






前言
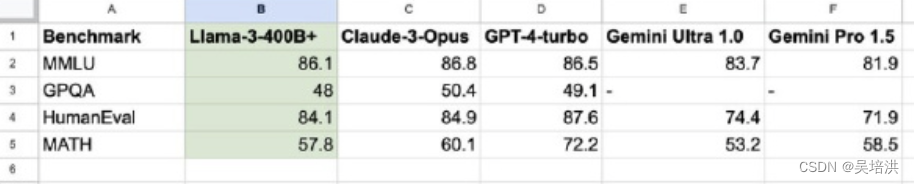
4月18日,Meta终于正式发布全新一代开源模型Llama3,为训练这个模型,投入了49152块H100的GPU,经大咖们评测,这是比肩GPT4的开源大型,下图是多个场景的测试对比。
出于个人兴趣和好奇,我也花了点时间进行了私有化的部署,并基于AnythingLLM打造了一个知识库,现分享一下部署的过程,希望越来越多的人投入到大模型的应用开发中,一起交流打造良好的生态。
先展示成果
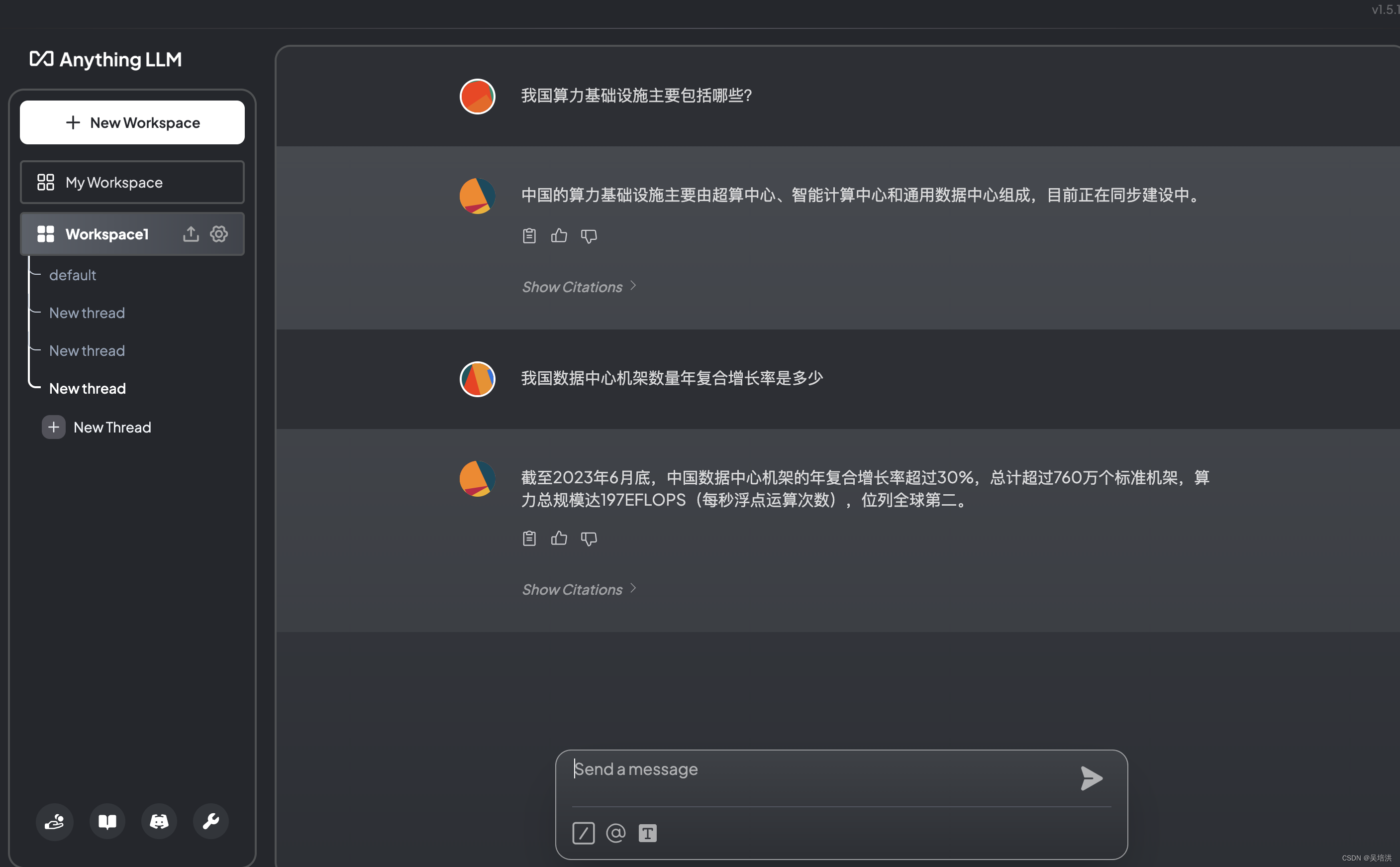
我上传了这篇文章《中国信通院余晓晖:推动算力基础设施高质量发展》到大模型知识库中,文章有一段内容如下:

对大模型提问,如下结果,还是令人很满意的:
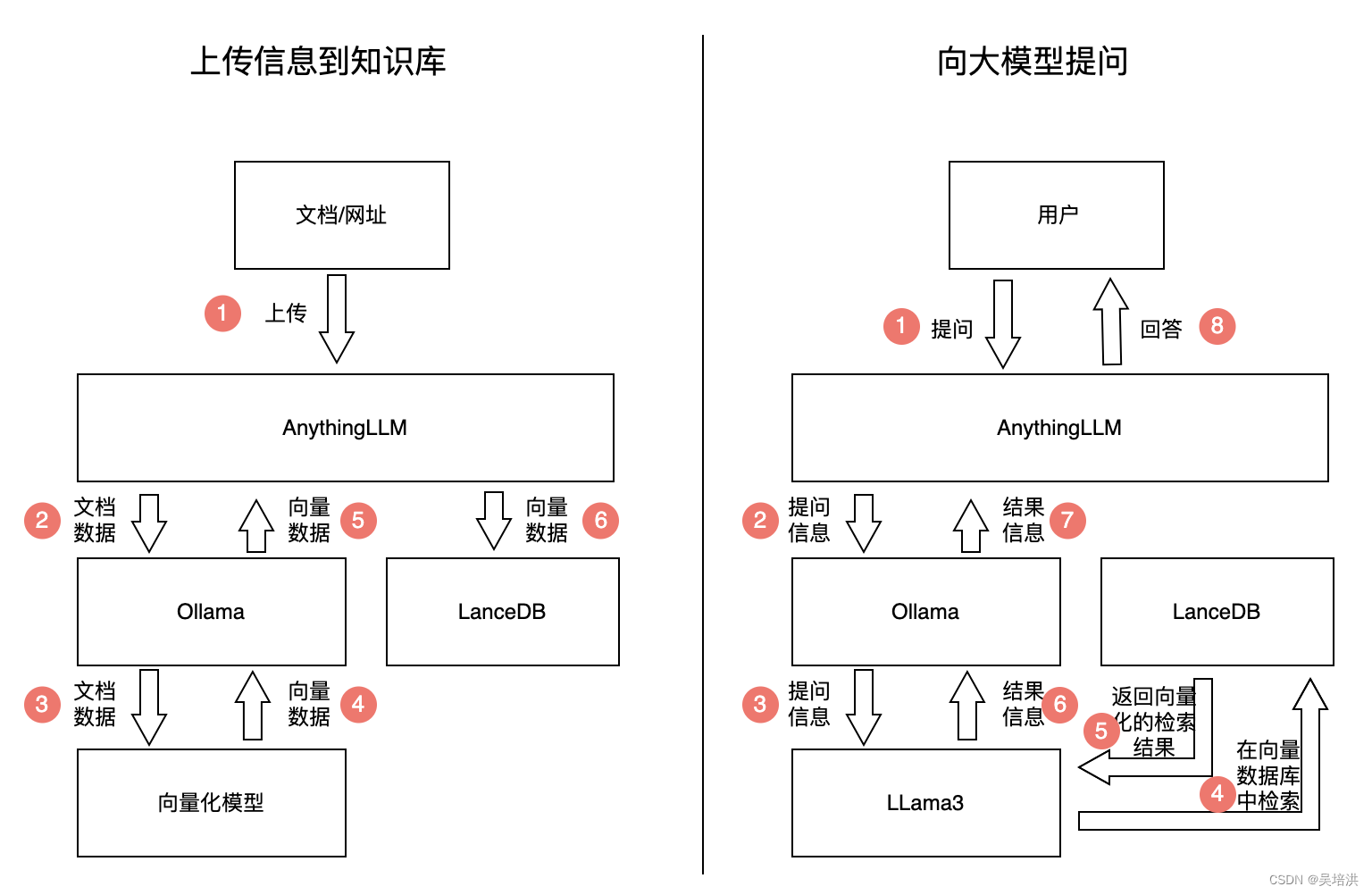
知识库整体架构
使用Ollama部署Llama3,由于Llama3自身对中文支持不好,所以此次部署的是王慎执博士对llama3微调之后的8B版本,大模型采用8位量化,向量数据库用的是LanceDB。知识库整体架构及访问流程如下:
