










今天给大家分享一篇最新的RAG论文:
论文题目:Enhancing Retrieval-Augmented Generation: A Study of Best Practices
论文链接:https://arxiv.org/abs/2501.07391
论文代码:https://github.com/ali-bahrainian/RAG_best_practices
图片来源:https://x.com/shao__meng/status/1879329913293209734
研究概述
这篇论文主要关注的是检索增强型生成(RAG)系统中的一个核心问题:不同的组件和配置如何影响系统的性能。
简单来说,RAG系统通过结合语言模型和外部知识库来生成更准确的回答,但之前的研究并没有深入探讨哪些因素(比如模型大小、提示设计、知识库大小等)对系统性能的影响最大。这篇论文的目标就是通过系统的实验和分析,找出这些关键因素,并提出一些新的配置方法,帮助提升RAG系统在各种复杂任务中的表现。
论文亮点
- ✅查询扩展:使初始查询多样化以获得更多相关信息。
- ✅对比上下文学习(Contrastive ICL):利用真假例子消除虚假信息,提高准确性!
- ✅聚焦模式:仅提取必要的上下文并最大限度地减少噪音。
查询阶段
- 查询扩展 查询扩展是扩展用户输入查询(q)以生成各种关键字和查询变体的过程。
- 利用 Flan-T5 等生成模型创建增强查询(Raffel et al., 2020)。
例子)
最初询问:“COVID-19 有哪些症状?”
•生成的关键词:
•“冠状病毒感染的迹象”
•“SARS-CoV-2 的症状”
•“常见的 COVID-19 症状”
检索阶段
- 第一步:在知识库中搜索每个关键字并检索广泛的相关文档。
- 第二阶段:使用初始查询将范围缩小到仅相关文档。
RAG有哪些相关研究?
在RAG领域,已经有不少研究为这篇论文奠定了基础。以下是一些重要的相关研究:
-
RAG系统的初步研究:
- Guu et al. (2020) 展示了语言模型可以通过实时检索文档来提高生成文本的准确性,而不需要增加模型的大小。
- Shi et al. (2024b) 则证明了即使对于没有直接访问权限的黑盒模型,检索模块也能发挥作用。
-
RAG系统的优化:
- Wang et al. (2024) 提出了优化检索组件的策略,比如改进文档索引和检索算法,以减少延迟并保持准确性。
- Hsia et al. (2024) 研究了如何通过架构决策(如语料库选择、检索深度等)来提升RAG系统的效率。
- Wu et al. (2024) 探讨了如何平衡模型内部知识和外部检索到的信息,避免两者之间的冲突。
-
RAG系统的应用:
- Lewis et al. (2020) 提出了将外部知识源集成到推理过程中的RAG模型,确保生成的信息是最新且准确的。
- Borgeaud et al. (2022) 和 Lee et al. (2024) 讨论了RAG模型如何通过整合可验证的信息来提高回答的事实准确性。
-
RAG系统的评估:
- Semnani et al. (2023) 和 Chang et al. (2024) 研究了大型语言模型(LLMs)生成不准确信息的问题,并探讨了RAG系统如何解决这一问题。
- Tran and Litman (2024) 则讨论了如何通过增强知识检索来实现基于知识的对话。
论文如何探索这个问题?
