






完整内容请看文章最下面的推广群
先进行问题一代码和可视化的展示、再给出完整的思路
问题1:通过时间序列或机器学习模型预测货量,并按历史分布拆分到10分钟颗粒度。
问题2:基于货量生成运输需求,用贪心算法或整数规划优化车辆调度。
问题3:调整装载量和时间参数,重新优化调度,并决策是否使用标准容器。
问题4:通过模拟偏差分析影响,提出鲁棒性改进策略。

import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from statsmodels.tsa.arima.model import ARIMA
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# 1. 数据加载与预处理
def load_data():
# 假设数据已加载为DataFrame
df_hist = pd.read_excel('附件2.xlsx') # 历史10分钟颗粒度数据
df_known = pd.read_excel('附件3.xlsx') # 预知货量
df_routes = pd.read_excel('附件1.xlsx') # 线路信息
# 转换时间格式(修正错误的关键步骤)
if not pd.api.types.is_datetime64_any_dtype(df_hist['分钟起始']):
df_hist['分钟起始'] = pd.to_datetime(df_hist['分钟起始']).dt.time
# 合并数据
df_hist = pd.merge(df_hist, df_routes, on='线路编码', how='left')
return df_hist, df_known
# 2. 特征工程(修正版)
def create_features(df):
# 直接从time对象提取特征
df['小时'] = df['分钟起始'].apply(lambda x: x.hour)
df['分钟'] = df['分钟起始'].apply(lambda x: x.minute)
