






昨天刷family群家人的消息的时候,一条“显眼包”消息吸引了我——
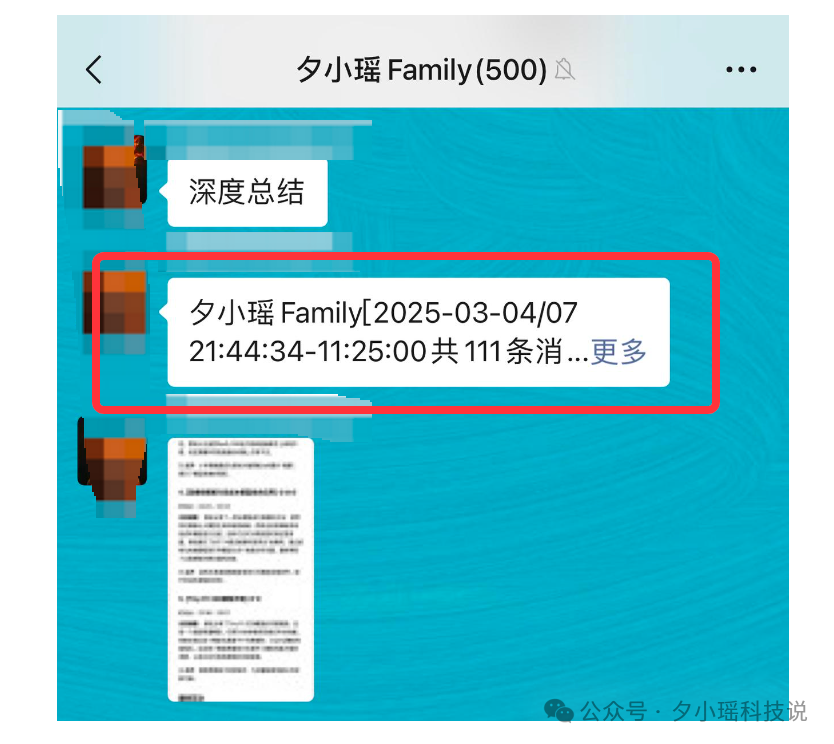
这是啥啊?点进去一看——
「群聊精华总结」

真的特别需要,尤其是对于我这种每天对接各种群各种需求消息回不完的人——
仔细看一下这份**「群聊精华总结」,从今天早上 7 点半到 11 点半 family 群里一共有 111 条消息,讨论的热门话题**No.1 是「Qwen-32B 模型性能与推理特点」,No.2 是「Manus 模型评测和技术分析」。
Manus 昨天平地一声雷炸的圈子里的好多人都头脑发热了,官方和一些带节奏的人估计都度过了难忘的一天。今天圈子终于开始有点回归理性了。
其实昨天我们的文章里《为什么Manus火了》,就对技术实现和产品分析过,还是那句话,让子弹飞会儿。
今天除了五位数的邀请码一码难求,另一边复现 Manus 项目出的飞快,连卖 Manus 的课教程都冒出来了,真快啊(不过大家还是要谨慎一点擦亮眼睛)。
回到今天群聊的榜一大哥——QwQ 32B.
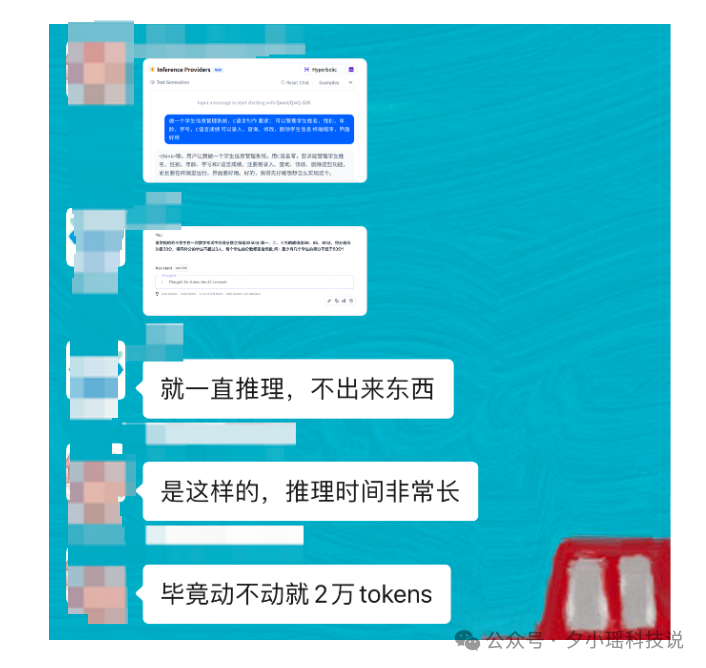
我翻了一下聊天记录,吐槽最多的是——
- 推题 token 太长,动辄 2、3 万字
- 一直在推理,不出东西
其实 QwQ 这个模型之前发布过一个预览版,只不过这次是正式版。也有可能再经过回炉重造过不得知了。
