










23年8月来自加拿大蒙特利尔大学的论文“Continual Pre-Training of Large Language Models: How to (re)warm your model?”。
大语言模型 (LLM) 通常会在数十亿个tokens上进行预训练,一旦有新数据可用,就必须重新启动该过程。一个更便宜、更有效的解决方案是启用这些模型的持续预训练,即用新数据更新预训练模型,而不是从头开始重新训练它们。然而,新数据引起的分布变化通常会导致过去数据的性能下降。为了朝着高效的持续预训练迈出一步,本文研究不同预热策略的效果。假设在使用新数据集进行训练时,必须重新增加学习率以提高计算效率。研究在 Pile(上游数据,300B 个tokens)上预训练模型的预热阶段,并继续在 SlimPajama(下游数据,297B 个tokens)上进行预训练,遵循线性预热和余弦衰减进度。在 Pythia 410M 语言模型架构上进行了所有实验,并通过验证困惑度(perplexity)评估性能。虽然重新预热模型首先会增加上游和下游数据的损失,但从长远来看,它会提高下游性能,甚至优于从头开始训练的模型。
设置
设置中,上游(或预训练)数据集是 Pile(Gao,2020)。下游(或微调)数据集是 SlimPajama(Soboleva,2023)。SlimPajama 是 RedPajama(Together.xyz,2023)的广泛去重复数据版本,它基于 LLama 数据集(Touvron,2023)构建。在这项工作中,交替使用“微调”和下游的持续预训练。然而,在持续预训练设置中,下游数据集与之前的预训练数据集规模相当(即非常大,与许多微调数据集不同)。
SlimPajama 数据集是从与 Pile 类似的来源构建的,但数据量更大。因此,一些上游数据可能会在下游预训练期间重复。实验设置与 (Ash & Adams, 2020) 的设置相当,首先在数据集的一半样本上训练分类器,然后在所有样本上对其进行微调。图像分类的预热启动具有挑战性。用在 Pile 上预训练的模型并继续在 SlimPajama 上进行预训练,遵循因果语言建模的类似设置。
数据集——用与 Black et al. (2022) 相同权重的 Pile 进行验证。对 SlimPajama 数据集 (Soboleva et al., 2023) 进行混洗和随机抽样,形成 ∼297B tokens的训练数据集和 ∼316M tokens的验证数据集。不使用重放。用与 (Black et al., 2022) 相同的token化器,其专门在 Pile 上进行训练。
模型 – 用在 Pile (Biderman,2023) 上预训练的 410M Pythia,即 GPT-NeoX (Black,2022) 模型。不用flash attention (Dao,2022)。
超参 – 用 AdamW 优化器,β1 = 0.9、β2 = 0.95、ε = 10−8,权重衰减为 0.1。最大学习率在实验中有所不同 {1.5 · 10−4, 3 · 10−4, 6 · 10−4}。用余弦学习率衰减到0.1 · MaxLr的最小 。所有预热长度均基于完整的下游数据集大小(297B 个 tokens)计算。余弦衰减进度在 240B 个 tokens 时达到最小学习率,此后保持不变。将梯度裁剪设置为 1.0。训练以半精度(FP16)进行,无 dropout操作。
持续预热
1 预热多久
在文献中,通常最多用 1% 的数据进行预热 (Zhao,2023)。在这个实验中,研究是否对这个超参敏感。
设置:针对 297B 个 tokens的一个进度尝试不同的预热长度:0%、0.5%、1% 和 2% 的数据,并测量前 50B 个 tokens 之后的性能。从不同的角度来看,可以将此实验视为对不同数量数据运行 1% 的预热。假设对更多迭代进行预热可以实现更平稳的过渡,从而提高性能。
结果:本实验结果如图所示。它们表明,用于预热学习率的数据大小不会显著影响下游任务(学习)或上游任务(遗忘)的困惑度。这些结果推翻了原来的假设,即用更多 tokens 进行预热可以平滑过渡,线性预热毫无用处。然而,在没有任何渐进式预热的情况下,训练的模型会经历一个初始的“混沌阶段”,导致损失在训练的前几次迭代中激增,这种现象也称为稳定性差距(Lange,2023;Caccia,2022)。
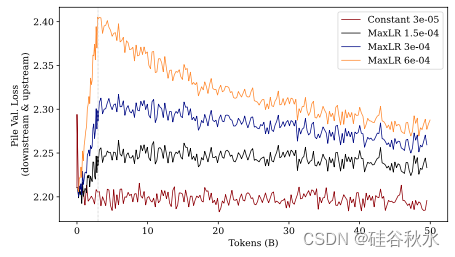
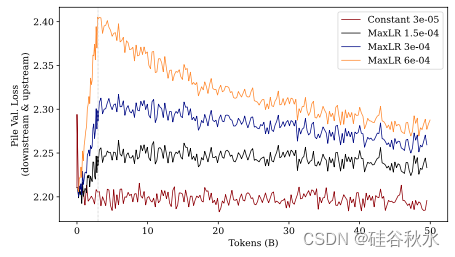
如图所示:(顶部)在 SlimPajama 上用不同数量的 tokens 微调进行预热时困惑度的演变。(底部)在 Pile 验证集(上游)上进行相同实验的困惑度。MaxLr = 3 · 10−4,MinLr = 0.1 · MaxLr。该图显示,在该规模下,预热阶段的长度不会显著影响结果。

要点 1:
• 预热阶段的长度似乎对 Pile 和 SlimPajama 验证损失没有显著影响。
2. 预热达到多高?
