






今天给大家分享8篇Transformer最新顶会论文,值得大家学习和借鉴~
【1】 A Comparative Study on Dynamic Graph Embedding based on Mamba and Transformers
标题: 基于Mamba和Transformers的动态图嵌入比较研究
链接:https://arxiv.org/abs/2412.11293
作者: Ashish Parmanand Pandey, Alan John Varghese, Sarang Patil, Mengjia Xu
摘要:Dynamic graph embedding has emerged as an important technique for modeling complex time-evolving networks across diverse domains. While transformer-based models have shown promise in capturing long-range dependencies in temporal graph data, they face scalability challenges due to quadratic computational complexity. This study presents a comparative analysis of dynamic graph embedding approaches using transformers and the recently proposed Mamba architecture, a state-space model with linear complexity. We introduce three novel models: TransformerG2G augment with graph convolutional networks, DG-Mamba, and GDG-Mamba with graph isomorphism network edge convolutions. Our experiments on multiple benchmark datasets demonstrate that Mamba-based models achieve comparable or superior performance to transformer-based approaches in link prediction tasks while offering significant computational efficiency gains on longer sequences. Notably, DG-Mamba variants consistently outperform transformer-based models on datasets with high temporal variability, such as UCI, Bitcoin, and Reality Mining, while maintaining competitive performance on more stable graphs like SBM. We provide insights into the learned temporal dependencies through analysis of attention weights and state matrices, revealing the models’ ability to capture complex temporal patterns. By effectively combining state-space models with graph neural networks, our work addresses key limitations of previous approaches and contributes to the growing body of research on efficient temporal graph representation learning. These findings offer promising directions for scaling dynamic graph embedding to larger, more complex real-world networks, potentially enabling new applications in areas such as social network analysis, financial modeling, and biological system dynamics.
动态图嵌入已成为跨不同领域建模复杂时间演化网络的重要技术。虽然基于变压器的模型在捕获时间图数据中的长程依赖关系方面显示出了希望,但由于二次计算复杂性,它们面临着可扩展性挑战。本研究对使用变压器的动态图嵌入方法和最近提出的Mamba架构(一种具有线性复杂性的状态空间模型)进行了比较分析。我们介绍了三种新模型:TransformerG2G用图卷积网络增强、DG Mamba和GDG Mamba用图同构网络边卷积。我们在多个基准数据集上的实验表明,基于Mamba的模型在链路预测任务中实现了与基于变换器的方法相当或更优的性能,同时在较长的序列上提供了显著的计算效率提升。值得注意的是,DG Mamba变体在具有高时间变异性的数据集(如UCI、比特币和现实挖掘)上始终优于基于变换器的模型,同时在SBM等更稳定的图上保持竞争性能。我们通过分析注意力权重和状态矩阵来提供对学习到的时间依赖性的见解,揭示了模型捕捉复杂时间模式的能力。通过有效地将状态空间模型与图神经网络相结合,我们的工作解决了先前方法的关键局限性,并为越来越多的关于高效时间图表示学习的研究做出了贡献。这些发现为将动态图嵌入扩展到更大、更复杂的现实世界网络提供了有前景的方向,有可能在社交网络分析、金融建模和生物系统动力学等领域实现新的应用。
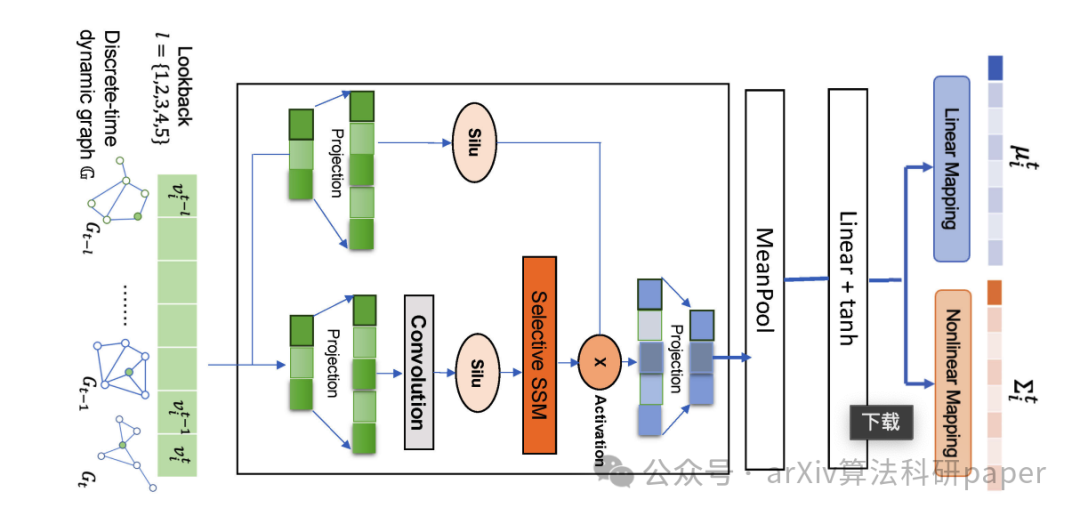
【2】 FairGP: A Scalable and Fair Graph Transformer Using Graph Partitioning
