






自2022年11月发布以来,ChatGPT引发了关于大型语言模型(LLMs)和一般人工智能能力的广泛讨论。现在很少有人没听说过ChatGPT或尝试过它。尽管像GPT、Gemini或Claude这样的工具非常强大,拥有数百(甚至数千)亿的参数,并在大量文本语料库上进行预训练,但它们并非万能。有些特定任务这些模型无法胜任。然而,我们并非没有解决这些任务的办法。我们可以利用小型开源模型的力量,将它们适应到我们的特定问题上。
本博客旨在简要概述一些较小的开源LLMs,并解释两个关键的LLM微调概念:量化和LoRA。此外,我们将介绍一些最受欢迎的微调库以及代码示例,以便您能快速将这些概念应用到您的用例中。让我们深入了解微调。
目录
1、“小”型大型语言模型 2、量化 3、低秩适应(LoRA) 4、Unsloth 5、监督微调训练器(SFT) 6、优势比偏好优化(ORPO) 7、结论 8、参考文献
“小”型大型语言模型
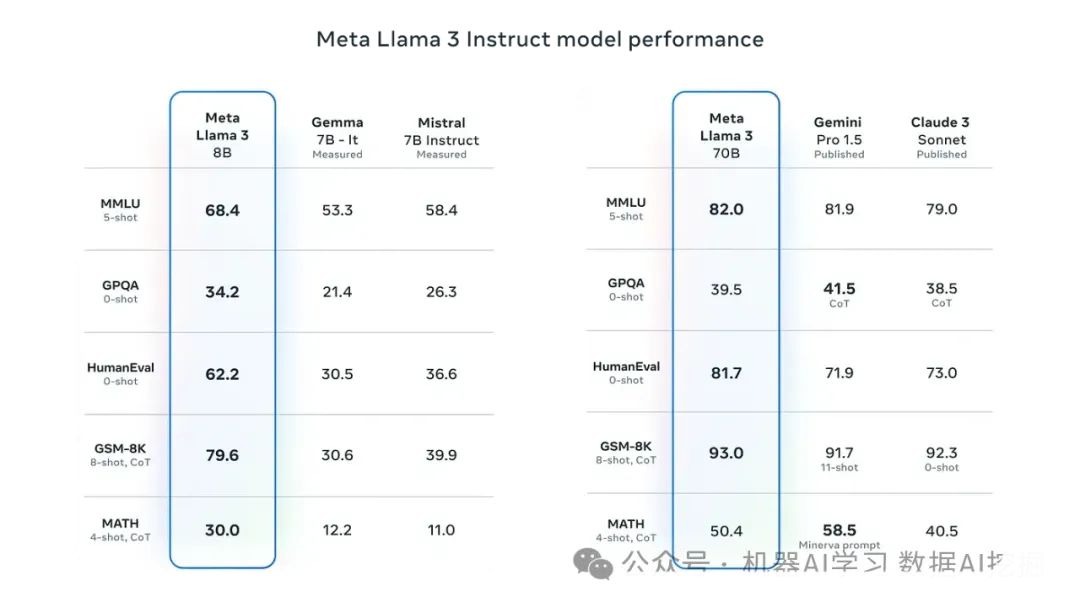
微调LLMs可能代价昂贵,尤其是对于参数数量庞大的模型。根据经验法则,通常参数在100亿以下的模型可以进行微调而不会碰到显著的基础设施挑战。然而,对于像Llama 3 70B这样的大型模型,则需要大量资源。对一个700亿参数的模型如Llama 3进行微调大约需要1.5TB的GPU显存。为了直观比较,这个数量级的显存相当于一个大约有20块Nvidia A100组成的集群,每块有80GB的显存。假设硬件是可用的,这样的设置成本约为40万美元。
或者,人们可以使用云服务提供商,如AWS、Azure或GCP,但这种方法同样成本高昂。例如,使用AWS上的一块Nvidia A100 GPU一小时的成本是40美元。如果你要在20个GPU上对700亿参数模型进行5天的微调,费用大约会是10万美元。
由于这些成本,大多数实践者主要使用参数少于100亿的较小LLMs。这些模型可以更经济地训练,只需要16GB到24GB的显存(用于更大的批量大小和更快的训练)。例如,我在AWS上使用一块Nvidia A100将Mistral 7B微调为塞尔维亚语,不到10小时就完成了,成本不到20美元。
当然,如果没有量化,特别是4位量化,一个70亿参数的模型仍然无法在这么大的显存中完成训练。
量化如果使用完整的32位参数,我们仍然需要大量的显存来训练LLM——大约需要150GB,这对于人类来说是一个荒谬的数字.
