






LLMs 被视为 AI 领域的一个里程碑式的突破,但要将其应用于实际生产环境,并且还能用对、用好并非易事。模型的使用成本和响应延迟是目前将大语言模型(LLMs)应用于生产环境中的核心难题之一。
在本期刊载的这篇文章中,作者从自身项目的实践经验出发,分享了一系列实用技巧,帮助优化LLM Prompt ,能够一定程度上降低大模型的使用成本和响应延迟。
文章首先解析了导致高成本和高延迟的根源在于输入输出 tokens 的数量,而非任务本身的复杂度。接下来,作者逐一阐述了包括提示词拆分、模块化设计、与传统编程技术结合使用等多种优化策略。这些策略体现了作者对大模型应用本质的深刻理解,注重发挥 LLMs 在复杂推理方面的优势,同时将数学计算、数据聚合等工作外包给 SQL/Python 等更高效的工具。
本文贯穿了一种务实的方法论 —— 理性看待 LLMs 技术,扬长避短,与其他技术工具形成合力,而非将其视为解决一切问题的“灵丹妙药”。这种观点和方法论对于企业更好地将 LLMs 技术应用于生产实践至关重要。

image generated by author with GPT-4o
高成本和延迟是将大语言模型应用于生产环境中的主要障碍之一,二者均与提示词信息的体量(prompt size)紧密相连。
鉴于大语言模型(LLM)展现出极强的广泛适用性,不少人视其为解决各类问题的灵丹妙药。通过与诸如检索增强生成技术(RAG)及 API 调用等在内的工具整合,并配以精细的指导性提示词,LLM 时常能展现出逼近人类水平的工作能力。
然而,这种无所不包的应用策略,其潜在隐患在于可能会导致提示词的信息量迅速膨胀,直接引发高昂的使用成本以及较大的响应延迟,令 LLMs 在生产环境的实际部署面临重重困难。
针对高价值任务(如代码优化任务)使用 LLMs 时,成本这方面的考量或许会退居其次 —— 一段平常半小时才能编写完成的代码现在等待半分钟即完成,花费一定的成本尚可接受。但转至 To C 领域,面对成千上万次的即时对话需求,成本控制与响应速度便成为决定项目成败的关键。
本文将分享为 Resider.pl 构建由 LLM 支持的房地产搜索助手 “Mieszko” 这一过程的心得。本文的重点是:如何跨越从吸引眼球的概念验证(impressive POC)到在实操中有效运用 LLMs 的鸿沟。
01
Prompt is all you have
在构建 “Mieszko” 时,我非常倚重 LangChain 这一个出色的框架。该框架以一种有序且清晰的方式,将复杂的逻辑或组件抽象化,并配备了高效易用的提示词模板,仅需寥寥数行代码即可实现调用。
LangChain 的易用性或许会让我们不经意间忘却一个核心要点:不论我们的解决方案有多么繁琐,实质上所有组件都会汇总成一条长长的文本信息——“指令性提示词”——传递给LLM。接下来将要展示的内容是一个概括性的示例说明,用于展示 LLM Agent 在接收指令性提示词或执行任务前,其输入提示词的基本结构和主要组成部分。

使用 LLM Agent 中的指令性提示词模板时所采用的基本结构
02
是什么影响了使用成本和响应延迟?
LLMs(大语言模型)是有史以来构建的最复杂的人工智能模型之一,但其响应延迟和使用成本主要取决于输入和输出处理的 tokens 数量,而非任务本身的难度。
撰写本文时,OpenAI 旗舰模型 GPT-4 Turbo 的定价公式大致如下:

响应延迟的相关计算方法则并不那么直接,但根据 “Mieszko” 的应用场景,可简单归结为以下这个公式:
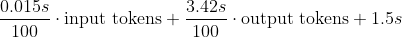
从成本角度看,input tokens 通常是 LLMs 使用成本的“大头”,其价格仅为 output tokens 的三分之一,但对于更复杂的任务,提示词长度会远超面向用户的 output tokens 长度。
然而,延迟主要受 output tokens 影响,处理 output tokens 的时间大约是 input tokens 的 200 倍。
在使用 LLM Agents 时,约 80% 的 tokens 来自 input tokens ,主要是初始的提示词和 Agents 推理过程中的消耗。这些 input tokens 是使用成本的关键组成部分,但对响应时间的影响有限。
03
监控和管理 tokens 的消耗
在构建任何 LLMs 应用程序时,除了初始提示词模板之外,至少还需要以下组件:
- 记忆库(每次与 LLMs 的交互(每次调用)中,都需要包含之前所有的对话消息或历史上下文。)
- 工具箱(如供 LLMs 调用的API),及其详细的指导性提示词
- 检索增强生成(RAG)系统及其产生的上下文
从技术上讲,我们可以添加任意数量的工具,但如果依赖最简单的 Agent&Tools 架构,可能系统的扩展性就会很差。对于每一种可用的工具,都需要在每次调用 Agents 时发送诸如 API 文档之类的详细说明。
**在准备新系统组件时,需要考虑每次调用增加多少个 tokens 是值得的。**如果使用的是 OpenAI 的模型,可以快速评估新工具或额外的指导性提示词的“tokens 消耗”情况,方法如下:
- 直接访问网站:https://platform.openai.com/tokenizer
- 如果你更喜欢使用 Python,可以使用 tiktoken 库,通过以下简单函数实现:

04
如何在保持提示词精简的同时不牺牲准确性
初次接触时,大语言模型(LLMs)可能令人感到无所适从,但归根结底,重要的是要记住我们打交道的仍是软件。这意味着我们应当事先预料到会出现错误,管理和控制软件系统设计中的抽象层次和模块化程度,并寻找更高效的解决方案来处理子任务。
在开发 Mieszko 的过程中,我发现以下一些通用技巧特别有用。我将在未来几周内撰写后续文章讲解其中的大多数通用技巧,因此,如果你想不错过这些内容,欢迎您在此(https://medium.com/@janekmajewski/subscribe)订阅我的个人主页,以便在文章发布时接收到通知。
4.1 将大段提示词拆分成多层然后再调用
软件工程的关键原则之一是模块化和抽象化。试图用单个提示词来处理更复杂的问题,就如同编写难以维护的“意大利面条式”代码(Spaghetti code)(译者注:这个比喻来源于意大利面(spaghetti)缠绕不清、难分难解的形象。当一段代码缺乏清晰的结构、正确的模块划分和合理的逻辑顺序,而是充斥着大量的嵌套条件语句、无序的跳转、重复的代码块时,就被视为“意大利面式代码”。)一样低效。
在构建 Mieszko 时,性能显著提升的一个关键点是将提示词拆分为两个部分:
- 用于决策的 Agent (Decision Agent):对下一步可以采取的措施以及如何处理提示词输出的一般指导原则。
- 用于执行任务的 Agent / 对话型 LLMs 系统:含有针对具体步骤(如房源搜索、数据比较或房地产知识查询)的详细指导性提示词。
分层决策与执行架构图
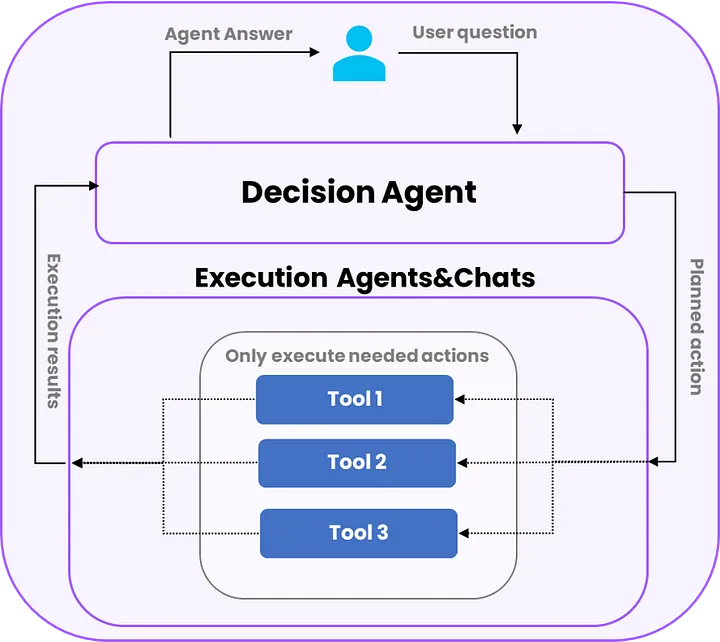
分层决策和执行调用架构图,图片由原文作者提供
这种架构使得我们能够在每次调用时,首先选取需要使用的特定任务提示词,而无需随附沉重的、消耗大量 tokens 的执行指令(execution instructions),从而平均减少了超过 60% 的 tokens 使用量。
4.2 务必监控每次调用时的最终提示词
LLM 接收到的最终提示词(final prompt)可能与最初的提示词模板相去甚远。通过工具(tools)、记忆库(memory)、上下文(context)及 Agent 的内部推理来丰富提示词模板这一过程,可能会使提示词的规模激增数千个 tokens 。
此外,LLMs 有时会展现出如洛奇·巴尔博亚(Rocky Balboa)(译者注:洛奇·巴尔博亚(Rocky Balboa),美国电影《洛奇》系列的主角,业余拳击手出身,凭借自身的努力,登上拳坛最高峰。)般的韧性,即使面对存在错误和矛盾的提示词,也能“站起来”给出合理的答案。
通过仔细审查数十次 LLMs 的调用,并深入了解大语言模型(LLM)实际上接收到了什么信息,能为关键突破(key breakthroughs)和消除漏洞(bug elimination)提供宝贵洞见。我强烈推荐使用 LangSmith 来进行深入分析。
如果想要寻求最简便的方案,也可以启用 LangChain 中的调试功能,它将为我们提供每次调用时确切发送的提示词,以及大量有用信息,帮助我们更好地监控和优化提示词内容。
import langchain
langchain.debug=True
4.3 如只需几行代码即可处理的事,向 LLMs 提交前请三思
**在使用 LLMs 时,最大的误区是忘记你仍然可以利用编程来解决问题。**以我为例,一些最大的性能提升,就是通过使用 Python 函数在 LLMs 调用的上下游处理一些极为简单的任务。
在使用 LangChain 时,这一点尤为有效,我们可以轻松地将 LLMs 的调用与传统的 Python 函数进行链式处理。下面是一个简化的示例,我曾用它来解决一个难题:即便指示 LLMs 保持回答与用户发送的消息相同的语言,LLMs 仍默认回复英文。
我们无需借助 LLMs 来检测目前的对话使用的是什么语言,利用 Google Translate API 或甚至是一个简单的 Python 库(如 langdetect ),可以更快、更准确地完成这项任务。一旦我们确定了输入语言,就可以明确地将其传入指导性提示词中,从而减少在 LLMs 的调用过程中需要处理的工作量。