标题: FairGP:使用图形划分的可扩展且公平的图形Transformer
链接:https://arxiv.org/abs/2412.10669
作者: Renqiang Luo, Huafei Huang, Ivan Lee, Chengpei Xu, Jianzhong Qi, Feng Xia
摘要:Recent studies have highlighted significant fairness issues in Graph Transformer (GT) models, particularly against subgroups defined by sensitive features. Additionally, GTs are computationally intensive and memory-demanding, limiting their application to large-scale graphs. Our experiments demonstrate that graph partitioning can enhance the fairness of GT models while reducing computational complexity. To understand this improvement, we conducted a theoretical investigation into the root causes of fairness issues in GT models. We found that the sensitive features of higher-order nodes disproportionately influence lower-order nodes, resulting in sensitive feature bias. We propose Fairness-aware scalable GT based on Graph Partitioning (FairGP), which partitions the graph to minimize the negative impact of higher-order nodes. By optimizing attention mechanisms, FairGP mitigates the bias introduced by global attention, thereby enhancing fairness. Extensive empirical evaluations on six real-world datasets validate the superior performance of FairGP in achieving fairness compared to state-of-the-art methods. The codes are available at https://github.com/LuoRenqiang/FairGP
最近的研究突出了图变换器(GT)模型中的公平性问题,特别是针对敏感特征定义的子群。此外,GT计算量大且内存要求高,限制了其在大规模图形中的应用。实验表明,图划分可以在降低计算复杂度的同时提高GT模型的公平性。为了理解这一改进,我们对GT模型中公平问题的根源进行了理论研究。我们发现,高阶节点的敏感特征对低阶节点的影响不成比例,导致敏感特征偏差。提出了一种基于图划分的公平性感知的可扩展GT(FairGP),对图进行划分以最小化高阶节点的负面影响。通过优化注意机制,FairGP减轻了全局注意带来的偏见,从而提高了公平性。通过对六个真实数据集的大量实证评估,验证了FairGP在实现公平性方面优于现有方法。
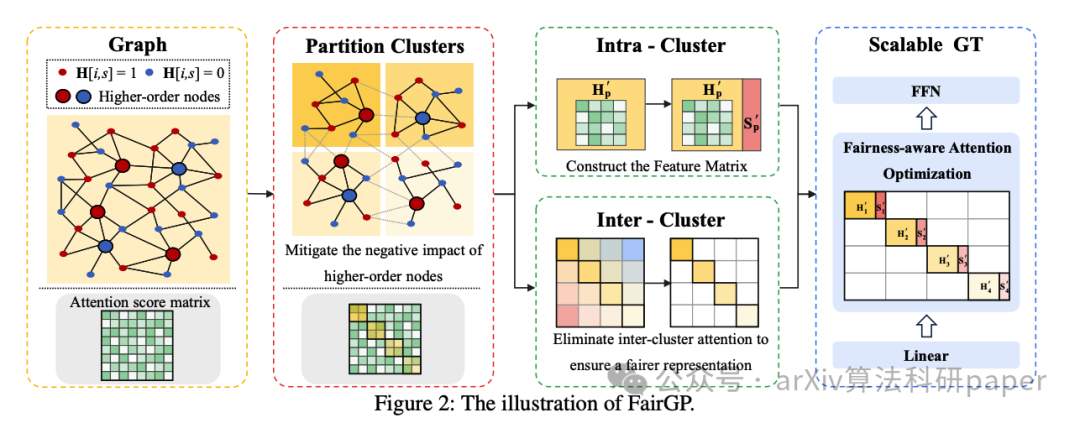
【3】 Transformers Use Causal World Models in Maze-Solving Tasks
标题: Transformer在解谜任务中使用因果世界模型
链接:https://arxiv.org/abs/2412.11867
作者: Alex F. Spies, William Edwards, Michael I. Ivanitskiy, Adrians Skapars, Tilman Räuker, Katsumi Inoue, Alessandra Russo, Murray Shanahan
摘要:Recent studies in interpretability have explored the inner workings of transformer models trained on tasks across various domains, often discovering that these networks naturally develop surprisingly structured representations. When such representations comprehensively reflect the task domain’s structure, they are commonly referred to as ``World Models’’ (WMs). In this work, we discover such WMs in transformers trained on maze tasks. In particular, by employing Sparse Autoencoders (SAEs) and analysing attention patterns, we examine the construction of WMs and demonstrate consistency between the circuit analysis and the SAE feature-based analysis. We intervene upon the isolated features to confirm their causal role and, in doing so, find asymmetries between certain types of