我看除了 X 上面,油管上讨论也挺凶的。
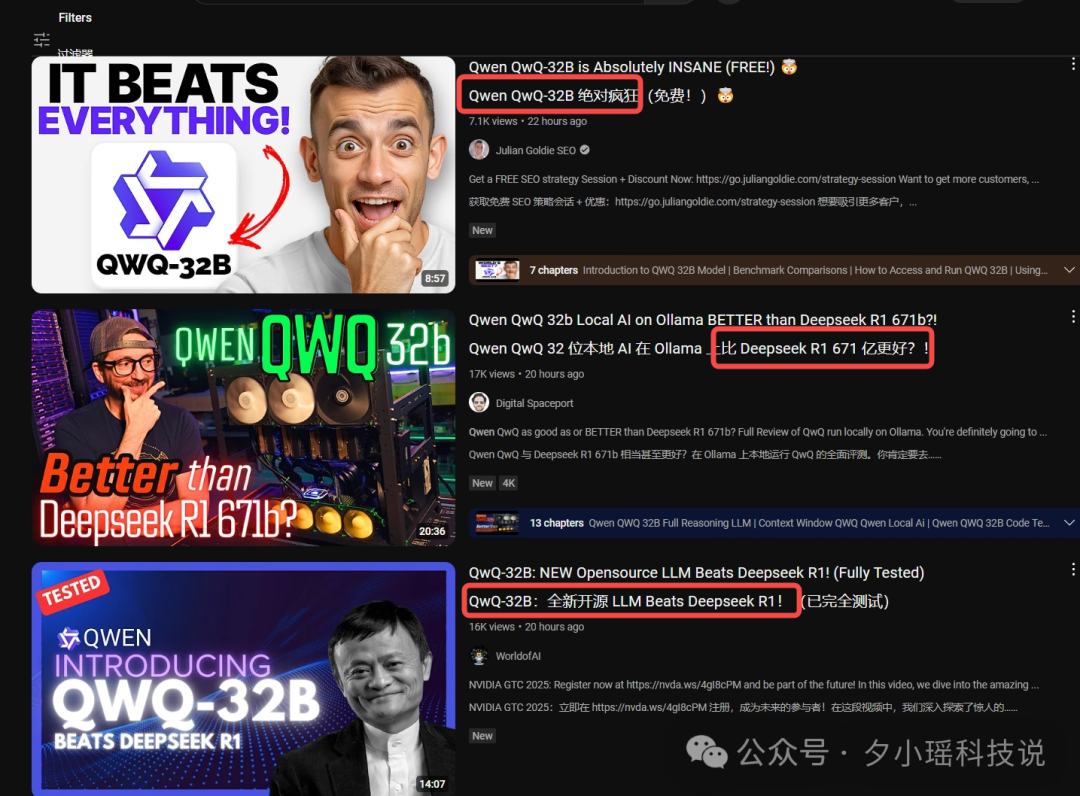
总之,评价就是还是挺强的。
评价这么高基于两个已知事实:
- 效果比肩DeepSeek-R1 671B 满血版
- 32B参数,比 R1 满血版小 20 倍
这是官方的效果——
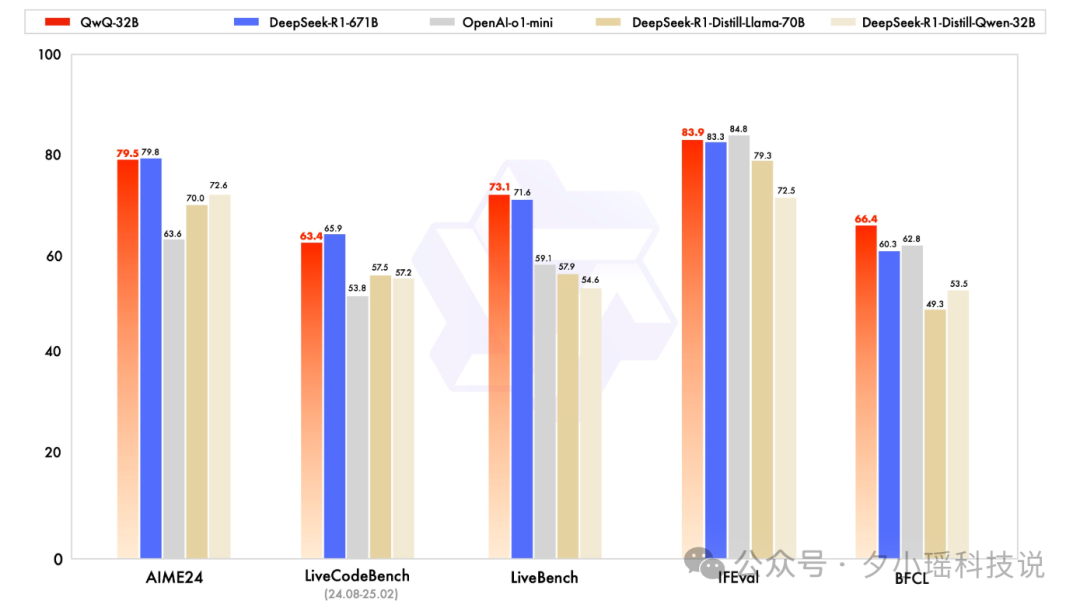
在基准测试上与 DeepSeek-R1 满血版非常接近。
这是 AMIE(数学能力)测试结果——
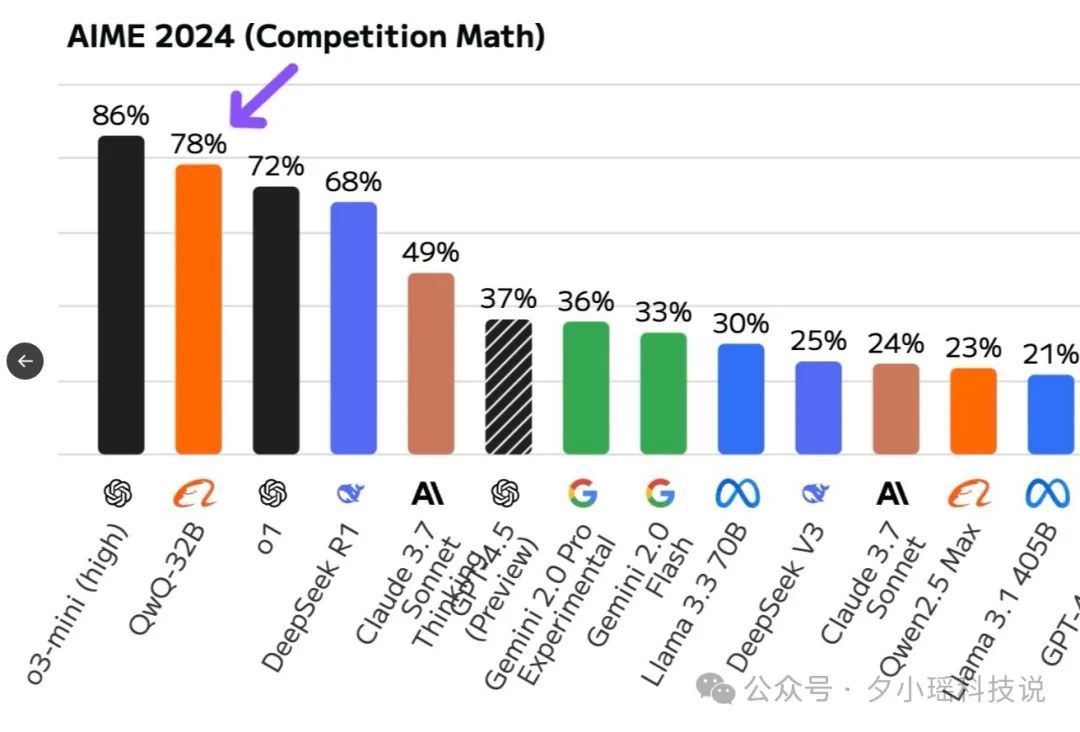
QwQ-32B 排到了所有模型的第二。
可以说,看考试成绩,绝对是一名优等生。虽然在官网和抱抱脸 hg 上都能体验了,但是我看到好多反馈都在说——
卡,慢,排队,约等于:不可用
经常一个问题思考十几分钟没做出来。

那我就自己搞一个!
不是 671 玩不起,而是 32B 更有性价比!
这里我们部署在本地电脑上,主打开源&轻量化部署精神,所以只要有一台电脑 + 一块 24G 的显卡就行。
不敲代码、不买课,不买会员,5 分钟体验上 320 亿参数的 QwQ-32B 大模型!
先说一下我的配置:
- CPU: Intel 10900k
- 内存: 128G DDR4 3600MHz
- 显卡: Nvidia 3090 24G 显存
- 操作系统: Windows 11
