







现在深度学习的模型结构越来越大,参数动不动都是上亿甚至上千亿,这也对训练模型的资源量有很高的要求,显然单个机器上要训练这么大的网络是不现实的,因此学术界和工业界自然开始研究用分布式训练。也就是将一个机器学习模型任务拆分成多个子任务,并将子任务分发给多个计算节点,解决资源瓶颈。
1. 分布式训练概述/动机
分布式训练的动机很简答:单节点算力和内存不足,因此不得不做分布式训练。
训练机器学习模型需要大量内存。假设一个大型神经网络模型具有 1000 亿的参数(LLM 时代有不少比这个参数量更大的模型),每个参数都由一个 32 位浮点数(4 个字节)表达,存储模型参数就需要 400GB 的内存。在实际中,我们需要更多内存来存储激活值和梯度。假设激活值和梯度也用 32 位浮点数表达,那么其各自至少需要 400GB 内存,总的内存需求就会超过 1200GB(即 1.2TB)。而如今的硬件加速卡(如 NVIDIA A100)仅能提供最高80GB的内存。单卡内存空间的增长受到硬件规格、散热和成本等诸多因素的影响,难以进一步快速增长。因此,我们需要分布式训练系统来同时使用数百个训练加速卡,从而为千亿级别的模型提供所需的TB级别的内存。
为了方便获得大量用于分布式训练的服务器,我们往往依靠云计算数据中心。一个数据中心管理着数百个集群,每个集群可能有几百到数千个服务器。通过申请其中的数十台服务器,这些服务器进一步通过分布式训练系统进行管理,并行完成机器学习模型的训练任务。
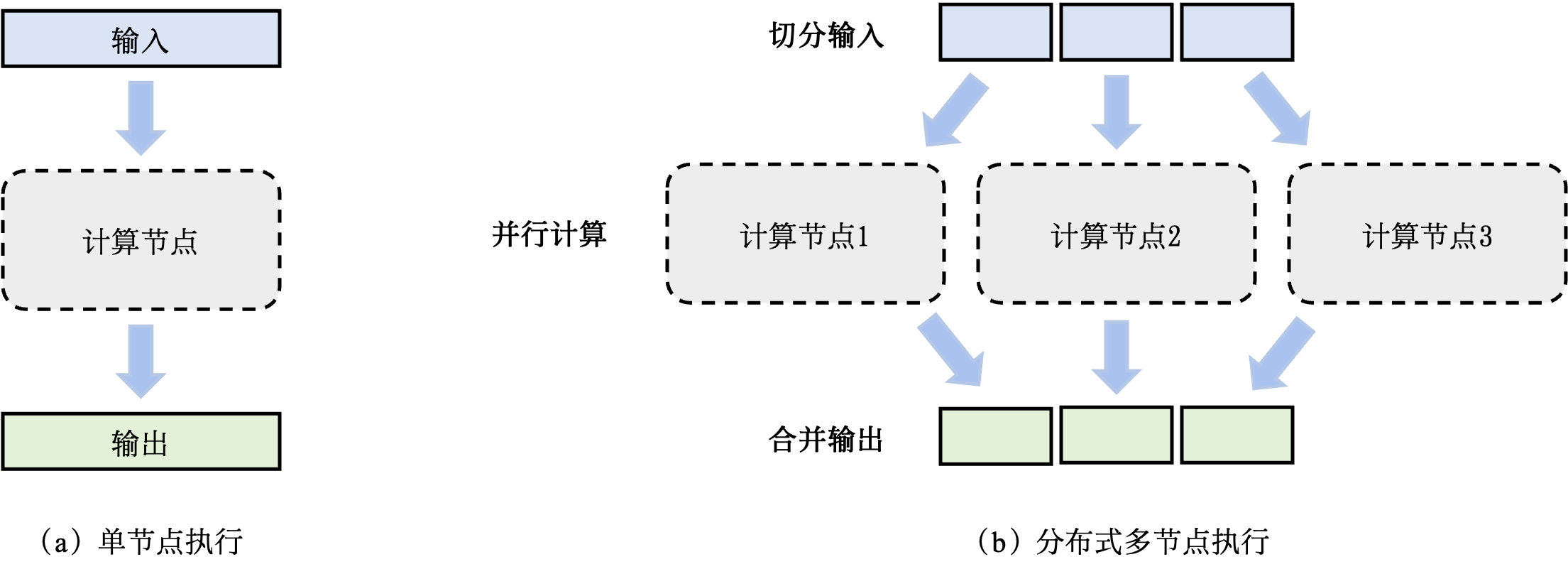
相比单节点执行,可以看到分布式训练主要要对输入做一些切分(可能是切分数据集、切分模型参数或者混合的方式)并送到不同的节点进行训练,由于数据或参数的独立性,各节点之间的计算是相对独立的,因此可以并行计算,从而达到加速模型训练的目的。