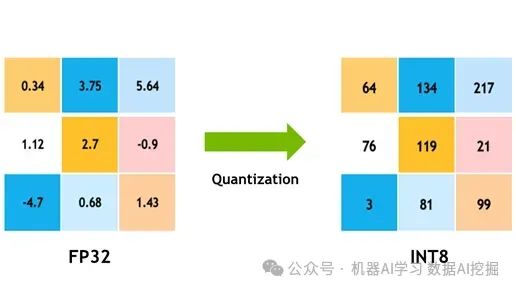
量化通过将模型参数转换为低精度数据类型(如8位或4位)来提供解决方案,显著降低了内存消耗并提高了执行速度。概念很直接:所有可能的32位值都被映射到一个较小的有限值范围(例如,对于8位转换是256)。这个过程可以被视为围绕几个固定点的高精度值分组,这些固定点代表了它们附近的值。
**低秩适应(LoRA)**LoRA是一种通过使用矩阵维数约简来更新模型权重的技术。这项技术尤其相关,因为广泛应用于LLMs的变压器严重依赖矩阵。关于LoRA在低层次工作的详细解释可以在Jay Alammar的博客文章中找到。
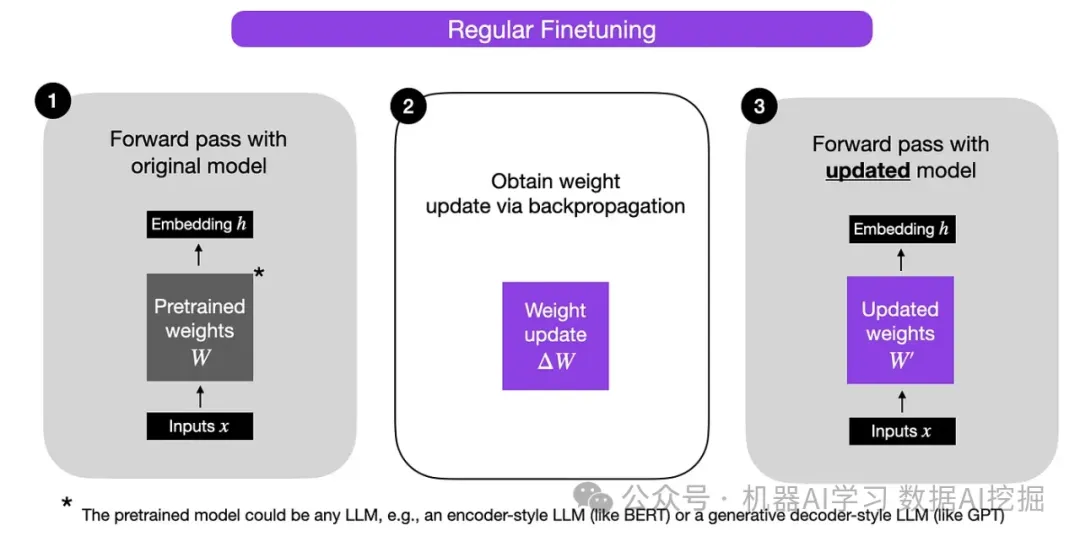
在更新模型权重时,需要调整这些矩阵内的参数。从概念上讲,这种调整可以被视为将一个权重更新矩阵加到原始矩阵上:W’ = W + ΔW。LoRA引入了一种新颖的方法,通过将这个更新矩阵分解成两个较小的矩阵,当这两个矩阵相乘时,接近更新矩阵。在微调过程中,LoRA不是创建然后分解更新矩阵,而是直接创建这两个较小的矩阵用于乘法运算。
下面几张图片中可以看到常规微调和使用LoRA进行微调之间的直观比较。
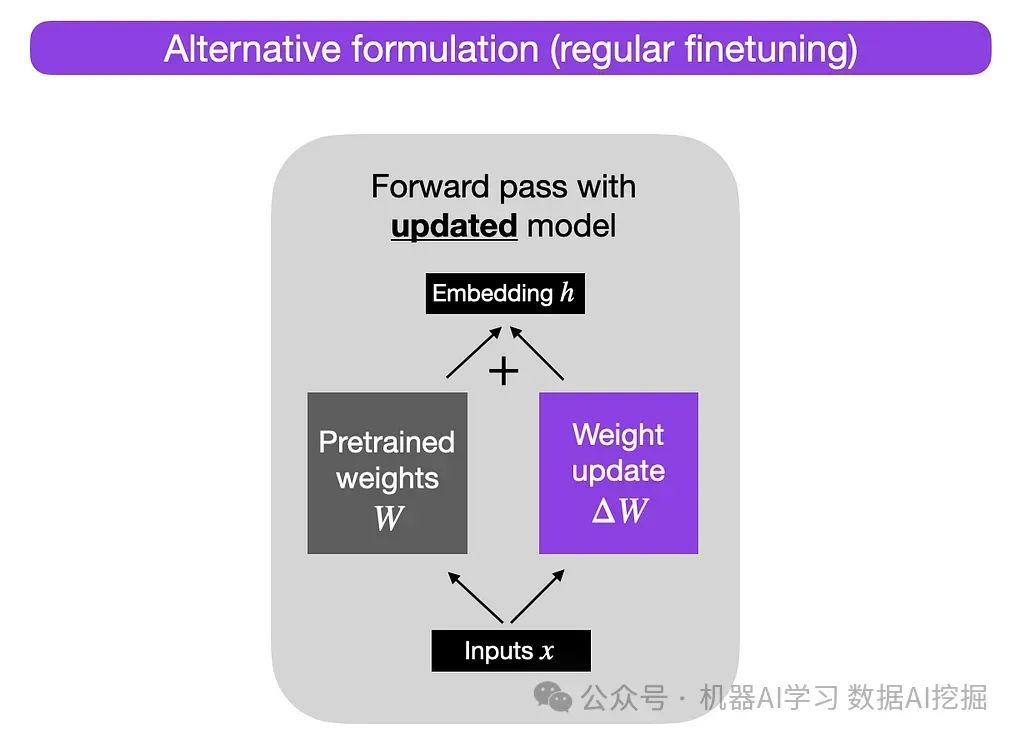
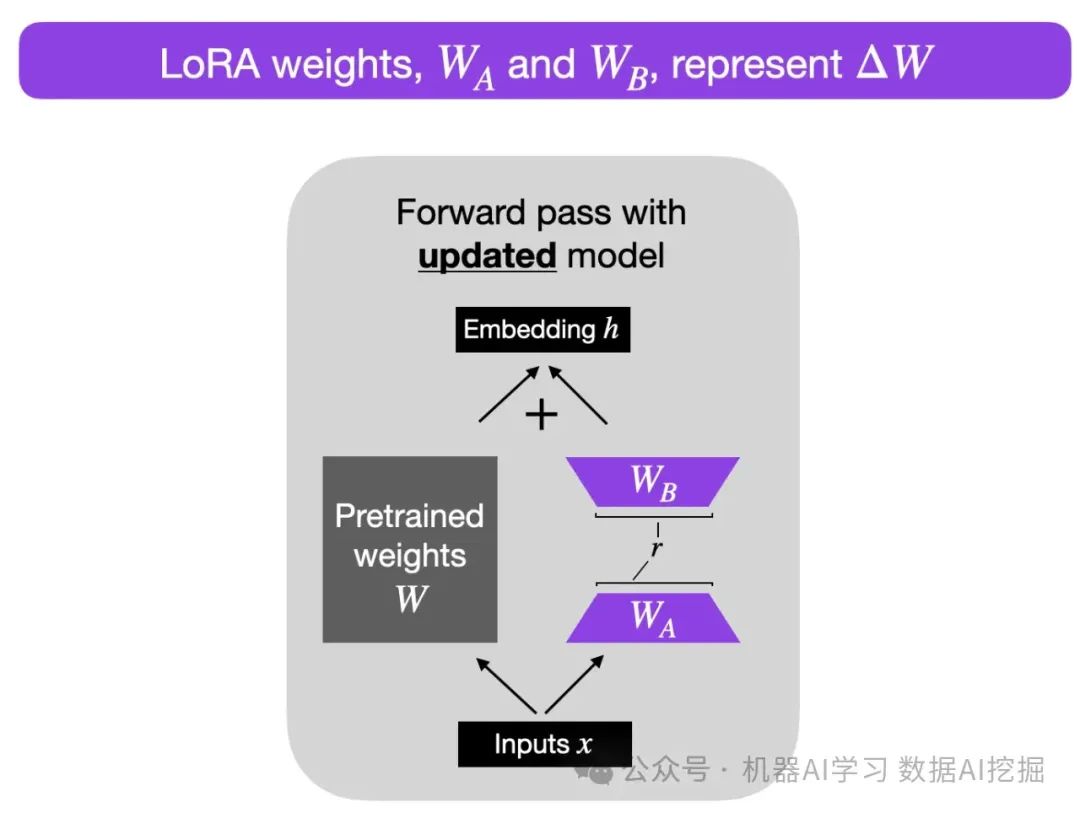
LoRA的关键好处是,尽管近似稍微不那么精确,但它显著提高了内存和计算效率。例如,考虑一个有1000x1000参数的矩阵,总共有100万参数。通过使用分解后(略微不精确)的1000x100乘以100x1000矩阵的版本,参数数量减少到只有2*100k,实现了80%的参数减少。
量化和LoRA通常结合使用,形成了所谓的QLoRA。
Unsloth如果我重新开始进行LLM微调,我会选择Unsloth Python库。Unsloth提供了一系列针对LLM微调的优化,并支持包括Mistral、Llama 3、Gemma等在内的多种流行的LLMs。例如,他们的免费层级包括了12种不同的针对Mistral的微调优化,提供了显著的2.2倍加速。