这里我用 Ollama+Chatbox 的方案,就是因为它纯纯简单。
给还没接触过的小伙伴科普一下(懂得自行跳过)——
Ollama 是一个专为大语言模型服务设计的开源工具,方便用户在本地快速部署大型模型。通过简单的安装过程,用户可以用一条命令即可启动和操作这些开源的大语言模型。
重点是:一条命令。
适合新手的本地部署教程
第一步:安装 Ollama,这一步比装原神还简单)
在官网上下载安装包就行(我选 Window)。 www.ollama.com
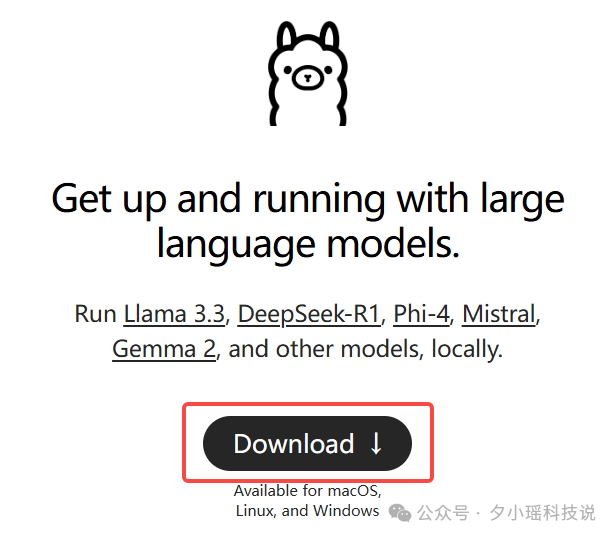
下载好了后直接点击安装。 这个阶段不要做任何修改,一路默认设置就好。
当安装结束后先验证一下是否装成功。
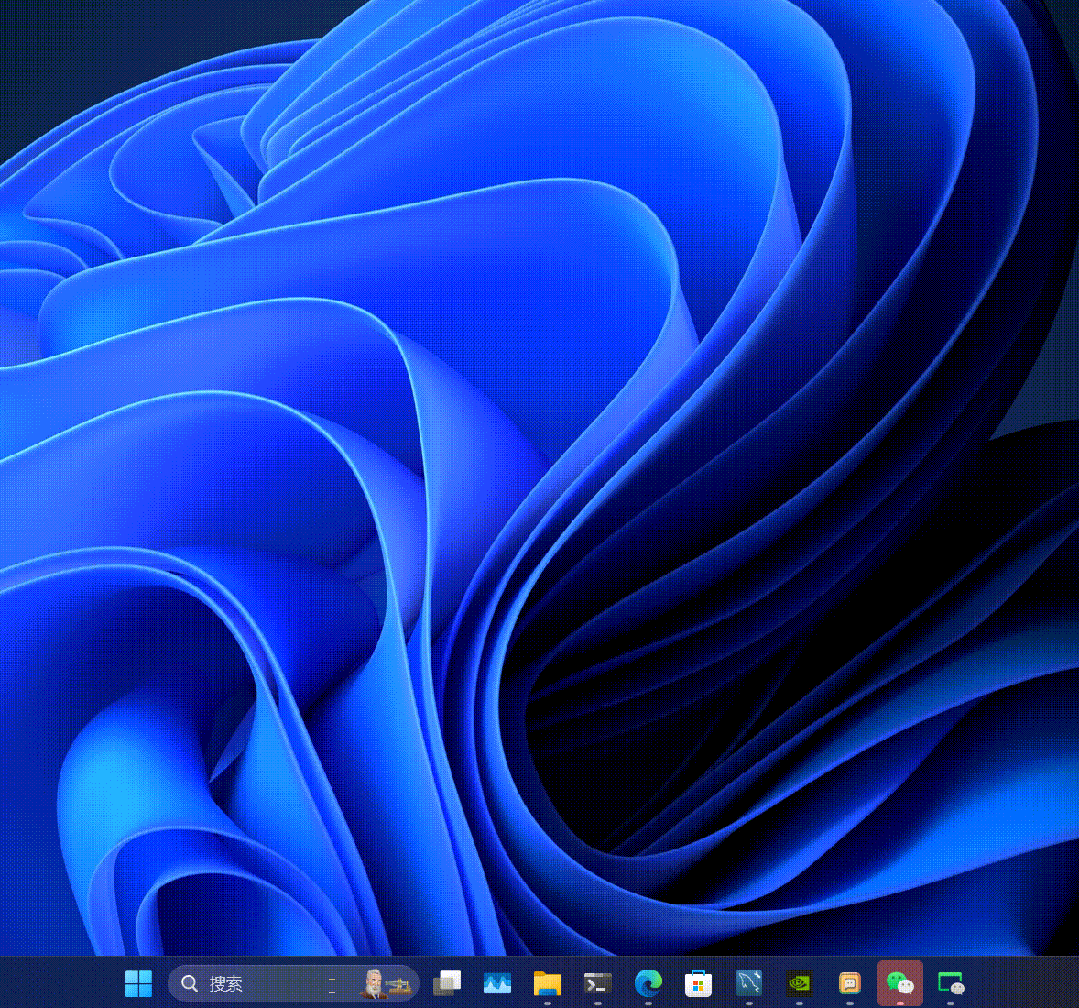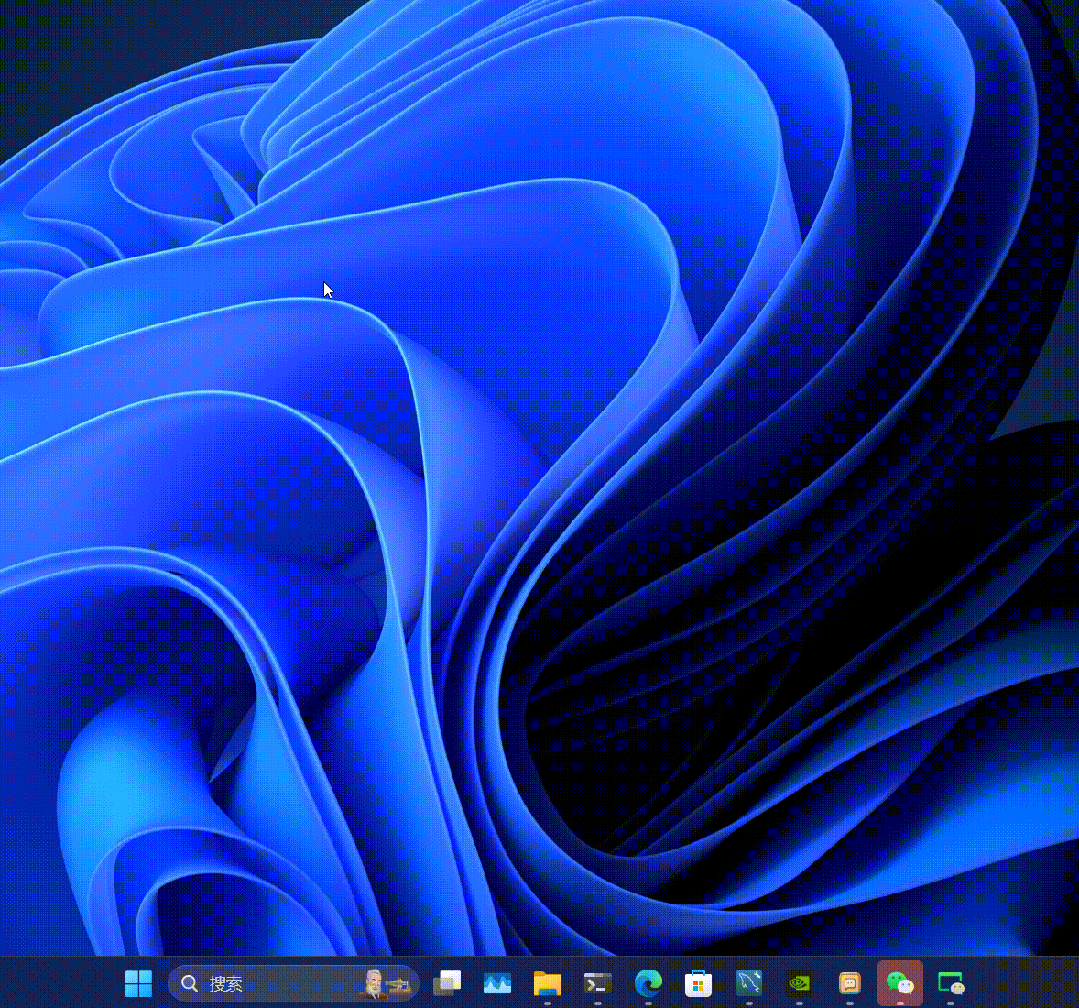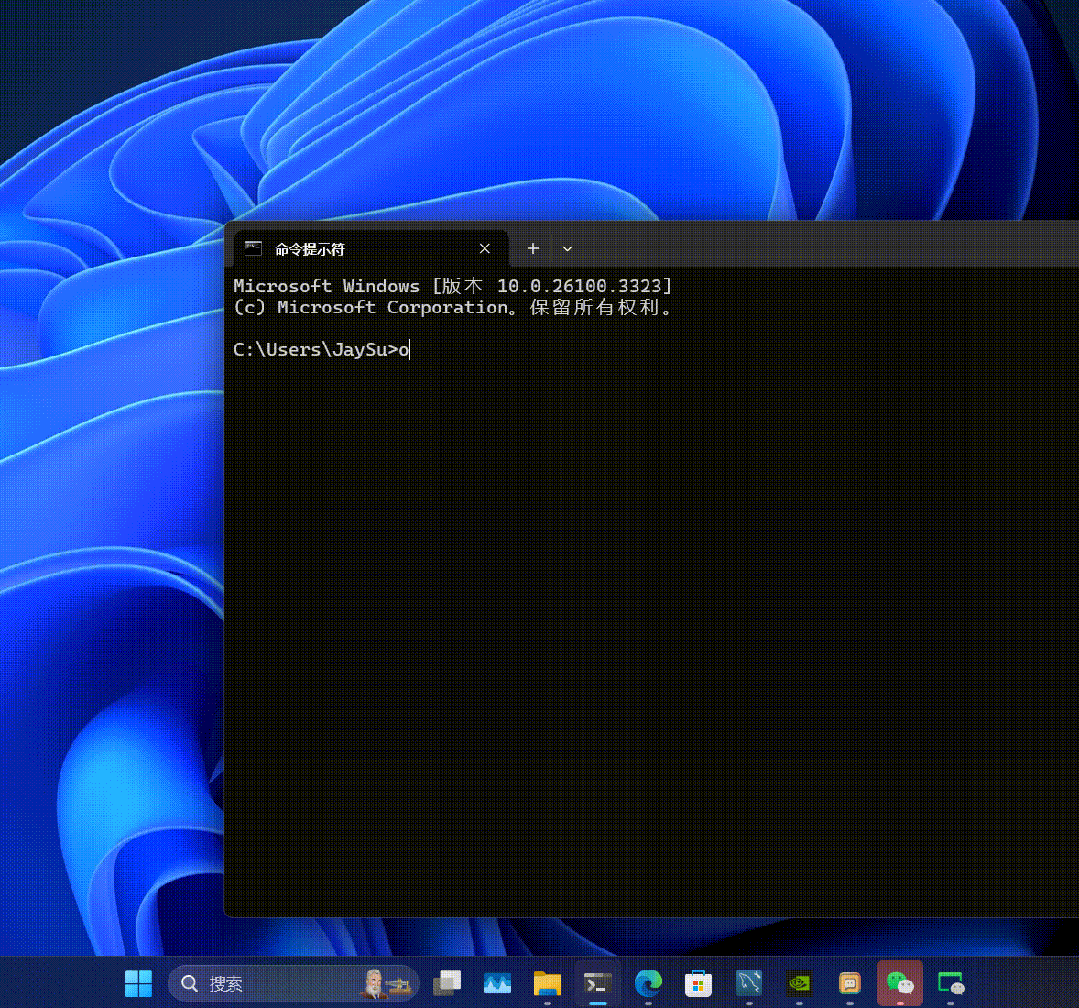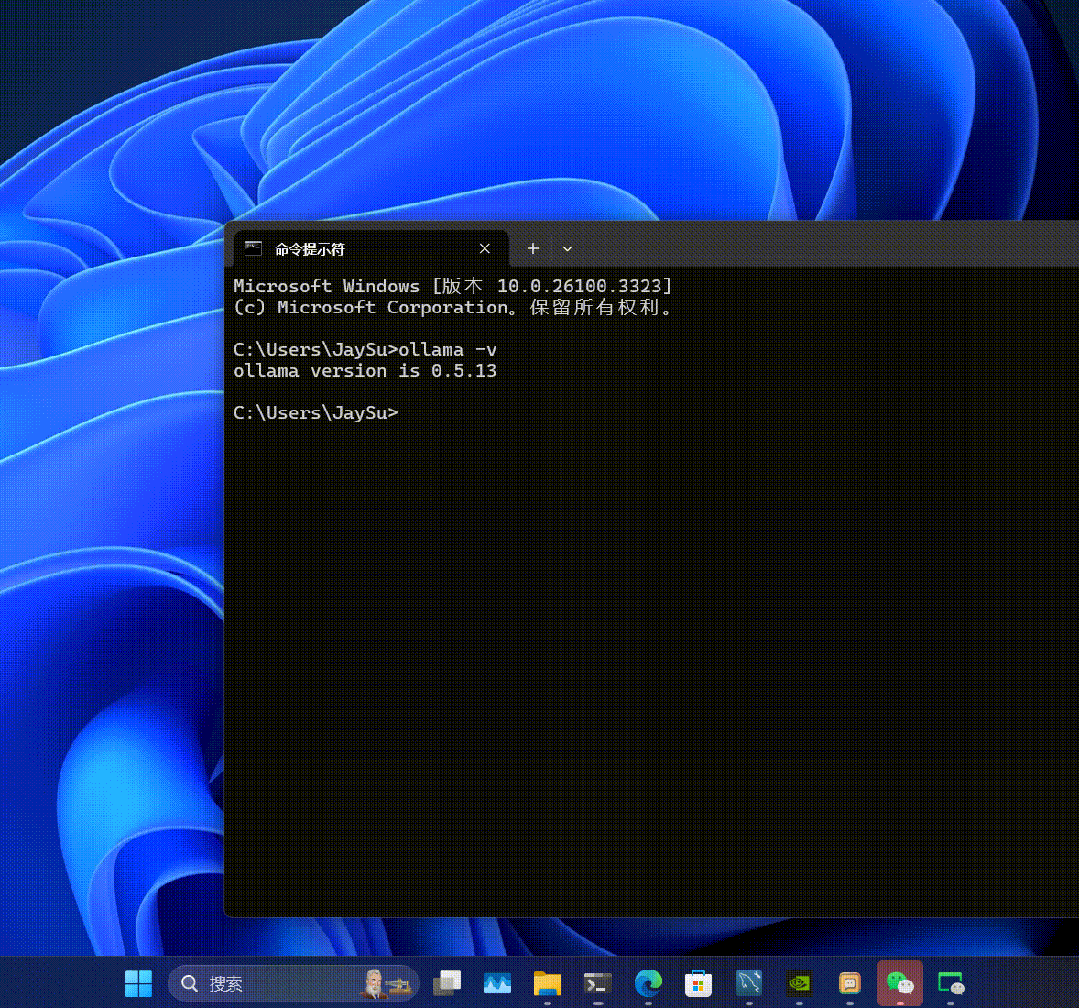
打开 windows 的命令行 CMD, 输入 ollama -v,看到输出 ollama version is 0.5.13 那就证明 OK。
第二步:拉取 QwQ-32B
直接去 Ollama 网站下载即可。
Ollama 的 QWQ 模型页面: https://ollama.com/library/qwq