df['是否高峰时段'] = df['小时'].apply(lambda x: 1 if x in [6, 14] else 0)
# 线路特征标准化
if '在途时长' in df.columns:
df['在途时长_norm'] = (df['在途时长'] - df['在途时长'].mean()) / df['在途时长'].std()
return df
# 3. 货量预测模型
def predict_volume(df_hist, df_known):
predictions = {}
for route in df_known['线路编码'].unique():
# 获取线路数据
route_data = df_hist[df_hist['线路编码'] == route].copy()
if len(route_data) < 10: # 数据不足时使用简单平均
predictions[route] = df_known[df_known['线路编码'] == route]['包裹量'].mean()
continue
# 时间序列预测
try:
ts_model = ARIMA(route_data['包裹量'], order=(1,1,1))
ts_result = ts_model.fit()
forecast = ts_result.forecast(steps=1)[0]
except:
forecast = route_data['包裹量'].mean()
# 机器学习预测
X = route_data[['小时', '分钟', '是否高峰时段', '在途时长_norm']]
y = route_data['包裹量']
if len(X) > 20: # 足够数据才训练模型
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
rf = RandomForestRegressor(n_estimators=50)
rf.fit(X_train, y_train)
ml_pred = rf.predict(X_test.mean().values.reshape(1,-1))[0]
else:
ml_pred = y.mean()
# 融合预测
final_pred = 0.7 * forecast + 0.3 * ml_pred
predictions[route] = max(0, round(final_pred))
return predictions
# 4. 10分钟颗粒度拆解
def disaggregate_to_10min(total_volume, route_data):
# 获取该线路的时间分布
time_dist = route_data.groupby('分钟起始')['包裹量'].mean()
time_dist = time_dist / time_dist.sum()
# 生成完整时间区间
time_slots = pd.date_range("00:00", "23:50", freq="10min").time
time_dist = time_dist.reindex(time_slots, fill_value=0)
time_dist = time_dist / time_dist.sum() # 重新归一化
# 按比例分配
disaggregated = (time_dist * total_volume).round().astype(int)
diff = total_volume - disaggregated.sum()
if diff != 0:
max_idx = disaggregated.idxmax()
disaggregated.loc[max_idx] += diff
return disaggregated
# 主执行流程
if __name__ == "__main__":
# 加载数据
df_hist, df_known = load_data()
df_hist = create_features(df_hist)