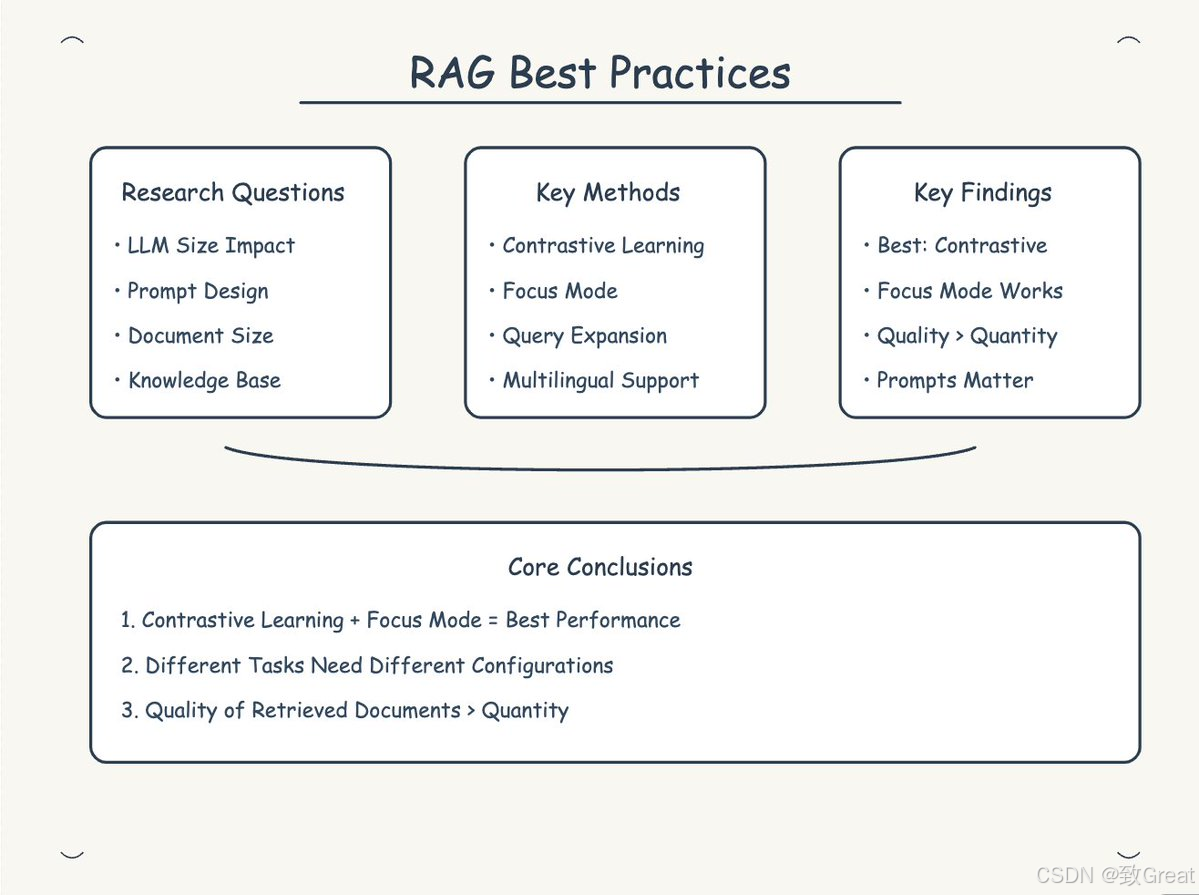
论文通过以下几个步骤来解决RAG系统中不同组件和配置对性能影响的问题:
-
提出研究问题:
论文首先提出了九个关键的研究问题,涵盖了语言模型大小、提示设计、文档块大小、知识库大小、检索步长、查询扩展、对比上下文学习、多语言知识库和焦点模式等方面。 -
设计RAG系统变体:
基于这些研究问题,论文设计了多种RAG系统的变体,包括查询扩展模块、检索模块和文本生成模块。 -
实验设置:
论文详细描述了实验的设置,包括使用的数据集(TruthfulQA和MMLU)、知识库(Wikipedia Vital Articles)、评估指标(如ROUGE、余弦相似度、MAUVE、FActScore等)以及RAG方法的具体实现细节。 -
实验和结果分析:
论文在两个数据集上进行了广泛的实验,评估了不同RAG变体的性能,并进行了相关性评估、事实性评估和定性分析。 -
对比分析:
论文对比了不同RAG配置的效果,分析了语言模型大小、提示设计、文档大小、知识库大小、检索步长、查询扩展、对比上下文学习、多语言知识库和焦点模式对生成响应质量的影响。 -
提出新方法:
论文提出了四种新的RAG配置方法,包括查询扩展、对比上下文学习示例、多语言知识库和焦点模式RAG,这些都是本文的新贡献。
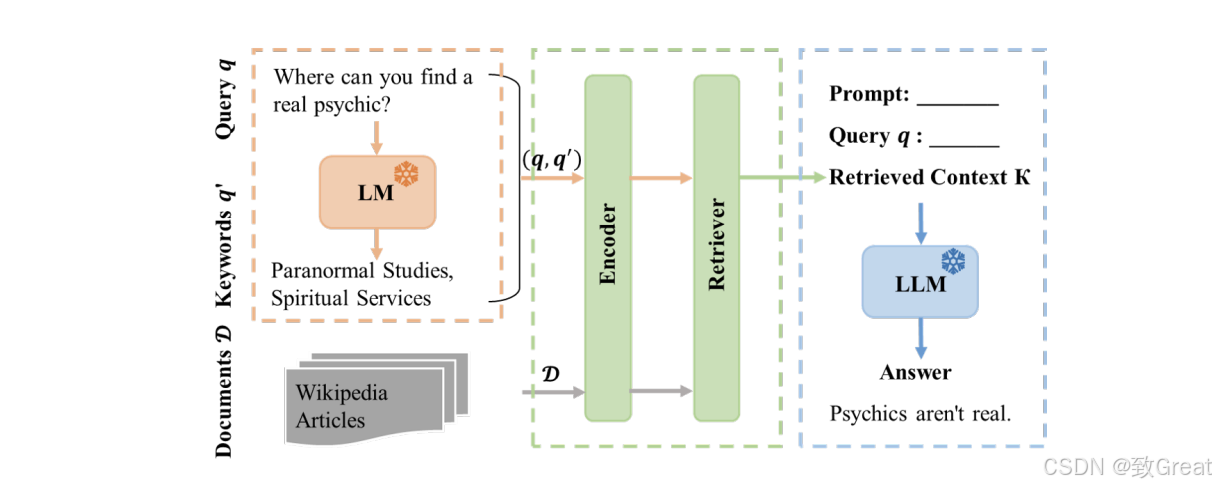
通过这些步骤,论文系统地研究了RAG系统的架构,并提出了具体的改进措施,为开发和优化RAG系统提供了实证基础和理论支持。
论文做了哪些实验?
