我们对目前可用的十种宏基因组病毒/噬菌体鉴定工具进行了比较分析,为其他研究人员提供了有价值的指标和见解,以供他们参考和扩展。通过使用模拟群落和人工数据集,可以计算这些工具的精确度、召回率和偏差。通过调整每个工具的病毒鉴定过滤阈值并比较F1分数,我们能够在每种情况下优化其性能。在人工RefSeq片段基准测试中,大多数工具表现良好,其中PPR Meta、VIBRANT 和VirSorter2的F1分数最高。在模拟不均匀群落数据集中,除了Kraken2之外,其他工具的表现普遍较差,Kraken2的表现几乎达到了完美的精确度,并且召回率也高于平均水平。除了Seeker之外,所有工具都能够生成与原始病毒群落相似的多样性概况,因此适用于噬菌体生态学研究。我们建议,在目前可用的宏基因组噬菌体鉴定工具中,Kraken2应该被考虑用于识别之前已表征的噬菌体。当需要检测新型噬菌体时,应将Kraken2与VirSorter2和DeepVirFinder等工具结合使用。
- 材料与方法 -
使用RefSeq数据集进行基准测试
自2020年1月1日(含当日)以来存入RefSeq的完整细菌和古菌染色体、质粒序列以及噬菌体基因组,于2021年8月12日下载,用于构建基准测试集。使用dedupe.sh工具删除了与2020年前RefSeq序列和DeepVirFinder、PPR Meta、Seeker、VIBRANT、VirFinder和VirSorter的训练数据集具有≥95%同一性的序列,以减少潜在的过拟合。然后使用BBTools套件中的reformat.sh工具随机下采样染色体和质粒序列,采样比例为14.3倍,以产生约19:1的宿主:噬菌体比例。使用Phigaro(v2.3.0,默认设置)和PhageBoost(v0.1.7,默认设置)依次对染色体和质粒序列进行处理,以去除前噬菌体序列。具有≥30%开放阅读框(ORF)并在pVOG数据库中命中的宿主序列被作为污染物移除。然后使用自定义Python脚本(可从https://github.com/sxh1136/Phage_tools获取)将所有序列统一切割成1到15 kbp之间的片段,以创建人工片段。然后在三组片段(染色体、质粒和噬菌体)上以默认设置运行每个病毒预测工具,VIBRANT和VirSorter除外,这两个工具在处理噬菌体衍生片段集时额外使用了它们的病毒组去污染模式,因为在主要由病毒片段组成的数据集中,这种模式可能会提高性能。
各工具命令及其版本号:
https://github.com/sxh1136/Phage_tools/blob/master/manuscript_tools_script.md
RefSeq基准测试数据集:
https://figshare.com/articles/dataset/RefSeq_Datasets_for_benchmarking_-_Ho_et_al_/19739884
对于可以手动调整分数/概率阈值的工具(如DeepVirFinder、MetaPhinder、PPR Meta、Seeker和VirFinder),绘制了F1曲线(100个数据点),并通过最大F1得分确定了最佳阈值。对于viralVerify和VirSorter,这两者具有噬菌体识别的分类阈值,绘制了具有最高F1得分的类别集;对于VirSorter,比较了两个类别集,分别是类别1、2、4和5以及所有类别,因为这些类别是常用的。ViralVerify还使用了Pfam-A 33.0和提供的病毒/染色体特异性HMM数据库进行了额外的运行,这些在工具的GitHub使用指南中列出。Kraken2使用了预构建的kraken2-microbial数据库进行运行,该数据库可从https://lomanlab.github.io/mockcommunity/mc_databases.html获取。Kraken2识别为病毒的两个染色体片段的参考基因组从NCBI RefSeq下载(NC_CP059254.1和NZ_CP07771.1)。使用pharokka对片段和参考基因组进行注释,并使用clinker进行全局比对和可视化。工具真阳性和假阳性病毒预测的分类信息通过R包taxonomizr v 0.10.3进行检索。
在这个数据集上每个工具的运行时间是使用由Cloud Infrastructure for Big Data Microbial Bioinformatics(CLIMB-BIGDATA)提供的Linux虚拟机记录的,配置如下:CPU:Intel® Xeon® Processor E3-12xx v2(8 VCPU),GPU:Cirrus Logic GD 5446,内存:64-GB多位ECC。工具运行时设置为16个线程(MetaPhinder、PPR-Meta和Seeker除外)。
随机打乱序列的基准测试
在前一个基准测试中创建的所有人工噬菌体片段都使用HMMER3套件中的esl-shuffle工具(v3.3.2,-d)在保持二核苷酸分布的情况下进行随机重排。然后在随机重排的序列上使用在RefSeq基准测试中确定的优化阈值运行每个识别工具,并记录假阳性结果。
模拟群落宏基因组的基准测试
从欧洲核苷酸档案库(BioProject PRJEB19901)中检索了不均匀模拟群落的三个宏基因组测序重复样本。这些群落包含五种噬菌体菌株:ES18(H1)、F0、F2、M13和P22(HT105)。使用FASTQC(v0.11.8,默认设置)检查数据质量,并使用cutadapt(v2.10,–max-n 0)移除过度表达的序列。然后使用MetaSPAdes(v3.14.1,默认设置)对清理后的双端读取序列进行组装,并移除长度小于1 kbp的contigs。随后,通过依次运行Phigaro和PhageBoost来从contigs中移除前噬菌体,就像处理RefSeq染色体和质粒数据集一样。然后在这三组contigs上使用先前确定的最佳参数运行每个工具,但对viralVerify和VirSorter进行了所有分类阈值的重新评估。使用MetaQUAST(v5.0.2,默认设置)将contigs映射到参考噬菌体基因组并计算覆盖率。
模拟病毒群落的基准测试
Roux等人创建的四个包含500到1000个病毒基因组的模拟群落(样本13、2、7和9)被选中进行分析。这些样本属于四个不同的β多样性组,且其50种最丰富的病毒没有重叠。每次模拟产生的1000万对双端读取序列都经过Trimmomatic的质量控制,并由Roux等人使用MetaSPAdes进行组装。然后下载这些contigs进行基准测试。与之前一样,长度小于1 kbp的contigs被移除,并输入到每个病毒识别程序中。随后提取每个工具的阳性病毒contig集合,并使用BBMap将读取序列映射到这些集合中,对于模糊映射的读取序列,随机分配到contigs中(ambiguous=random),如Roux等人所述。然后使用SAMtools(v1.11)提取主映射读取序列及其配对均映射到同一contig的序列(选项 -F 0×2 0×904),并将其映射到非冗余人工contigs池中。该池是通过使用nucmer(v3.1)对所有四个样本进行聚类而创建的,聚类标准为≥ 95% ANI(平均核苷酸一致性)且长度≥ 80%。通过将读取计数标准化为contig长度和总文库大小来计算每个工具的丰度矩阵,从而生成每百万计数(CPM)。然后使用vegan包(v2.5.7)计算这些丰度矩阵的Shannon、Simpson和Bray-Curtis不相似性指数。还使用vegan计算了非度量多维尺度分析(NMDS)和相似性分析(ANOSIM)。ANOSIM的p值经过了Benjamini-Hochberg方法的校正。种子和置换分别设置为123和9999(如果可能)。所有图表均由ggplot2(v3.3.2)生成,并通过ggpubr(v0.4.0)的ggarrange进行排列。
参考文献
Ho, S.F.S., Wheeler, N.E., Millard, A.D. et al. Gauge your phage: benchmarking of bacteriophage identification tools in metagenomic sequencing data. Microbiome 11, 84 (2023). https://doi.org/10.1186/s40168-023-01533-x
- 作者简介 -
第一作者