为了确保分布式训练系统的高效运行,需要首先估计系统计算任务的计算和内存用量。假如某个任务成为了瓶颈,系统会切分输入数据,从而将一个任务拆分成多个子任务。子任务进一步分发给多个计算节点并行完成。
一个模型训练任务(Model Training Job)往往会有一组数据(如训练样本)或者任务(如算子)作为输入,利用一个计算节点(如GPU)生成一组输出(如梯度)。
分布式执行一般具有三个步骤:
- 第一步将输入进行切分;
- 第二步将每个输入部分会分发给不同的计算节点,实现并行计算;
- 第三步将每个计算节点的输出进行合并,最终得到和单节点等价的计算结果。
这种首先切分,然后并行,最后合并的模式,本质上实现了分而治之(Divide-and-Conquer)的方法(实际上在计算机的系统领域这是一个非常主流的解决思路):由于每个计算节点只需要负责更小的子任务,因此其可以更快速地完成计算,最终实现对整个计算过程的加速。
2. 分布式训练主流实现方法
分布式训练系统的设计目标是:将单节点训练系统转换成 等价的 并行训练系统(divide and conquer),从而在不影响模型精度的条件下完成训练过程的加速。
下图是一个单节点训练系统的流程:为了更新参数(模型训练一个 iter 需要更新模型参数),计算图的执行分为前向计算和反向计算两个阶段。前向计算的第一步会将数据读入第一个算子,该算子会根据当前的参数,计算出计算给下一个算子的数据。算子依次重复这个前向计算的过程(执行顺序:算子1,算子2,算子3),直到最后一个算子结束。最后的算子随之马上开始反向计算。反向计算中,每个算子依次计算出梯度(执行顺序:梯度3,梯度2,梯度1),并利用梯度更新本地的参数。反向计算最终在第一个算子结束。反向计算的结束也标志本次数据小批次的结束,系统随之读取下一个数据小批次,继续更新模型。