重新预热学习率的一个目标是实现计算效率高的持续预训练。学习率太小可能会导致下游数据集的学习效率低下,而学习率太大可能会导致上游数据集的灾难性遗忘。重新预热学习率的一个重要方面是决定将其增加到多高。因此,在这个实验中,改变最大学习率来评估其对性能的影响。
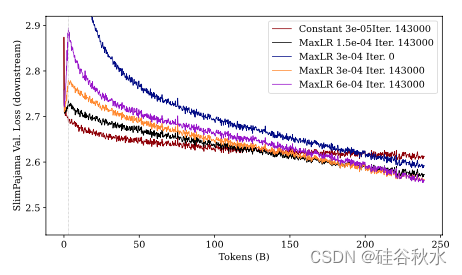
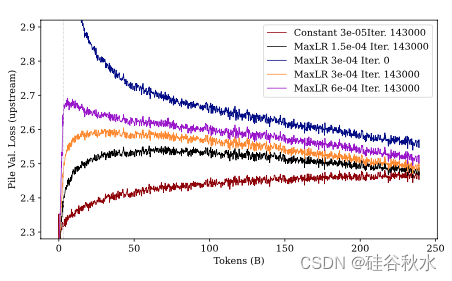
设置:将预热阶段的长度固定为训练数据的 1% 这个默认值,并改变最大学习率。用 Pythia 410M(Biderman et al., 2023)预训练时使用默认值 3 · 10^−4,1.5 · 10^−4,和 6 · 10^-4 进行实验。对于后预热的余弦衰减阶段,将最终学习率设置为最大学习率的 10%。用的学习率进度在 240B 个 tokens 时衰减到最小学习率,此后保持不变。在240B 个 tokens 的最后(衰减期结束)运行退出。
结果:本实验的结果如下三个图所示。在训练结束时,较大的最大学习率会提高下游数据的性能,而会损害上游数据的性能。相反,较小的最大学习率会提高上游数据的性能,同时限制对下游数据的适应性——导致性能下降。改变最大学习率可能是一种权衡下游和上游性能的有效方法。此外的一个普遍趋势:在 SlimPajama 上进行微调会导致模型忘记在 Pile 上学到的内容,从而造成 Pile 验证困惑度增加。最后,从恒定学习率训练的模型采用早期停止(类似于传统的微调)是一种经济的方式,可以适应新的数据分布,同时保持上游数据集的强大性能。
要点 2:
• 重新预热然后降低学习率似乎是在下游任务上学习良好的必要条件。此外,虽然保持恒定的学习率最初在 Pile 上是有利的,但当在 SlimPajama 上训练足够长的时间时,这种优势就会消失。
• 仅在 SlimPajama 上学习的模型在 SlimPajama 上的表现,比在 Pile 上预训练的模型更差,尽管它仅针对下游任务进行了优化,突出了两个数据集之间的正向迁移。
3. 比较从头开始训练的模型
在这个实验中,比较微调模型和从头开始训练的模型。
设置:用与MaxLr = 3 · 10−4 模型相同的余弦衰减进度从随机的初始化开始训练模型。
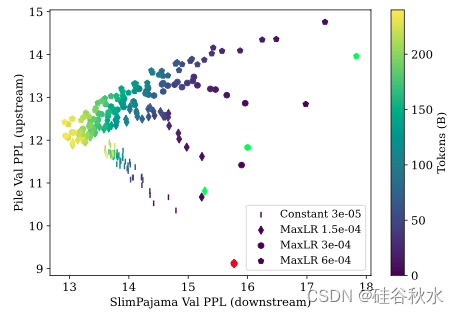
结果:所有经过预热的微调模型都比从头开始训练的模型表现更好。这表明,即使下游数据集与上游数据集规模相同且与上游数据集重叠,微调而不是重新训练也可能提高性能。在 200B 个 tokens 之后,从头开始训练的模型比使用恒定学习率微调的模型表现更好。
4. 在同样数据重新预热
在之前的实验中,对新数据进行微调会导致旧数据的损失快速增加,随后减少。最大学习率越大,增量越大。损失增加的一个假设是,上游和下游数据之间的分布变化会干扰训练过程。为了评估这一假设,在没有分布变化的环境中应用了预热策略。也就是说,通过对 Pile 进行微调来复制实验。