部署
基于以上架构,需要部署的组件时Ollama,Llama3,AnythingLLM,LanceDB(AnythingLLM自带,不需要单独部署)
部署Ollama及Llama3
在linux服务器中执行命令,在线下载并安装Ollama和Llama3
#安装ollama
curl -fsSL https://ollama.com/install.sh | sh
#下载llama3
ollama run wangshenzhi/llama3-8b-chinese-chat-ollama-q8修改ollama配置
vim /etc/systemd/system/ollama.service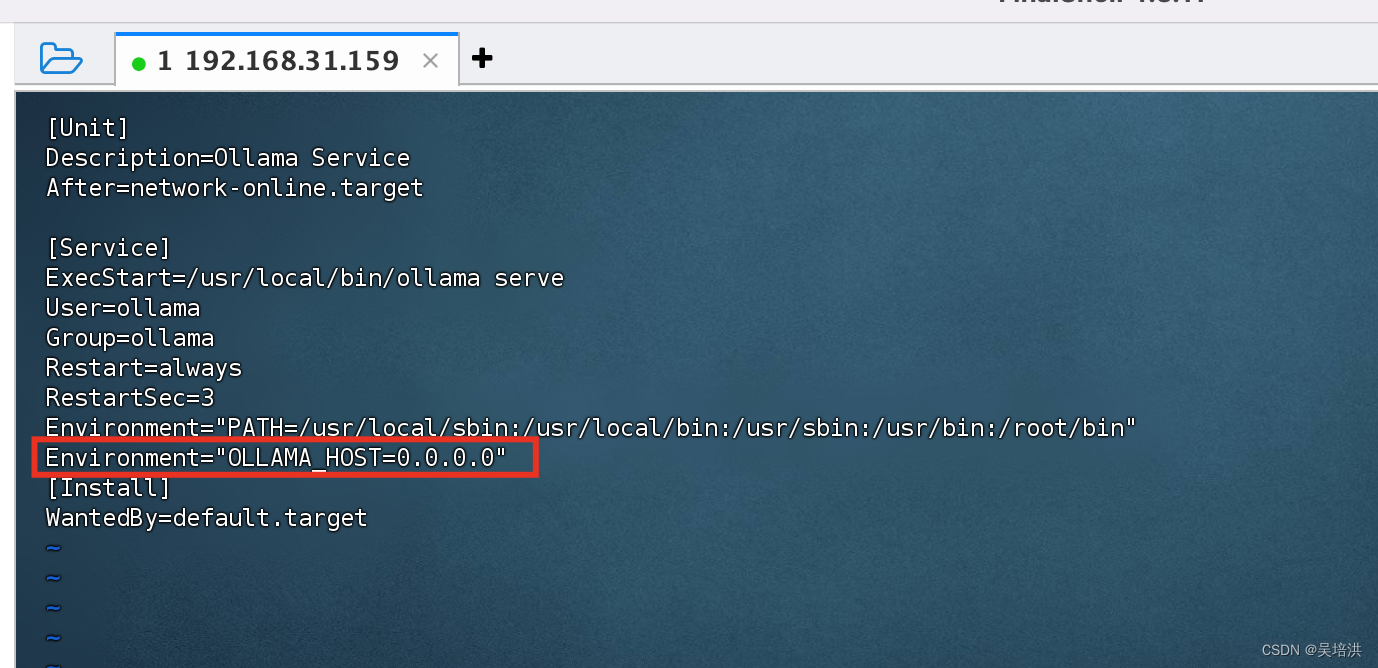
#重启ollama
systemctl restart ollama
systemctl daemon-reload
#将ollama访问端口加到防火墙
firewall-cmd --zone=public --add-port=11434/tcp --permanent