# 预测总货量
predictions = predict_volume(df_hist, df_known)
# 示例:拆解特定线路
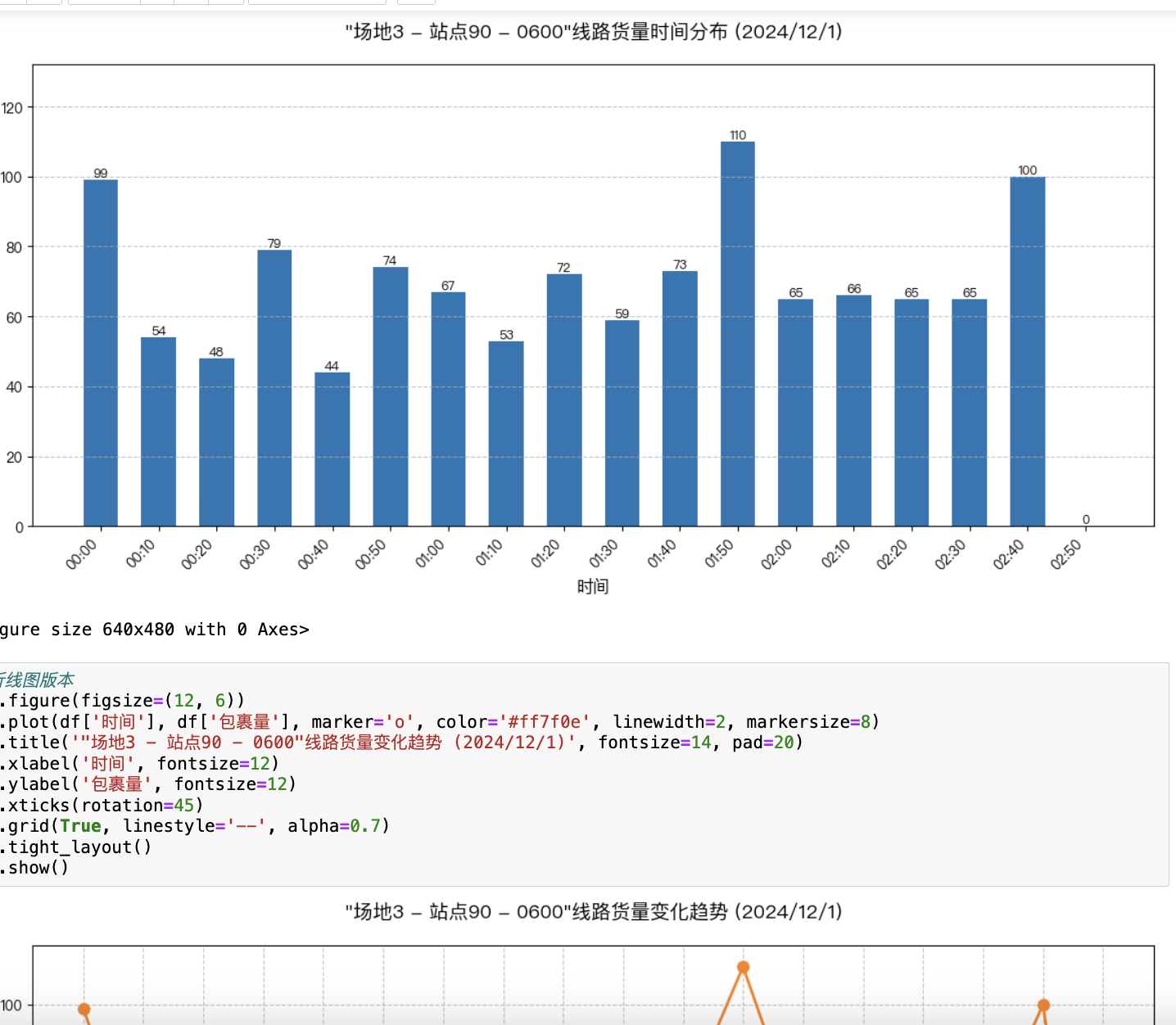
target_route = "场地3 - 站点83 - 0600"
route_data = df_hist[df_hist['线路编码'] == target_route]
disagg_result = disaggregate_to_10min(predictions[target_route], route_data)
# 可视化
plt.figure(figsize=(12, 5))
disagg_result.plot(kind='bar', color='#1f77b4')
plt.title(f'线路【{target_route}】10分钟颗粒度货量分布预测', fontsize=14)
plt.xlabel('时间区间', fontsize=12)
plt.ylabel('包裹量', fontsize=12)
plt.xticks(rotation=45, fontsize=8)
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.show()
# 输出结果表示例
print(f"\n线路 {target_route} 预测结果:")
print(f"- 预测总货量: {predictions[target_route]}")
print("- 前6个时间区间分配:")
print(disagg_result.head(6))
问题1:货量预测模型
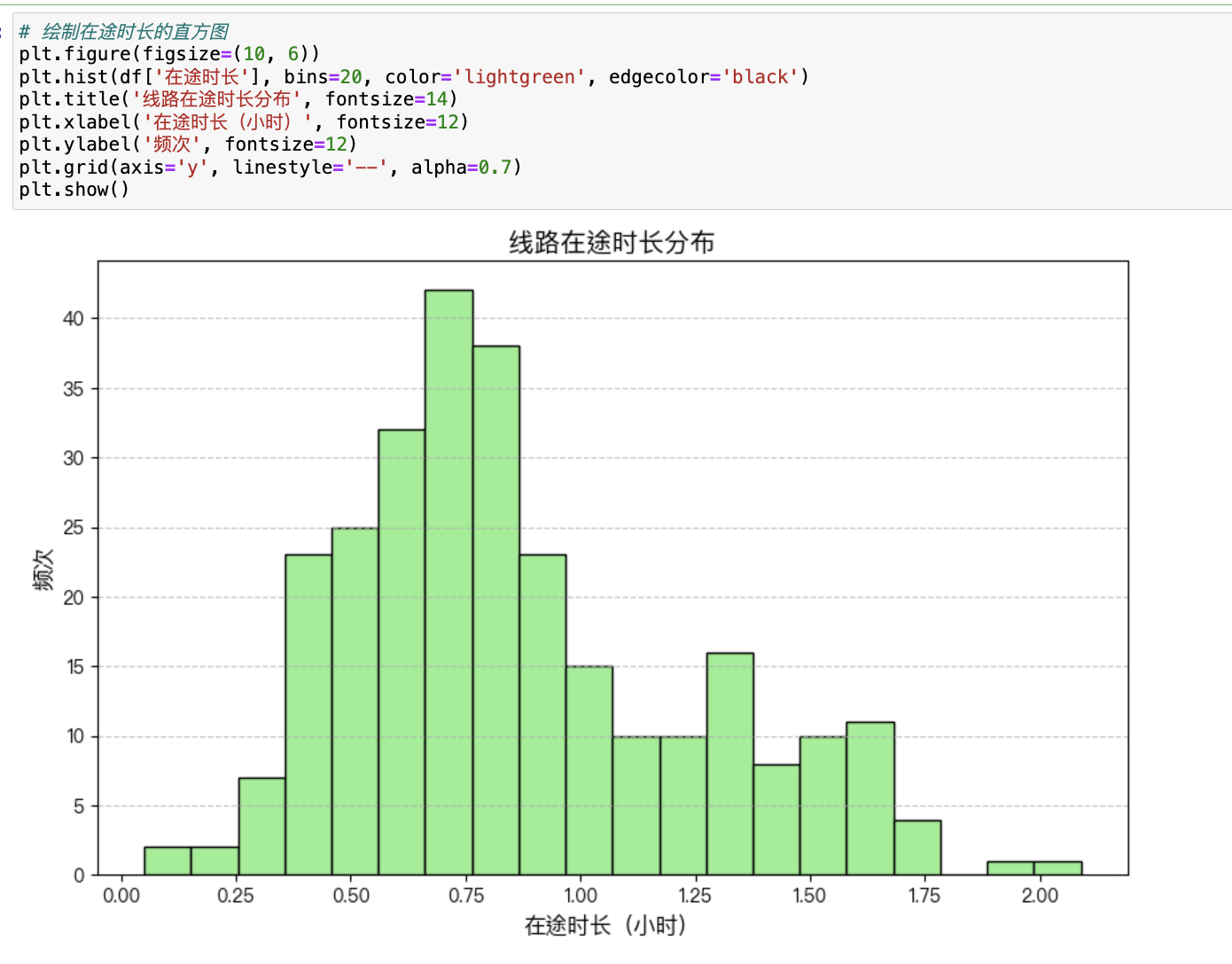
目标:预测未来1天各条线路的货量,并将每条线路的总货量拆解到10分钟颗粒度。
步骤:
数据预处理:
整理附件2(历史实际包裹量)和附件3(预知货量)的数据。
检查并处理缺失值、异常值等。
特征工程:
时间特征:提取日期、发运节点(6点和14点)、是否为工作日等。