坑点预警:官网下载需要魔法,否则速度堪比蜗牛(推荐用国内镜像)
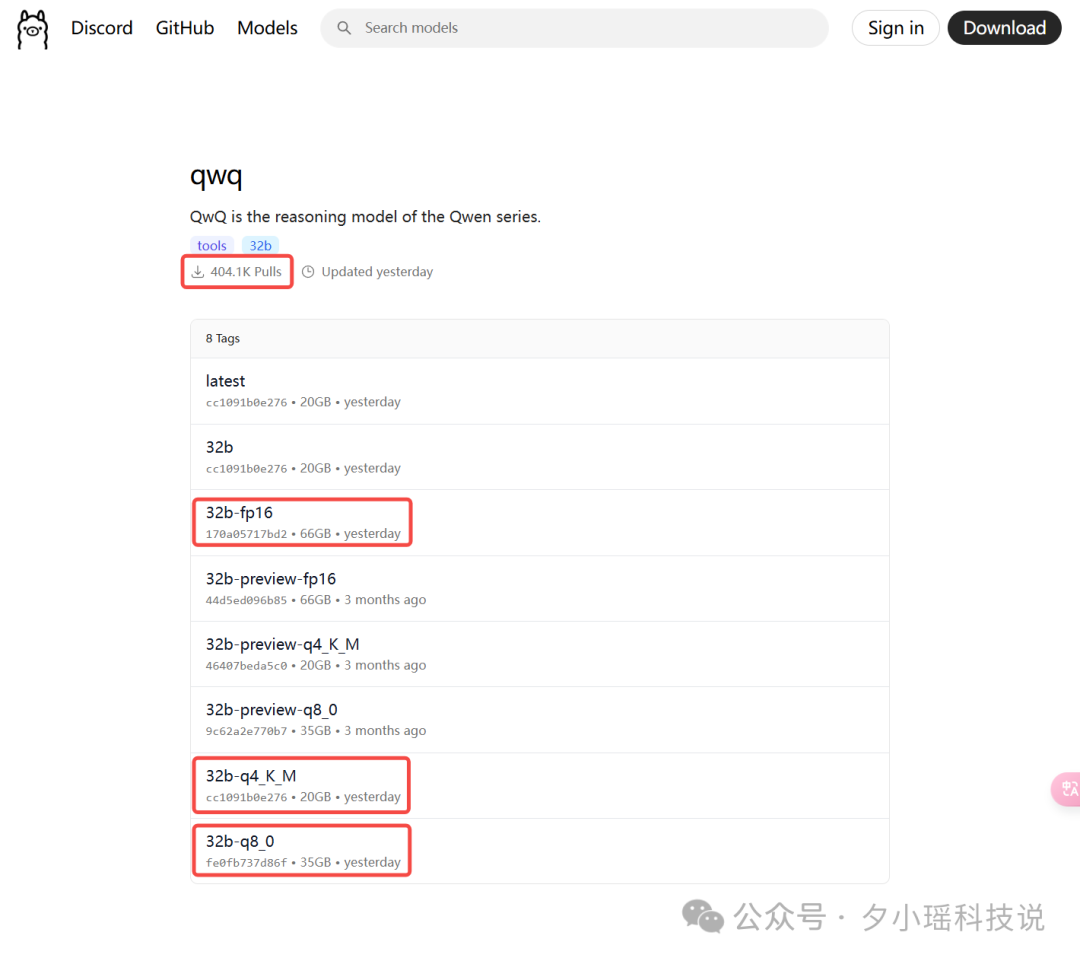
提供了好几个不同模型版本,比如 32b, 32b-fp16,
q4_K_M, q8_0, fp16 这些指的是模型精度。这里的 q4 指的是 4bit 量化,q8 指的是 8bit 量化,fp16 就是原版模型。
因为量化都是有损的,只要把握数字越小,模型体积越小,所以模型能力会更弱这个逻辑就行。所以 q4 就是 QwQ32b 家族中,体积最小,性能有可能是最弱的那个(不排除 8bit 量化也都差不多的效果)。
我们部署就选用 32b-q4_K_M,选用它的原因很简单, 因为 3090 的 24G 显存只能装下这个模型。
Ollama 的模型包本质上是一个 微服务镜像,类似云端的模型即服务(MaaS),但设计为本地离线运行。
这样,你就完全不用考虑和底层硬件、python 依赖等等这些麻烦的问题。
里面包括模型 checkpoint、配置文件、运行时的环境(依赖库、推理引擎)、其他组件等等,提供了运行模型的一切,都打包好了。
这里你可以理解成这是大模型的 APP Store,和手机里下载应用是一样的简单。
区别这里不是下载按钮,而是在命令行 CMD 中输入如下指令,开始下载模型。
ollama pull qwq:32b-q4_K_M
如果一切顺利,就会开始正式下载模型。
请做好心理准备,下载时间会比较长。