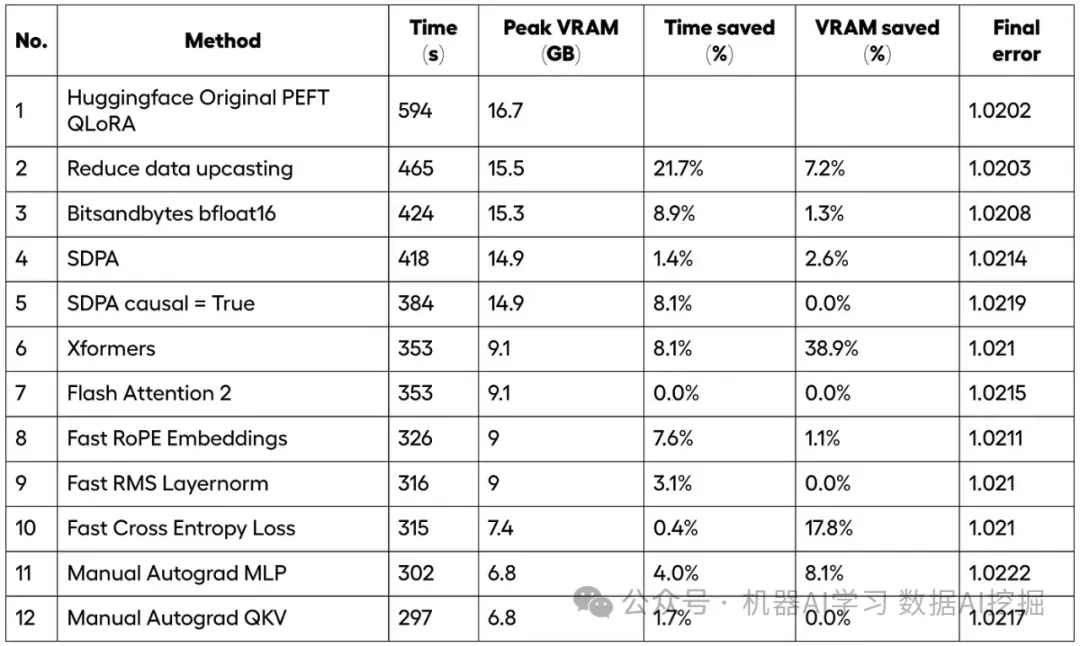
以下是使用Unsloth库微调Llama 3 8B的代码片段。所有这些代码块都取自Unsloth的GitHub,完整的用于微调Llama 3 8B的笔记本可以在这里找到。
以4位精度导入模型:
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/llama-3-8b-bnb-4bit",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
# token = "hf_...", # use one if using gated models like meta-llama/Llama-2-7b-hf
)
安装LORA:
model = FastLanguageModel.get_peft_model(
model,
r = 16, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
# [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes!
use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context
random_state = 3407,
use_rslora = False, # We support rank stabilized LoRA
loftq_config = None, # And LoftQ
)
初始化Hugging Face的监督微调训练器:

训练模型:
trainer_stats = trainer.train()
监督微调训练器(SFT)在预训练一个LLM之后,下一个关键步骤是监督微调。这个过程对于开发一个能够理解并生成连贯响应的模型至关重要,而不仅仅是完成句子。