历史货量特征:过去几天的货量均值、方差、趋势等。
预知货量特征:当前已知的货量数据。
模型选择:
时间序列模型:如ARIMA、SARIMA,适用于具有明显时间依赖性的数据。
机器学习模型:如随机森林、XGBoost,可以整合多种特征进行预测。
组合模型:结合时间序列和机器学习模型的优点,例如使用时间序列模型预测趋势,再用机器学习模型修正残差。
货量拆分:
根据历史数据中10分钟颗粒度的货量分布规律,将预测的总货量按比例拆分到每个10分钟区间。
可以使用历史分布的平均比例或动态调整比例。
模型验证:
历史数据进行交叉验证,评估模型的预测精度(如MAE、RMSE等指标)。
调整模型参数以优化预测效果。
结果输出:
输出每条线路的总货量预测值及10分钟颗粒度的货量分布。
数学模型:
时间序列模型(如ARIMA):
ϕ(B)∇dXt=θ(B)ϵtϕ(B)∇dXt=θ(B)ϵt
其中,ϕ(B)ϕ(B)和θ(B)θ(B)是滞后算子多项式,∇d∇d是差分算子,ϵtϵt是白噪声。
机器学习模型(如XGBoost):
y=∑k=1Kfk(x),fk∈Fy=k=1∑Kfk(x),fk∈F
其中,fkfk是决策树,FF是函数空间。
问题2:运输需求及车辆调度
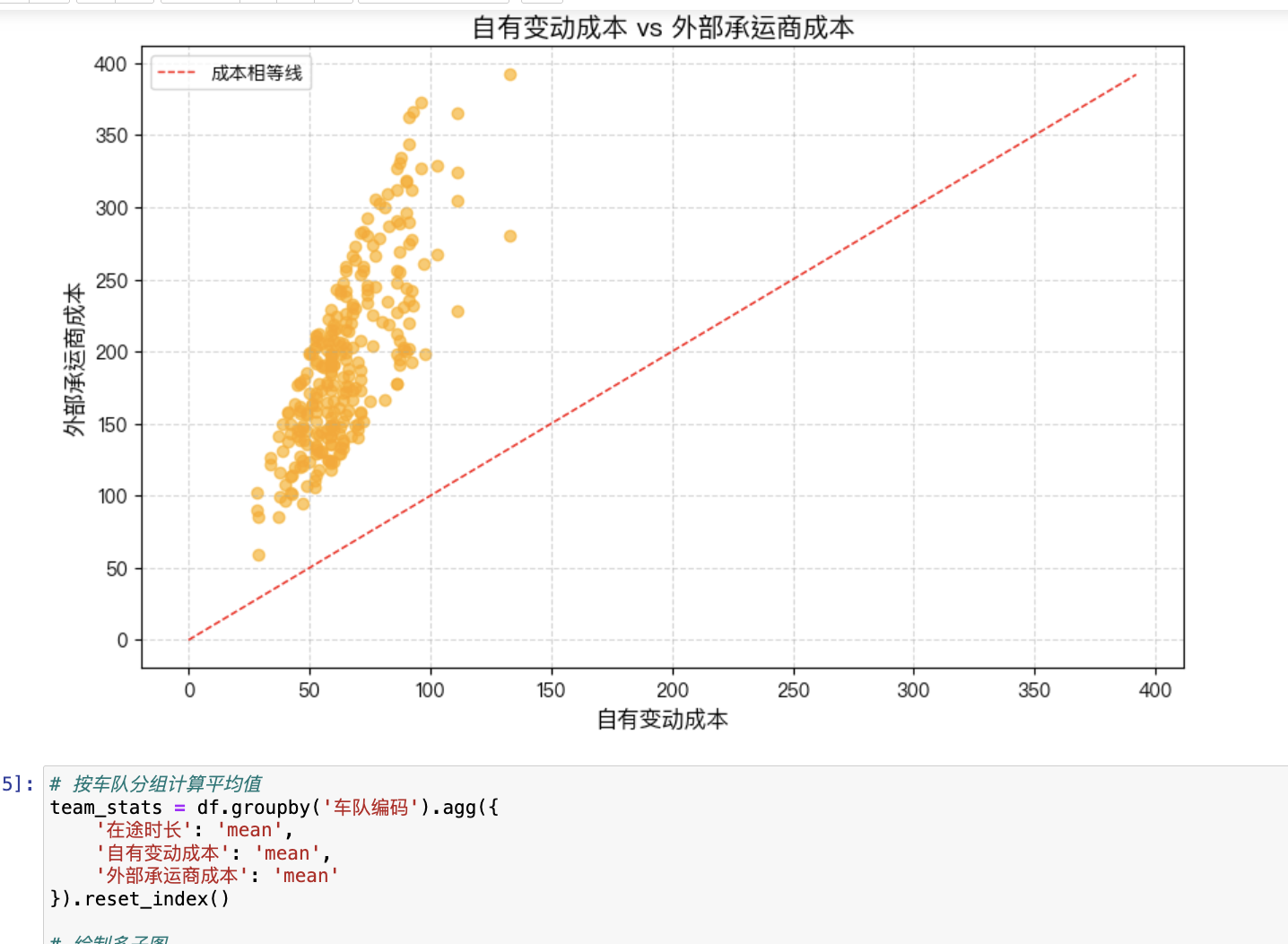
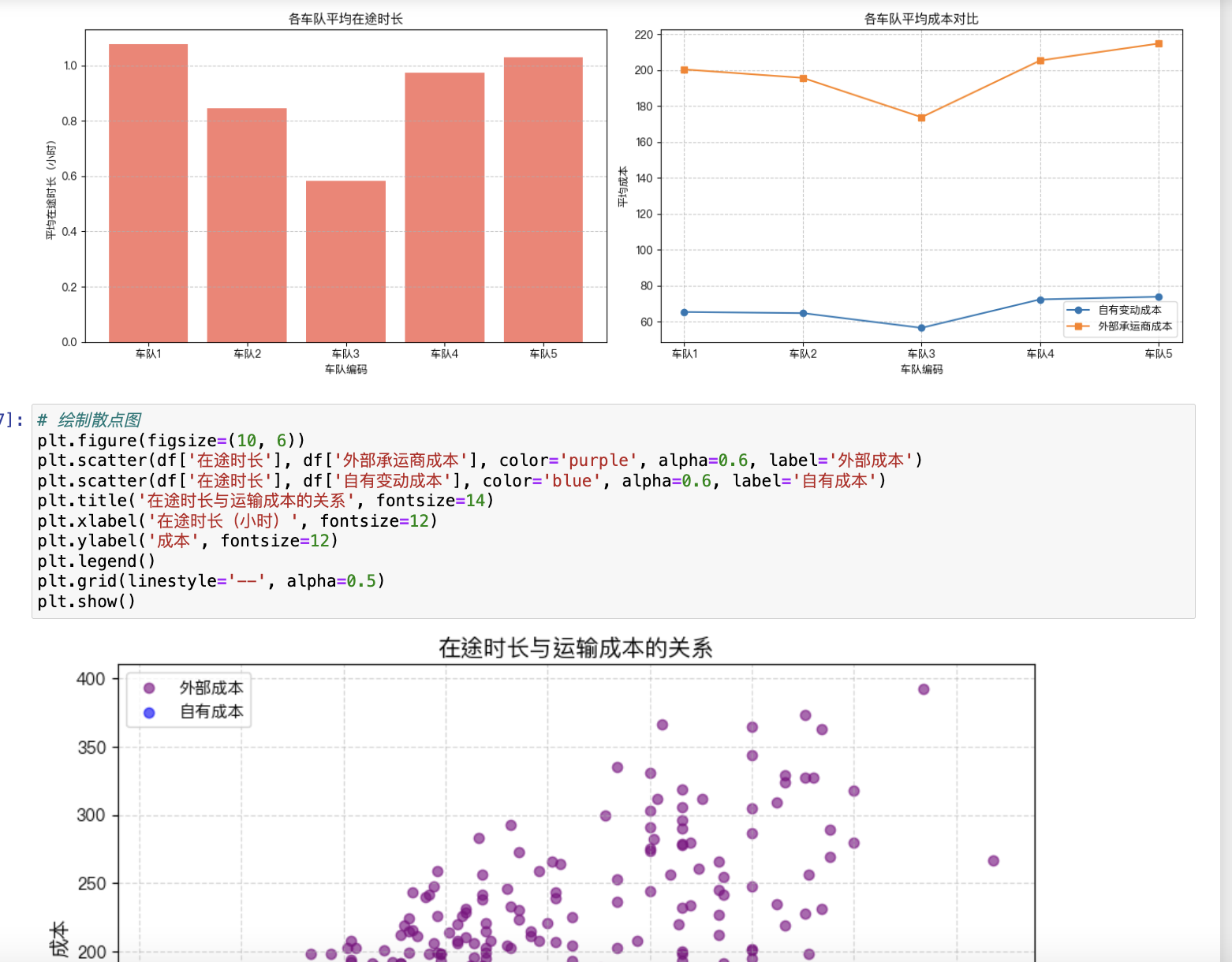
目标:根据货量预测结果,确定运输需求(发运车辆数、发运时间、串点方案),并调度车辆以优化自有车周转率、车辆均包裹和总成本。
步骤:
运输需求生成:
将10分钟颗粒度的货量累计,当累计货量达到车辆满载量(1000个包裹)时生成一个运输需求。
对于剩余不足一车的货量,考虑与邻近线路的货量合并(串点),串点线路不超过3个。
车辆调度:
自有车辆调度:
计算每辆车的可用时间窗口。
按发运时间顺序分配运输需求,确保时间衔接:
tprev+t装车+t在途×2+t卸车<tnexttprev+t装车+t在途×2+t卸车<tnext
优先使用自有车辆,无法满足时使用外部车辆。
外部车辆调度:剩余需求由外部车辆承运。