#重启防火墙
firewall-cmd --reload部署AnythingLLM
以下是下载的网站,根据系统的不同,下载对应的版本安装即可
配置AnythingLLM
打开AnythingLLM,页面如下:
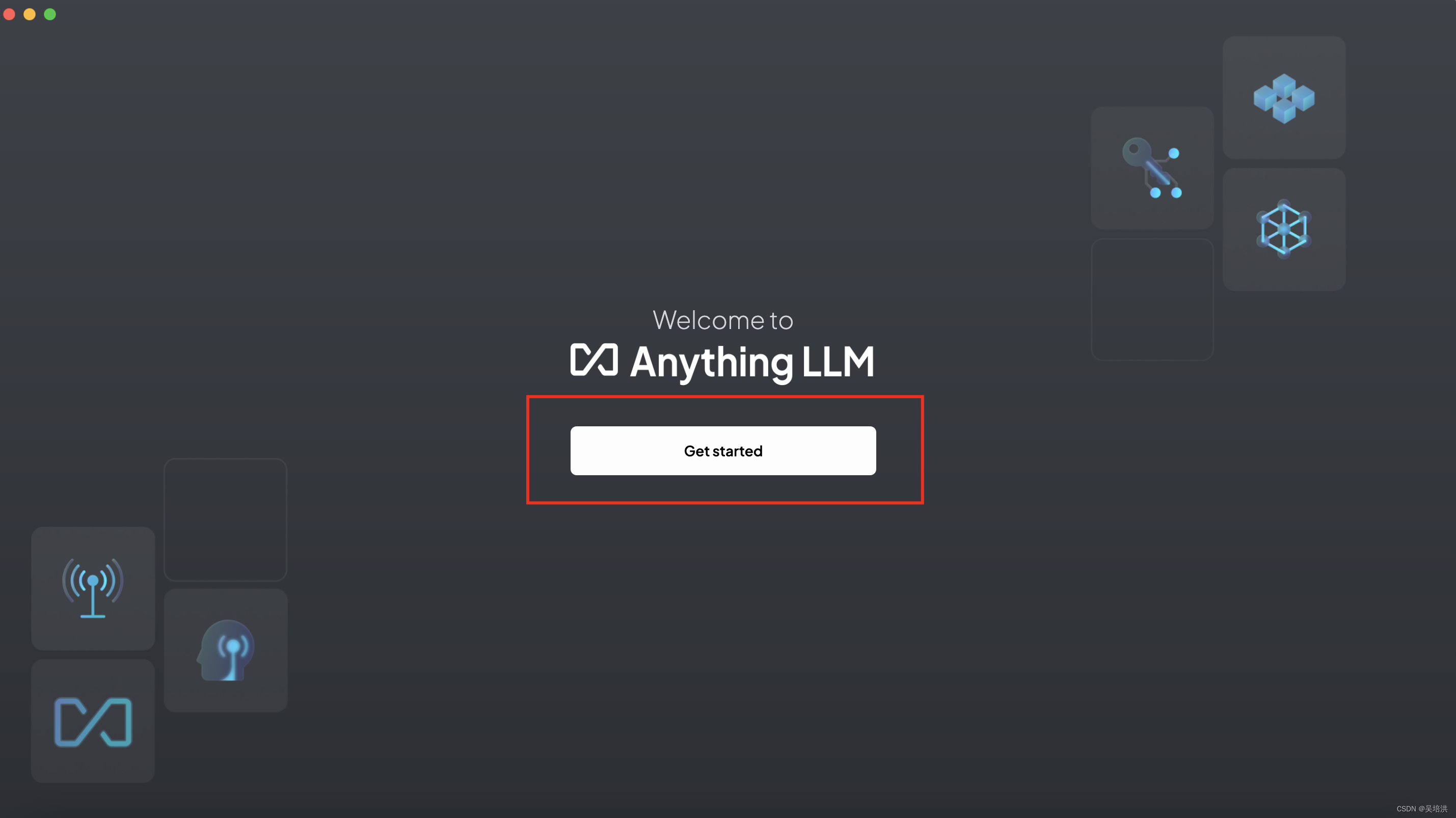
选择Ollama,输入Ollama的服务器地址,选择已经部署好的大模型,一直点右边的箭头到最后完成即可。
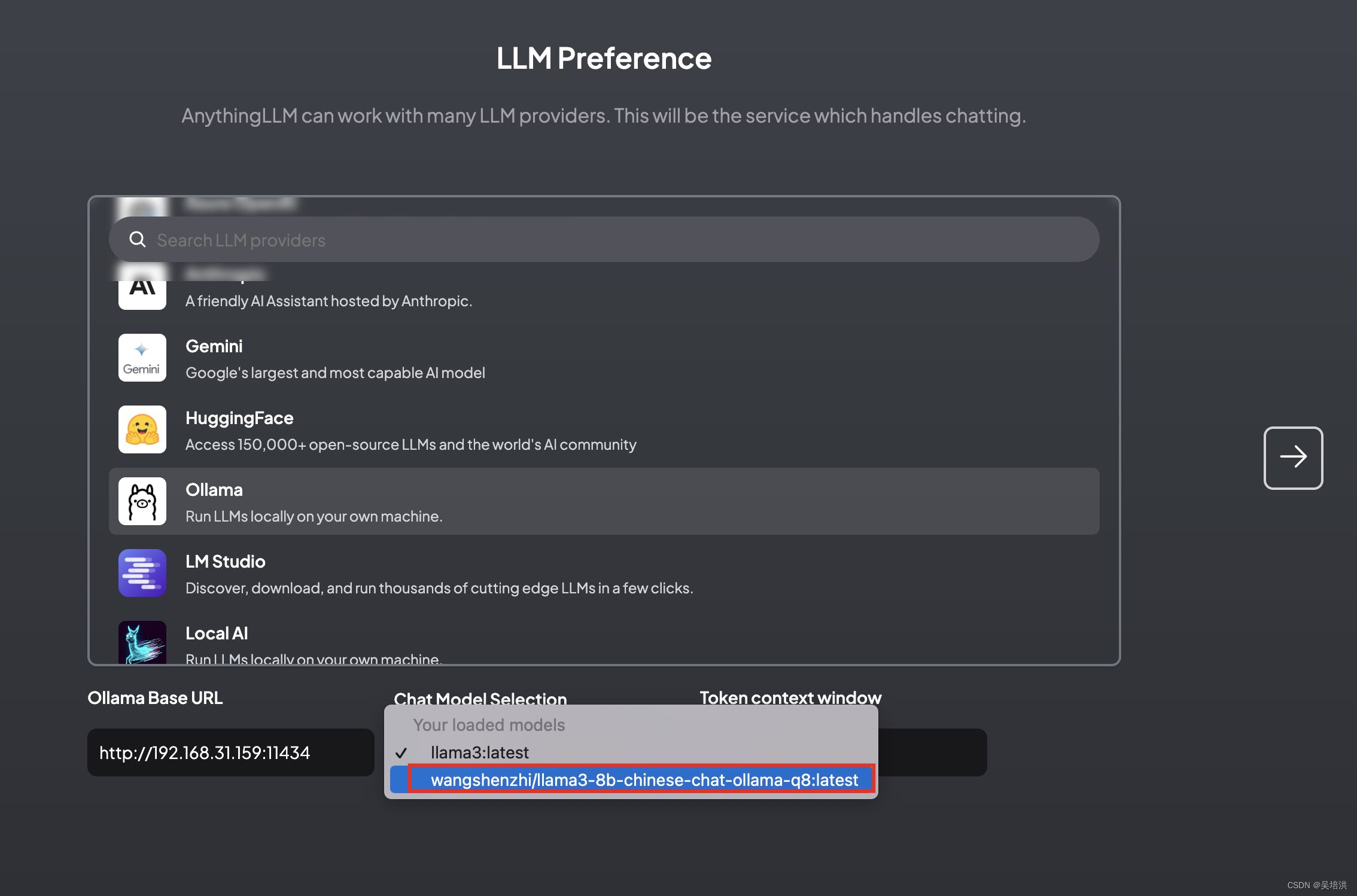
点击小扳手进入设置界面