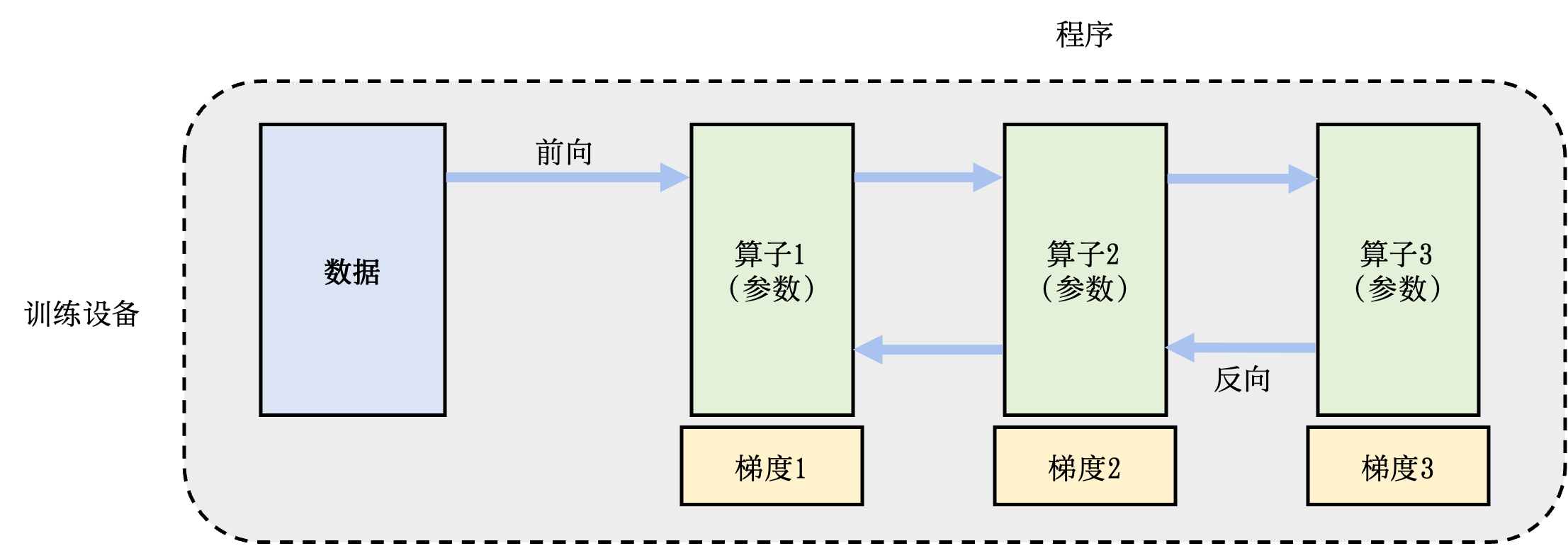
再进一步对这个过程拆分:模型训练过程中有频繁的读数据和计算这两个操作,因此我们可以从这两个方面入手,对数据和计算分别拆分,从而完成并行加速。
下表是分布式训练方法的分类:
| 分类 | 单数据 | 多数据 |
|---|---|---|
| 单程序 | 单程序单数据:单点执行 | 单程序多数据:数据并行 |
| 多程序 | 多程序单数据:模型并行 | 多程序多数据:混合并行 |
单节点训练系统可以被归类于单程序单数据模式。而假如用户希望使用更多的设备实现并行计算,首先可以选择对数据进行分区,并将同一个程序复制到多个设备上并行执行。这种方式是单程序多数据模式,常被称为数据并行 (Data Parallelism)。另一种并行方式是对程序进行分区(模型中的算子会被分发给多个设备分别完成)。这种模式是多程序单数据模式,常被称为模型并行 (Model Parallelism),模型并行又细分为张量并行和流水线并行。当训练超大型智能模型时,开发人员往往要同时对数据和程序进行切分,从而实现最高程度的并行。这种模式是多程序多数据模式,常被称为混合并行 (Hybrid Parallelism)。

2. 数据并行
数据并行是将训练数据划分为多个子集,每个子集分配给一个计算设备(如GPU),每个设备独立地使用其数据子集进行前向传播和反向传播计算。在每个训练步骤结束时,所有设备将计算得到的梯度汇总并平均,然后更新模型参数。
2.1. Data parallelism (DP)
Data Parallelism (DP) 是分布式训练中最常用的并行策略之一,其核心思想是将输入数据分片后分发到多个计算节点(如 GPU/TPU),每个节点持有完整的模型副本,独立计算梯度,最终同步更新模型参数。
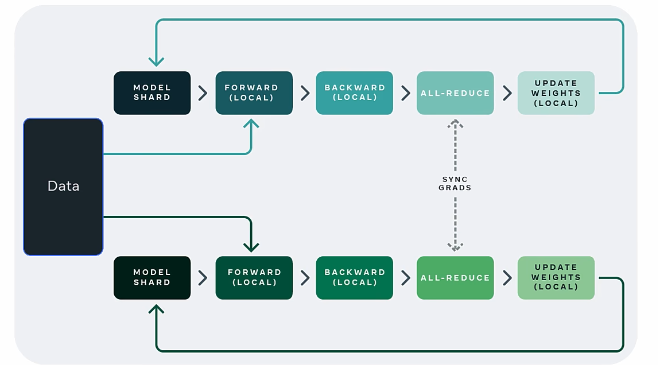