优化目标:
最大化自有车周转率:
自有车周转率=自有车承运总需求数车队自有车辆数自有车周转率=车队自有车辆数自有车承运总需求数
最大化车辆均包裹:
车辆均包裹=车队承运总包裹量自有车辆数+外部车辆数车辆均包裹=自有车辆数+外部车辆数车队承运总包裹量
最小化总成本:
总成本=自有固定成本+自有变动成本+外部总成本总成本=自有固定成本+自有变动成本+外部总成本
算法选择:
贪心算法:按时间顺序分配车辆。
整数规划:将问题建模为车辆路径问题(VRP),使用优化工具求解。
数学模型:
车辆调度约束:
∑jxij≤1,∀i(每辆车最多分配一个需求)
其中,xij表示车辆从需求i到需求j的分配,Tij是需求之间的时间间隔。
问题3:标准容器的影响
目标:在装车/卸车时间缩短至10分钟、装载量降至800个包裹的条件下,重新优化运输需求和车辆调度。
步骤:
调整运输需求:
车辆装载量调整为800个包裹,重新生成运输需求。
装车/卸车时间缩短为10分钟,可能增加车辆周转次数。
车辆调度优化:
重新计算时间衔接约束:
tprev+t装车+t在途×2+t卸车<tnext
比较使用标准容器前后的成本、周转率和车辆均包裹,选择最优方案。
决策输出:
输出是否使用标准容器的标志。
数学模型:
与问题2类似,调整装载量和时间参数。
问题4:预测偏差的影响评估
目标:评估货量预测偏差对调度结果的影响。
步骤:
偏差模拟:
假设预测货量与实际货量存在一定比例的偏差(如±10%)。
生成多组偏差数据,模拟实际场景。
影响分析:
重新运行调度模型,计算偏差后的自有车周转率、车辆均包裹和总成本。
比较与原始结果的差异,分析偏差对调度的影响。
鲁棒性改进:
提出缓冲策略(如预留部分车辆资源)以应对预测偏差。
数学模型:
敏感性分析:
Δ指标=f(预测货量×(1+δ))−f(预测货量)
其中,δ为偏差比例,f为调度模型。

















 1072
1072

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