interventions. Surprisingly, we find that models are able to reason with respect to a greater number of active features than they see during training, even if attempting to specify these in the input token sequence would lead the model to fail. Futhermore, we observe that varying positional encodings can alter how WMs are encoded in a model’s residual stream. By analyzing the causal role of these WMs in a toy domain we hope to make progress toward an understanding of emergent structure in the representations acquired by Transformers, leading to the development of more interpretable and controllable AI systems.
最近关于可解释性的研究探索了变压器模型在不同领域的任务训练的内部工作,经常发现这些网络自然地发展出令人惊讶的结构化表示。当这些表示全面反映任务域的结构时,它们通常被称为“世界模型”(WMs)。在这项工作中,我们发现这样的WMs变压器培训迷宫任务。特别地,通过使用稀疏自动编码器(SAE)和分析注意模式,我们检验了WMs的构造,并证明了电路分析和SAE基于特征的分析之间的一致性。我们对孤立的特征进行干预,以确认其因果作用,并在此过程中发现某些类型干预之间的不对称性。令人惊讶的是,我们发现模型能够对比训练期间看到的更多的活动特征进行推理,即使尝试在输入标记序列中指定这些特征会导致模型失败。此外,我们观察到不同的位置编码可以改变WMs在模型的剩余流中的编码方式。通过分析这些WMs在玩具领域中的因果关系,我们希望在理解变形金刚获得的表征中的涌现结构方面取得进展,从而开发出更具可解释性和可控性的AI系统。

【4】 Transformer-Based Bearing Fault Detection using Temporal Decomposition Attention Mechanism
标题: 使用时间分解注意力机制的基于Transformer的轴承故障检测
链接:https://arxiv.org/abs/2412.11245
作者:Marzieh Mirzaeibonehkhater, Mohammad Ali Labbaf-Khaniki, Mohammad Manthouri
摘要:Bearing fault detection is a critical task in predictive maintenance, where accurate and timely fault identification can prevent costly downtime and equipment damage. Traditional attention mechanisms in Transformer neural networks often struggle to capture the complex temporal patterns in bearing vibration data, leading to suboptimal performance. To address this limitation, we propose a novel attention mechanism, Temporal Decomposition Attention (TDA), which combines temporal bias encoding with seasonal-trend decomposition to capture both long-term dependencies and periodic fluctuations in time series data. Additionally, we incorporate the Hull Exponential Moving Average (HEMA) for feature extraction, enabling the model to effectively capture meaningful characteristics from the data while reducing noise. Our approach integrates TDA into the Transformer architecture, allowing the model to focus separately on the trend and seasonal components of the data. Experimental results on the Case Western Reserve University (CWRU) bearing fault detection dataset demonstrate that our approach outperforms traditional attention mechanisms and achieves state-of-the-art performance in terms of accuracy and interpretability. The HEMA-Transformer-TDA model achieves an accuracy of 98.1%, with exceptional precision, recall, and F1-scores, demonstrating its effectiveness in bearing fault detection and its potential for application in other time series tasks with seasonal patterns or trends.