2.2. Distribution Data Parallel (DDP)
PyTorch 的 DistributedDataParallel (DDP) 是实现数据并行的核心库,专为多设备(如多 GPU/TPU)分布式训练设计。它通过高效的通信和内存管理,解决了传统数据并行(如 DataParallel)的性能瓶颈。
2.3. Fully Sharded Data Parallel (FSDP)
Fully Sharded Data Parallel (FSDP) 是一种高级分布式训练技术,旨在解决超大规模模型在多 GPU / 节点上的内存限制问题,其核心思想是将模型参数、梯度和优化器状态分片 (Shard) 到不同设备,显著降低单卡内存占用,同时通过高效通信实现并行训练。
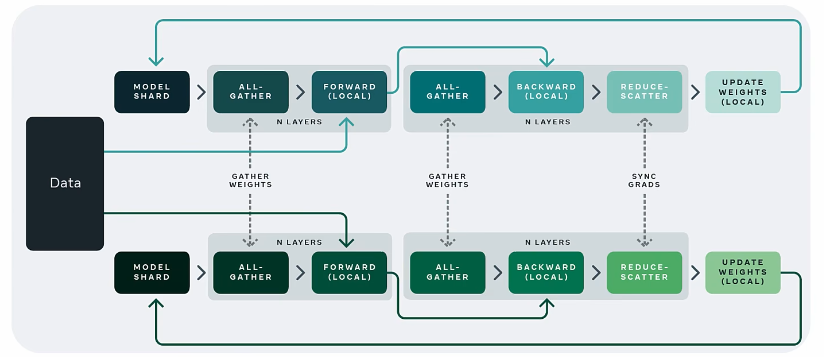
3. 模型并行
模型并行往往用于解决单节点内存不足的问题。一个常见的内存不足场景是模型中含有大型算子,例如深度神经网络中需要计算大量分类的全连接层。完成这种大型算子计算所需的内存可能超过单设备的内存容量。那么需要对这个大型算子进行切分。假设这个算子具有 P 个参数,而系统拥有 N 个设备,那么可以将 P 个参数平均分配给 N 个设备,从而让每个设备负责更少的计算量,能够在内存容量的限制下完成前向计算和反向计算。
3.1. 张量并行
张量并行是将模型中的张量(Tensor)拆分为多个子张量,分配到不同的计算设备上。每个设备只负责计算子张量的部分,然后通过通信将结果汇总。这种策略通常用于处理超大模型(如GPT-3),可以将模型的权重和计算分布在多个设备上。
3.2. 流水线并行
流水并行是将模型按层或模块划分为多个阶段(Stage),每个阶段分配到不同的计算设备上。输入数据被划分为多个微批次(micro-batch),通过流水线的方式在不同阶段之间传递,实现多批次数据的同时处理。