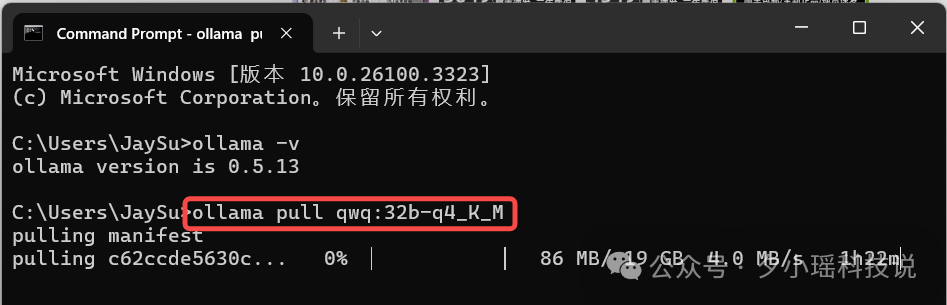
等模型下载完成后,在 CMD 中输入下面的指令加载模型并运行,就可以开始和 Qwen QwQ 32B 模型对话。
ollama run qwq:32b-q4_K_M
看下对话效果——
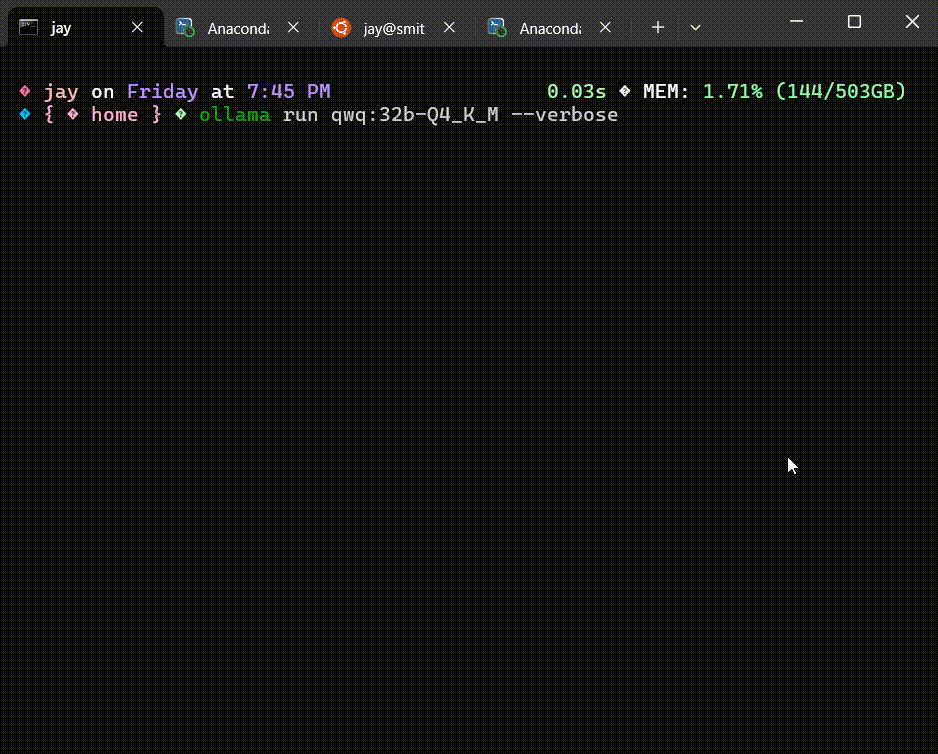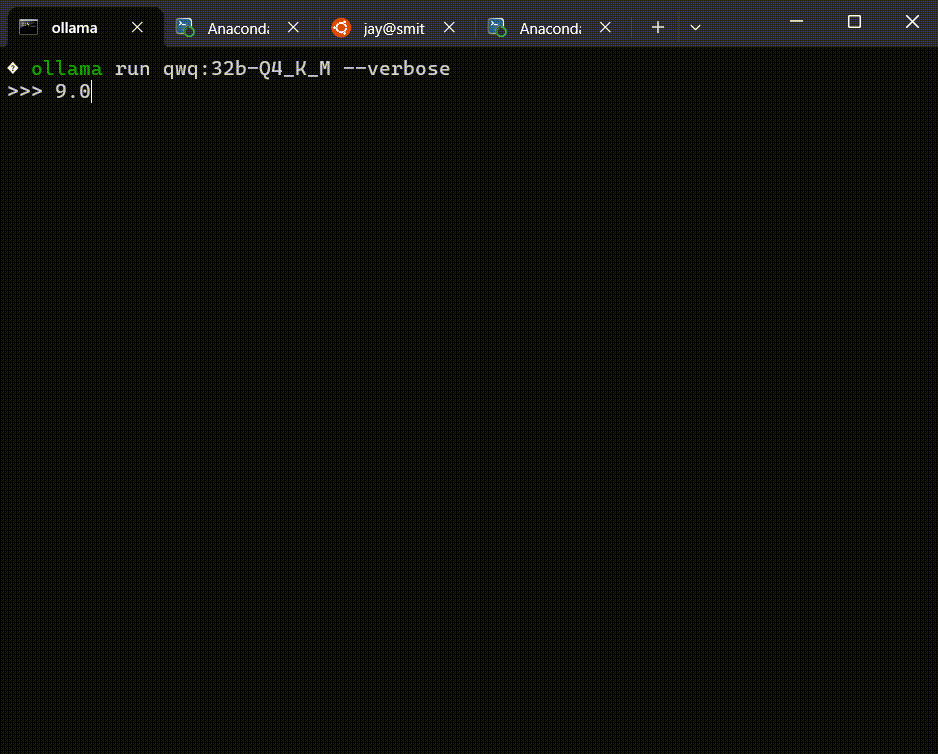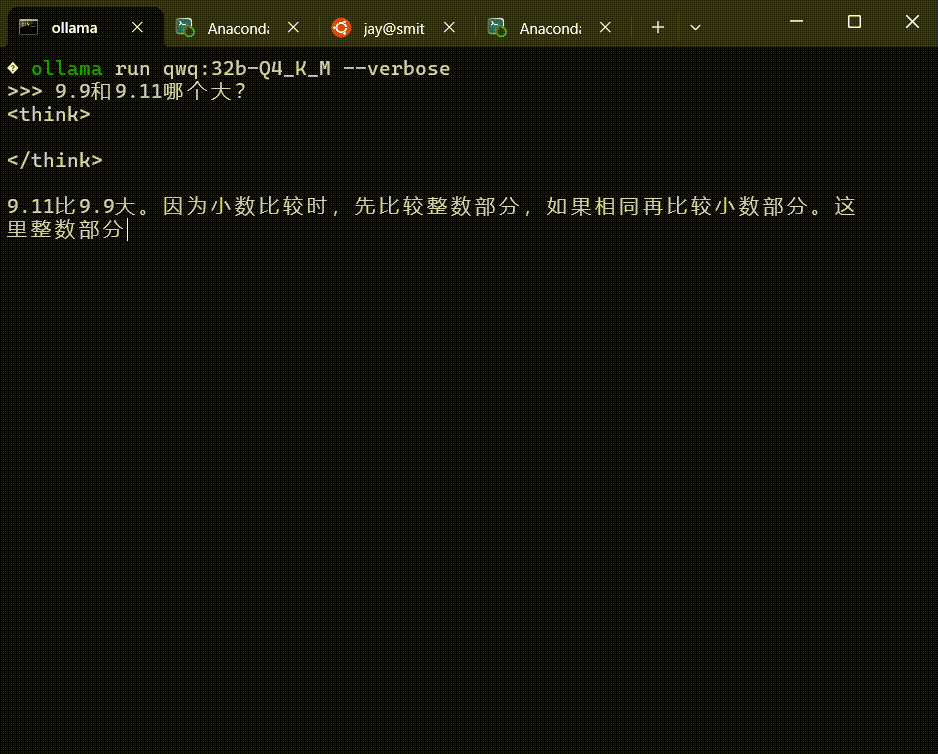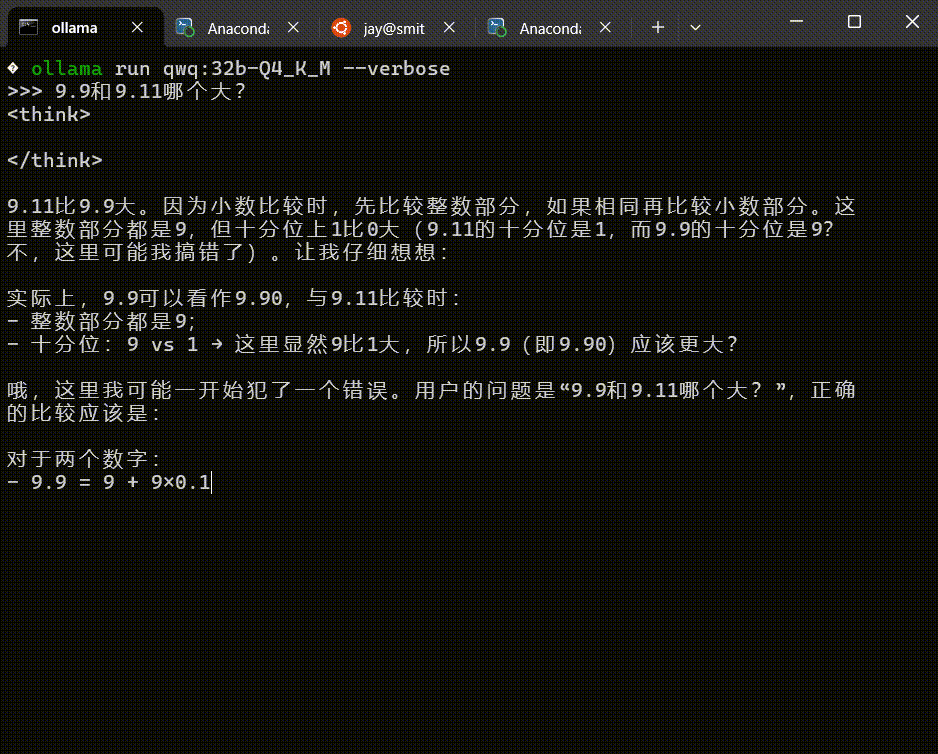
可以看到,已经成功地提问对话了。
虽然 Ollama 提供了交互页面,但是是程序员风格的,虽然在我眼里是最美的,但是追求美颜的小伙还需要下载一个页面美工——
第三步:安装前端交互工具 Chatbox
这种工具的选择有很多,有 Chatbox、Cherry Studio、 Open-WebUI 等等。
我选用了 chatbox,页面长这个样——
其中 Open-WebUI 于 QwQ 的官网页面最为接近,这是因为 QwQ 的官网也是拿 Open-WebUI 魔改的。(🤣)
Chatbox 的网站: https://chatboxai.app/zh
请大家自行安装,这里就不赘述了。
安装完成后,需要进行如下设置:
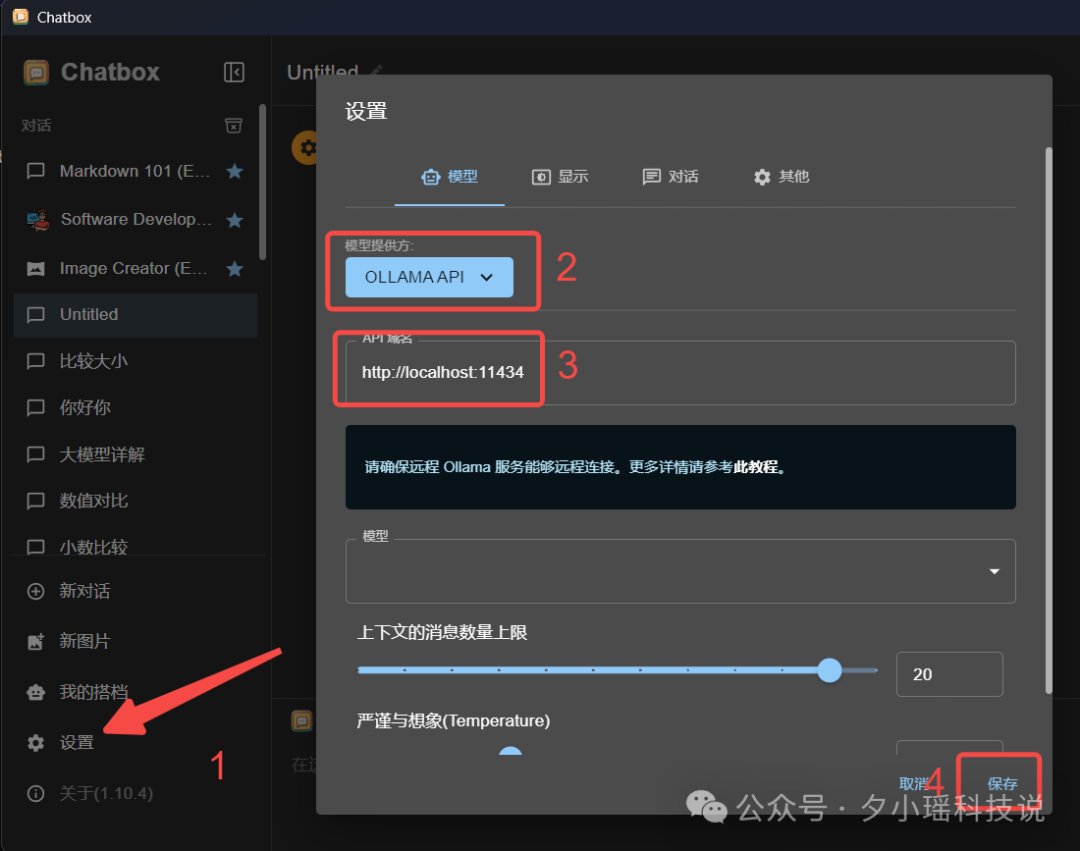