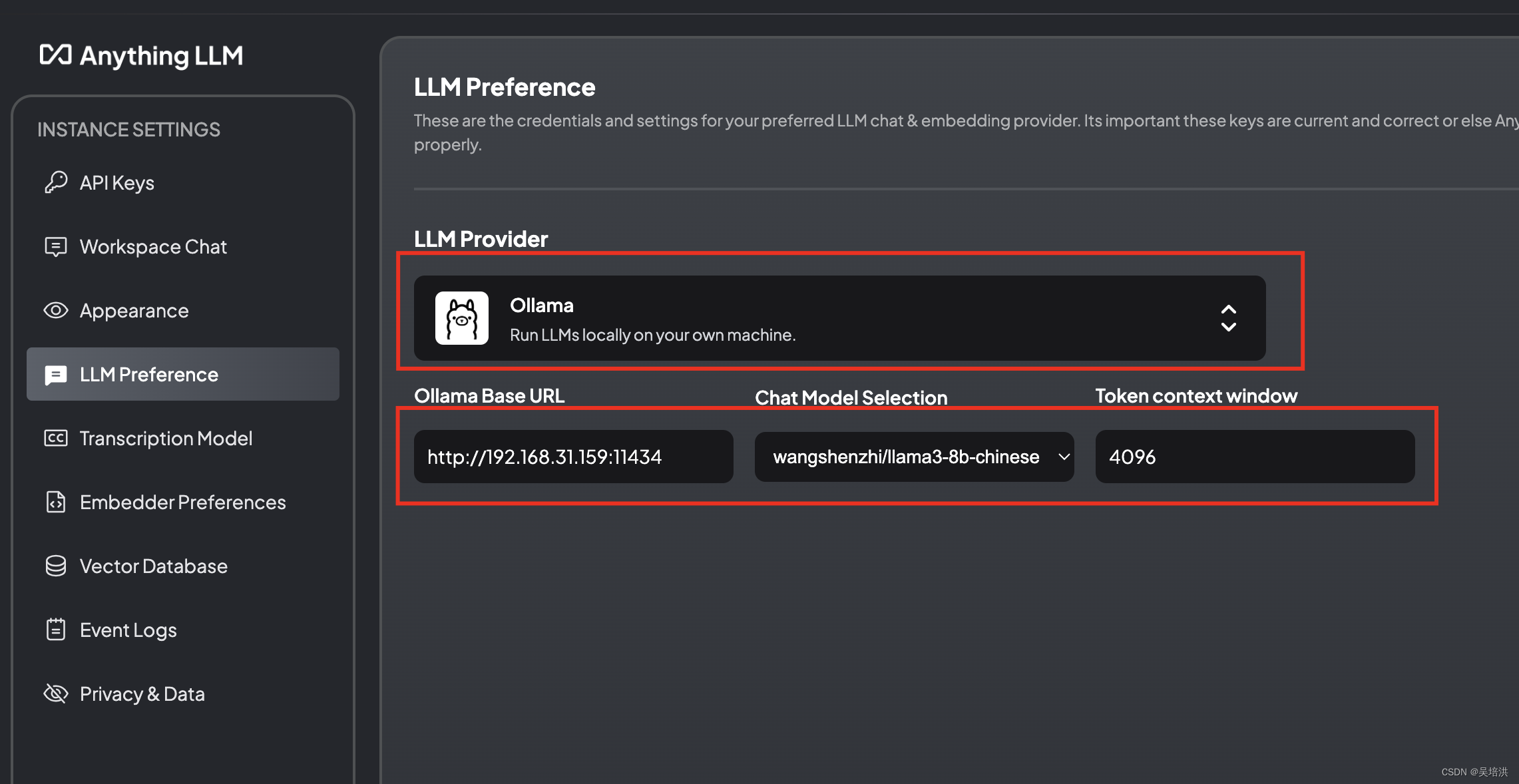
查看大模型的参数配置,输入大模型的本地访问地址
配置Embedding模型的参数,这里也配置大模型的地址
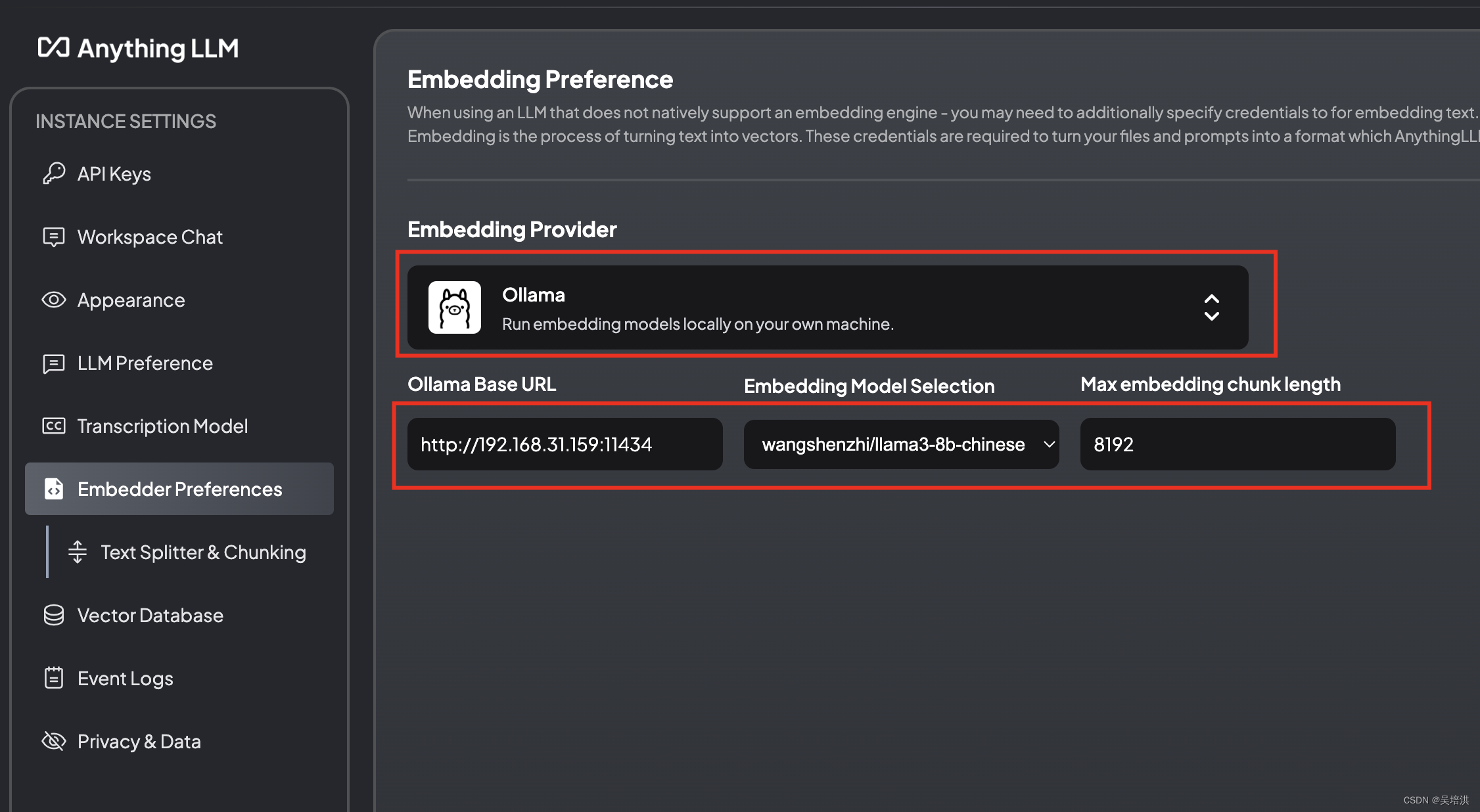
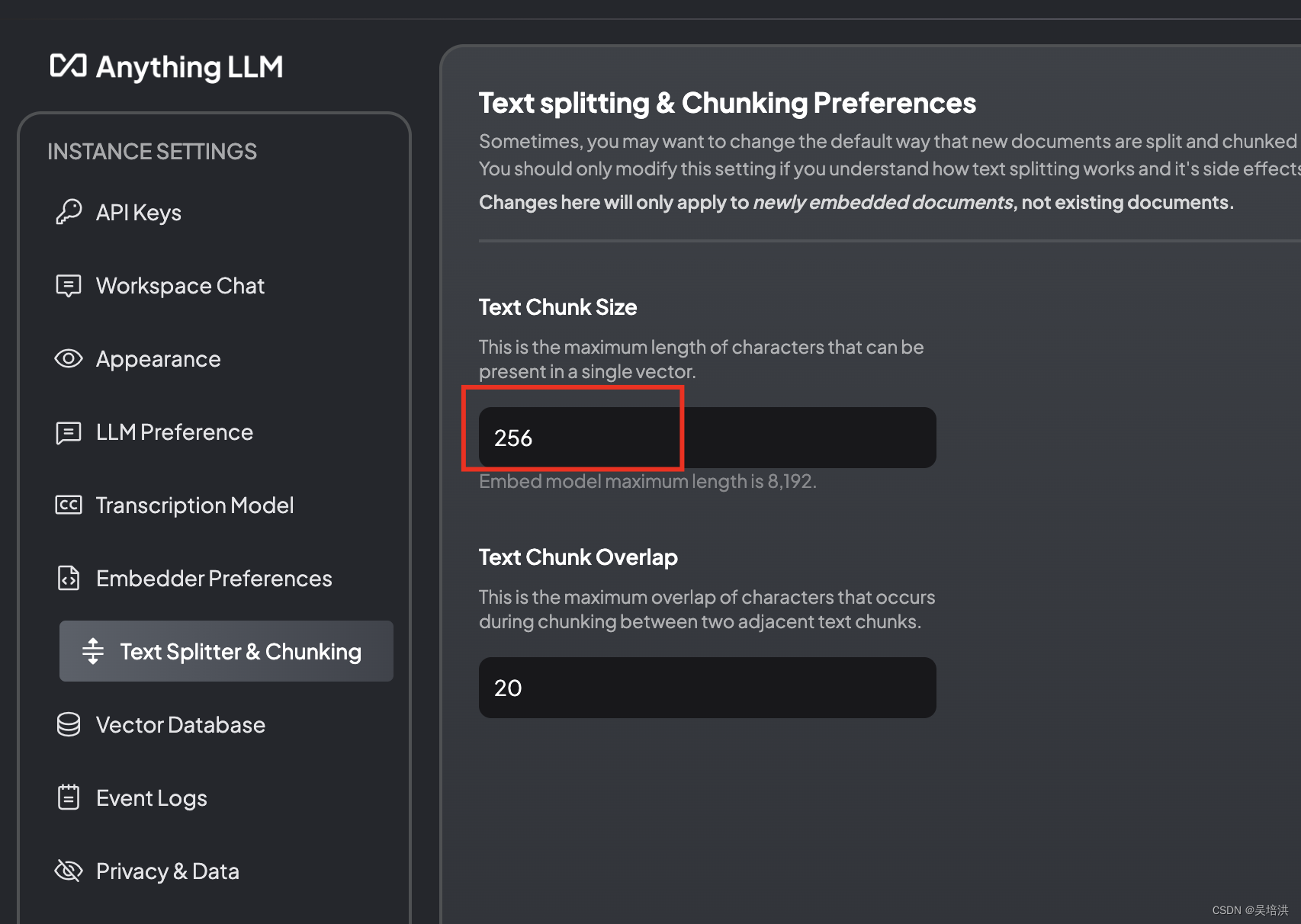
调整Chunk大小,可以根据回答的结果准确性微调
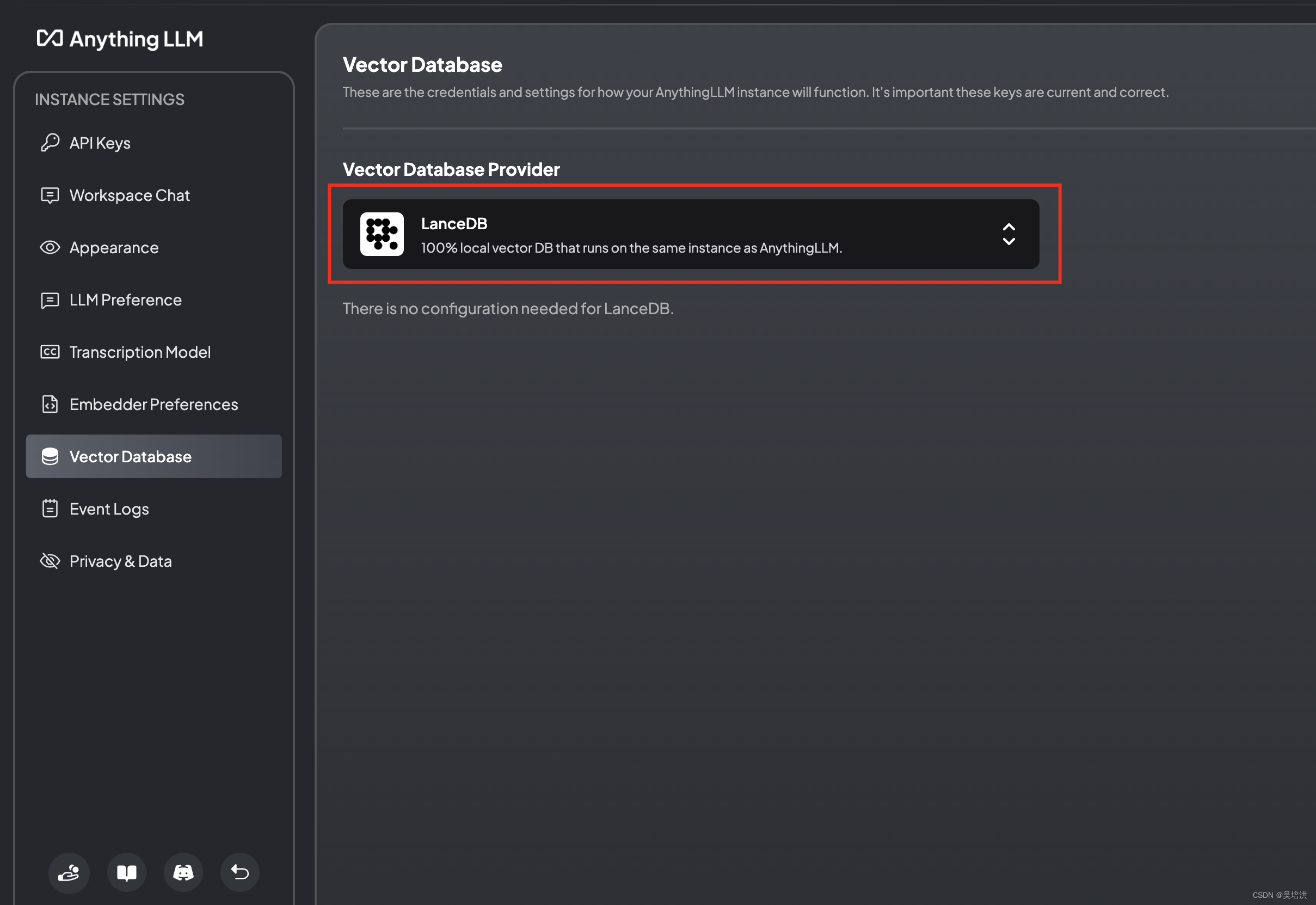