像Hugging Face的SFT(监督微调训练器)和PEFT(参数高效微调),以及Tim Dettmers的BitsAndBytes等工具,极大地简化了将LoRA、量化和微调等技术应用到模型的过程。这些库简化了高级优化方法的实施,使它们对开发者和研究人员更加易于访问和高效。
下面,你会注意到Unsloth、SFT和ORPO的代码非常相似。这种相似性源于这些库背后的基本思想大致相同,差异主要在于库本身以及可能的一些超参数。
以4位精度导入模型:
# Hugging Face model id
model_id = "meta-llama/Meta-Llama-3-8B"
model_id = "mistralai/Mistral-7B-v0.1"
# BitsAndBytesConfig int-4 config
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16 if use_flash_attention2 else torch.float16
)
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=bnb_config,
use_cache=False,
device_map="auto",
token = os.environ["HF_TOKEN"], # if model is gated like llama or mistral
attn_implementation="flash_attention_2" if use_flash_attention2 else "sdpa"
)
model.config.pretraining_tp = 1
tokenizer = AutoTokenizer.from_pretrained(
model_id,
token = os.environ["HF_TOKEN"], # if model is gated like llama or mistral
)
tokenizer.pad_token = tokenizer.eos_
tokentokenizer.padding_side = "right"
安装LORA
初始化Hugging Face的监督微调训练器:
args = TrainingArguments(
output_dir="mistral-int4-alpaca",
num_train_epochs=1,
per_device_train_batch_size=6 if use_flash_attention2 else 2, # you can play with the batch size depending on your hardware
gradient_accumulation_steps=4,
gradient_checkpointing=True,
optim="paged_adamw_8bit",
logging_steps=10,
save_strategy="epoch",
learning_rate=2e-4,
bf16=use_flash_attention2,
fp16=not use_flash_attention2,
tf32=use_flash_attention2,
max_grad_norm=0.3,
warmup_steps=5,
lr_scheduler_type="linear",
disable_tqdm=False,
report_to="none"
)
model = get_peft_model(model, peft_config)

训练模型
trainer.train()
优势比偏好优化(ORPO)在这篇博客文章中,我们专注于大型语言模型(LLMs)的预训练和监督微调。然而,所有最先进的LLMs都经历了另一个关键步骤:偏好对齐。这一步骤发生在预训练和微调之后,你告知模型哪些生成的输出是可取的,哪些不是。流行的偏好对齐方法包括来自人类反馈的强化学习(RLHF)和直接偏好优化(DPO)。
一种名为优势比偏好优化(ORPO)的新方法于2024年3月出现,结合了监督微调和偏好对齐。
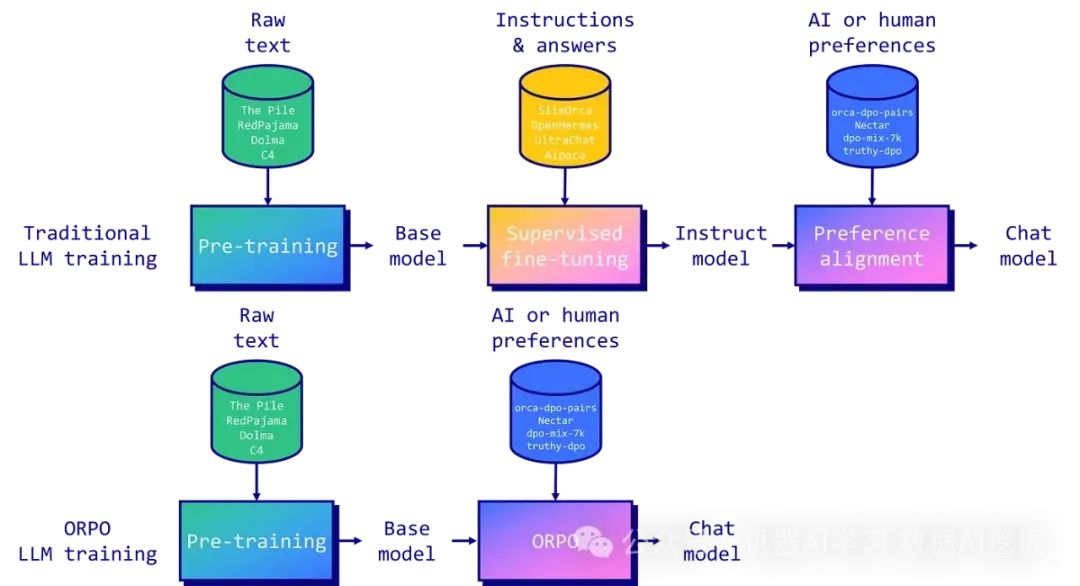