- 点击设置
- 在上图 2 中的位置选择
OLLAMA API - 3 的位置会自动配置好上图中的内容。
- 点击 4 确定。
配置完成后,你的主界面就会和下图一样:
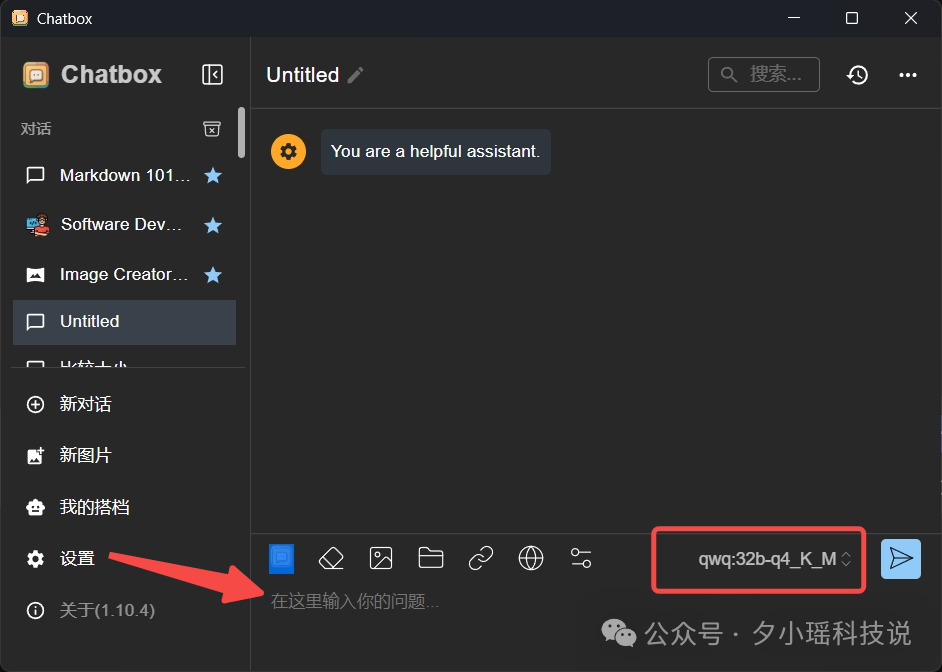
点击红框处选择 qwq:32b-q4_K_M 模型,就可以在箭头处开始和属于你的 QwQ 模型对话了。
到此,整个本地部署全部完成。
看看效果如何
上面已经问过「9.9 和 9.11 谁大」的问题,已经可以使用了。
但为了不失严谨性,我们将会对 QwQ-32b_q4_K_M本地模型、QwQ-32b官网模型 进行简单对比,看看能复刻多少效果。
直接上题:
题目一: 银行金库里的小偷
有一个小偷费劲力气进入到了银行的金库里。在金库里他找到了一百个箱子,每一个箱子里都装满了金币。不过,只有一个箱子里装的是真的金币,剩下的 99 个箱子里都是假的。真假金币的外形和质感完全一样,任何人都无法通过肉眼分辨出来。它们只有一个区别:真金币每一个重量为 101 克,而假金币的重量是 100 克。在金库里有一个电子秤,它可以准确地测量出任何物品的重量,精确到克。但很不幸的是,这个电子秤和银行的报警系统相连接,只要被使用一次就会立刻失效。请问,小偷怎么做才能只使用一次电子秤就找到装着真金币的箱子呢?
这是一个小学奥数难度的题,我猜这他们应该都没问题,但没准也会阴沟里翻船呢,对吧 ?
