









香港中文、腾讯AI LAB和北大团队联合研发的DynamiCrafter模型,能够处理几乎所有类型的图像,并根据文本提示生成逼真的动态内容,用户不再受限于特定的场景或动作,只需提供适当的文本提示,DynamiCrafter就能够创造出各种动画效果,从而大大拓宽了AI视频生成的应用范围。



相关链接
论文链接: https://arxiv.org/pdf/2310.12190.pdf
项目地址: https://doubiiu.github.io/projects/DynamiCrafter
试用链接:https://huggingface.co/spaces/Doubiiu/DynamiCrafter
论文阅读

摘要
动画静止图像提供了一种引人入胜的视觉体验。传统的图像动画技术主要关注随机动态的自然场景(如云和流体)或特定领域的运动(如人的头发或身体运动),从而限制了它们对更一般的视觉内容的适用性。为了克服这一限制,我们探索了开放域图像动态内容的合成,将它们转换为动画视频。关键思想是通过将图像纳入生成过程作为指导,利用文本到视频扩散模型的运动先验。给定一幅图像,我们首先使用查询转换器将其投影到文本对齐的丰富上下文表示空间,这有助于视频模型以兼容的方式消化图像内容。然而,一些视觉细节仍然难以在最终的视频中保留。为了补充更精确的图像信息,我们进一步将完整图像与初始噪声连接起来,将其提供给扩散模型。实验结果表明,所提方法可以产生视觉上令人信服的、更逻辑和自然的运动,同时可以生成更具可读性的动画。以及对输入图像的更高一致性。比较评估表明,我们的方法比现有的竞争对手具有明显的优势。
方法
给定一幅静止图像,我们的目标是将其动画化以生成一个短视频剪辑,该剪辑继承了图像的所有视觉内容,并展示了隐含的和自然的动态。注意,静止图像可以出现在结果帧序列的任意位置。从技术上讲,这种挑战可以被表述为一种特殊的图像条件化视频生成,对视觉一致性有很高的要求。我们通过利用预训练视频扩散模型的生成先验来解决这个合成任务。
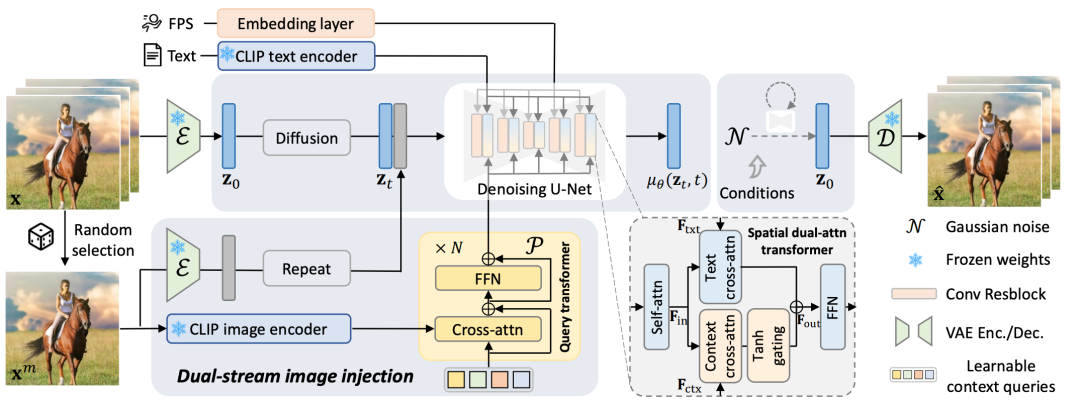
DynaCrafter流程:在训练过程中,我们通过提出的双流图像注入机制随机选择一帧视频作为去噪过程的图像条件,以继承视觉细节并以上下文感知的方式消化输入图像。在推理过程中,我们的模型可以从输入静态图像的噪声条件下生成动画剪辑。
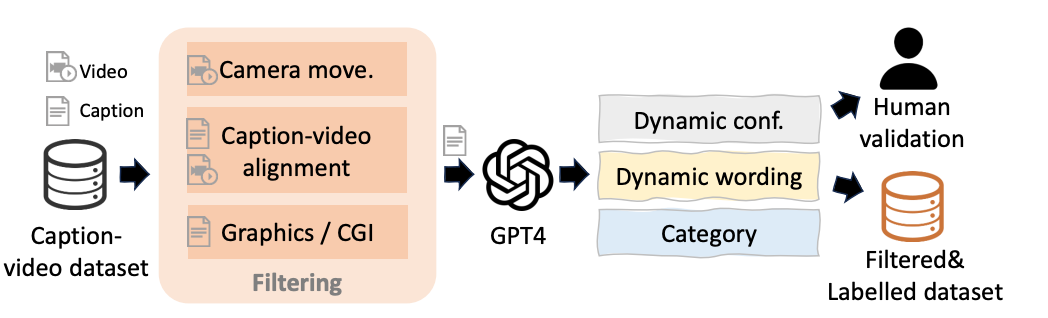
数据集过滤和注释过程的说明:为了实现解耦训练,我们通过过滤和重新标注WebVid10M数据集来构建数据集,所构造的数据集包含带有纯动态措辞的标题,例如做俯卧撑的男人以及分类例如人。
实验



结论
在本研究中介绍了一种有效的框架DynaCrafter,通过利用预训练的视频扩散先验知识,利用所提出的双流图像注入机制和专用训练范式来制作开放域图像的动画。实验结果强调了与现有方法相比的有效性和优越性。此外,我们利用构建的数据集探讨了基于文本的图像动画动态控制。最后,我们证明了我们的框架在各种应用和场景中的通用性。
感谢你看到这里,也欢迎点击关注下方公众号,一个有趣有AI的AIGC公众号:关注AI、深度学习、计算机视觉、AIGC、Stable Diffusion、Sora等相关技术,欢迎一起交流学习💗~



















 1864
1864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