配置向量数据库
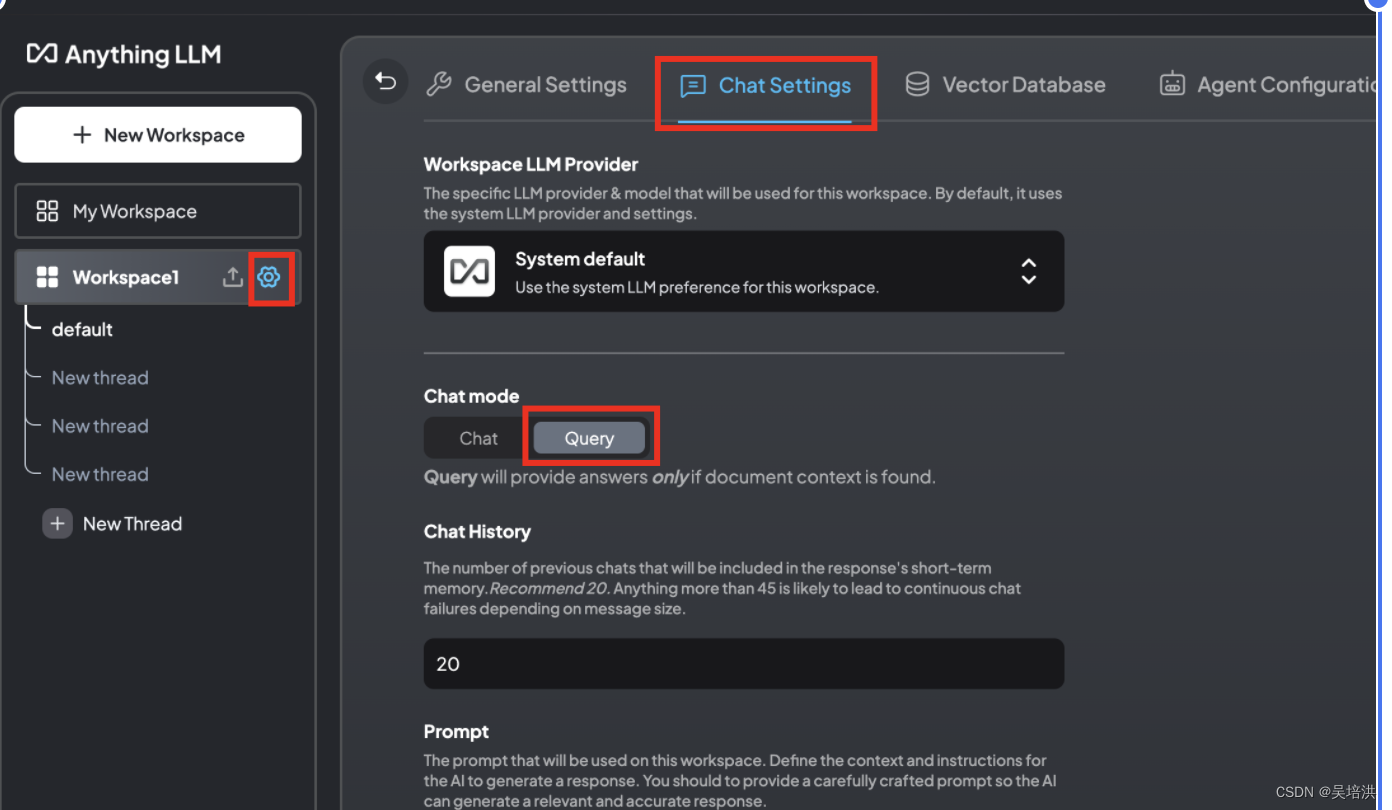
workspace配置
配置对话模式为Query,仅从知识库中获取答案并回答
进入主界面后,创建一个workspace,点击上传箭头,会弹出一个页面,可以将文件上传到知识库
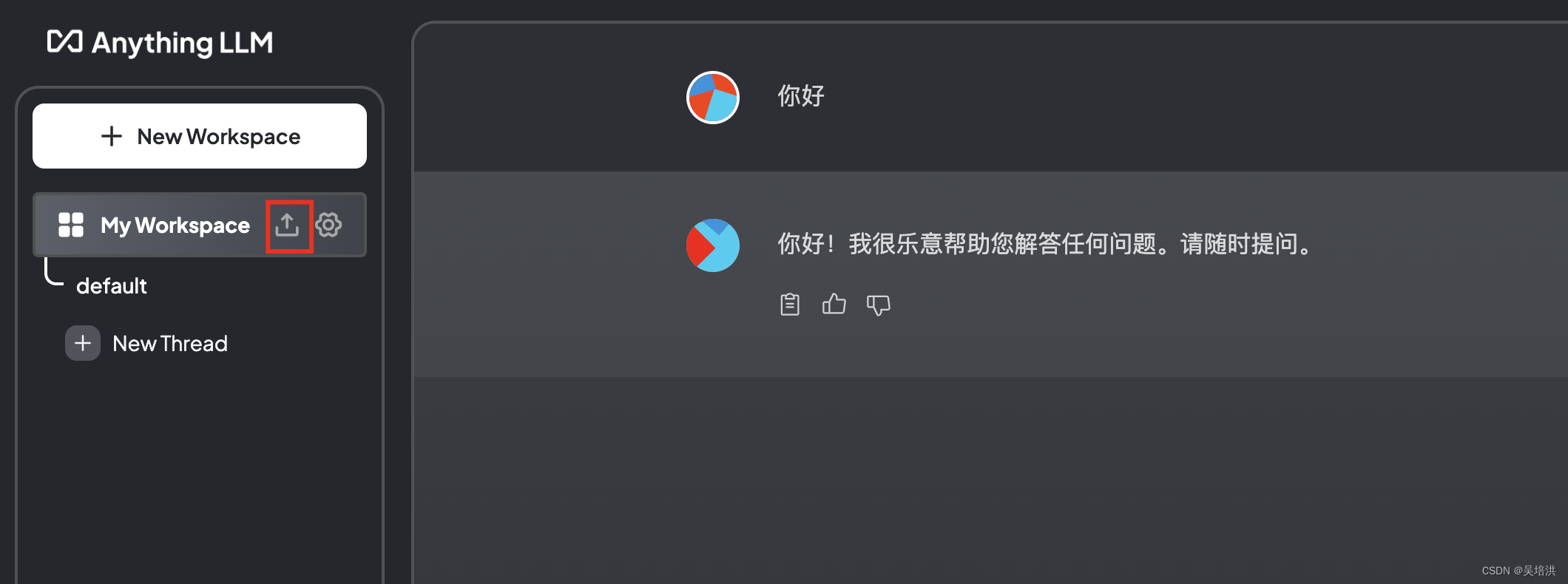
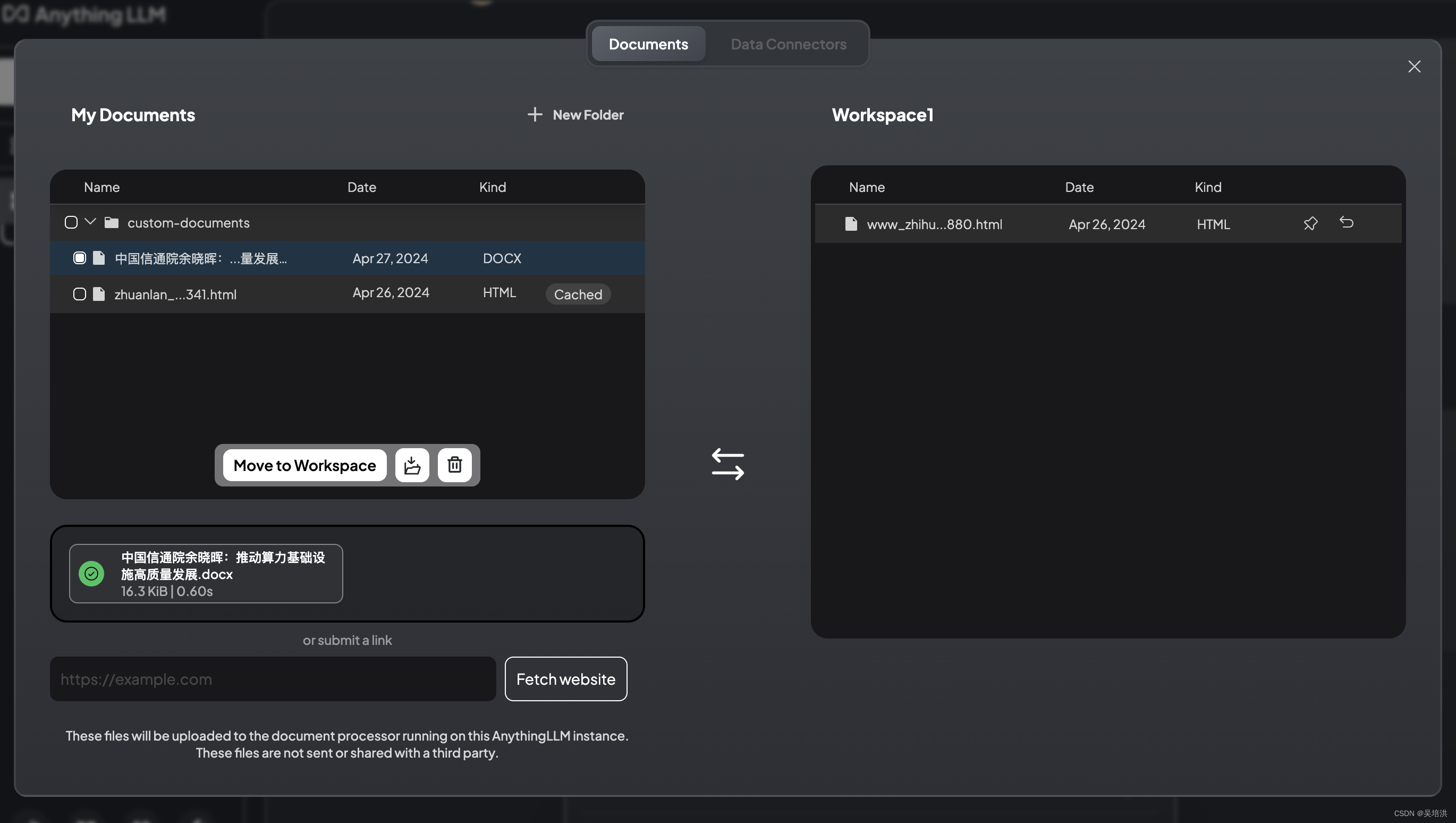
上次文件之后,选中后,点击Move to Workspace移动到右边的框中