设置:在此实验中,不是针对 SlimPajama 数据进行微调,而是对 Pile 数据 50B 个 tokens 进行微调,用相同预热策略的参数。
结果:如图表明,在继续对 Pile 进行预训练的同时重新预热学习率,在查看下游验证损失时,与对 SlimPajama 数据重新预热的效果类似。这表明,Pile 和 SlimPajama 之间的分布漂移并不是前面重新预热学习率负面影响的唯一原因,优化的动态性也在损失增加中发挥作用。
如图显示,训练结果首先增加了 Pile 和 SlimPajama 数据的困惑度,但之后两者都降低了。有趣的是,在 Pile 上进行微调时,SlimPajama 困惑度和 Pile 困惑度之间具有线性关系,在 SlimPajama 上进行微调时并非如此。这种关系的一个可能解释是,在 Pile 上训练的模型在预热期间爬出最小值,并随着学习率的衰减返回到相同的最小值,从而产生线性趋势。
要点 3:
• 重新调整学习率似乎是导致之前开始学习下游任务时出现性能下降的一个重要原因,这一点可以通过在对同一数据集训练时重新预热然后降温学习率来证明。
• 在同一数据集上进行训练时,模型似乎无法从重新预热学习率导致的性能损失中恢复过来。
5. 评估早期检查点
设置:从模型预训练中选择三个检查点来测试预热策略是否受益于从非收敛检查点开始。假设是,选择距收敛较远的检查点可能有利于适应下游任务,因为这些检查点可能位于损失区域中更有利的点。
为了选择明显不同的检查点,将最后一个预训练检查点(即 143,000 次迭代后的 Pythia 410M)与一个更早的检查点进行比较,该检查点的 Pile 验证损失接近之前所有模型达到的最大 Pile 验证损失(∼ 2.5),以及两个其他检查点之间的第三个检查点。
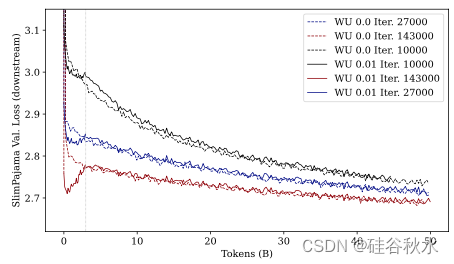
结果:如图提供了 SlimPajama 上验证损失的演变。可以看到,在设置中,选择较早的检查点进行后期微调不会导致下游性能的改善。因此,选择最新的检查点是最佳选择。结论是,预训练不会导致模型失去可塑性,那将使模型难以重新预热。
局部结论:即使下游数据与上游数据的来源相似,在新数据上重新预热预训练模型也是一项艰巨的任务。结果表明,用于预热的tokens数不会显著改变性能,增加最大学习率会提高最终模型的下游性能,而降低最大学习率会提高上游性能,选择较早的检查点会降低上游和下游数据的性能。
要点 4:
• 在 Pile 上进行预训练时使用较早的检查点并不会导致在 SlimPajama 上学习得更快。

















 821
821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