4.4 在设计 Agent 的提示词时要精打细算,因为它们通常至少会被调用两次
集成了工具的 Agent 能够将 LLMs 的能力提升到新的层次,但同时它们也非常消耗 tokens(计算资源)。 下面的图表展示了 LLM Agent 针对 query 提供答案的一般逻辑流程。
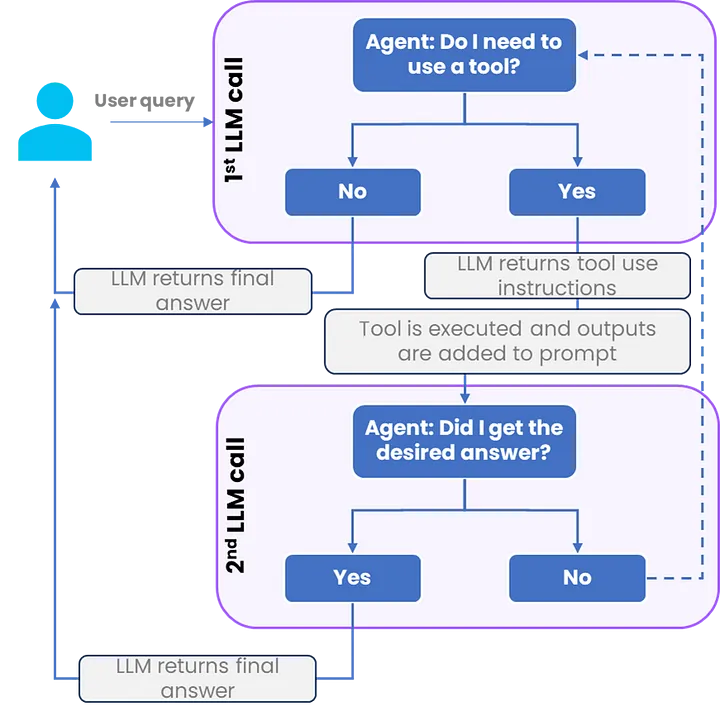
AI Agent 两次调用 LLM,图片由原文作者提供
如上图所示,Agent 通常至少需要调用 LLM 两次:第一次是为了规划如何使用工具,第二次则是解析这些工具的输出以便给出最终答案。这一特点意味着,我们在设计提示词时节省的每一个 token,实际上都会带来双倍的效益。
对于某些较为简单的任务,采用 Agent 的方式可能是“用牛刀杀鸡”,而直接使用带有 Completion 的简单指导性提示词(译者注:模型接收到 instruction prompt 后的内容生成过程。)可能就能够达到相似的结果,且速度甚至还能快上一倍。以 Mieszko 项目为例,我们决定将大部分任务从 Multi-Agent 架构转变为基于特定任务的 Agent+Completion 模式。
4.5 将大语言模型和传统编程工具结合使用,发挥各自的优势(Use LLMs for reasoning but calculate and aggregate with SQL or Python)
相较于早期的 GPT-3.5,最新顶尖大语言模型已经有了很大的进步,那时它们在处理基础数学公式时都还会出错。现在,在诸如计算 segment averages (译者注:在一组数据中,将数据分成若干个段或区间,然后计算每个段内数据的平均值。)任务上,LLMs 已经能够轻松处理数百个数字。
但它们更擅长编写 Python 或 SQL,无需数以万亿计的模型参数,就能以 100% 的准确率执行复杂的数学运算。然而,向 LLMs 传递大量数字会消耗大量 tokens ,在最好的情况下,每 3 位数字都会转换为一个 token ;若数值庞大,单个数字就可能占用多个 tokens 。
想要更低成本、更高效率地分析数学运算,获得运算结果,窍门在于如何运用 LLMs 理解问题及手头数据,继而将之转译为 SQL 或 Python 这类更适合进行数学分析的编程语言。
实践中,可将编写的代码嵌入一个函数内执行,此函数负责连接数据源并仅将最终分析结果呈现给 LLM,供其直接理解、分析。
05
Summary
希望本文介绍的这些通用技巧,能够帮助各位读者更好地了解 LLMs 应用中使用成本和响应延迟的主要影响因素,以及如何优化它们。我希望尽可能多地分享我在开发基于 LLM 的生产级应用中学到的关键经验教训。在本系列接下来的文章中,我将从更具体、实践性更强的实践案例着手:
- 使用 Python guardrails (译者注:使用 Python 编写基于规则的验证函数。)提升 LLM 输出内容的可靠性
- 通过模块化和抽象化(Modularity and Abstraction)增强 LLM Agents
- 利用 LangSmith 了解、监控基于 LLMs 的应用(预计六月中旬发布)
最后,特别感谢 Filip Danieluk ,并向 Filip Danieluk 致以崇高的敬意,他是 Mieszko 引擎的 co-creator 。无数个昼夜的深入讨论和结对编程(pair-programming)催生了本系列文中阐述的内容,这些见解既属于我,也属于 Filip 。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 790
790

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