执行右下角的Save and Embed,会将文件向量化后存储到向量数据库中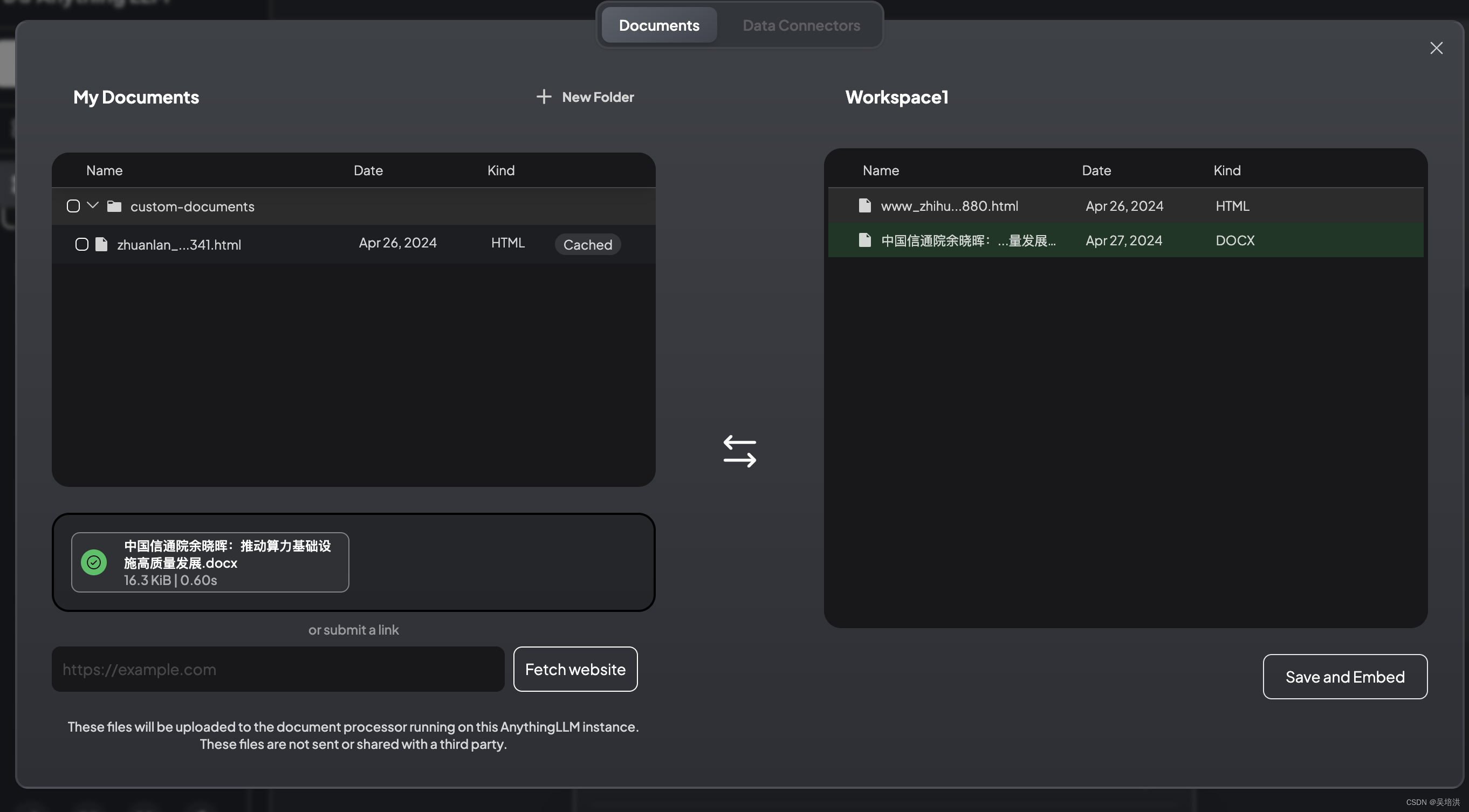
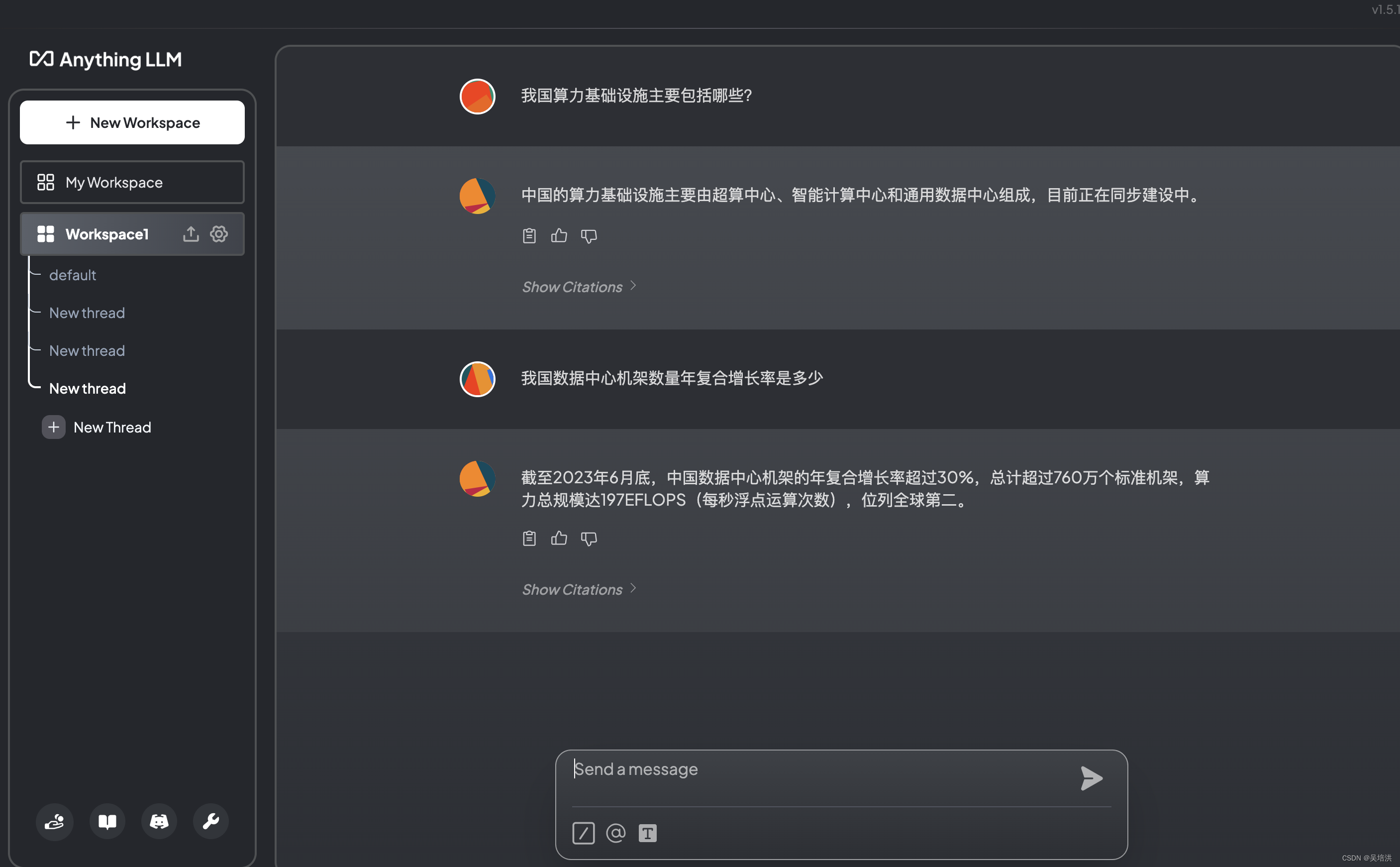
返回页面即可跟大模型对话,获取想要的答案















 4122
4122











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