伯明翰大学
微生物与感染研究所
Siu Fung Stanley Ho
博士后研究员
Siu Fung Stanley Ho何兆锋(音译), 伯明翰大学微生物与感染研究所博士后研究员,正在开发一门宏基因组生物信息学课程,以解决通过污水向河网释放抗生素的问题。
了解更多:
https://uk.linkedin.com/in/stanley-ho-microbiology
通讯作者

伯明翰大学
微生物与感染研究所
Willem van Schaik
教授
Willem van Schaik教授,伯明翰大学微生物学和感染研究所主任。他在分子微生物学、人类微生物组和抗生素耐药性领域发表了 80 多篇论文,h指数51。他的主要研究方向是分析共生细菌进化为具有多重耐药性的机会性病原体的机制,以及分析复杂微生物生态系统中的抗生素耐药性基因库("耐药性基因组")。
了解更多:
https://www.birmingham.ac.uk/staff/profiles/microbiology-infection/van-schaik-willem
宏基因组推荐
本公众号现全面开放投稿,希望文章作者讲出自己的科研故事,分享论文的精华与亮点。投稿请联系小编(微信号:yongxinliu 或 meta-genomics)
猜你喜欢
iMeta高引文章 fastp 复杂热图 ggtree 绘图imageGP 网络iNAP
iMeta网页工具 代谢组MetOrigin 美吉云乳酸化预测DeepKla
iMeta综述 肠菌菌群 植物菌群 口腔菌群 蛋白质结构预测
10000+:菌群分析 宝宝与猫狗 梅毒狂想曲 提DNA发Nature
一文读懂:宏基因组 寄生虫益处 进化树 必备技能:提问 搜索 Endnote
16S功能预测 PICRUSt FAPROTAX Bugbase Tax4Fun
生物科普: 肠道细菌 人体上的生命 生命大跃进 细胞暗战 人体奥秘
写在后面
为鼓励读者交流快速解决科研困难,我们建立了“宏基因组”讨论群,己有国内外6000+ 科研人员加入。请添加主编微信meta-genomics带你入群,务必备注“姓名-单位-研究方向-职称/年级”。高级职称请注明身份,另有海内外微生物PI群供大佬合作交流。技术问题寻求帮助,首先阅读《如何优雅的提问》学习解决问题思路,仍未解决群内讨论,问题不私聊,帮助同行。
点击阅读原文

















 4524
4524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