轴承故障检测是预测性维修中的一项关键任务,准确、及时的故障识别可以防止代价高昂的停机和设备损坏。变压器神经网络中的传统注意机制往往难以捕获轴承振动数据中复杂的时间模式,导致性能不理想。针对这一局限性,我们提出了一种新的注意机制&时间分解注意(TDA),它将时间偏差编码与季节趋势分解相结合来捕获时间序列数据的长期依赖性和周期性波动。此外,我们还结合了赫尔指数移动平均(HEMA)进行特征提取,使模型能够有效地从数据中捕获有意义的特征,同时降低噪声。我们的方法将TDA集成到Transformer架构中,允许模型分别关注数据的趋势和季节性成分。在Case Western Reserve University(CWRU)轴承故障检测数据集上的实验结果表明,该方法优于传统的注意机制,在准确性和可解释性方面达到了最新水平。HEMA-Transformer TDA模型的准确率达到98.1%,具有极高的精度、召回率和F1分数,证明了其在轴承故障检测中的有效性,以及在其他具有季节性模式或趋势的时间序列任务中的应用潜力。
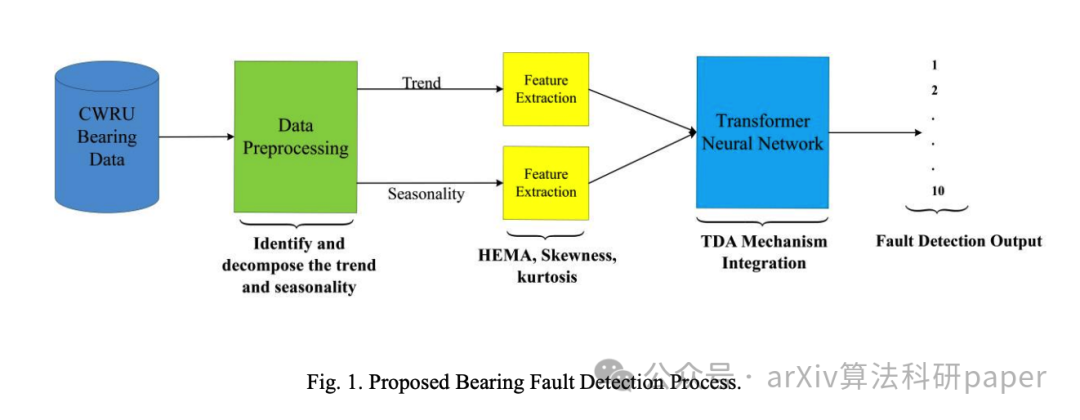
【5】 A Progressive Transformer for Unifying Binary Code Embedding and Knowledge Transfer
标题: 统一二进制代码嵌入和知识转移的渐进Transformer
链接:https://arxiv.org/abs/2412.11177
作者: Hanxiao Lu, Hongyu Cai, Yiming Liang, Antonio Bianchi, Z. Berkay Celik
摘要:Language model approaches have recently been integrated into binary analysis tasks, such as function similarity detection and function signature recovery. These models typically employ a two-stage training process: pre-training via Masked Language Modeling (MLM) on machine code and fine-tuning for specific tasks. While MLM helps to understand binary code structures, it ignores essential code characteristics, including control and data flow, which negatively affect model generalization. Recent work leverages domain-specific features (e.g., control flow graphs and dynamic execution traces) in transformer-based approaches to improve binary code semantic understanding. However, this approach involves complex feature engineering, a cumbersome and time-consuming process that can introduce predictive uncertainty when dealing with stripped or obfuscated code, leading to a performance drop. In this paper, we introduce ProTST, a novel transformer-based methodology for binary code embedding. ProTST employs a hierarchical training process based on a unique tree-like structure, where knowledge progressively flows from fundamental tasks at the root to more specialized tasks at the leaves. This progressive teacher-student paradigm allows the model to build upon previously learned knowledge, resulting in high-quality embeddings that can be effectively leveraged for diverse downstream binary analysis tasks. The effectiveness of ProTST is evaluated in seven binary analysis tasks, and the results show that ProTST yields an average validation score (F1, MRR, and Recall@1) improvement of 14.8% compared to traditional two-stage training and an average validation score of 10.7% compared to multimodal two-stage frameworks.