4. 混合并行
在训练大型人工智能模型中,往往会同时面对算力不足和内存不足的问题。因此,需要混合使用数据并行和模型并行,这种方法被称为混合并行。
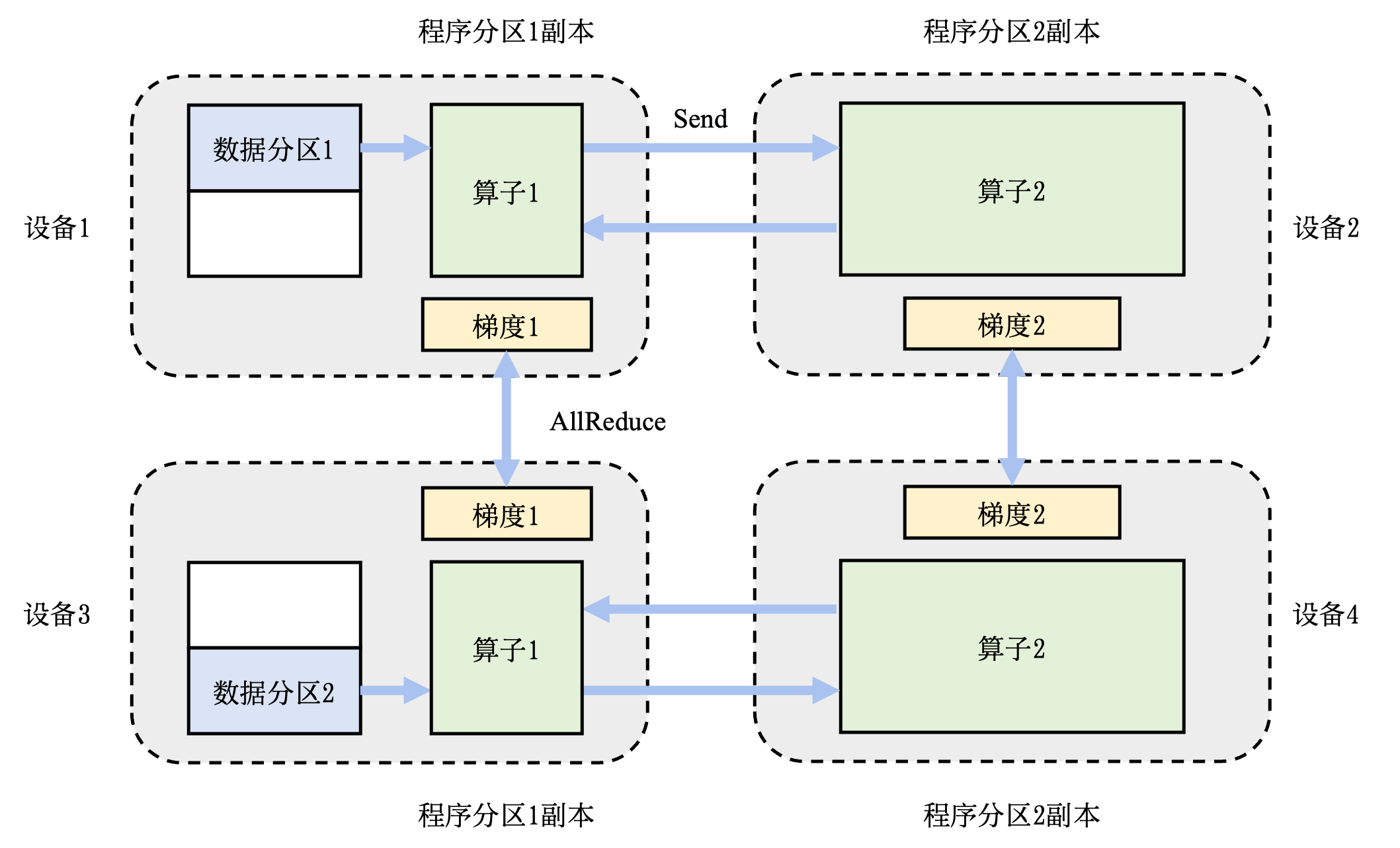
下图就是一个混合并行的例子,数据集被切分到不同的机器上执行,同样的数据集又会被切分到不同的设备上执行不同的计算。这里提供了一个由 4 个设备实现的混合并行的例子。在这个例子中,首先实现算子间并行解决训练程序内存开销过大的问题:该训练程序的算子 1 和算子 2 被分摊到了设备 1 和设备 2 上。进一步,通过数据并行添加设备 3 和设备 4,提升系统算力。为了达到这一点,对训练数据进行分区(数据分区 1 和数据分区 2),并将模型(算子 1 和算子 2,这里不一定是单个算子,可以是对计算图做拆分)分别复制到设备 3 和设备 4。在前向计算的过程中,设备 1 和设备 3 上的算子 1 副本同时开始,计算结果分别发送给设备 2 和设备 4 完成算子 2 副本的计算。在反向计算中,设备 2 和设备 4 同时开始计算梯度,本地梯度通过 AllReduce 操作进行平均。反向计算传递到设备 1 和设备 3 上的算子 1 副本结束。
参考文献
深度学习框架 —— 分布式训练 - machine_gun_lin - 博客园
分布式并行策略基础介绍!【分布式并行】系列第01篇_哔哩哔哩_bilibili
PyTorch数据并行怎么实现?DP、DDP、FSDP数据并行原理?【分布式并行】系列第02篇_哔哩哔哩_bilibili

















 2585
2585

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