实验分类
论文进行了以下几类实验:
-
相关性评估:
- 对比了不同RAG变体生成的文本与参考文本的相关性。
- 使用了ROUGE-1、ROUGE-2、ROUGE-L、嵌入余弦相似度和MAUVE等指标来评估性能差异。
- 评估了九个研究问题对RAG系统性能的影响。
-
事实性评估:
- 使用FActScore指标评估了RAG变体在TruthfulQA和MMLU数据集上的事实性表现。
- 对比了有无RAG模块的模型(w/o_RAG)与包含RAG模块的模型之间的事实性表现。
-
定性分析:
- 提供了在TruthfulQA和MMLU数据集上由模型变体生成的示例。
- 展示了所提出的模块如何通过专门的检索技术显著提高RAG系统的性能。
具体实验设置:
- 数据集:使用了TruthfulQA和MMLU两个公开数据集。
- 知识库:使用了Wikipedia Vital Articles作为知识库,包括法语和德语文章。
- 评估指标:采用了ROUGE、嵌入余弦相似度、MAUVE和FActScore等指标。
- RAG方法的具体实现:包括使用T5模型进行查询扩展、FAISS用于向量索引和相似性搜索、Sentence Transformer作为文本编码器等。
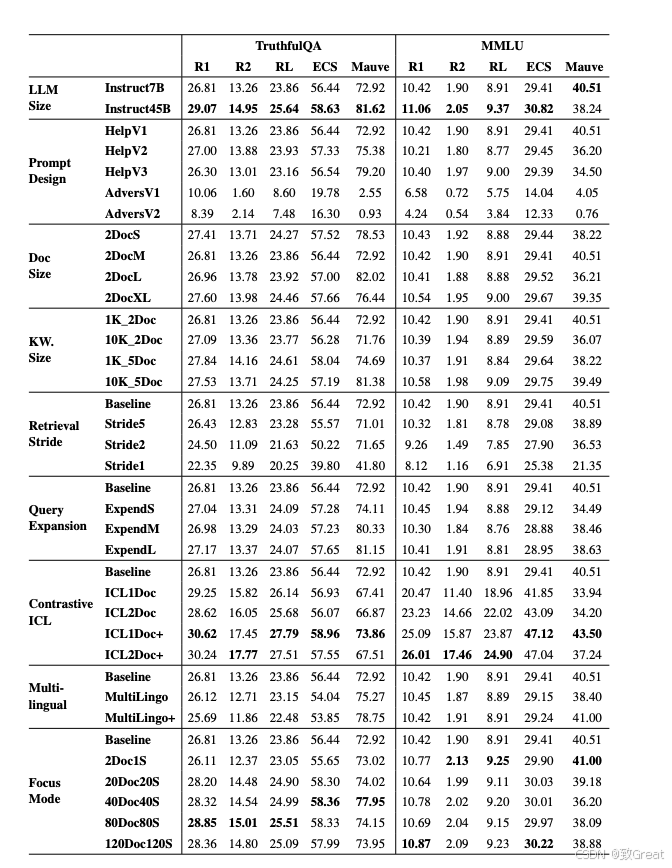
基于74次实验的结果,论文总结了关键发现,并提出了对比上下文学习RAG和焦点模式RAG在性能上的优越性。
论文的核心代码
下面代码实现了查询扩展和聚焦搜索,
-
查询扩展:
- 使用序列到序列模型对查询进行扩展,生成更多的关键词,以提高检索的准确性。
- 扩展后的查询用于在FAISS索引中搜索相似的标题,从而找到更多相关的文档。
-
聚焦检索:
- 如果指定了
focus参数,系统不仅会检索相关文档,还会进一步聚焦于文档中的最相关句子,提供更精确的结果。
- 如果指定了
更多细节请查看:https://github.com/ali-bahrainian/RAG_best_practices/tree/main
from faiss import IDSelectorArray, SearchParameters
import numpy as np
import pandas as pd
from sentence_transformers import SentenceTransformer
import torch
import spacy
import faiss
# Load the English model
nlp = spacy.load("en_core_web_sm")
class Retriever:
"""
Handles the retrieval of relevant documents from a pre-built FAISS index.