先看官网 QwQ-32B的答案:

回答很准确,没什么可以挑剔的。
然后是上面我本地的 QwQ-32b_q4_K_M:
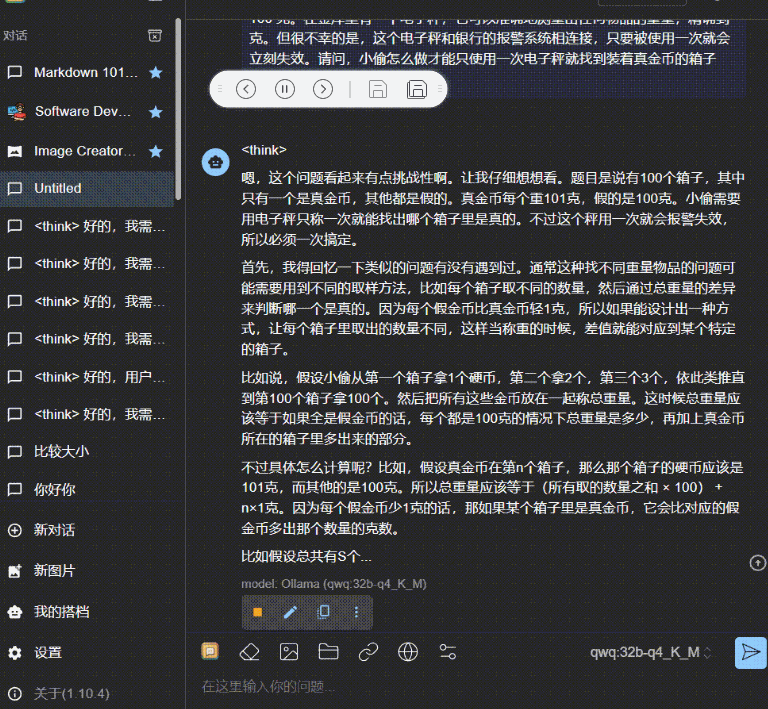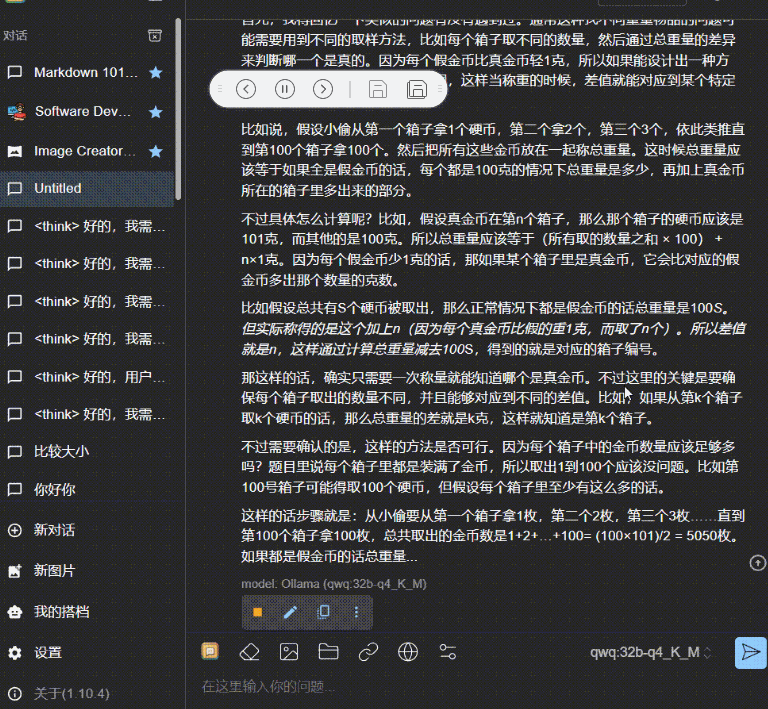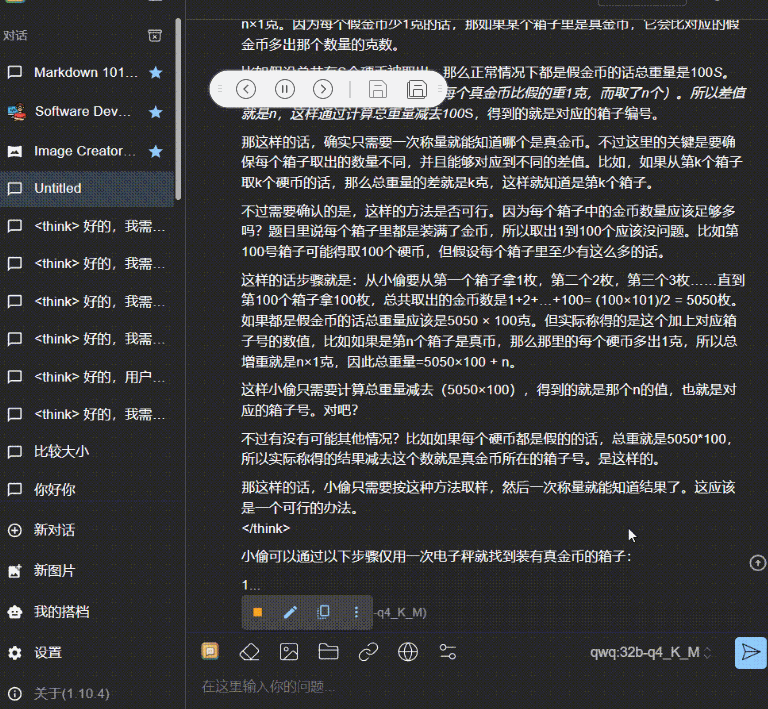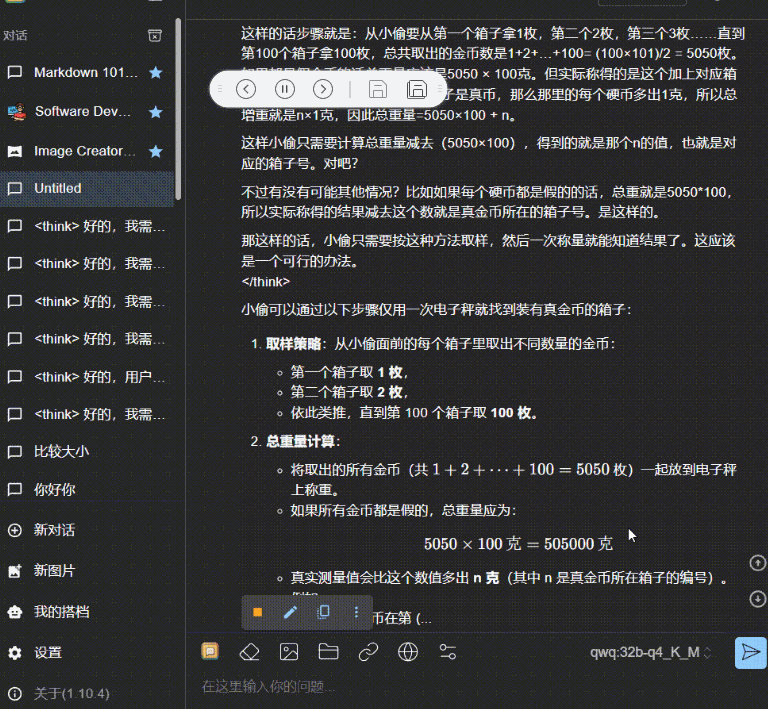
这个视频没有进行任何加速,可以看到,在发送的一瞬间,就立马开始输出。
比官网爽太多了!
第一题没有分出胜负, 加大难度!!
题目二: 池塘取水
假设有一个池塘,里面有无穷多的水。现有 2 个空水壶,容积分别为 5 升和 6 升。问题是如何只用这 2 个水壶从池塘里取得 3 升的水。
官网 QwQ-32B的答案:

下面是本地的 QwQ-32b_q4_K_M:


可以看到,本地版也成功的给出了两种不同的方法。
题目三: 编程题
本地部署大模型用来作为编程助手是一个比较大的需求。对于当前大模型的能力来说,Leetcode 这类普通的面试题应该可以秒杀。
所以直接给他们上难度。
编写一个 Python 程序,展示一个球在旋转的六边形内弹跳。球应受到重力和摩擦力的影响,并且必须以逼真的方式从旋转的墙壁上弹回。
官网 QwQ-32B:
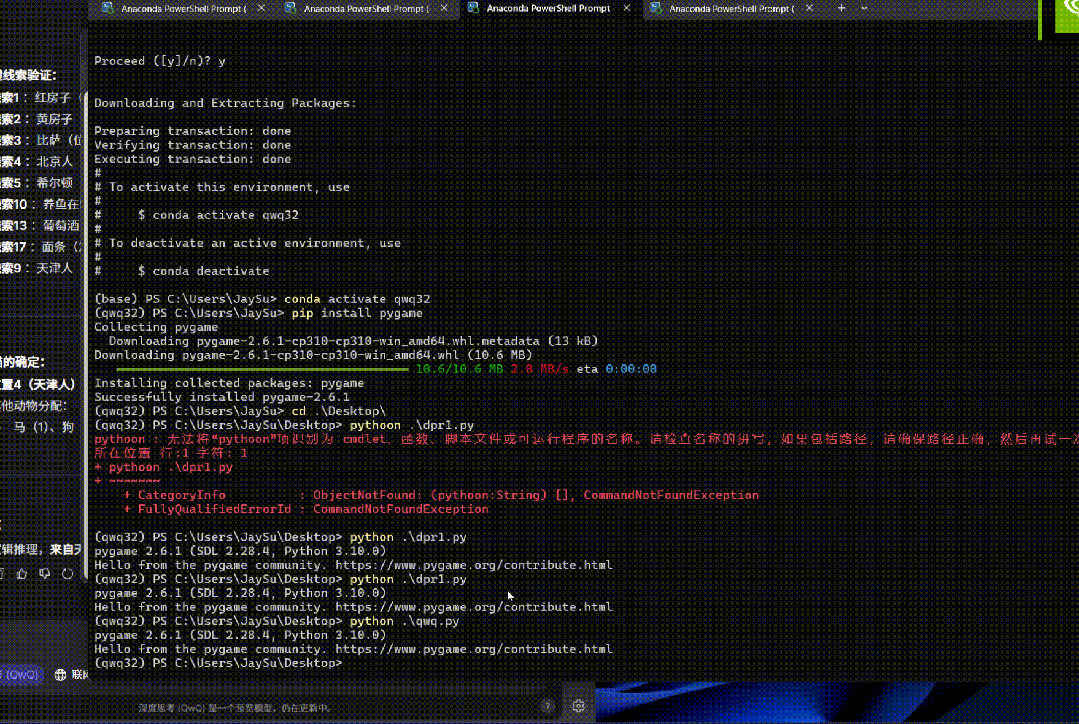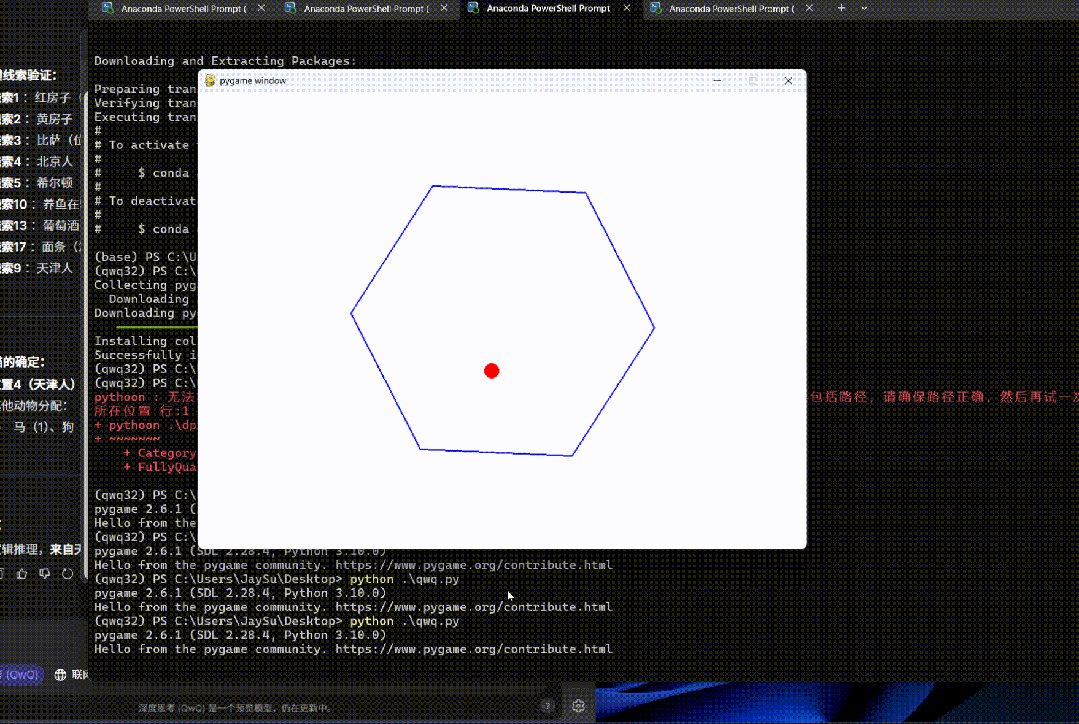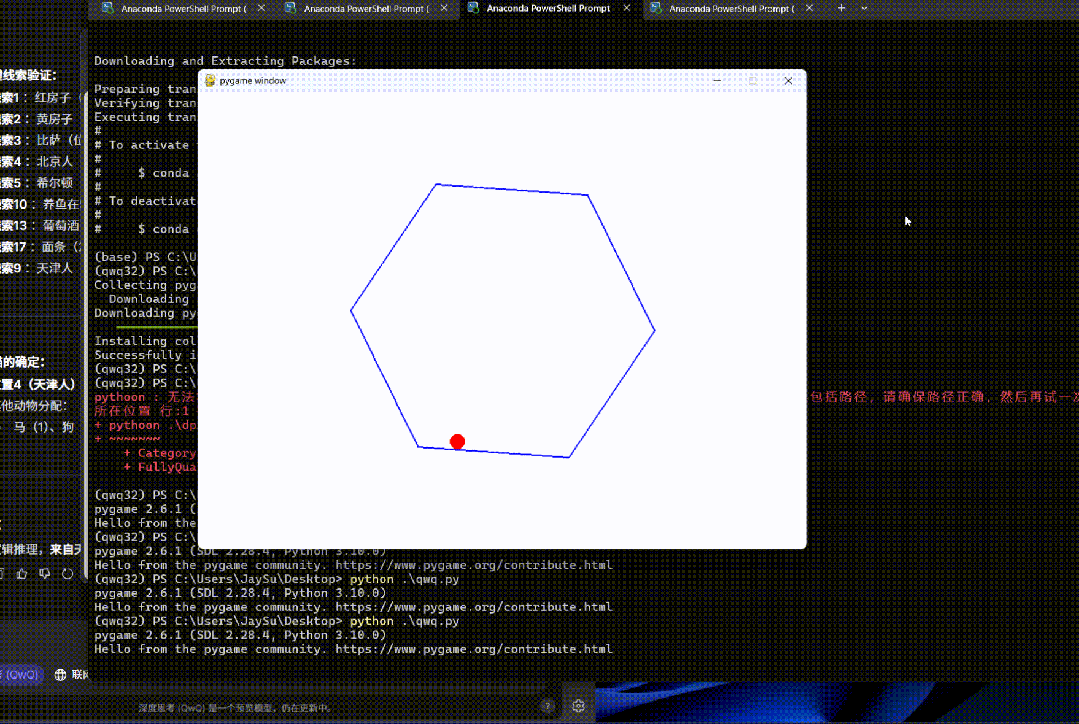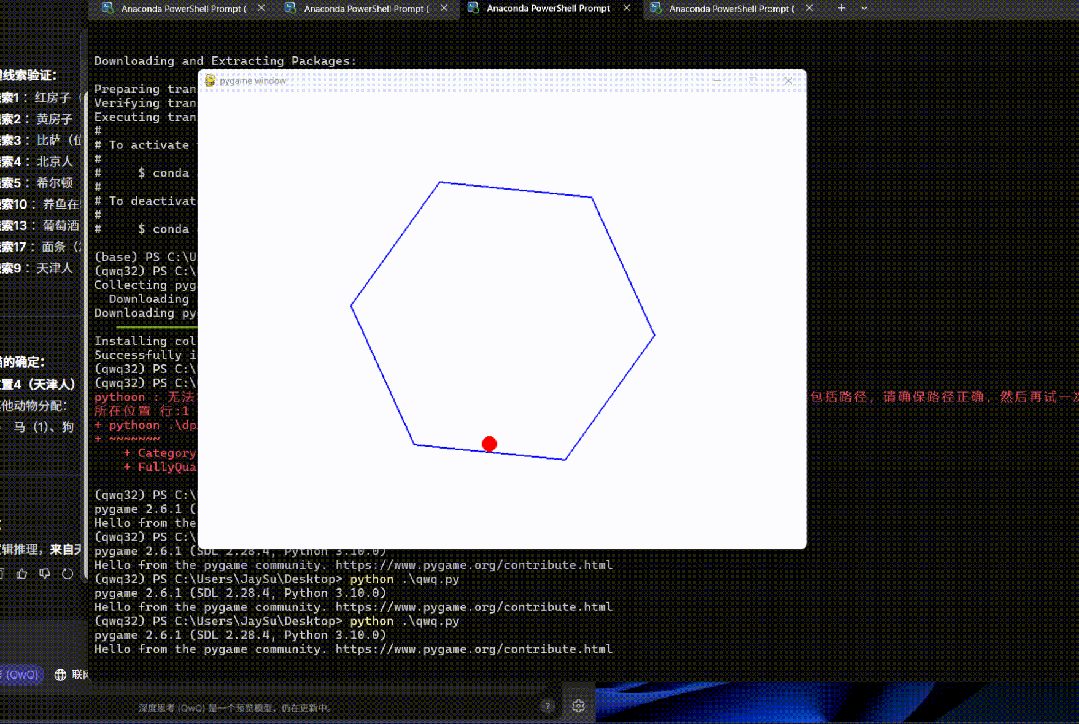
一把过。
而且对物理规律的把握非常准确。
很难让人相信这是一个只有 32B 参数的模型。
我们再看看本地的 QwQ-32b_q4_K_M 的表现:
这次非常遗憾,没有完全输出答案就中断了。

吐了 3、4 分钟之后,就卡住了,之后也没再输出。
应该是显存不足了,大模型推理的过程会慢慢吞噬显存,到一定长度后就爆了。尤其是长文本和复杂任务推理的时候。
而且,QwQ32b 模型有一个特点就是会输出超长的思考过程,动不动几万字 token,官网使用卡住了就大概率就是爆了。
上面这三道测试题,虽然不具备严谨的统计意义,但可以很直观的让大家感受到本地部署的 QwQ 32b 模型能力。
一句话总结就是,对于普通难度的问题,与官网没有太大区别。对于某些超级难的问题,本地模型还是有些困难。
但本地部署模型的那种让你随时都能用,不需要排队等待的那种爽感,可不是在线模型能够带给你的。
赶紧搞起来!!
如何零基础入门 / 学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 1274
1274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