最近,语言模型方法已经被集成到二进制分析任务中,如函数相似性检测和函数签名恢复。这些模型通常采用两个阶段的训练过程:通过机器代码的屏蔽语言建模(MLM)进行预训练和针对特定任务进行微调。虽然MLM有助于理解二进制代码结构,但它忽略了基本的代码特性,包括控制和数据流,这会对模型泛化产生负面影响。最近的工作利用基于转换器的方法中特定于域的特性(例如,控制流图和动态执行跟踪)来改进二进制代码语义理解。然而,这种方法涉及复杂的特征工程,这是一个繁琐和耗时的过程,在处理剥离或模糊的代码时可能会引入预测不确定性,从而导致性能下降。本文介绍了一种新的基于转换器的二进制代码嵌入方法ProTST。ProTST采用基于独特树状结构的分层训练过程,知识从根的基本任务逐步流向叶的更专业的任务。这种渐进的师生范式允许模型建立在先前学习的知识之上,从而产生高质量的嵌入,可以有效地用于各种下游二进制分析任务。在7个二元分析任务中对ProTST的有效性进行了评估,结果表明,ProTST得到了平均验证分数(F1、MRR和Recall@1)与传统的两阶段培训相比提高了14.8%,与多模态两阶段框架相比平均验证分数为10.7%。
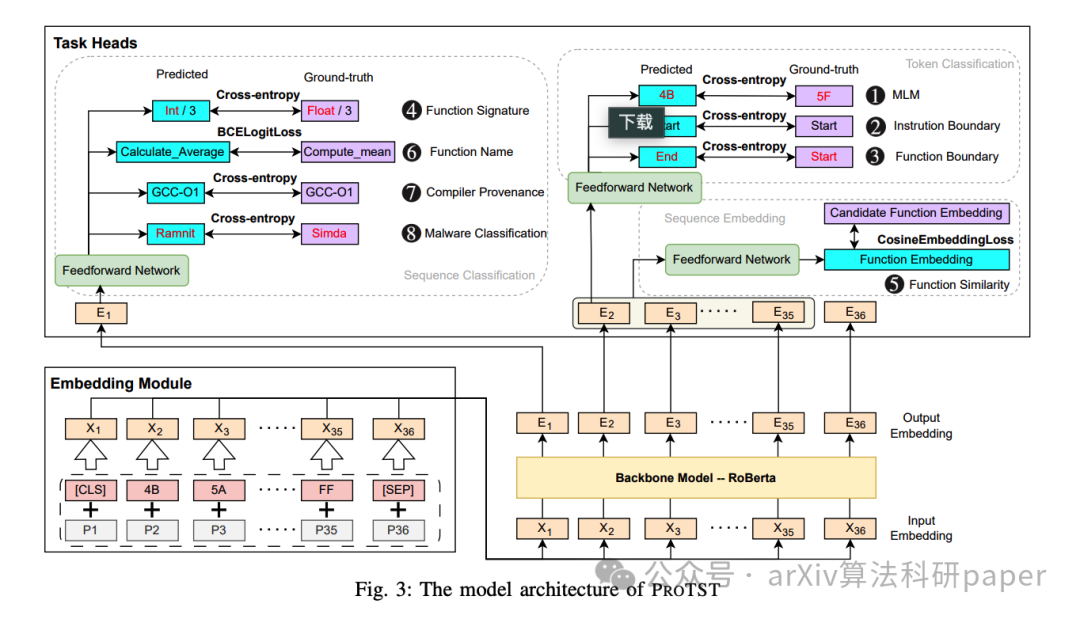
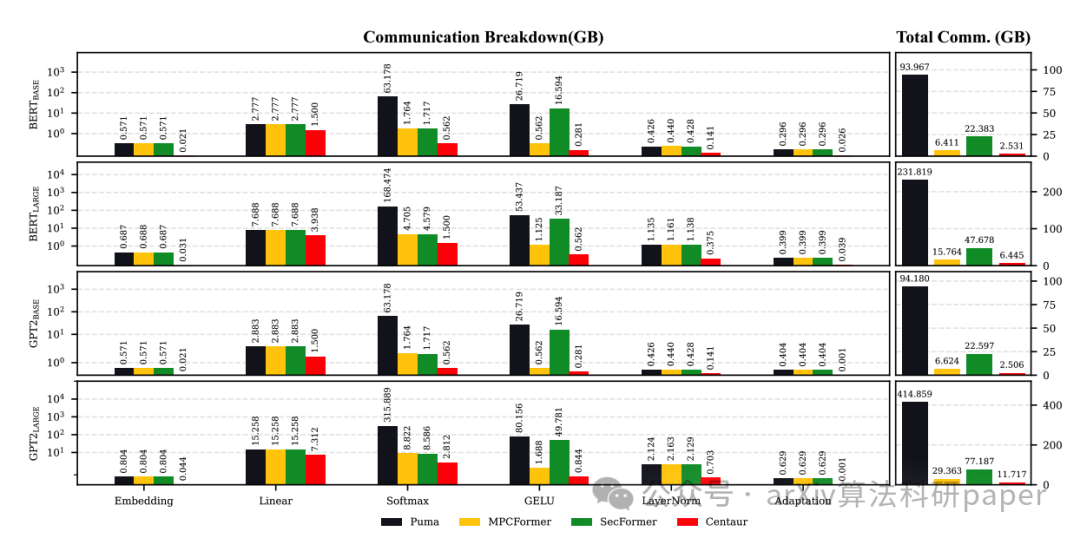
【6】 Centaur: Bridging the Impossible Trinity of Privacy, Efficiency, and Performance in Privacy-Preserving Transformer Inference
标题: Centaur:在隐私保护的Transformer推理中弥合隐私、效率和性能这一不可能的三位一体
链接:https://arxiv.org/abs/2412.10652
作者: Jinglong Luo, Guanzhong Chen, Yehong Zhang, Shiyu Liu, Hui Wang, Yue Yu, Xun Zhou, Yuan Qi, Zenglin Xu
摘要:As pre-trained models, like Transformers, are increasingly deployed on cloud platforms for inference services, the privacy concerns surrounding model parameters and inference data are becoming more acute. Current Privacy-Preserving Transformer Inference (PPTI) frameworks struggle with the “impossible trinity” of privacy, efficiency, and performance. For instance, Secure Multi-Party Computation (SMPC)-based solutions offer strong privacy guarantees but come with significant inference overhead and performance trade-offs. On the other hand, PPTI frameworks that use random permutations achieve inference efficiency close to that of plaintext and maintain accurate results but require exposing some model parameters and intermediate results, thereby risking substantial privacy breaches. Addressing this “impossible trinity” with a single technique proves challenging. To overcome this challenge, we propose Centaur, a novel hybrid PPTI framework. Unlike existing methods, Centaur protects model parameters with random permutations and inference data with SMPC, leveraging the structure of Transformer models. By designing a series of efficient privacy-preserving algorithms, Centaur leverages the strengths of both techniques to achieve a better balance between privacy, efficiency, and performance in PPTI. We comprehensively evaluate the effectiveness of Centaur on various types of Transformer models and datasets. Experimental results demonstrate that the privacy protection capabilities offered by Centaur can withstand various existing model inversion attack methods. In terms of performance and efficiency, Centaur not only maintains the same performance as plaintext inference but also improves inference speed by 5.0−30.4 times.