Enables querying with sentence transformers embeddings.
Attributes:
index (faiss.Index): FAISS index for fast similarity search.
doc_info (pd.DataFrame): DataFrame containing detailed information about documents.
documents (list of str): List of original documents.
embedding_model (SentenceTransformer): Model used for embedding the documents and queries.
"""
def __init__(self, index, doc_info, embedding_model_name, model_loader_seq2seq, index_titles):
"""Initializes the Retriever class with necessary components.
Args:
index: FAISS index for fast retrieval.
doc_info (DataFrame): DataFrame containing info about embedded document; aligned indices with index embeddings.
documents (list): List of original documents.
embedding_model_name (str): Name of the sentence transformer model.
"""
self.index = index
self.doc_info = doc_info
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.embedding_model = SentenceTransformer(embedding_model_name).to(self.device)
self.sent_info = None
self.index_sents = None
self.model_seq2seq = model_loader_seq2seq.model
self.tokenizer_seq2seq = model_loader_seq2seq.tokenizer
# Define text-query pairs for query expansion
self.text_query_pairs = [
{"text": "Mitochondria play a crucial role in cellular respiration and energy production within human cells.", "query": "Cell Biology, Mitochondria, Energy Metabolism"},
{"text": "The Treaty of Versailles had significant repercussions that contributed to the onset of World War II.", "query": "World History, Treaty of Versailles, World War II"},
{"text": "What are the implications of the Higgs boson discovery for particle physics and the Standard Model?", "query": "Particle Physics, Higgs Boson, Standard Model"},
{"text": "How did the Silk Road influence cultural and economic interactions during the Middle Ages?", "query": "Silk Road, Middle Ages, Cultural Exchange"}
]
self.index_titles = index_titles
def build_index(self, documents):
"""
Builds a FAISS index from document embeddings for efficient similarity searches which
includes embedding document chunks and initializing a FAISS index with these embeddings.
Args:
chunk_size (int): The size of each text chunk in tokens.
overlap (int): The number of tokens that overlap between consecutive chunks.
Returns:
faiss.IndexFlatIP: The FAISS index containing the embeddings of the document chunks.
"""
embeddings = self.embed_sents(documents)
index = faiss.IndexFlatIP(embeddings.shape[1])
index.add(embeddings)
return index
def embed_sents(self, documents):
"""
Generates embeddings for document chunks.
The process involves:
1. Preparing chunks of documents:
- Splits each document into overlapping chunks based on `chunk_size` and `overlap`.
2. Encoding these chunks/documents into embeddings using the Sentence Transformer.
Args:
chunk_size (int): Size of each chunk in tokens.
overlap (int): Overlap between consecutive chunks in tokens.
Returns:
np.ndarray: An array of embeddings for all the documents (chunks).
"""
self.sent_info = self.prepare_sents(documents)
self.sent_info = pd.DataFrame(self.sent_info)
embeddings = self.embedding_model.encode(self.sent_info["text"].tolist(), show_progress_bar=True)
self.sent_info['embedding'] = embeddings.tolist()
return np.array(embeddings)
def prepare_sents(self, documents):
"""
Splits each document into sentences and
creates dictionary for DataFrame associated with index.
Returns:
Tuple[List[str], List[dict]]: Tuple containing list of all sents and their info.
"""
sent_info = []
sent_id = 0
for document in documents:
doc = nlp(document)
sents = [sent.text for sent in doc.sents]
# Prepend same document to its chunks and store document/chunk details
for sent in sents:
sent_dict = {"text": sent, "org_sent_id": sent_id}
sent_info.append(sent_dict)
sent_id += 1
return sent_info
def retrieve(self, query_batch, k, expand_query, k_titles, icl_kb_idx_batch=None, focus=None):
"""
Retrieves the top-k most similar documents for each query in a batch of queries.
Args:
query_batch (list of str): List of query strings.
k (int): Number of documents to retrieve.
Returns:
List[List[dict]]: List of lists containing formatted results of retrieved documents for each query.