这里我们有一部分使用ORPO进行微调和偏好对齐的代码。完整代码可以在此处找到(https://colab.research.google.com/drive/1eHNWg9gnaXErdAa8_mcvjMupbSS6rDvi?usp=sharing)。
以4位精度导入模型:
配置LORA:
# LoRA config
peft_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=['up_proj', 'down_proj', 'gate_proj', 'k_proj', 'q_proj', 'v_proj', 'o_proj']
)
model = prepare_model_for_kbit_training(model)
翻译为:初始化Hugging Face的ORPO训练器:


trainer.train()
结论尽管像GPT、Gemini或Claude这样的大型语言模型(LLMs)功能强大,但它们的大规模和资源需求使它们在许多任务中不切实际。为了解决这个问题,可以使用量化和低秩适应(LoRA)等技术对较小的开源LLMs进行微调和定制以满足特定需求。这些技术减少了内存消耗并提高了计算效率,使得训练模型更加经济,尤其是对于那些参数少于100亿的模型。
像Unsloth、监督微调训练器(SFT)和优势比偏好优化(ORPO)这样的工具简化了微调过程,使其更加易于访问。例如,Unsloth提供的优化可以显著加速训练,而ORPO结合了监督微调和偏好对齐,以提高模型性能。
通过利用这些技术和工具,开发人员和研究人员可以根据特定需求定制LLMs,而无需承担与训练大型模型相关的高昂成本。这种方法使得高级语言模型的访问民主化,并在不同领域启用了广泛的应用。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 681
681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