随着预训练模型(如Transformers)越来越多地部署在云平台上用于推理服务,围绕模型参数和推理数据的隐私问题变得越来越严重。当前的隐私保护转换推理(PPTI)框架与隐私、效率和性能的“不可能三位一体”作斗争。例如,基于安全多方计算(SMPC)的解决方案提供了强大的隐私保障,但也带来了显著的推理开销和性能权衡。另一方面,使用随机排列的PPTI框架实现了接近纯文本的推理效率,并保持了准确的结果,但需要公开一些模型参数和中间结果,从而存在严重的隐私泄露风险。用一种技术解决这个“不可能的三位一体”的问题具有挑战性。为了克服这一挑战,我们提出了一种新的混合PPTI框架Centaur,与现有的方法不同,Centaur利用变压器模型的结构,通过随机排列和SMPC推理数据来保护模型参数。通过设计一系列高效的隐私保护算法,Centaur充分利用这两种技术的优势,在PPTI中实现隐私、效率和性能之间的更好平衡。我们综合评估了Centaur在各种变压器模型和数据集上的有效性。实验结果表明,Centaur提供的隐私保护功能能够抵抗现有的各种模型反转攻击方法。在性能和效率方面,Centaur不仅保持了与明文推理相同的性能,而且推理速度提高了5.0−30.4倍。
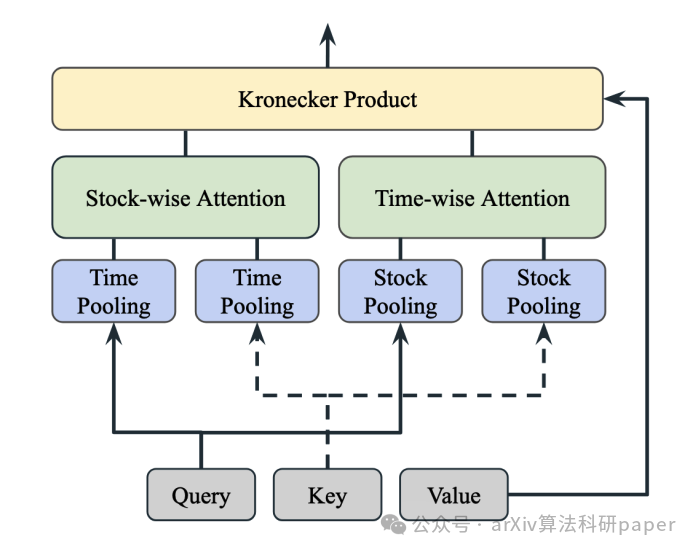
【7】 Higher Order Transformers: Enhancing Stock Movement Prediction On Multimodal Time-Series Data
标题: 更高级的Transformer:增强多峰时间序列数据的股票走势预测
链接:https://arxiv.org/abs/2412.10540
作者: Soroush Omranpour, Guillaume Rabusseau, Reihaneh Rabbany
摘要:In this paper, we tackle the challenge of predicting stock movements in financial markets by introducing Higher Order Transformers, a novel architecture designed for processing multivariate time-series data. We extend the self-attention mechanism and the transformer architecture to a higher order, effectively capturing complex market dynamics across time and variables. To manage computational complexity, we propose a low-rank approximation of the potentially large attention tensor using tensor decomposition and employ kernel attention, reducing complexity to linear with respect to the data size. Additionally, we present an encoder-decoder model that integrates technical and fundamental analysis, utilizing multimodal signals from historical prices and related tweets. Our experiments on the Stocknet dataset demonstrate the effectiveness of our method, highlighting its potential for enhancing stock movement prediction in financial markets.