"""
if k == 0:
return [[] for _ in query_batch]
if expand_query:
# Expand the query using a seq2seq model
eq_prompt_batch_str = []
for query in query_batch:
examples = self.text_query_pairs.copy()
examples.append({"text": query, "query": ""})
eq_prompt = "\n".join([f"Question: {example['text']}\nQuery Keywords: {example['query']}" for example in examples])
eq_prompt_batch_str.append(eq_prompt)
eq_prompt_batch_enc = self.tokenizer_seq2seq(eq_prompt_batch_str, return_tensors='pt', padding=True).to(self.device)
eq_batch_enc = self.model_seq2seq.generate(**eq_prompt_batch_enc, max_length=25, num_return_sequences=1)
eq_batch = self.tokenizer_seq2seq.batch_decode(eq_batch_enc, skip_special_tokens=True)
eq_batch = [eq.split(", ") for eq in eq_batch] # Split the expanded queries
# Encode the expanded queries and search the index for similar titles
eq_batch_indexed = [(eq, i) for i, eqs in enumerate(eq_batch) for eq in eqs]
eq_batch_flat = [eq for eq, _ in eq_batch_indexed]
eq_embeddings = self.embedding_model.encode(eq_batch_flat, show_progress_bar=False)
_, indices_eq = self.index_titles.search(np.array(eq_embeddings), k_titles)
# Retrieve the indices of the documents associated with the similar titles
indices_eq_batch = [[] for _ in range(len(query_batch))]
for ids, (_, i) in zip(indices_eq, eq_batch_indexed):
indices_eq_batch[i].append(self.doc_info[self.doc_info['org_doc_id'].isin(ids)].index.tolist())
else:
# If not expanding the query, set the indices to an empty list
if icl_kb_idx_batch:
# Remove the correct answer from the retrieved documents
all_ids_batch = [list(range(self.index.ntotal)) for _ in range(len(query_batch))]
for all_ids, icl_kb_idx in zip(all_ids_batch, icl_kb_idx_batch):
all_ids.remove(icl_kb_idx)
all_ids_batch = [[all_ids] for all_ids in all_ids_batch]
indices_eq_batch = all_ids_batch
else:
indices_eq_batch = [[] for _ in range(len(query_batch))]
# Batch encode the queries
query_embeddings = self.embedding_model.encode(query_batch, show_progress_bar=False)
# Process each query separately
results_batch = []
for query_embedding, ids_filter in zip(query_embeddings, indices_eq_batch):
ids_filter = ids_filter if ids_filter else [list(range(self.index.ntotal))]
id_filter_set = set()
for id_filter in ids_filter:
id_filter_set.update(id_filter)
id_filter = list(id_filter_set)
id_selector = IDSelectorArray(id_filter)
# Search the index for similar documents, retrieve a larger set of documents
similarities, indices = self.index.search(np.array([query_embedding]), k, params=SearchParameters(sel=id_selector))
indices, similarities = indices[0], similarities[0]
# Focus on the most relevant sentences from the retrieved documents
if focus:
docs = self.doc_info.loc[indices]["text"].tolist()
self.index_sents = self.build_index(docs)
similarities, indices = self.index_sents.search(np.array([query_embedding]), focus)
indices, similarities = indices[0], similarities[0]
icl_kb = icl_kb_idx_batch!=None
if focus:
# Retrieve the most relevant sentences from the retrieved documents
results_batch.append([self._create_result(idx, sim, icl_kb, focus) for idx, sim in zip(indices[:focus], similarities)])
else:
results_batch.append([self._create_result(idx, sim, icl_kb, focus) for idx, sim in zip(indices[:k], similarities)])
return results_batch
def _create_result(self, idx, score, icl_kb, focus):
"""
Creates/builds a result dictionary of the retrieved document.
Args:
idx (int): Index of the result/document in doc_info.
score (float): Similarity (& Diversity) score of document.
Returns:
dict: Dictionary containing the document text and additional information.
"""
if focus:
# Retrieve the most relevant sentences from the retrieved documents
sent = self.sent_info.iloc[idx]
result_dict = {
"text": sent["text"],
"sent_id": sent["org_sent_id"],
"score": score
}
else:
doc = self.doc_info.iloc[idx]
# Create the result dictionary
result_dict = {
"text": doc["text"],
"doc_id": doc["org_doc_id"],
"score": score
}
if icl_kb:
# Include the correct and incorrect answers for ICL KB
result_dict['correct_answer'] = doc["correct_answer"]
result_dict['incorrect_answer'] = doc["incorrect_answer"]
return result_dict
添加微信1185918903,关注公众号ChallengeHub获取更所咨询


















 908
908

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