在本文中,我们通过引入高阶变换器(一种用于处理多元时间序列数据的新型结构)来解决预测金融市场中股票运动的挑战。我们将自我注意机制和变压器架构扩展到更高的层次,有效地捕获跨时间和变量的复杂市场动态。为了管理计算复杂度,我们提出了一种低秩近似的潜在大注意张量使用张量分解和采用核注意,减少复杂度的线性方面的数据大小。此外,我们提出了一个编码器-解码器模型,该模型集成了技术和基本分析,利用历史价格和相关tweet的多模态信号。我们在Stocknet数据集上的实验证明了我们的方法的有效性,突出了它在金融市场中增强股票运动预测的潜力。
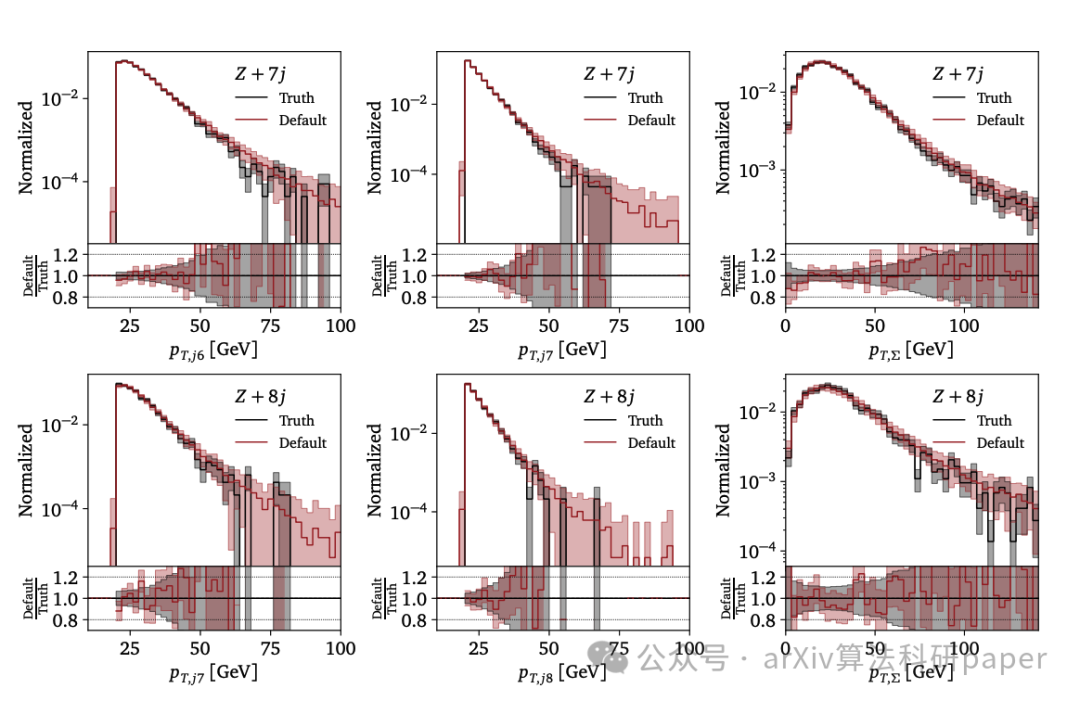
【8】 Extrapolating Jet Radiation with Autoregressive Transformers
标题: 用自回归变形器外推喷射辐射
链接:https://arxiv.org/abs/2412.12074
作者: Anja Butter, François Charton, Javier Mariño Villadamigo, Ayodele Ore, Tilman Plehn, Jonas Spinner
摘要:Generative networks are an exciting tool for fast LHC event generation. Usually, they are used to generate configurations with a fixed number of particles. Autoregressive transformers allow us to generate events with variable numbers of particles, very much in line with the physics of QCD jet radiation. We show how they can learn a factorized likelihood for jet radiation and extrapolate in terms of the number of generated jets. For this extrapolation, bootstrapping training data and training with modifications of the likelihood loss can be used.
生成网络是LHC事件快速生成的有力工具。通常,它们用于生成具有固定数量粒子的配置。自回归变换器允许我们产生具有可变粒子数的事件,非常符合QCD喷流辐射的物理。我们展示了他们如何学习射流辐射的因式分解的可能性,并根据产生的射流的数量进行外推。对于这种外推,可以使用自举训练数据和修改似然损失的训练。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 1943
1943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









